Overview
뉴럴 네트워크의 학습에 필요한 구체적인 방법론들은 크게 아래의 세 가지로 분류할 수 있다. 지난 강의에서는 1. One time setup에 대해 알아보았다.
- One time setup
- Activation functions
- Data preprocessing
- Weight initialization
- Regularization
- Training dynamics
- Learning rate schedules
- Hyperparameter optimization
- After training
- Model ensembles
- Transfer learning
- Large-batch training
이번 강의에서는 2. Training dynamics와 3. After training에 대해 알아본다. Training 중과 후에 어떻게 네트워크를 세팅할 것인지에 대한 부분이다.
Learning Rate Schedules
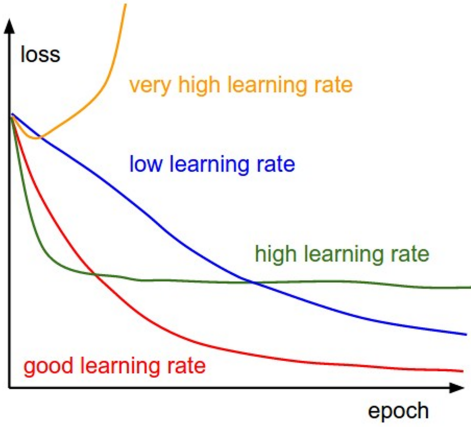
Learning rate의 크기를 어떻게 설정하느냐에 따라 아래와 같이 loss의 흐름을 결정할 수 있다. Learning rate가 크면 초반의 학습 속도가 빠르고, 작으면 후반에 더 낮은 loss로 수렴할 수 있다. 이 두 장점을 모두 취하기 위해 learning rate를 epoch에 따라 변화시키는 방법을 사용한다. 이러한 방법을 learning rate schedules라고 한다.
Step Decay
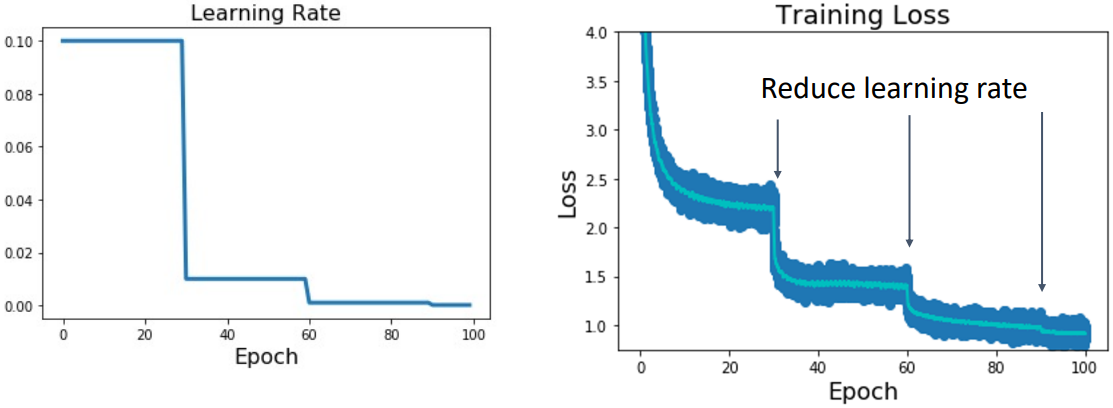
Training Loss 그래프에서, 진한 파란색은 각 mini-batch에서의 data point, 하늘색은 이동평균선을 나타낸다.
Step decay는 일정한 epoch마다 learning rate를 감소시키는 방법이다. 초기 learning rate를 설정하고, 일정한 epoch마다 learning rate에 factor를 곱하여 감소시킨다. Loss의 급격한 감소 후 plateau에 도달했을 때 learning rate를 감소시키면 loss를 추가적으로 낮출 수 있다.
하지만 Step Decay 방식은 설정해야 할 hyperparameter가 많다는 단점이 있다. 초기 learning rate뿐만 아니라 decay를 수행할 epoch, 얼마나 감소시킬 것인지 등을 모두 정해야 하기 때문에 hyperparameter tuning이 어려워진다.
Cosine Decay
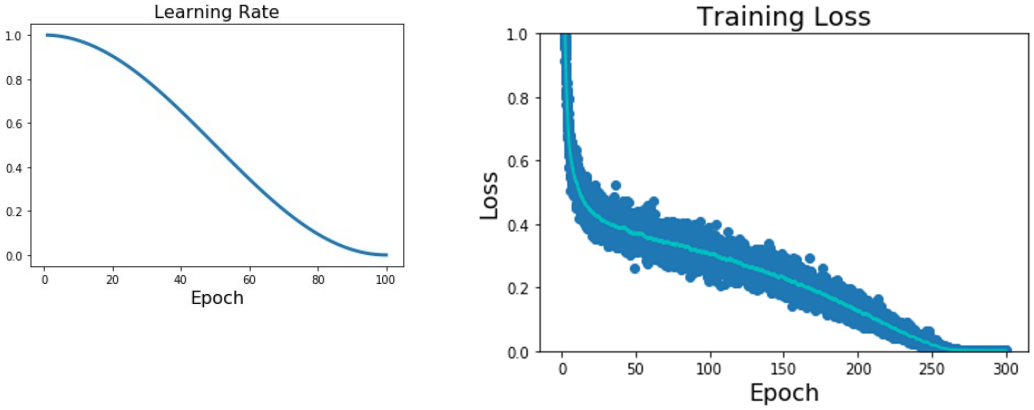
$\alpha_t = \cfrac{1}{2}\alpha_0\left(1 + \cos\left(\cfrac{t\pi}{T}\right)\right)$
Cosine decay는 위 함수를 통해 learning rate를 결정하는 방법이다. $t$는 현재 epoch, $T$는 총 epoch 수, $\alpha_0$는 초기 learning rate이다. Cosine decay는 learning rate가 연속적으로 감소하며, $T$와 $\alpha_0$는 learning rate schedule을 사용하지 않더라도 결정해아 할 hyperparameter이므로 추가적인 hyperparameter tuning이 적다는 장점이 있다. 따라서 Cosine decay는 가장 많이 사용되는 방식이며, 새로운 모델을 만들 때 우선적으로 검토하는 것이 좋다.
Linear Decay
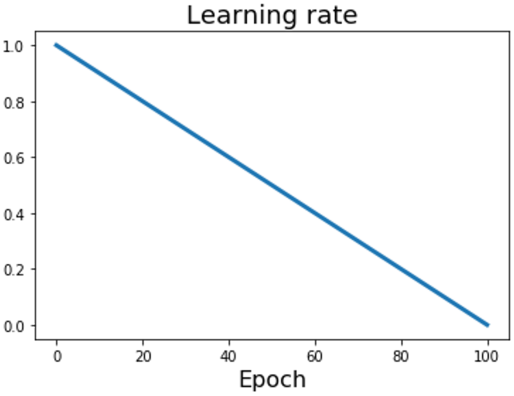
$\alpha_t = \alpha_0\left(1 - \cfrac{t}{T}\right)$
Linear decay는 Cosine decay와 유사하지만 선형적으로 감소한다. Linear decay는 컴퓨터 비전보다는 LLM 등에 많이 사용되는데, 여기에 특별한 이유가 있다기보다는 선행 연구에서 사용된 방법을 그대로 사용해 온 것이다.
Inverse Square Root Decay
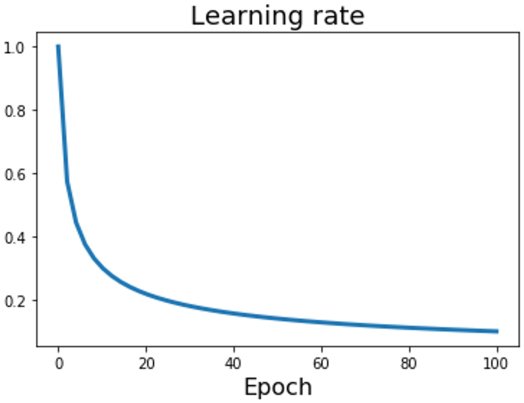
$\alpha_t = \cfrac{\alpha_0}{\sqrt{t}}$
Inverse square root decay는 transformer를 처음으로 소개한 논문에서 사용하였지만, 이외의 경우에는 많이 사용되지 않았다.
Constant
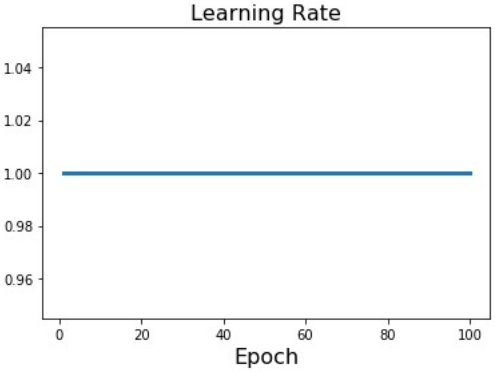
$\alpha_t = \alpha_0$
Learning rate를 상수로 두는 것은 가장 단순하면서도 성능 차이가 다른 것에 비해 크지 않다. 새로운 모델을 처음 개발할 때는 단순히 learning rate를 상수로 두고 시작하는 것이 가장 좋은데, learning rate를 조절하는 것이 모델의 성능에 핵심적인 영향을 미치지 않기 때문이다. 따라서 초반에는 모델이 정상적으로 작동하도록 만드는 것에 집중하고, hyperparameter tuning을 대략적으로 끝낸 후에 learning rate scheduling을 결정하는 것이 좋다.
Early Stopping
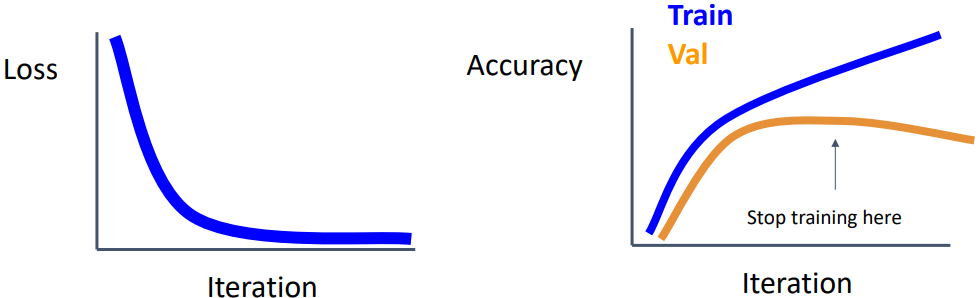
Overfitting이 시작되면 validation accuracy가 더 이상 증가하지 않는다. Early stopping은 이를 감지하고 validation accuracy가 더 이상 증가하지 않을 때 학습을 중단하는 방법이다. 이는 실제로 모델을 학습시킬 때 매우 유용한 방법이다.
Hyperparameter Optimization
주로 사용되는 hyperparameter optimization 방법으로는 grid search와 random search가 있다.
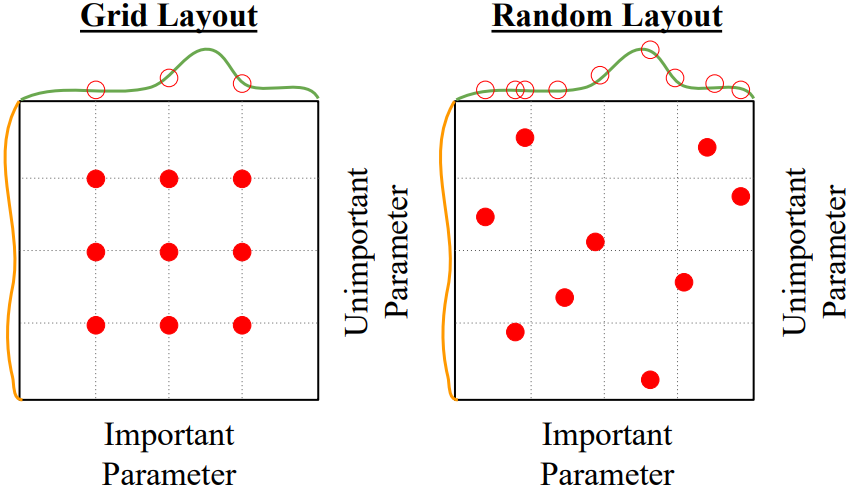
Grid Search
Grid search는 각 hyperparameter에 대해 실험을 진행할 특정 값들을 미리 정해놓고, 이들의 모든 조합을 시험하는 방법이다. 보통 $1 \times 10^{-4}$, $1 \times 10^{-3}$, $1 \times 10^{-2}$, $1 \times 10^{-1}$ 등 log linear하게 hyperparameter 값들을 설정한다. Grid search는 가장 보편적으로 이용되는 방식이지만, hyperparameter의 수가 많아질수록 필요한 test 수가 지수적으로 증가하므로 hyperparameter의 수를 잘 조절하는 것이 중요하다.
Random Search
Random search는 hyperparameter의 값들을 일정 범위 안에서 랜덤하게 선택하는 방법이다. 일반적으로 random search가 grid search보다 효율적인데, 이는 hyperparameter마다 모델의 성능에 영향을 미치는 중요도가 다를 수 있기 때문이다. 모델을 학습시키기 전에는 어떤 hyperparameter가 중요한지 알 수 없기 때문에 grid search를 수행할 경우 중요하지 않은 hyperparameter에 대해 불필요한 시간을 소비하게 된다. 반면 Random search를 이용하면 중요한 hyperparameter에 대해 sample 값을 많이 얻을 수 있다. 따라서 random search를 이용하는 것도 좋다.
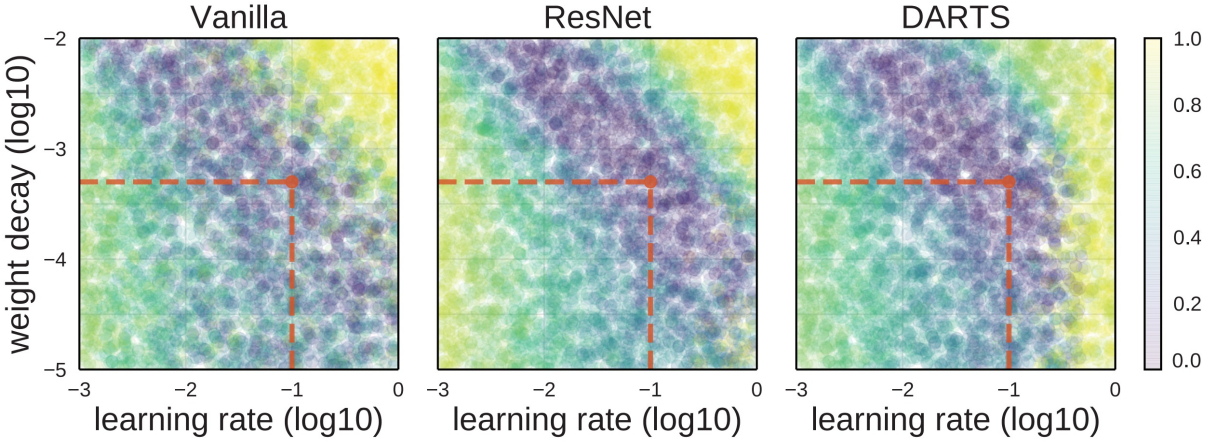
위 그림은 좌표평면의 모든 영역을 random search로 채웠을 때의 accuracy를 나타낸 것이다. 특징으로는 landscape가 한 축에 평행한 것이 아니라 두 축이 correlated되어 있다는 것과, accuracy가 급격하게 변하지는 않는다는 것이다.
Strategies for Hyperparameter Tuning
Step 1: Check Initial Loss
이는 모델을 본격적으로 학습시키기 전에 코드에 버그가 없는지 확인하는 단계이다. 데이터 입력, loss function, gradient 계산 등이 모두 제대로 작동하는지 확인한다. 보통 첫 loss 값은 직접 계산할 수 있기 때문에 이를 이용하여 1차적 검증을 진행한다. Regularization은 사용하지 않는다.
Step 2: Overfit a Small Sample
모델의 학습 과정에 문제가 없는지 확인하는 단계이다. 매우 적은 수(5~10개 mini-batch)의 데이터를 이용하여 training accuracy가 100%가 될 때까지 모델을 학습시켜 본다. 이 과정에서 모델의 architecture에는 문제가 없는지 검증할 뿐 아니라, learning rate나 weight initialization 등 중요한 hyperparameter에 대한 tuning을 진행한다. 데이터의 양이 매우 적기 때문에 수 분 내로 학습을 진행할 수 있다.
Loss가 일정 값 이하로 감소하지 않는다면 learning rate가 너무 작거나 weight initialization이 잘 되었는지 확인해야 하고, 반대로 loss가 급격히 증가한다면 learning rate가 너무 크거나 weight initialization이 잘못되었을 수 있다.
Step 3: Find LR that Makes Loss Go Down
Learning rate는 가장 중요한 hyperparameter이다. 따라서 모델이 정상적으로 학습된다는 것을 확인했다면, 전체 데이터셋에 대해 Loss를 감소시키는 learning rate를 우선 찾아야 한다. 이전 단계의 architecture를 사용하고 L2 regularization(Weight decay)를 약하게 사용하여 약 100 iteration 내에 loss를 급격히 감소시키는 learning rate를 찾는다. 보통 $1 \times 10^{-4}$, $1 \times 10^{-3}$, $1 \times 10^{-2}$, $1 \times 10^{-1}$ 등을 시험해 본다. 이 또한 수 분 내로 결과를 보고 모델을 수정할 수 있다.
Step 4: Coarse Grid, Train For ~1-5 Epochs
이 단계에서는 모델을 실제로 좋은 성능으로 학습시켜 보는 단계이다. 이전 단계에서 사용한 learning rate와 weight decay를 기준으로 grid search를 진행한다. Weight decay로는 $1 \times 10^{-4}$, $1 \times 10^{-5}$, $0$을 시도해 보면 좋다. 학습은 1~5 epoch 정도를 진행시켜 본다. 따라서 수 시간 내로 결과를 확인할 수 있다.
Step 5: Refine Grid, Train Longer
이전 단계에서 가장 좋은 성능을 보인 hyperparameter들을 기준으로 더욱 세밀한 grid search를 진행한다. 이번에는 10~20 epoch 정도로 오래 학습을 진행시켜 본다. 여기까지 learning rate decay는 사용하지 않는다.
Step 6: Look at Learning Curves
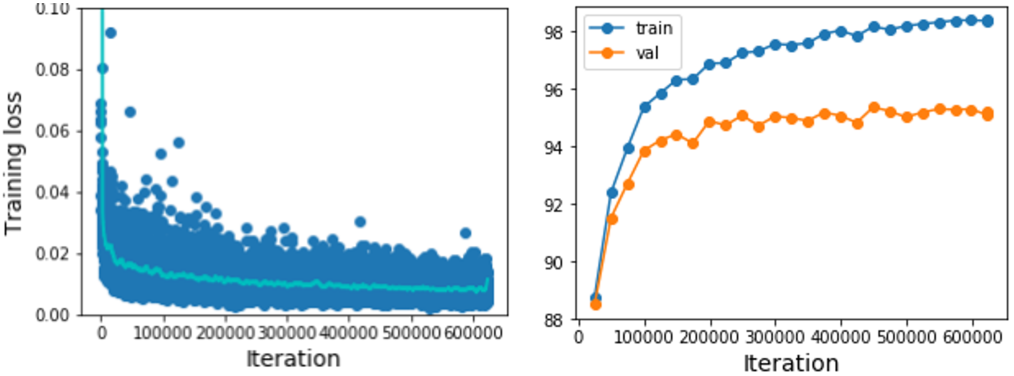
학습 과정에서 loss와 accuracy 그래프를 확인하는 것이 중요하다. Loss 그래프에서는 위의 왼쪽 그래프와 같이 각 data point의 평균과 분산을 대략적으로 확인할 수 있고, accuracy 그래프에서는 오른쪽 그래프와 같이 training set과 validation set에서의 accuarcy를 비교할 수 있다. 이를 통해 학습이 잘 이루어지고 있는지, overfitting이 일어나지 않는지 등을 확인할 수 있다. 아래 그림들은 위 두 그래프에서 나타날 수 있는 여러 문제 상황들을 보여 준다.
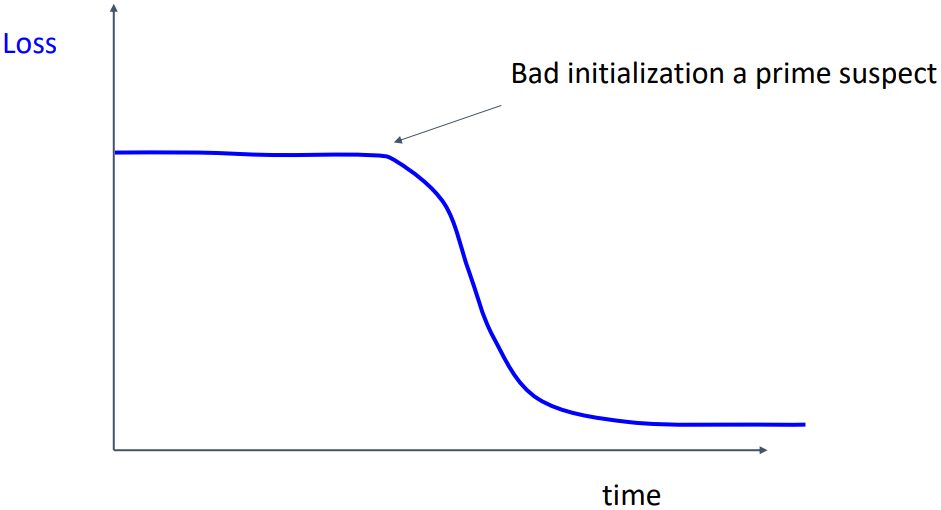
위 그래프처럼 학습 초반에는 loss가 일정하다가 어느 순간 감소하는 경우, weight initialization이 잘못되었거나 초기 learning rate가 너무 작게 설정되었을 수 있다.
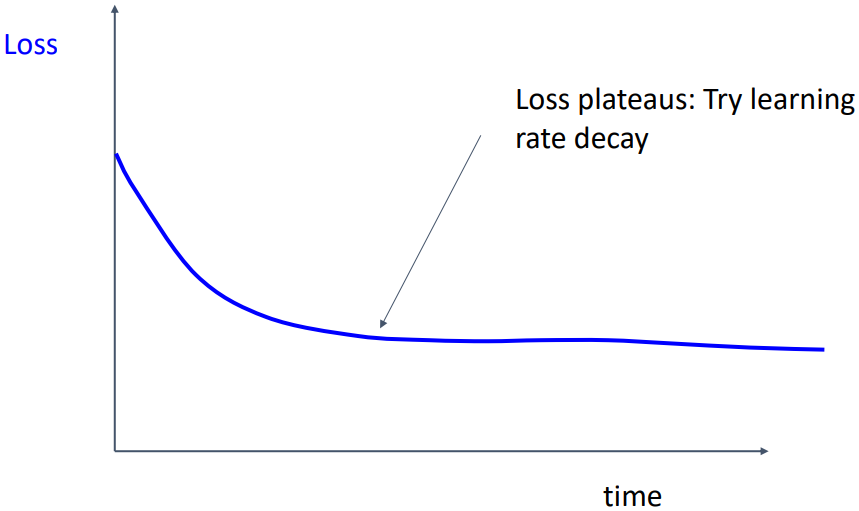
위 그래프처럼 loss가 plateau에 도달하는 경우, learning rate decay를 적용해볼 수 있다.
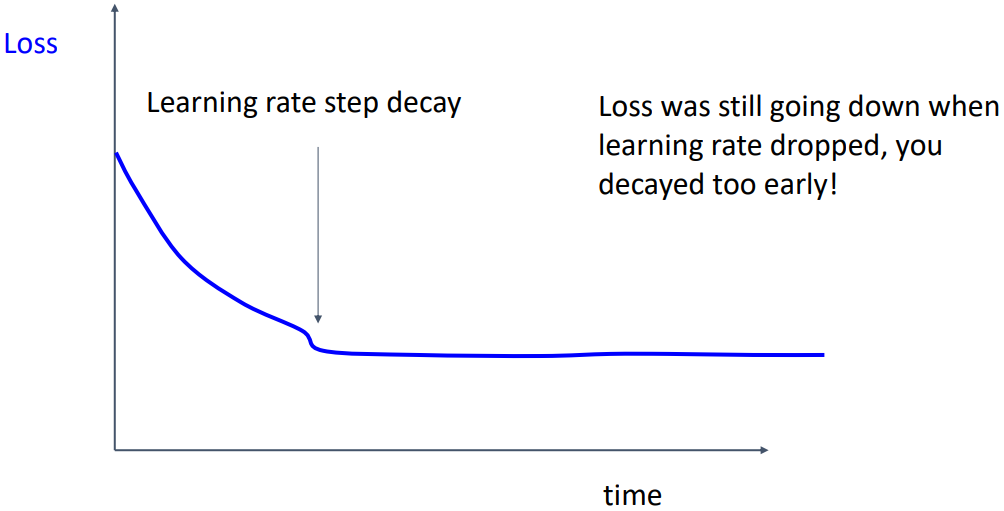
반대로 위 그래프처럼 loss가 아직 감소 중인데 갑자기 크게 감소하는 경우, learning rate decary가 너무 빨리 수행되었다고 판단할 수 있다. 다만 cosine decay와 같이 연속적인 decay는 이러한 현상을 발견하기 어렵기 때문에 초반에 적용하는 것을 주의해야 한다.
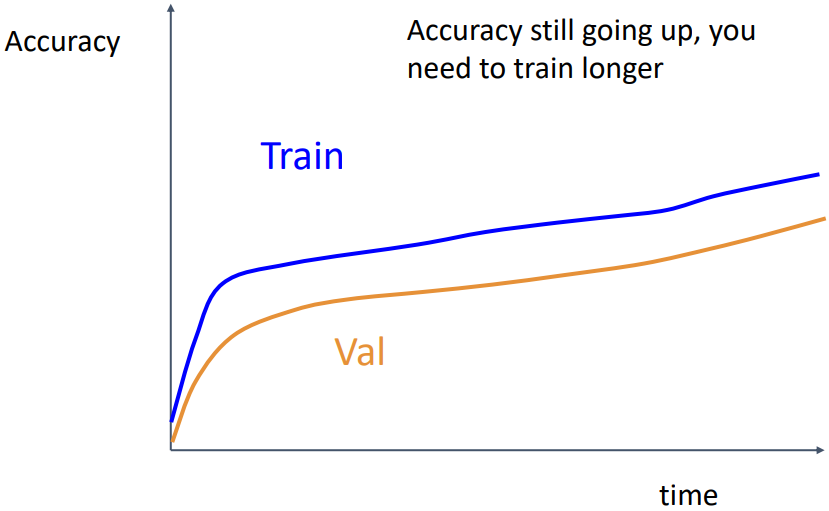
위 그래프는 train과 validation accuracy가 일정 gap을 가지고 모두 증가하는 경우이다. 이는 모델이 정상적으로 학습되고 있다는 뜻이며, 수렴할 때까지 기다리면 된다.
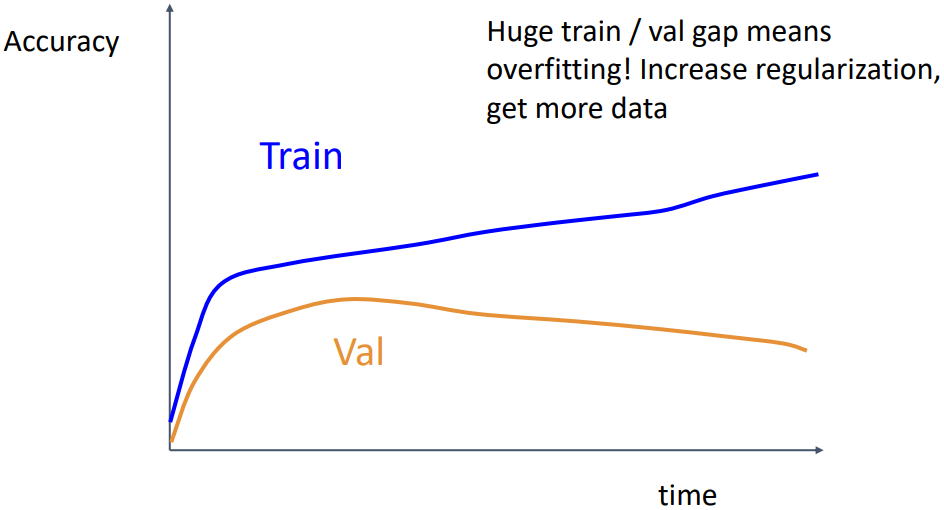
위 그래프에서는 train accuracy는 계속 증가하지만 validation accuracy는 일정 epoch 이후부터 감소하는 경우이다. 이는 모델이 overfitting되고 있다는 뜻으로, regularization을 강화하거나, 데이터의 양을 늘리거나, 모델의 크기를 줄이는 것으로 해결할 수 있다.
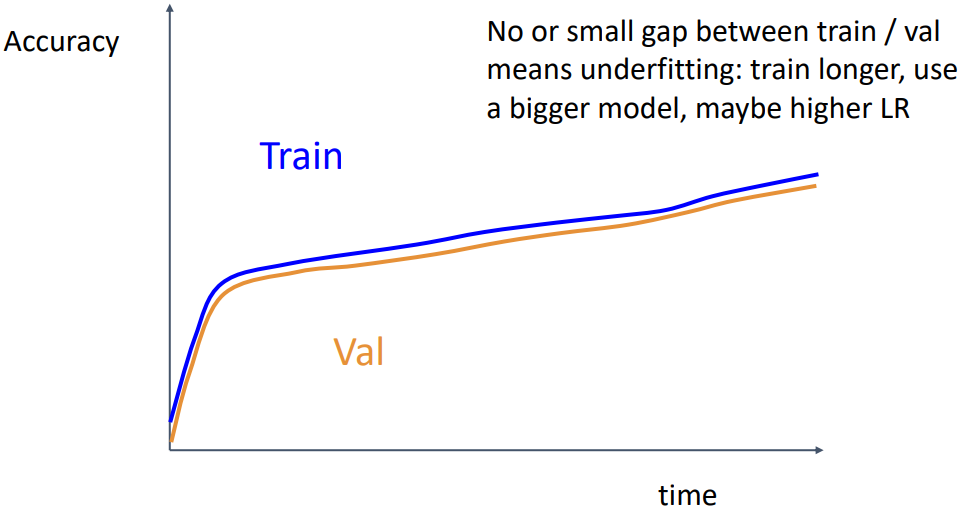
마지막으로, 위 그래프에서는 train accuracy와 validation accuracy가 가까이 붙어서 증가하는 경우이다. 이는 모델이 underfitting되고 있다는 뜻으로, 더 오래 학습시켜 보거나, 모델의 크기를 키우거나, learning rate를 증가시키거나, regularization을 줄이는 것으로 해결할 수 있다.
Step 7: Repeat Step 5-6
마지막 단계로는, 원하는 성능을 얻을 때까지 Step 5와 6을 반복한다.
Track Ratio of Weight Update / Weight Magnitude
학습이 잘 되고 있는지를 확인할 수 있는 또 다른 방법은 weight update와 weight magnitude의 비율을 확인하는 것이다. Weight 자체의 크기 대비 업데이트되는 양이 0.1% 정도가 되는 것이 적당하다. 다만 이 비율은 모델이나 task에 따라 달라질 수 있다.
Model Ensembles
Model ensemble은 여러 모델을 독립적으로 학습시키고, 이들의 결과를 평균내어 사용하는 방법이다. 이는 모델의 성능을 향상시키는 방법 중 하나이다. Model ensemble을 사용하면 대부분의 경우 2% 정도의 성능 향상을 얻을 수 있다.
한 가지 trick으로, 모델 자체를 여러 개 학습시키는 대신 하나의 모델을 훈련시키는 과정에서 특정 순간마다 모델의 snapshot을 저장해 두었다가 이들을 ensemble하여 사용하는 것이다. 다만 여러 모델을 독립적으로 ensemble하는 방법이 매우 흔하게 사용되는 것에 비해 snapshot 방식은 실제로 많이 사용되지는 않는다.
다른 trick으로 Polyak averaging이 있다. Polyak averaging은 test 시에 모델의 weight 자체를 사용하는 것이 아닌, train 시에 구한 weight의 이동 평균을 대신 사용하는 방법이다. 이 방법을 통해 직전 특정 개수의 모델을 ensemble한 효과를 얻을 수 있다. 이 방법은 생성 모델에서 출력을 smooth하게 만드는 데 사용될 수 있다.