Feature Transforms
이번 강의부터는 단순한 Linear classifier를 벗어나 Neural Networks에 대해 배울 것이다. Neural Networks는 Linear classifier가 해결할 수 없는 문제들을 여럿 해결할 수 있다.
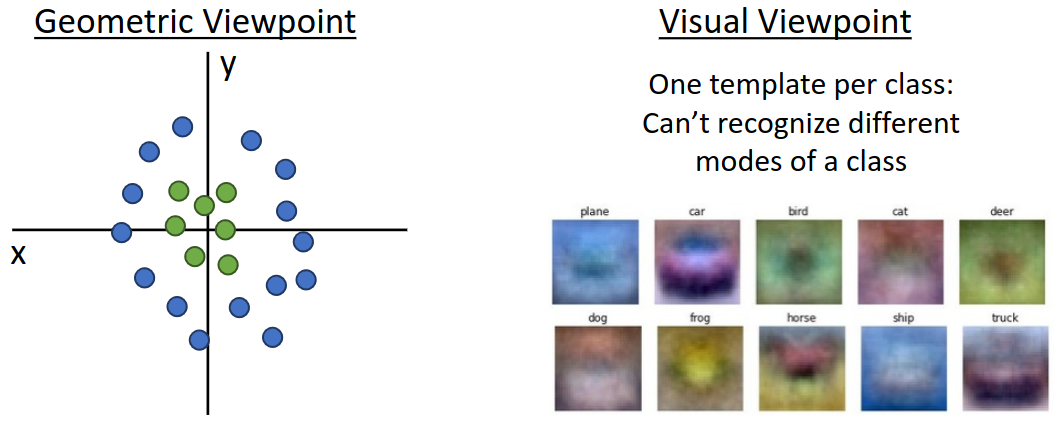
위 그림과 같이 선형으로 분류할 수 없는 두 클래스를 분류하는 문제를 해결할 수 있고, template matching의 관점에서는 하나의 클래스가 여러 개의 template을 가질 수 있게 해 준다.
Neural network에 대한 하나의 직관적인 이해는 인풋 데이터를 feature space로 매핑하는 것이다. 그 말은, 인풋 데이터 자체를 가지고 분류를 수행하는 것이 아니라, 데이터에서 먼저 feature들을 추출한 뒤 feature값을 축으로 하는 좌표공간상에 점을 찍고, 그 점들로 분류를 수행하는 것이다.
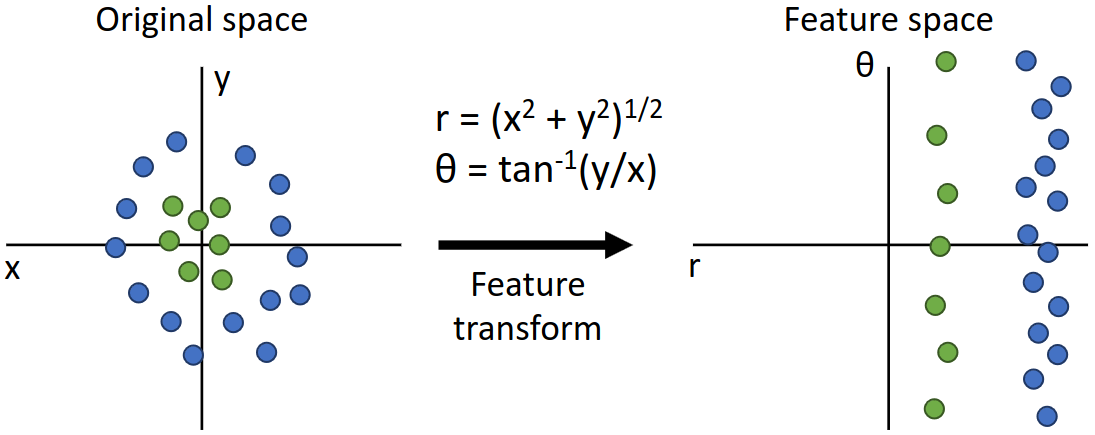
위 그림의 경우 왼쪽 이미지에서는 선형 분류가 불가능한 반면 feature를 추출한 후에는 선형 분류가 가능해진다. 위 경우 제곱, 제곱근, 역탄젠트 함수 등 specific한 함수들을 사용했는데, 만약 뉴럴 네트워크로 이러한 함수들을 approximation할 수 있다면, 어떤 데이터 분포든 간에 선형 분류가 가능하지 않을까? 이것이 뉴럴 네트워크의 핵심 아이디어이다.
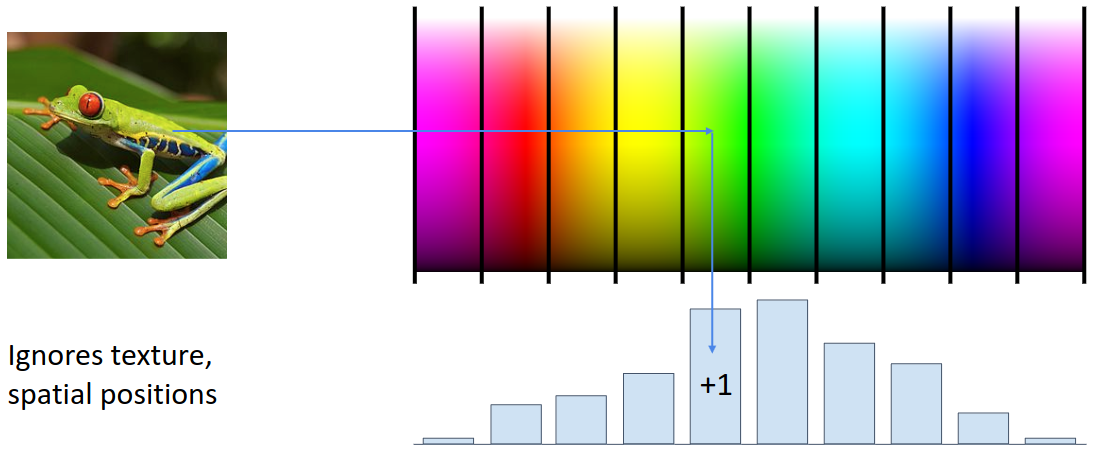

다른 종류의 Feature Transform으로는 Color Histogram과 Histogram of Oriented Gradients (HoG)가 있다. Color histogram은 이미지의 색상 분포를 히스토그램으로 나타낸 것인데, 각 픽셀이 어디에 위치해 있는지에 대한 정보는 버리고 색상의 분포만을 이용한다. 반면 HoG는 색상 정보는 버리고 각 픽셀별 edge의 방향과 강도 정보를 추출한다. 이를 통해 동일한 물체가 이미지 내에서 어디에 위치하든 비슷한 분류를 수행할 수 있다.
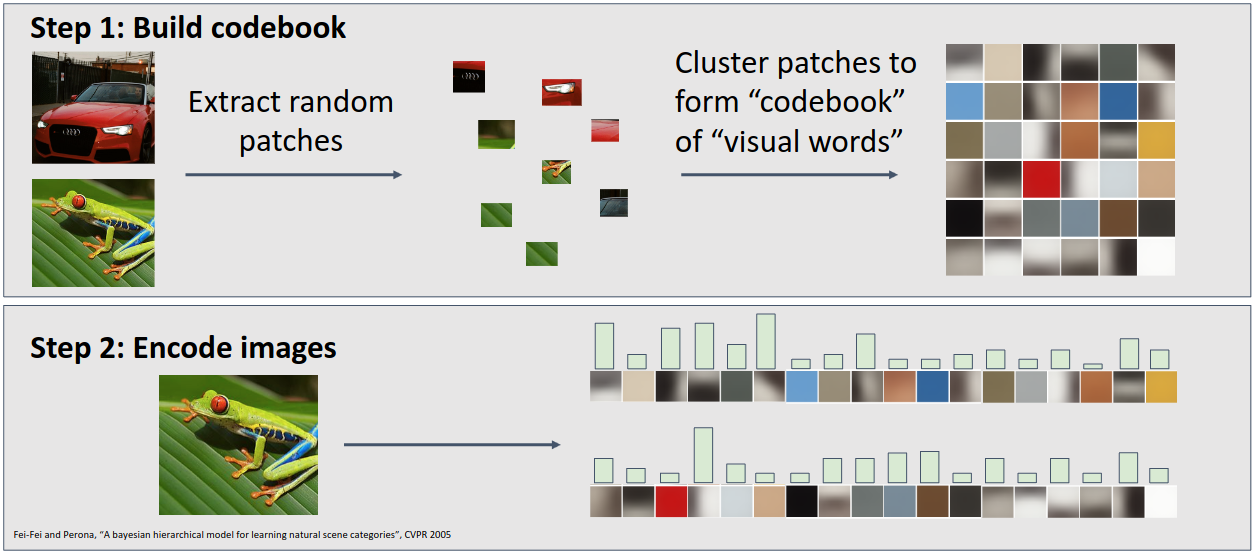
알고리즘적인 방법 외에 데이터에 기반한 방법으로 Bag of Words라는 방법도 있다. Bag of Words는 문서 분류에 주로 사용되는 방법으로, training image에서 랜덤하게 조각들을 잘라낸 다음 한데 모아 Codebook을 만들고, Codebook 안의 각 이미지 조각들이 전체 데이터셋에서 얼마나 많이 등장하는지를 바탕으로 Feature를 추출하게 된다.
실제로 AlexNet이 등장하기 1년 전인 2011년 ImageNet challenge에서 우승한 모델의 경우 사람이 직접 만든 feature transform을 사용했는데, 성능이 꽤 나쁘지 않았다고 한다.
결국 Feature Transform의 의미는, raw 데이터가 아닌 데이터의 특징을 추출하여 그 특징을 이용해 분류를 수행한다면 그 성능을 더욱 개선할 수 있다는 것이다. 그리고 뉴럴 네트워크를 사용함으로써 분류 그 자체뿐만 아니라 Feature Transform까지도 한번에 수행할 수 있게 되고, Feature Transform에 해당하는 파라미터들까지 학습이 가능해지면서 전체적인 성능을 향상시킬 수 있다.
2-Layer Neural Network
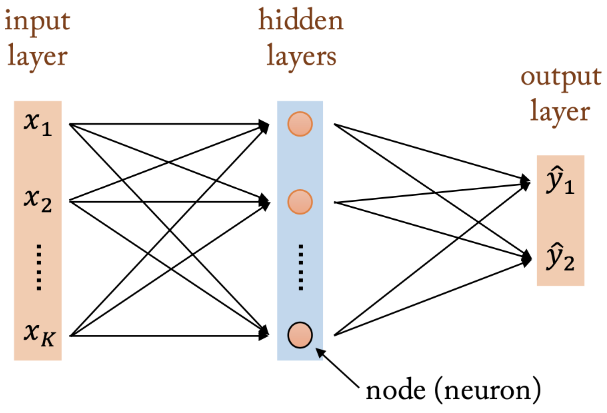
가장 간단한 형태의 Neural Network는 2-Layer Neural Network이다. 아래 그림과 같이 input layer, hidden layer, output layer로 구성되어 있고, 각 layer의 모든 element는 다음 layer의 모든 element와 연결되어 있다. 이 때문에 이를 Fully Connected Layer, Dense Layer, 또는 Multi-Layer Perceptron (MLP)이라고 부르기도 한다. 형태는 단순히 Linear classifier를 두 개 연결하고 그 사이에 비선형 함수를 끼워 넣은 것이다.
$f(x) = W_2 \cdot \max(0, W_1 \cdot x)$
직관적으로 살펴보면, 인풋 데이터에 첫 번째 weight matrix를 곱해 score를 구하고, 그 score에 $\max(0, x)$ 함수를 적용해 약간의 변형을 가한다. 이를 두 번째 weight matrix에 곱해 각 클래스에 대한 최종적인 score를 구하게 된다. 이때 첫 번째 layer를 통해 구한 score가 위에서 언급한 feature 역할을 하고, 두 번째 layer에서 그 feature를 이용해 분류를 수행할 수 있다.


Template Matching의 관점으로도 2-Layer Neural Network를 살펴볼 수 있다. 첫 번째 weight matrix $W_1$을 템플릿으로 보고, 두 번째 weight matrix $W_2$를 통해 템플릿들을 조합하여 최종 score를 만드는 것이라 볼 수 있다. 상단의 그림은 Lecture 3에서 Single Layer일 때의 $W$를 시각화한 것이고 하단은 2-Layer일 때의 $W_1$를 시각화한 것이다. 2-Layer일 경우에 템플릿이 조금 더 추상적으로 표현되는 것을 볼 수 있다. 이때 둘째 줄 4번째 사진의 경우 명확히 오른쪽을 보고 있는 말 그림이 있는 것을 보아 Single Layer에서 하나의 템플릿으로 여러 경우의 수를 표현할 수 없는 문제가 해결된 것을 볼 수 있다.
Activation Function
$f(x) = W_2 \cdot \max(0, W_1 \cdot x)$
위 수식에서 $\max(0, x)$ 함수를 Activation Function이라고 부른다. Activation Function은 Neural Network가 비선형 함수에도 approximation할 수 있도록 하는 핵심적인 역할을 한다.
$f(x) = W_2 \cdot (W_1 \cdot x) = (W_2 \cdot W_1) \cdot x = W_3 \cdot x$
Activation Function이 없다면 위 수식과 같이 Linear classifier와 다를 것이 없다. 하단의 Universal Approximation Theorem에서도 살펴보겠지만, Activation Function이 존재함으로써 Neural Network가 세상에 존재하는 어떤 함수든 근사할 수 있게 된다. 이는 위의 Feature Transform에서 언급한 것처럼 Neural Network가 인풋 데이터로부터 복잡한 feature들을 추출할 수 있도록 하는 핵심 요소가 된다.
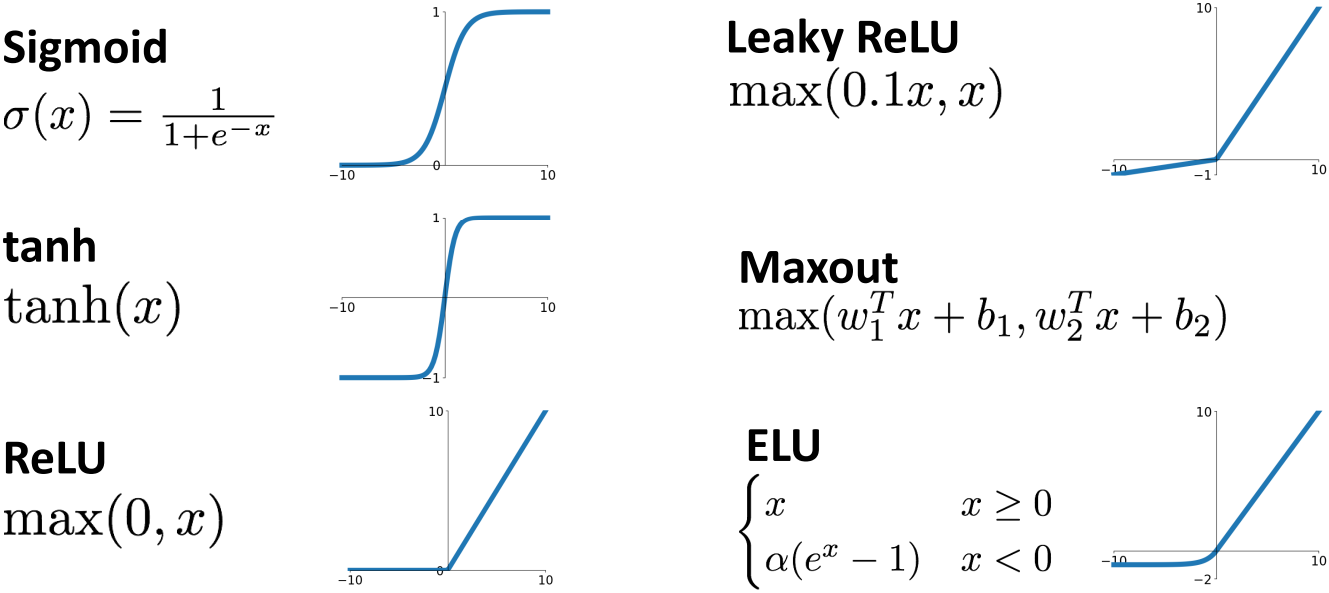
위 그림과 같이 여러 종류의 Activation Function이 존재하는데, ReLU (Rectified Linear Unit)가 대부분의 Neural Network에서 준수한 성능을 낸다고 알려져 있다. 딥러닝 모델을 처음 구축할 때 ReLU를 시도해 보는 것이 좋다. 각 Activation Function에 대해서는 Lecture 10에서 자세히 다룰 것이다.
Visualization of Intuitions
잠깐 딴 길로 새서, Feature transform과 Activation Function의 역할을 시각적으로 표현한 그림이 있다.
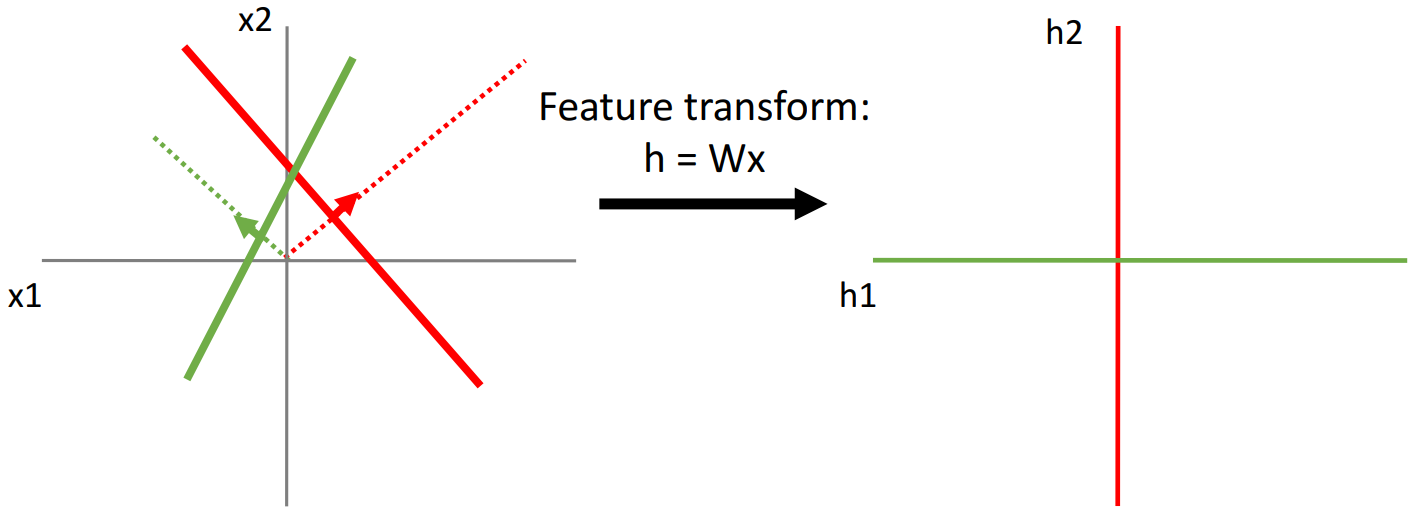
왼쪽 그림에서 초록색 선과 빨간색 선을 각각 새로운 좌표축으로 하여 좌표평면을 변형시킨 것이다.
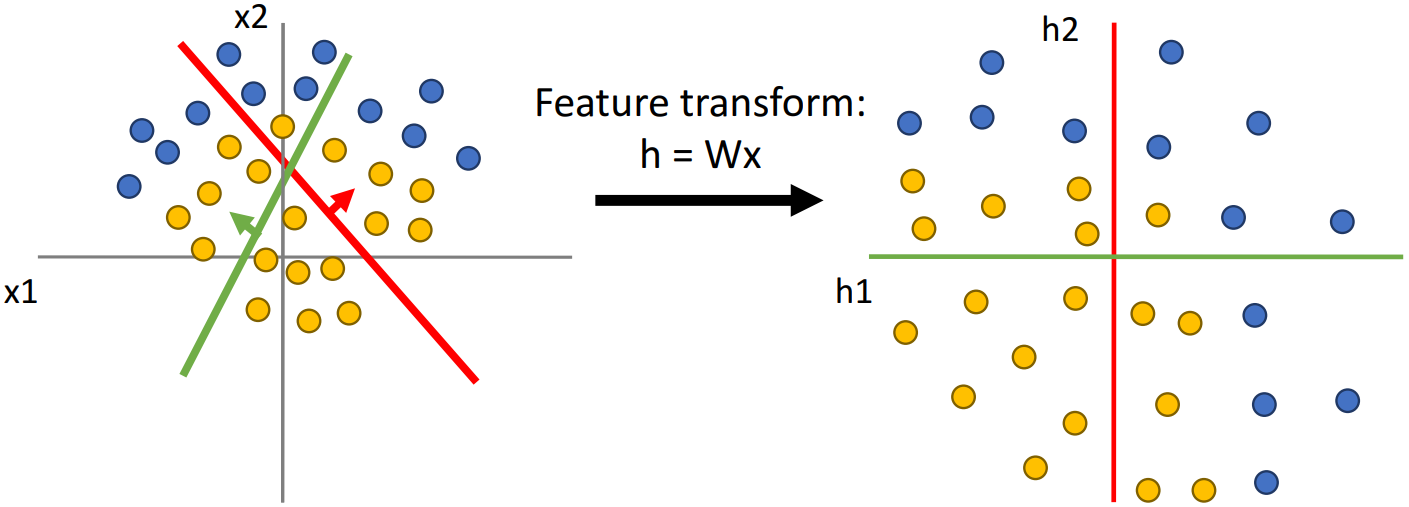
이때 공간을 단순히 선형적으로 변환한다면, 위 그림과 같이 Feature Space를 어떤 방식으로 구성하더라도 두 클래스를 구분할 직선을 그을 수 없다.
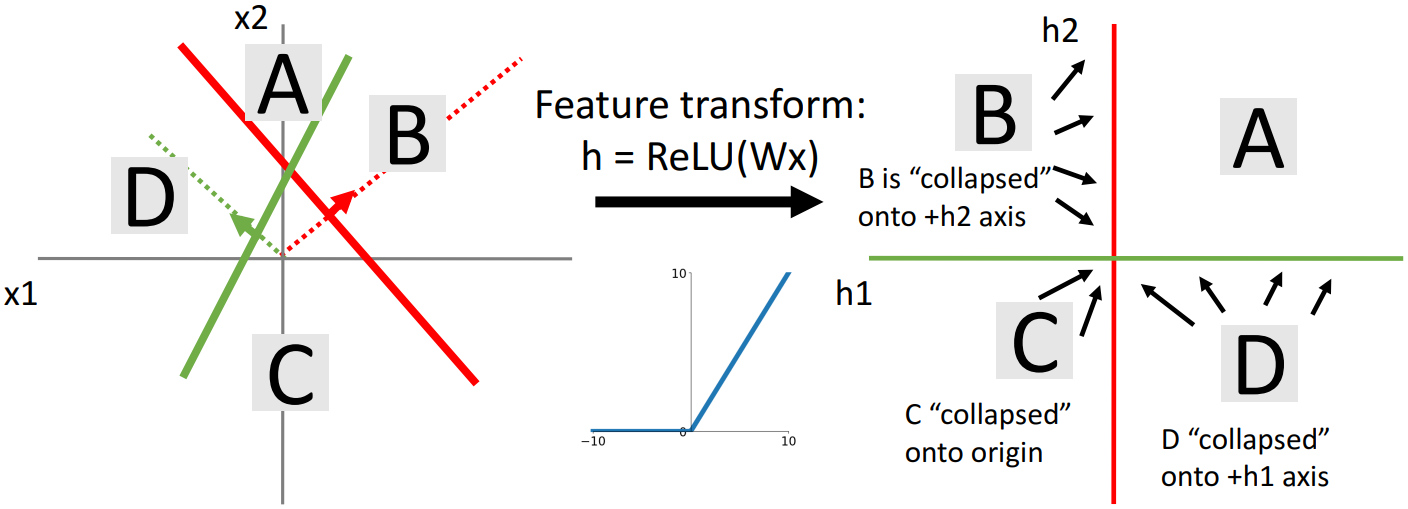
ReLU 함수를 함께 사용하면 좌표평면을 비선형적으로 변형시킬 수 있게 된다. 위 그림에서 A사분면의 경우 초록색 선과 빨간색 선을 기준으로 모두 양수인 영역이므로 점이 그대로 유지되지만, B사분면이나 D사분면의 경우 한쪽은 양수, 한쪽은 음수인 영역이므로 ReLU 함수를 거치며 점이 축으로 이동하게 된다. C사분면의 경우 둘 모두 음수인 영역이므로 점이 원점으로 모이게 된다.
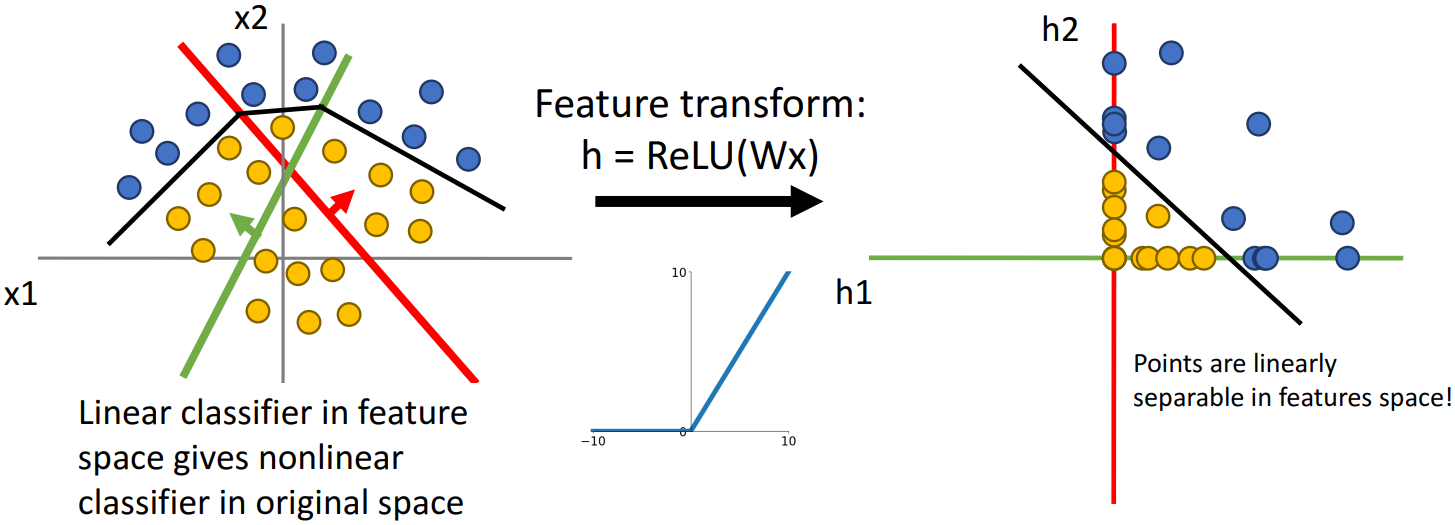
이를 그림으로 나타내면 위 그림과 같다. 비선형 함수로 인해 점이 모이는 경향성이 달라지고, Feature Space에서는 직선을 그을 수 있게 된다. 이때 이 직선을 원래의 x1, x2 좌표평면으로 되돌리면 비선형적인 경계를 나타내는 것을 볼 수 있다. 이것이 바로 Neural Network가 Feature Transform을 수행하여 비선형적인 분포를 가지는 데이터를 분류하는 방법이다.
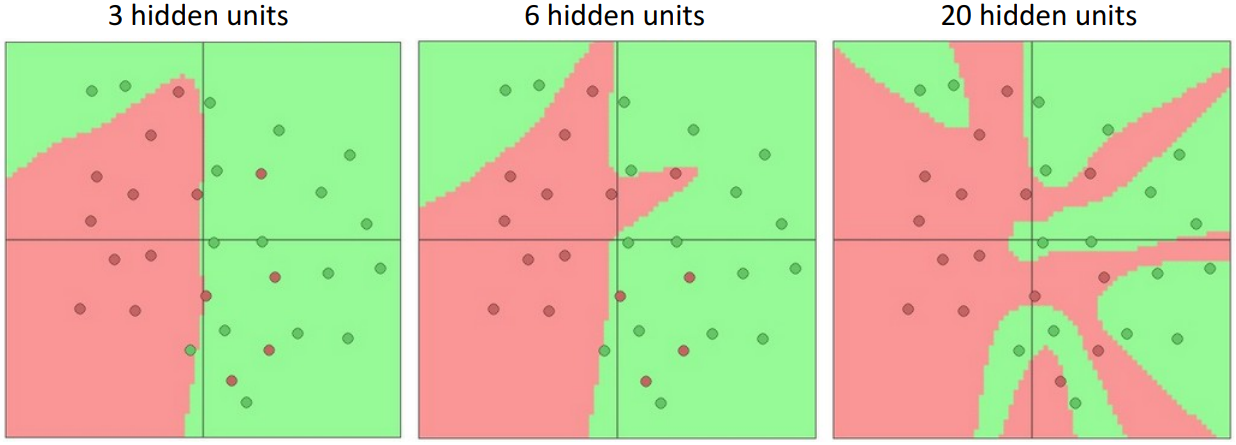
Hidden layer의 node 수가 많아지면 많아질수록 더 복잡한 feature transform을 수행할 수 있게 된다. 위 그림에서 20개의 node를 사용한 경우 모든 점에 대해 완벽하게 decision boundary를 그은 것을 확인할 수 있다. 이때 node가 많아질수록 모델이 복잡해지게 되는데, 이때 node의 수 자체를 조절하기보다는 regularization을 통해 모델의 복잡도를 조절하는 것이 일반적이다.
아래 웹사이트에서 직접 파라미터를 조정해 가며 위의 사진과 같이 decision boundary를 시각화해 볼 수 있다.
https://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html
Universal Approximation Theorem
Universal Approximation Theorem은 Neural Network가 어떤 함수든 근사할 수 있다는 정리이다. 이론적으로는 hidden layer가 한 개만 있어도 어떤 종류의 함수든 근사할 수 있다. 이 Theorem을 증명해 보도록 하자.
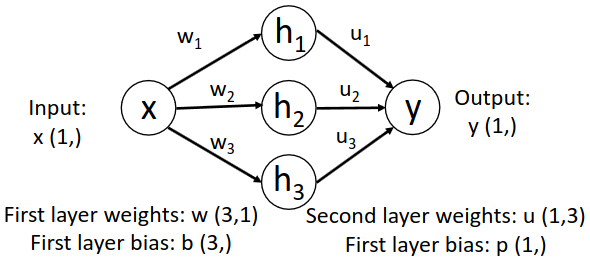
$h_i = \max(0, w_ix + b_i)$
$y = \sum u_ih_i + p$
위 그림과 같이 2-Layer, hidden node가 3개인 Neural Network를 생각해 보자. 각 node의 activation function은 ReLU다. 이때 input node에서 hidden node로 갈 때만 activation function을 거친다고 가정하면 각 node의 output은 위 수식과 같다.
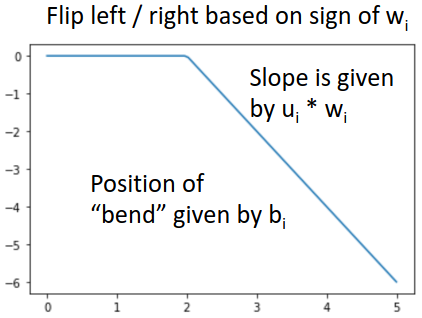
이때 $\sum$ 안의 성분인 $u_ih_i$는 풀어서 쓰면 $u_i\max(0, w_ix + b_i)$가 되는데, 이는 위 그림과 같이 ReLU 함수를 flip, shift, scale한 것과 같다. 즉 $u$, $w$, $b$를 적절히 조절하여 ReLU 함수를 좌표상 어디든 위치시킬 수 있다.
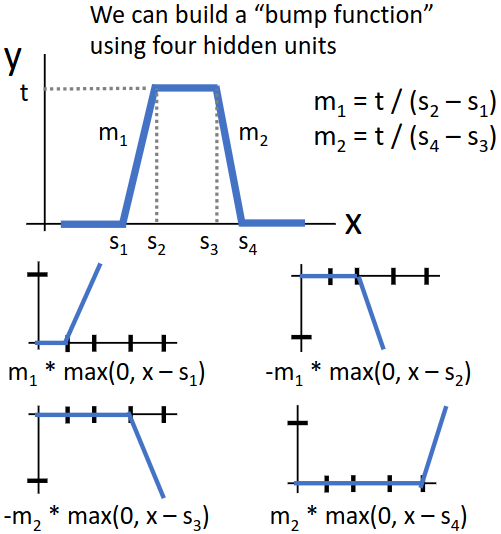
증명을 위한 트릭은, ReLU 함수 4개를 이용해 위와 같이 bump function을 만드는 것이다.
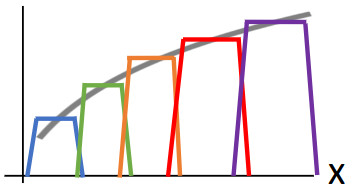
위 그림과 같이 Bump function을 여러 개 합침으로써 어떤 함수든 근사할 수 있다. 이로써 2-Layer Neural Network이기만 하면 임의의 함수를 만들어낼 수 있다는 것을 증명하였다. 이때 주의할 점은, Universal Approximation Theorem은 어떤 함수든 그 함수를 근사할 수 있는 parameter의 조합이 "존재"하기는 한다는 것을 보여줄 뿐이지 실제로 그 parameter들을 찾는 것은 또 다른 문제다.
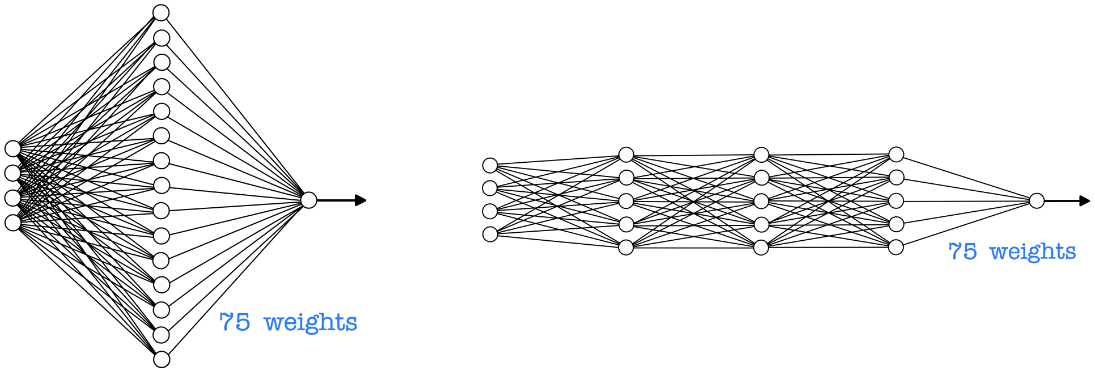
Universal Approximation Theorem에서는 hidden layer가 한 개인 경우를 살펴봤지만, 실제로는 hidden layer가 많아질수록 더 효율적으로 근사할 수 있다. 위의 그림처럼 node의 총 개수가 같다고 하더라도 deep한 network가 성능이 더 좋다고 알려져 있다.
Summary
이번 강의에서는, 우선 raw 데이터에서 feature를 추출한 다음 그 feature를 이용해 분류를 수행하는 것이 성능을 개선할 수 있다는 것을 살펴보았다. Neural Network를 여러 층으로 쌓음으로써 feature를 추출하고 분류하는 과정을 한번에 수행할 수 있다는 것을 배웠다. 또한 Activation Function의 존재로 인하여 어떤 feature 추출 함수든 근사할 수 있다는 것을 직관적인 예시와 Universal Approximation Theorem을 통해 살펴보았다.
지금까지의 흐름은 아래와 같다.
- Linear classifier 대신 Multi-Layer Neural Network 사용
- 이미지 분류 수행
- Loss Function을 이용하여 성능 평가
- Optimizer를 사용하여 $W$ 업데이트
다음 강의에서는 여러 층의 $W$와 activation function이 포함된 Multi-Layer의 경우 어떻게 모든 파라미터를 효율적으로 업데이트할 수 있을지 살펴보도록 하겠다.