Overview
이번 강의에서는 지난 Lecture 8: CNN Architectures I 강의에 이어, ResNet 이후에 등장한 CNN Architectures에 대해 알아본다. ResNet 이후로는 모델의 정확도뿐 아니라 모델의 크기, 연산량 등 복잡도와의 trade-off를 개선시키는 연구가 진행되었다.
모델의 복잡도를 측정하는 방법들은 아래와 같다.
- 파라미터 수
- 연산 횟수 (FLOPs, Floating Point Operations)
- 실행 시간 (Runtime)
이때, 연산 횟수의 경우 대부분의 컴퓨터 비전 논문에서는 conv layer에서의 곱셈 연산 1회, 덧셈 연산 1회를 합쳐 1FLOP이라 간주한다.
단순히 모델이 커지면 정확도를 향상시킬 수 있다는 것을 알았기 때문에, 무작정 큰 모델로 최대의 정확도를 내기보다는 모바일 기기 등 제한된 컴퓨팅 파워를 가진 환경에서도 효율적으로 동작할 수 있는 모델을 개발하려는 연구가 진행되었다. 제한된 컴퓨팅 환경일수록 정확도와 모델의 복잡도 간 trade-off가 중요해졌다.
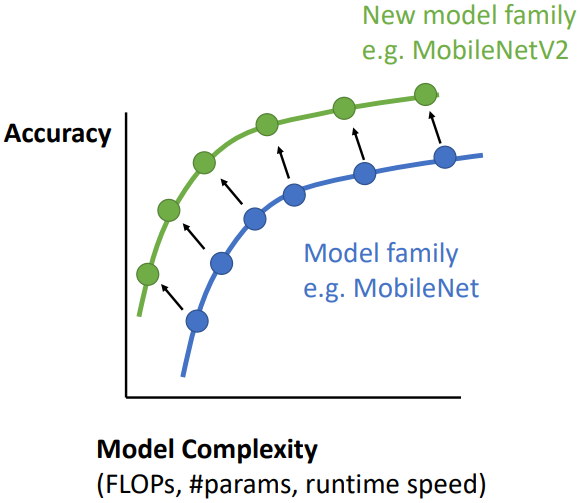
이제는 어떤 특정한 모델이 최대의 정확도를 내는지를 보는 것이 아닌, 아키텍쳐 전체의 성능을 비교하기 시작했다. 이때 위와 같은 그래프를 주로 사용하는데, 한 model family의 곡선 전체가 다른 family들 보다 좌상향된 위치에 있을 때 정확도와 복잡도 간 trade-off를 개선시킨 좋은 모델인 것으로 평가받게 되었다.
Grouped Convolution
최근 연구된 CNN Architectures들을 살펴보기 전에, 이러한 연구들에 적용되는 새로운 conv layer 기법인 Grouped Convolution에 대해 알아보자.
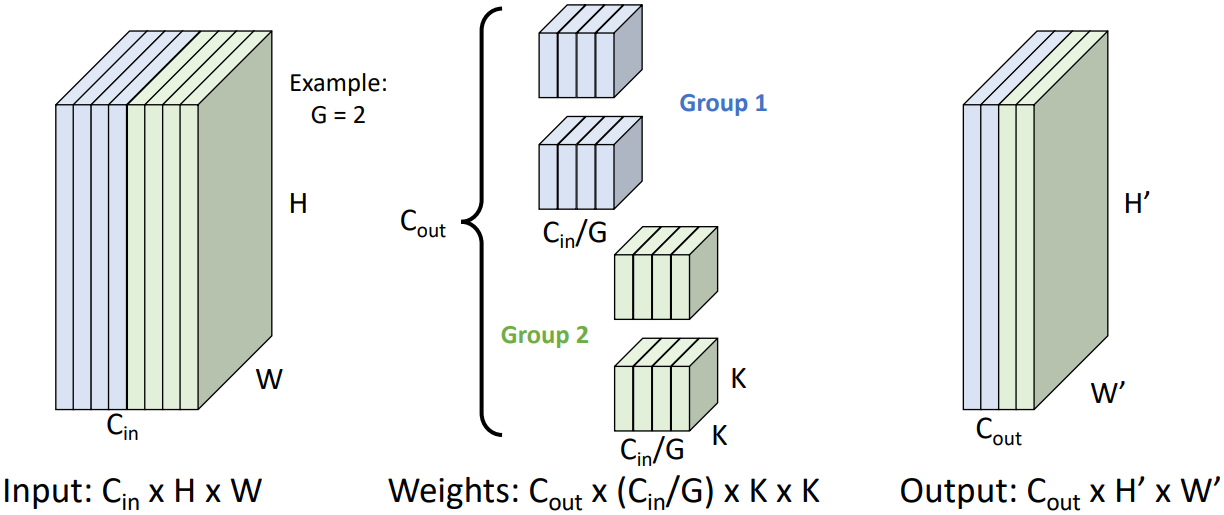
Grouped convolution은 ResNet 이후 모델들에서 주요하게 사용된 기법으로, 연산량을 크게 줄이는 역할을 한다. 우선 인풋 채널을 $G$개의 그룹으로 나눈다. $G$는 hyperparameter로, 위 그림에서는 $G = 2$로 설정하였다. 이후 각 필터의 크기를 $C_{in} \times K \times K$가 아닌 $C_{in}/G \times K \times K$로 설정하고, 필터들을 $G$개의 그룹으로 나눈다. 즉, 각 그룹당 필터의 개수는 $C_{out}/G$개가 된다. 이후 convolution을 진행하는데, 각 그룹에 속한 필터는 각 그룹에 해당하는 채널에 대해서만 convolution을 수행한다. 이를 통해 최종적으로 $C_{out}$개의 activation map을 얻는다.
Grouped convolution의 FLOPs를 계산해 보면 아래와 같다.
$C_{out} \times C_{in} \times K^2 \times H' \times W' / G$
기본 convolution의 FLOPs는 아래와 같다.
$C_{out} \times C_{in} \times K^2 \times H' \times W'$
따라서 Grouped convolution은 기본 convolution에 비해 $1/G$배로 연산량을 줄인다는 것을 알 수 있다.
Special Case: Depthwise Convolution
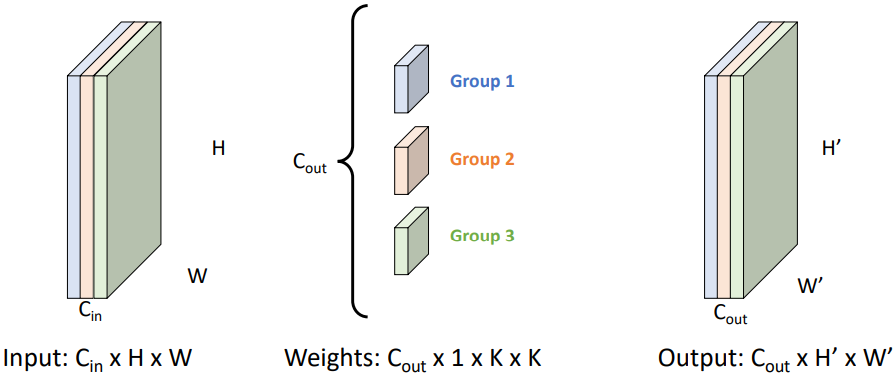
Depthwise convolution은 Grouped Convolution의 특수한 경우로, $G = C_{in}$인 경우이다. 즉, 각 채널 하나씩에 대해 필터를 적용하는 것이다. 이 경우, 필터의 크기는 $1 \times K \times K$가 된다. $G = C_{in} = C_{out}$로 설정하여 각 그룹당 하나의 필터만을 사용하는 것이 흔하지만, 각 그룹에 여러 개의 필터를 사용할 수도 있다.
Depthwise convolution의 경우 $G = C_{in} = C_{out} = C$로 놓으면 FLOPs는 아래와 같다.
$C \times K^2 \times H' \times W'$
New Architectures
이제 ResNet 이후 등장한 CNN Architectures들에 대해 대략적인 시간 순서대로 알아보자. 이러한 모델들은 ResNet의 성능을 유지하면서도 모델의 크기와 연산량을 줄이는 방향으로 연구되었다.
ResNeXt (2017)
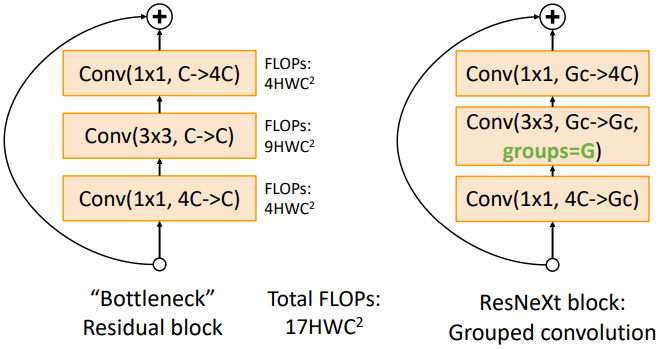
ResNeXt는 ResNet에 Grouped Convolution을 사용하여 모델의 복잡도를 줄인 모델이다. 중간 3x3 conv layer에 group = $G$를 추가하였다. $G$와 $c$는 별개의 hyperparameter이다. 이때 기존의 Bottleneck residual block의 FLOPs를 계산해 보면 $17HWC^2$가 된다. ResNeXt block의 경우 FLOP을 어떻게 계산할까?
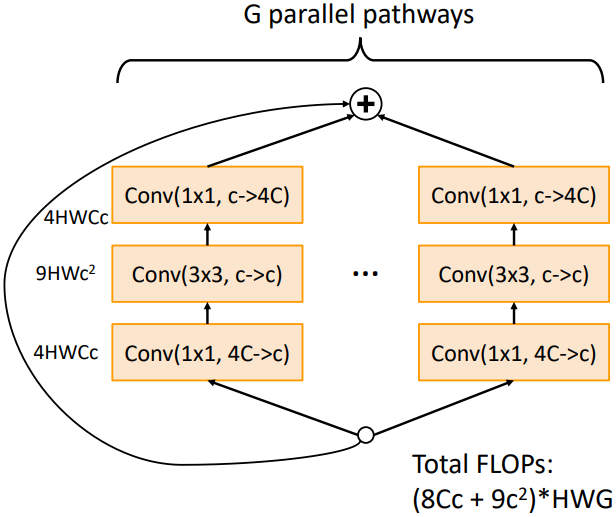
ResNeXt block은 위 그림처럼 residual block 자체를 G개로 나누어 수행하는 것과 동일하다. 기존의 residual block과 다른 점은 3x3 conv layer에서 C가 아닌 c개의 채널을 이용한다는 점이다. 이를 위해 앞뒤 1x1 conv layer에서는 이에 맞게 채널 수를 변환해 준다.
이 다이어그램에서 FLOPs를 계산해 보면 아래와 같다.
$(8Cc + 9c^2) \times HWG$
따라서 아래와 같이 위의 두 FLOPs 식을 같다고 놓고 적절한 $G$와 $c$ 값을 구하면 연산량이 동일하면서 group 수는 다른 ResNeXt 모델을 만들 수 있다.
$17HWC^2 = (8Cc + 9c^2)HWG$
이 과정을 통해, 연산량을 유지시킨 상태에서 group 수를 증가시키며 적절한 $c$를 구해 만든 모델들의 정확도를 비교해 보았을 때, group 수가 증가할수록 정확도 또한 증가하는 것을 아래의 표를 통해 확인할 수 있다.

Squeeze-and-Excitation Networks (SENet) (2018)
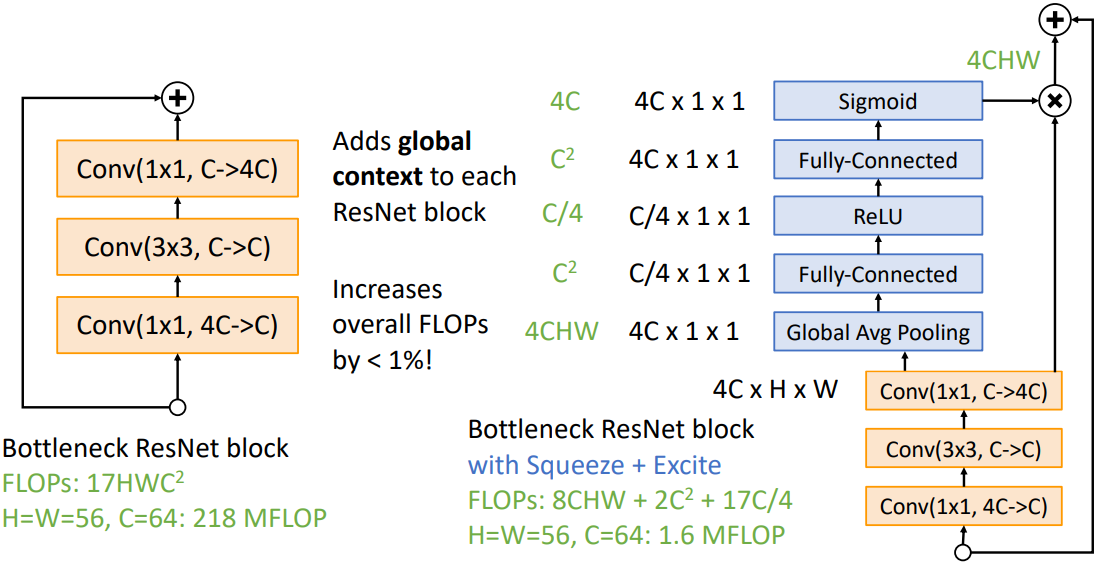
SENet은 ResNet의 확장된 버전으로, 기본 Residual block에 추가적인 squeeze and excite module을 더한 것이다. 이 모듈은 우선 residual block의 출력을 global average pooling하여 크기가 채널의 개수인 벡터를 얻는다. 이후 이를 2개의 FC layer에 통과시킨다. 이때 squeeze and excite module의 마지막 activation function이 sigmoid이기 때문에 최종 결과는 0과 1 사이의 값이 되고, 이를 채널별 '중요도'로 해석한다. 최종적으로 이를 residual block 출력의 각 채널에 곱해주어 채널별 중요도를 반영한 출력을 얻는다.
SENet이 유용한 이유는 해당 residual block이 이미지의 모든 영역을 참조할 수 있도록 하기 때문이다. Receptive field를 이미지 전체 영역으로 넓히기 전이더라도 global average pooling을 통해 이미지 영역 전체에 대한 정보를 얻을 수 있다.
이러한 큰 이점에도 불구하고 추가적인 연산량의 증가는 그렇게 크지 않다. 위 그림에서 볼 수 있듯 squeeze and excite module의 FLOPs는 아래와 같다.
$8CHW + 2C^2 + 17C/4$
각 변수에 일반적으로 사용되는 값들을 아래와 같이 대입하면,
$H = W = 56, \quad C = 64$
SENet의 연산량은 1.6MFLOPs가 된다. 같은 값을 대입했을 때 residual block 하나의 연산량이 218MFLOPs이라는 것을 감안하면 SENet의 추가적인 연산량은 극히 일부분이라는 것을 알 수 있다.
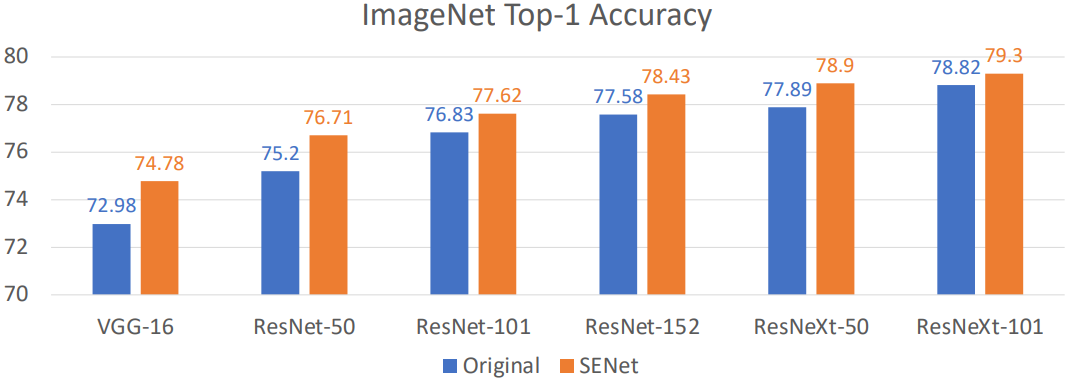
SENet은 어떤 모델에 적용되더라도 1~2%의 정확도 향상을 가져올 수 있다. 이로 인해 SENet은 다양한 최신 모델에 흔히 적용되는 architecture다.
MobileNet (2017)
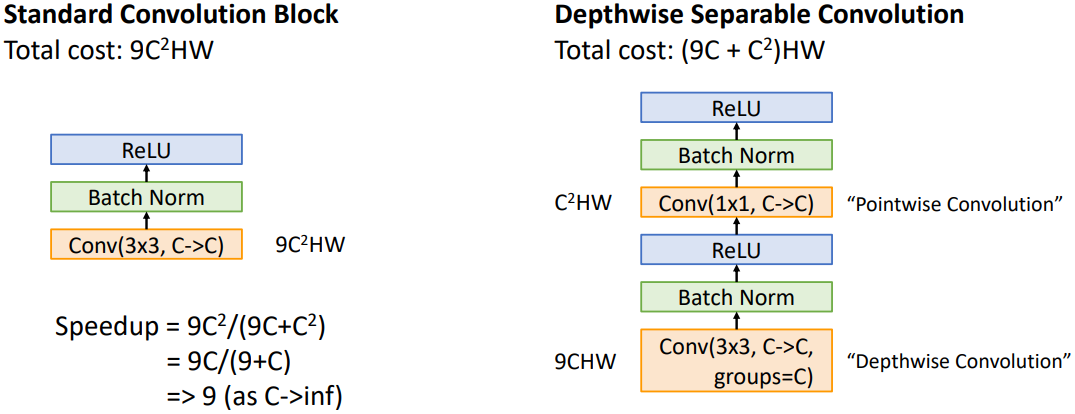
MobileNet은 ResNet 형태 대신 단순히 layer들을 쌓은 VGG 형태를 채택하고 있다. 기존의 3x3 convolution 대신 Depthwise Convolution과 1x1 Pointwise Convolution을 연속으로 사용하여 모델의 복잡도를 줄였다. 각 채널에 대해 필터를 적용하는 Depthwise Convolution과 각 채널을 선형 결합하는 Pointwise Convolution을 합친 것을 Depthwise Separable Convolution이라 하는데, 이를 통해 기존의 convolution에 비해 연산량을 크게 줄일 수 있다. 연산량을 계산해 보면 $C^2$ 항의 계수가 9에서 1로 줄어든 것을 확인할 수 있다.
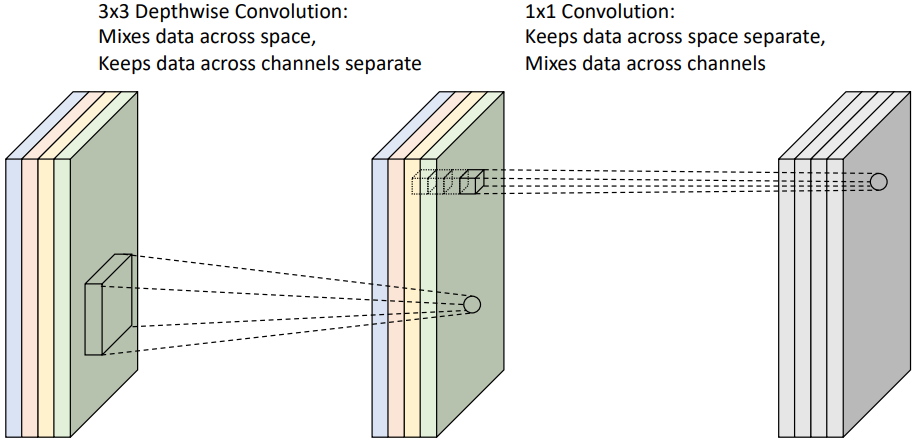
Depthwise Separable Convolution을 시각화하면 위와 같다. Depthwise Convolution은 한 채널 안에서 특정 영역의 정보를 종합하는 것이고, Pointwise Convolution은 특정 픽셀 위치에서 모든 채널을 관통하여 정보를 종합하는 것이다.
MobileNetV2 (2018)

MobileNetV2는 MobileNet과는 달리 ResNet 형태를 채택하였고, Inverted Bottleneck과 Linear Residual이라는 두 가지 contribution을 가지고 있다. 위 그림은 기존 ResNet의 bottleneck block(왼쪽)과 MobileNetV2 block(오른쪽)을 비교한 것이다.
우선 Inverted Bottleneck에 대해 살펴보면, 첫 번째 1x1 Convolution에서 채널 수를 1/4로 줄이는 것이 아닌 t배 증가시키고 있다. 이후 3x3 Convolution에서는 기존 block과는 다르게 Depthwise Convolution을 사용하고 있다. 이후 1x1 Convolution에서 다시 채널 수를 C로 줄이게 된다.
또한 MobileNetV2는 residual block 이후에 ReLU가 존재하지 않는데, 이를 Linear Residual이라 한다.
연산량을 계산해 보면 기존의 Residual block은 $17HWC^2$, MobileNetV2 block은 $2tHWC^2 + 9tHWC$가 된다. 따라서 두 식을 같다고 놓고 방정식을 풀면 연산량을 유지시키는 t를 구할 수 있고, 성능을 비교해 볼 수 있다.
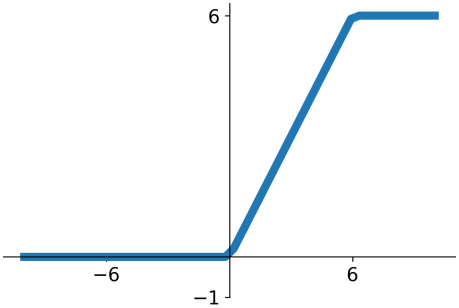
$ReLU6(x) = \begin{cases} 0 & \text{if } x < 0 \\ x & \text{if } 0 \leq x \leq 6 \\ 6 & \text{if } x > 6 \end{cases}$
마지막 특징으로, MobileNetV2는 ReLU 대신 ReLU6를 사용하고 있다. ReLU6는 ReLU와 비슷하지만 출력값이 6을 넘어가지 않는다는 특징을 가지고 있다. 이는 16비트, 8비트 등 낮은 비트 수의 소수점 연산만을 지원하는 모바일 환경에서도 오버플로우 없이 출력을 안정적인 범위 안으로 유지시키기 위함이다.
ShuffleNet (2018)
ShuffleNet은 MobileNet에서 사용된 Depthwise Separable Convolution에서, 1x1 convolution 없이 depthwise convolution만으로 채널간 데이터를 종합하는 방법을 제안하는데, 이를 Channel Shuffle이라 한다. Channel Shuffle은 말 그대로 각 그룹에 속하는 채널들을 특정한 규칙으로 섞어 주는 것이다.
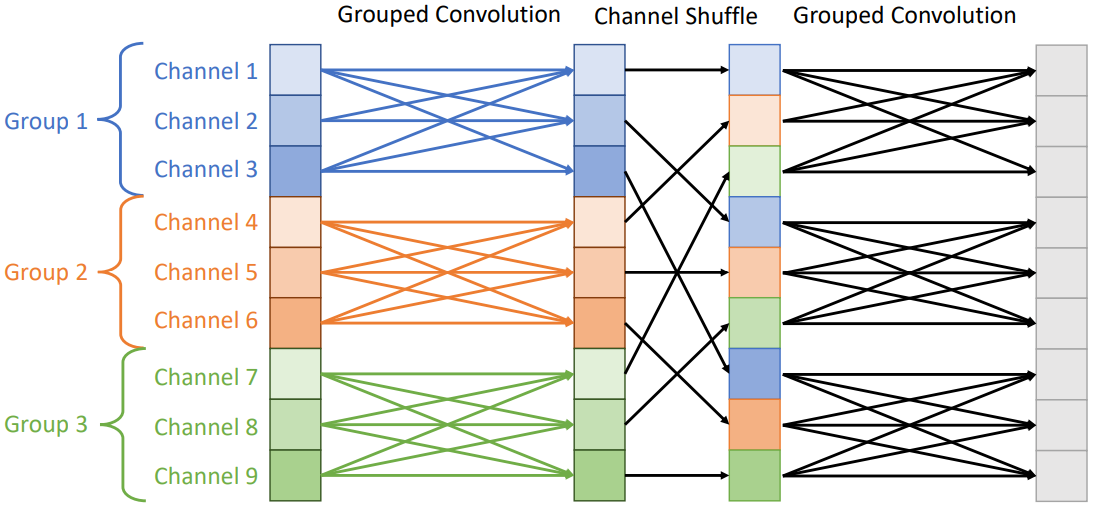
위 그림과 같이 하나의 depthwise convolution 이후에 channel shuffle을 넣어 각 그룹에 속하는 채널들을 섞어 준다면, 그 다음 depthwise convolution에서는 다른 채널들과 정보를 공유할 수 있게 된다. 이를 통해 채널 간 정보를 공유하면서도 모델의 복잡도를 줄일 수 있다.
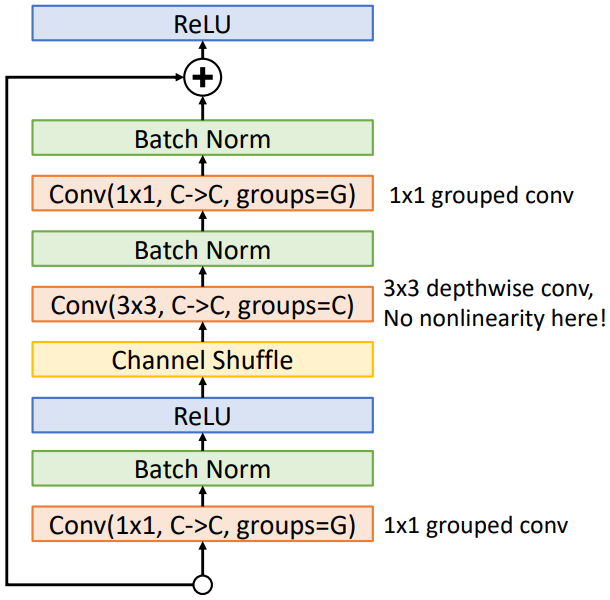
이러한 Channel Shuffle을 사용한 ShuffleNet의 구조는 위 그림과 같다. ResNet에서 기본 구조를 가져왔지만 모든 conv layer가 grouped되어 있다는 것이 차이점이다. Channel shuffle을 통해 ungrouped 1x1 conv layer 없이도 전체 채널 간 정보를 공유할 수 있기 때문에 모든 conv layer를 grouped conv로 설정하여 연산량을 줄일 수 있었다.
첫 번째 conv layer 이외에는 ReLU layer가 없다는 것도 특징인데, 이는 empirical한 부분이다.
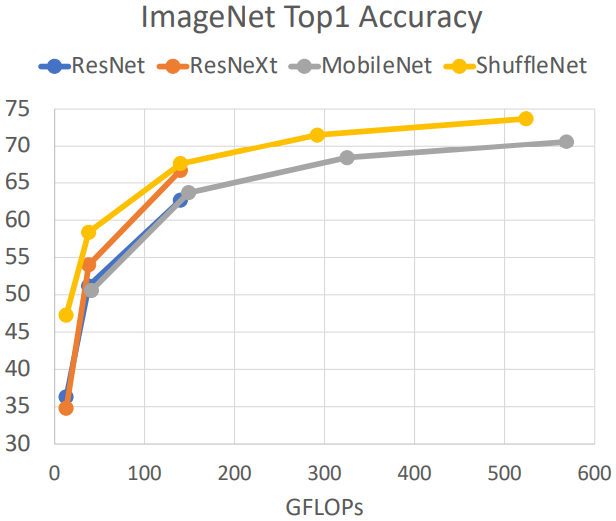
위 그래프는 지금까지 등장한 여러 모델들의 정확도와 연산량을 나타낸 것이다.
Neural Architecture Search (NAS) (2017)
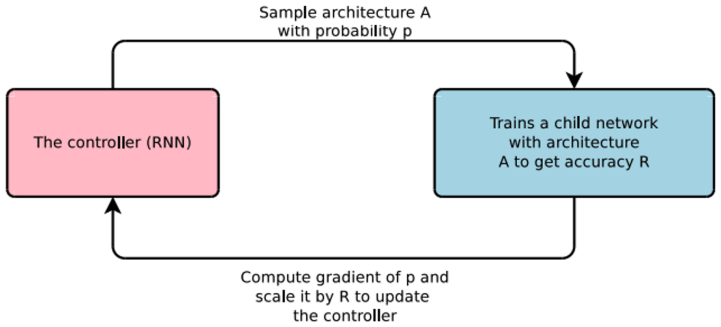
NAS는 사람이 직접 block을 설계하는 것이 아닌, 강화학습을 이용해 자동으로 block을 설계하는 방법이다. 각 layer마다 사용할 layer의 종류, 필터의 크기 등이 모두 학습의 대상이 된다. 강화학습 모델이 찾아낸 block을 아래 사진과 같이 각 cell 안에 삽입하여 전체 모델을 만들게 된다. 이렇게 모델을 만들어 훈련시키고 성능을 측정하는 과정을 반복하며 강화학습 모델이 학습하게 되고, 최종적으로 가장 성능이 좋은 block design을 찾아낸다.
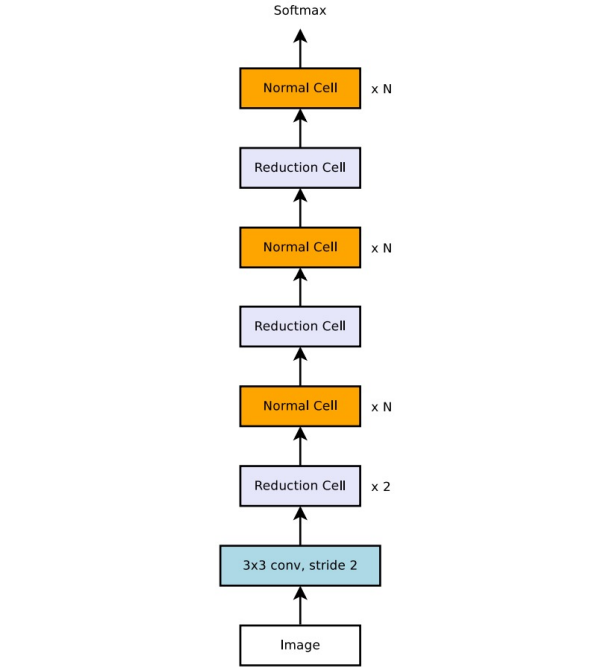
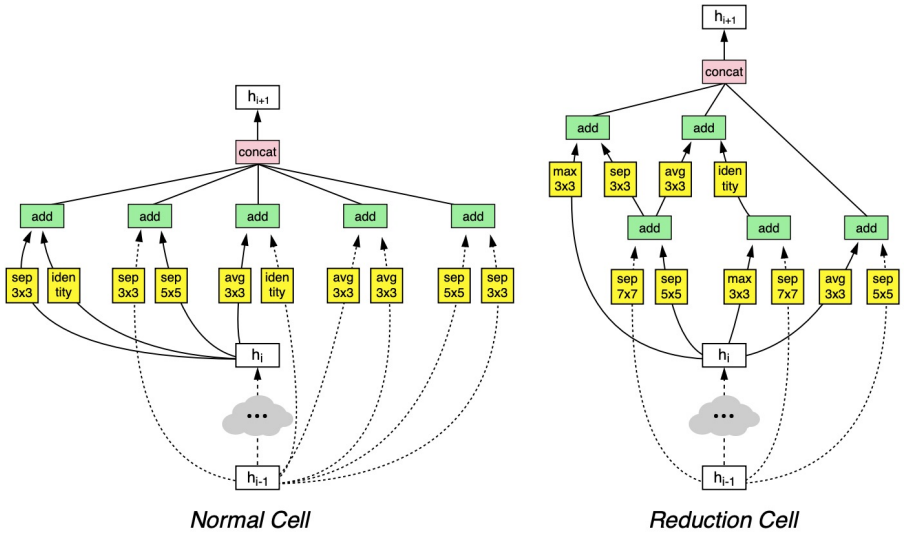
아래 그림은 실제로 NAS를 이용해 찾아낸 cell의 구조이다. 성능이 동시대의 다른 모델들보다 뛰어난 것은 맞지만 cell을 이렇게 구성한 근거는 전혀 알 수 없다는 것과, 강화학습 모델을 훈련시키는 데 엄청난 시간이 든다는 것이 단점이다.
NAS는 MobileNetV3을 설계하는 데 사용되었는데, MobileNetV2보다 더 높은 정확도를 보이면서도 연산량을 줄일 수 있었다.
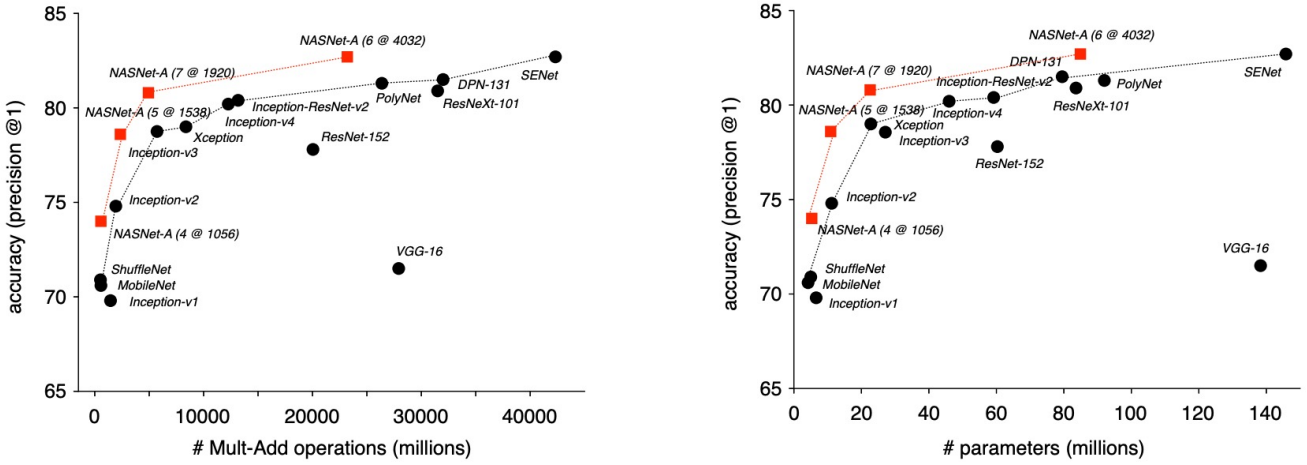
다른 모델들과 비교한 NAS 활용 모델의 성능은 위 그림과 같다. 다른 모델과 비교하여 복잡도 대비 정확도가 높은 것을 확인할 수 있다.
EfficientNet (2019)
NAS 출현 이후, NAS를 이용해 찾아낸 모델을 기초로 어떻게 더 모델의 크기와 정확도를 늘릴 수 있을지에 대한 연구가 진행되었다. 이를 Model Scaling이라 하는데, 모델의 width, depth, 이미지의 resolution 등을 증가시키게 된다.
EfficientNet은 이러한 Model Scaling의 방법론을 체계화한 모델이다. 그 순서는 아래와 같다.
- NAS를 통해 Baseline이 될 모델을 찾는다.
- Baseline 모델의 width, depth, resolution을 증가시킬 factor를 찾는다. Depth factor는 $\alpha$로, width factor는 $\beta$로, resolution factor는 $\gamma$로 표기한다. $\alpha, \beta, \gamma \geq 0$이고 $\alpha\beta^2\gamma^2 \approx 2$를 만족하도록 설정하는데, 이 조건을 통해 scaling 후 모델의 연산량이 두 배 증가하도록 한다. 이후 grid search를 통해 각 값을 찾는다. EfficientNet의 경우 $\alpha = 1.2, \beta = 1.1, \gamma = 1.15$로 설정하였다.
- Scaling을 $\alpha$, $\beta$, $\gamma$가 아닌 $\alpha^\phi$, $\beta^\phi$, $\gamma^\phi$로 적용하여, 모델의 연산량을 원하는 대로 조절할 수 있다. 이때 최종 연산량은 $2^\phi$배로 scaling된다.
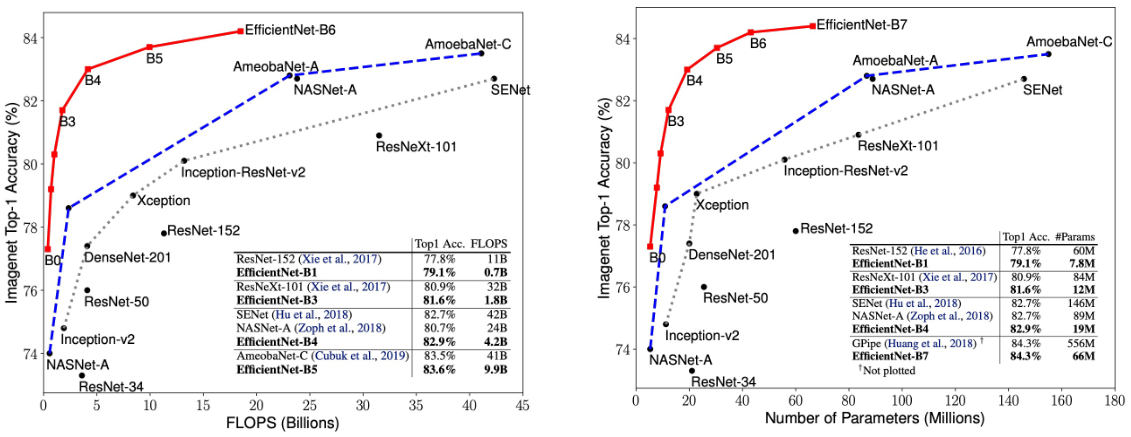
EfficientNet은 위 그림과 같이 다른 모델들과 비교하여 높은 정확도와 효율성을 보였다. 다만 연산량과 실제 runtime은 다른데, depthwise convolution의 경우 모바일 기기에서는 속도가 빠르지만 오히려 GPU나 TPU에서는 memory bound로 인해 그만큼의 속도가 나오지 않는다는 문제가 있다. (Conv layer의 연산량이 줄어 상대적으로 memory in/out의 소요시간이 bottleneck이 된다.) 또한 연산량을 수학적으로 계산하는 공식도 완전히 들어맞는 것이 아니며 FFT를 이용하는 등 단순 덧셈과 곱셈이 아닌 방식으로 속도를 개선할 수도 있기 때문에 위 그래프와 같은 비교를 할 때에는 주의해야 한다.
NFNet (2021)
EfficientNet 이후로, 모델의 복잡도보다도 실제 하드웨어 위에서의 runtime을 개선하는 방향으로 연구가 진행되었다. 이러한 연구들은 ResNet 아키텍쳐를 기반으로 하였다.
NFNet은 ResNet에서 Batch normalization을 제거할 수 있는 방법을 제안한 모델이다. Batch normalization은 작은 minibatch에서는 잘 작동하지 않고, training과 test 시의 동작이 다르며, 학습을 느리게 만든다는 단점이 있기 때문에 이를 제거한 것이다. NFNet은 Batch normalization을 제거하면서 몇 가지 trick을 제안하였다.
Scaled Residual Blocks
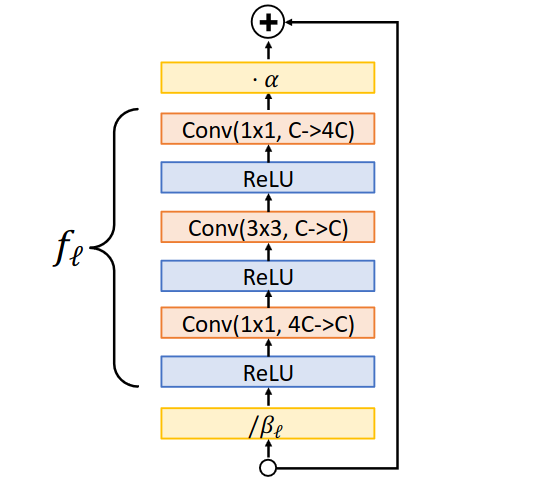
첫 번째 트릭은 Scaled Residual Blocks이다. NFNet은 위 그림과 같이 pre-activation ResNet block을 사용하였다. 이때, batch normalization을 제거하였기 때문에 layer을 거칠수록 출력의 variance가 증가하게 된다. 이를 보정하기 위해 입력을 $\beta$로 나누어 주고 출력에 $\alpha$를 곱해 주게 된다. 이때 $\alpha$는 사람이 직접 정해 주는 hyperparameter이며, $\beta$는 $\beta = \sqrt{Var(x_l)}$로 설정한다. 이를 통해 매 블록의 variance를 일정하게 유지할 수 있다.
Weight Standardization
두 번째 트릭은 Weight Standardization이다. Batch normalization이 activation을 normalize한다면 Weight standardization은 weight를 normalize한다. 구체적으로는, 모델이 학습하는 weight $W$는 그대로 있고, conv layer를 연산할 때는 $W$를 그대로 사용하는 것이 아닌 아래의 식을 통해 normalize된 weight $\hat W$를 사용한다.
$\hat W_{i,j} = \gamma \cdot \cfrac{W_{i,j} - mean(W_i)}{std(W_i)\sqrt{N}}$
이때 $\gamma$는 activation function의 종류에 따라 다른데, ReLU의 경우 $\gamma = \sqrt{2/(1-(1/\pi))}$로 설정한다.
Test 시에는 training 동안 구한 고정된 $\hat W$ 값을 사용한다.
Adaptive Gradient Clipping
기타 소소한 trick으로는, 먼저 Adaptive Gradient Clipping이 있다. 이는 단순히 gradient의 최댓값과 최솟값을 설정하여 Weight matrix의 norm이 너무 커지지 않도록 한 것이다.
Tweak ResNet architecture
NFNet은 ResNet 아키텍쳐의 구조도 살짝 변경하였다. SE_ResNeXt 구조에서 시작하여 stem과 downsampling block들의 구조를 변경하였고 ReLU 대신 GELU를 사용하였다. 또한 모든 layer에서 group width(그룹의 개수)를 128로 설정하였다.각 stage의 width는 각각 [256, 512, 1024, 1024] 대신 [256, 512, 1536, 1536]으로 설정하였다. 각 stage의 depth는 각각 [3, 4, 6, 3] 대신 [1, 2, 6, 3]으로 설정하였다.
Stronger Regularization
마지막으로 regularization도 강화하였다. MixUp, RandAugment, CutMix, DropOut, Stochastic Depth를 사용하였다.
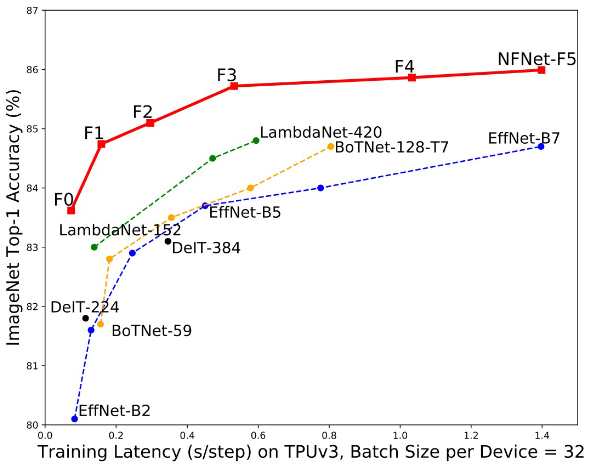
그 결과, 위 그림과 같이 training 시간 대비 정확도가 다른 모델에 비해 크게 개선된 것을 확인할 수 있다. 다만 x축이 training 시간이라는 것에 유의하자.
ResNet-RS (2021)
ResNet-RS는 기본 ResNet-200 모델에서 간단한 개선만을 통해 성능을 향상시킨 모델이다. ResNet-RS에 적용된 개선점들은 아래와 같다.
- Baseline ResNet-200 (accuracy: 79.0%)
- + Cosine LR deceay (+0.3%)
- + Longer training of 90 -> 350 epochs (-0.5%)
- + EMA(exponential moving average) of weights (+0.3%)
- + Label smoothing (+1.3%)
- + Stochastic Depth (+0.2%)
- + RandAugment (+0.4%)
- + Dropout on FC (-0.3%)
- + Less weight decay (+1.5%)
- + Squeeze and excite (+0.7%)
- + ResNet-D (+0.5%)
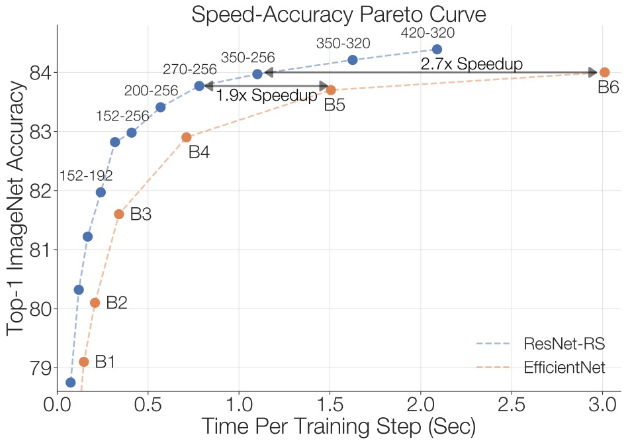
ResNet-RS의 training time 대비 정확도는 위 그림과 같다. EfficientNet보다 성능이 개선된 것을 확인할 수 있다.
RegNet (2020)
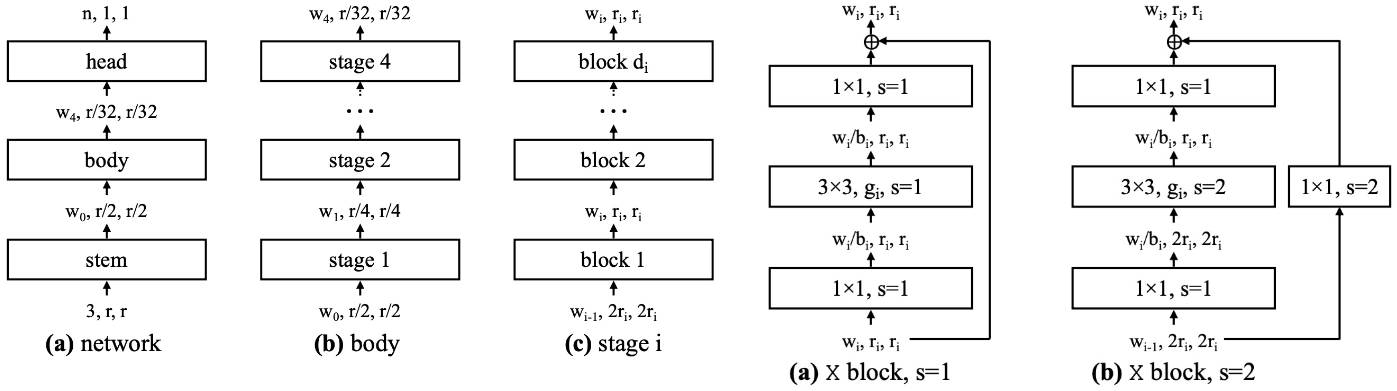
RegNet은 ResNet의 구조를 규격화한 모델이다. 위 그림과 같이 전체 네트워크, body, 각 stage와 각 block을 규격화하였다. 전체 네트워크는 stem, body, head로 구성되고, body는 4개의 stage로, stage는 여러 개의 block으로 구성된다. Stem은 3x3 conv layer로 이루어져 있으며 각 stage에서의 첫 번째 block은 이미지의 크기를 절반으로 줄인다.
각 stage는 block의 개수, input channel의 수, bottleneck ratio, group width의 총 4개의 hyperparameter만으로 구성될 수 있고 총 4개의 stage가 있으므로, 전체 네트워크는 총 16개의 hyperparameter만으로 구성될 수 있다.
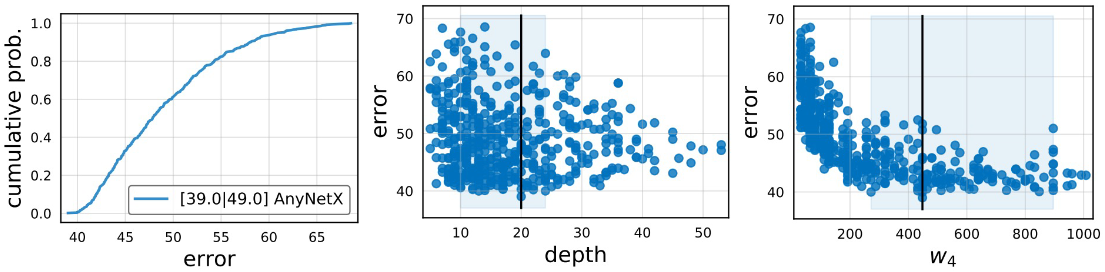
이후 위 그림과 같이 16개의 파라미터에 대해 random search를 진행한다. 이러한 결과를 바탕으로 더 세밀하게 파라미터들을 조정하게 되며, 파라미터간의 관계 또한 찾아내었다. Bottleneck ratio의 경우 모든 stage가 공통의 값을 갖도록 하여 파라미터를 16개에서 13개로 줄였고, group width 또한 모든 stage가 공통의 값을 갖도록 하여 파라미터를 13개에서 10개로 줄였다. 또한 input channel의 수와 stage당 block 수는 선형적으로 증가하도록 하여 최종적으로 아래 6개의 파라미터만으로 네트워크를 구성할 수 있도록 하였다.
- Overall depth $d$
- Bottleneck ratio $b$
- Group width $g$
- Initial width $w_0$
- Width grouth rate $w_a$
- Blocks per stage $w_m$
최종적으로 이 6개의 파라미터에 대해 random search를 수행하여 최적의 파라미터를 찾아내었고, 이를 바탕으로 성능을 다시 한 번 개선한 모델을 만들 수 있었다. 그 결과, 아래 그림과 같이 RegNet이 EfficientNet보다 정확도는 비슷하면서 training 시 최대 5배 빠르다는 결과를 얻었다.
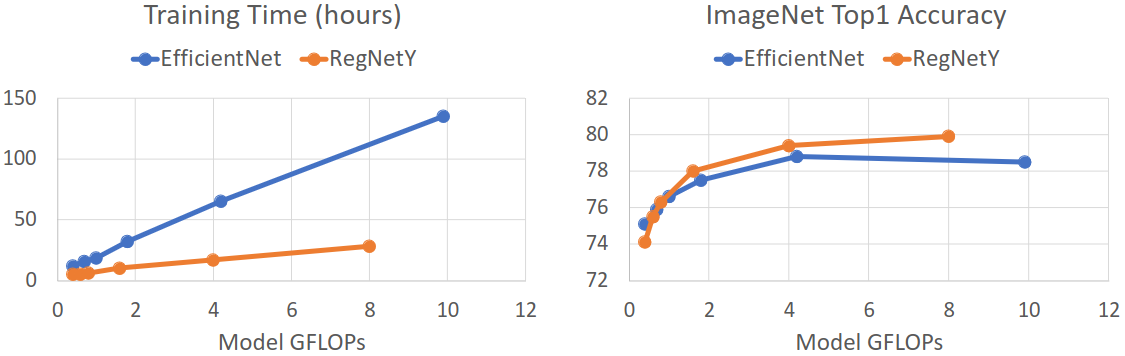
이러한 좋은 특성으로 인해 테슬라의 vision 시스템에서도 RegNet을 사용한다고 한다.