AlexNet
이번 강의에서는 ImageNet Challenge에서 우승한 여러 CNN 모델들의 Architecture에 대해 알아보도록 하자. 첫 번째 모델인 AlexNet은 2012년 CNN으로 우승한 첫 번째 모델이다.
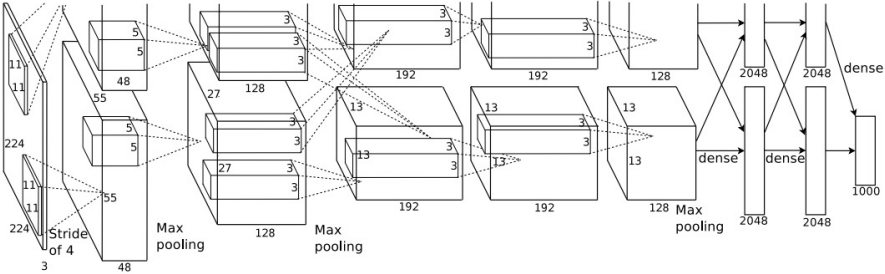
AlexNet은 5개의 Convolutional Layer와 3개의 Fully Connected Layer로 구성되어 있다. 첫 번째 Convolutional Layer에서는 11x11 필터, 2번째 layer에서는 5x5, 그 이후로는 3x3을 사용한다. 각 Layer에 대한 구체적인 정보는 아래 표와 같다.
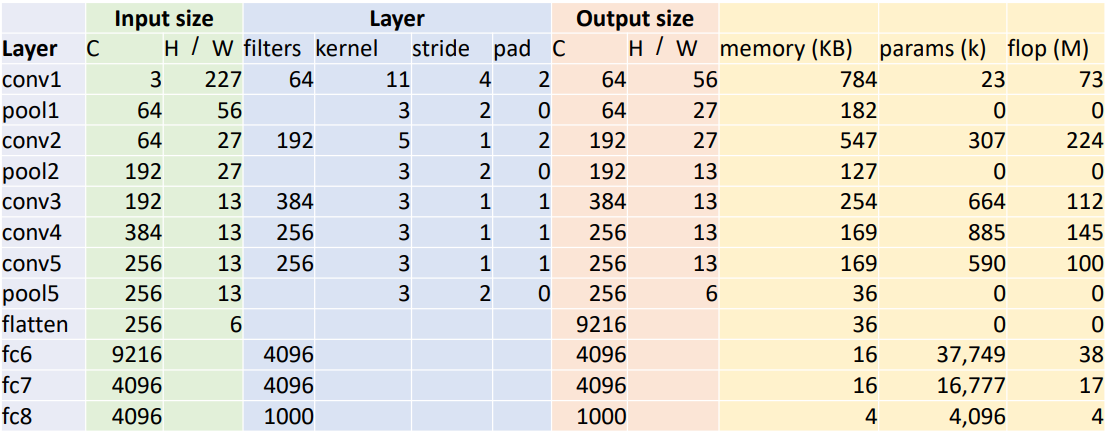
Input size와 필터 크기, stride 등의 정보로부터 output size뿐만 아니라 각 Layer가 소모하는 메모리, 파라미터 수와 연산 횟수(Flop, Floating-point operations)을 계산할 수 있다. 이는 딥러닝 모델을 설계하는 데 중요한 정보가 된다. 각 항목의 계산 과정을 구체적으로 알아보자.
Calculation
첫 번째 conv layer에 대해 우선 계산해 보자. Output Size인 56은 아래와 같이 계산된다.
$W' = (W - F + 2P) / S + 1 = (227 - 11 + 2 \times 2) / 4 + 1 = 56$
메모리 사용량의 경우 Output tensor의 모든 element의 바이트 수를 더한다. 보편적으로 4바이트 float을 사용하므로 메모리 사용량은 아래와 같다.
$C \times H' \times W' = 64 \times 56 \times 56 = 200704$
$200704 \times 4 \ bytes \div 1024 \approx 784 \ \text{KB}$
파라미터 수는 필터의 크기와 input 및 output 채널 수를 곱한 후 bias를 더하여 구할 수 있다.
$\begin{align*} \text{Weight shape } & = C_{\text{out}} \times C_{\text{in}} \times K \times K = 64 \times 3 \times 11 \times 11 = 23232 \\ \text{Bias shape } & = C_{\text{out}} = 64 \\ \text{# of parameters } & = 23232 + 64 = 23296 \end{align*}$
총 연산 횟수는 곱셈 연산과 덧셈 연산을 구분할 수 있지만, 계산해 보면 두 연산 횟수가 같기 때문에 하나의 값만을 연산 횟수로 사용한다. Output tensor의 element 수와 각 output element당 연산 횟수를 곱한다.
$\begin{align*} & ( \text{# of output elements}) \times (\text{# of operations per output element}) \\ & = (C_{\text{out}} \times H' \times W') \times (C_{\text{in}} \times K \times K) \\ & = (64 \times 56 \times 56) \times (3 \times 11 \times 11) \\ & = 200704 \times 363 \\ & = 728,775,552 \end{align*}$
위 수식은 곱셈과 덧셈 연산이 모두 해당된다. Dot product 연산을 생각해 보면 컴퓨터 내부에서는 element 개수만큼의 곱셈과 element 개수에서 1을 뺀 만큼의 덧셈을 수행하기 때문에 bias 덧셈 1회를 더하면 곱셈과 덧셈의 횟수가 모두 element의 개수와 같아진다.
Pooling Layer에서도 같은 방식으로 값들을 계산할 수 있다. Output Size는 아래와 같이 계산된다. 이때 소수점은 버린다.
$W' = (W - K) / S + 1 = (56 - 3) / 2 + 1 \approx 27$
메모리 사용량은 Output tensor의 모든 element의 바이트 수를 더한다.
$C \times H' \times W' = 64 \times 27 \times 27 = 46656$
$46656 \times 4 \ bytes \div 1024 \approx 182 \ \text{KB}$
pooling layer는 파라미터를 가지지 않으므로 파라미터 수는 0이 되고, 연산 횟수는 conv layer와 마찬가지로 output tensor의 element 수와 각 output element당 연산 횟수를 곱한다.
$\begin{align*} & ( \text{# of output elements}) \times (\text{# of operations per output element}) \\ & = (C_{\text{out}} \times H' \times W') \times (K \times K) \\ & = (64 \times 27 \times 27) \times (3 \times 3) \\ & = 419,904 \\ & = 0.4 \ \text{MFLOP} \end{align*}$
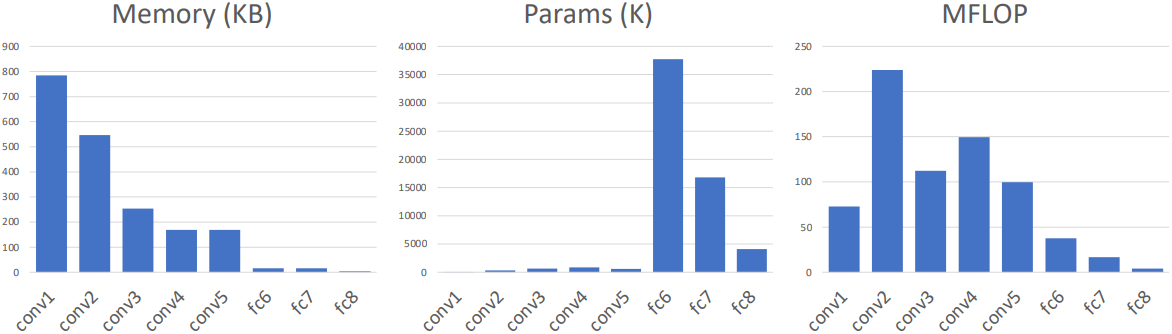
위 그래프를 통해 conv layer와 FC layer의 특징을 살펴볼 수 있다. Conv layer는 메모리 사용량과 연산량이 많지만 파라미터 수는 적다. 반면 FC layer는 반대로 메모리 사용량과 연산량이 적지만 파라미터 수가 많은 것을 알 수 있다. FC layer의 경우 파라미터 수가 많기 때문에 overfitting에 취약해진다.
VGG
VGG는 2014년 ImageNet Challenge에서 2위를 차지한 모델이다. AlexNet과 마찬가지로 Convolutional Layer와 Fully Connected Layer로 구성되어 있지만 AlexNet보다 더 깊은 구조를 가지고 있다. VGG는 필터 크기와 layer 배치에 대한 Design Rule을 적용하여 각 layer을 일일이 hyperparameter tuning 하지 않고 깊은 네트워크를 만들었다. 세 가지 Design Rule은 아래와 같다.
- 모든 필터는 3x3 크기, stride 1, padding 1
- 모든 pooling은 max pooling, 2x2 크기, stride 2
- Pooling 후에는 채널 수를 두 배로 증가
또한 Network를 아래와 같이 여러 Stage로 나누어 구성하였다.
- Stage 1: conv-conv-pool
- Stage 2: conv-conv-pool
- Stage 3: conv-conv-pool
- Stage 4: conv-conv-conv-[conv]-pool
- Stage 5: conv-conv-conv-[conv]-pool
이러한 규칙을 이용하여 구성한 VGG를 그림으로 표현하면 아래와 같다.
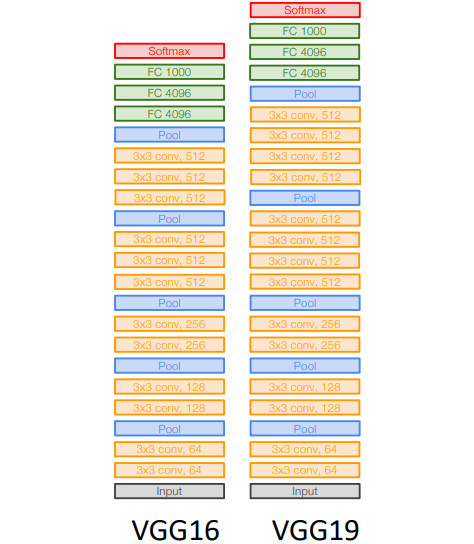
각 규칙이 왜 만들어졌는지에 대해 간단히 알아보자.

우선 3x3 필터 사용 규칙의 경우, 5x5 필터와 성능을 비교해 볼 수 있다. 우선 두 필터는 같은 receptive field를 가진다. 성능 면에서는, 5x5 필터의 경우 필요한 파라미터 수는 bias를 제외하면 $25C^2$가 되고, FLOP은 $25C^2HW$가 된다. 반면 3x3 필터를 두 번 겹쳐서 사용하는 경우 필요한 파라미터 수는 $2 \times 9C^2 = 18C^2$가 되고, FLOP은 $18C^2HW$가 된다. 따라서 3x3 필터를 사용하는 것이 5x5 필터를 사용하는 것과 같은 receptive field를 가지면서도 더 적은 파라미터와 연산량을 가지게 되고, 추가적인 non-linearity까지도 가질 수 있다. 따라서 3x3 필터를 사용하는 것이 더 유리하다.

매 Pooling Layer마다 크기는 절반으로 줄이고 채널 수는 두 배로 증가하는 규칙을 살펴보자. Input Size가 $C \times 2H \times 2W$인 경우와 $2C \times H \times W$인 경우를 비교해 보면, 두 경우 모두 FLOPs가 $36HWC^2$로 동일한 것을 볼 수 있다. 따라서 이 규칙으로 인해 연산량을 유지하면서 더 많은 종류의 feature를 얻을 수 있다.
GoogLeNet
GoogLeNet은 2014년 ImageNet Challenge에서 우승한 모델로, VGG보다 더 깊은 22개의 Layer를 가지고 있다. GoogLeNet은 가볍고 효율적인 네트워크를 설계하는 것에 집중하였다.
우선 빨간색으로 표시된 네트워크 도입 부분의 Stem Network를 통해 강력한 downsampling을 수행하는 것을 볼 수 있다. Stem Network를 통해 224x224 이미지를 28x28 이미지로 변환하면서 채널 수를 3채널에서 192채널로 크게 증가시킨다. 이를 통해 VGG-16과 비교하여 메모리는 5.7배, 파라미터 수는 8.9배, 연산 횟수는 17.8배 감소시킬 수 있었다.
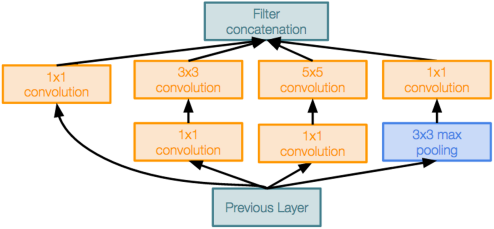
GoogLeNet에서도 위 그림과 같은 반복적인 구조를 사용하는데, 이는 GoogLeNet의 핵심이 되는 Inception Module이다. Inception Module은 1x1, 3x3, 5x5 등 여러 크기의 필터와 pooling layer를 동시에 사용하여 다양한 크기의 feature를 추출한다. 또한 1x1 conv layer를 적용함으로써 채널 수를 줄여 연산량을 감소시킨다. 이러한 구조를 통해 VGG보다도 더 적은 연산량을 가진다.

마지막으로, GoogLeNet은 네트워크의 마지막에 Global Average Pooling을 추가한다. 최종 Inception Module의 output은 위 표와 같이 1024x7x7이 되는데, 여기에 7x7 크기의 Average Pooling을 적용하여 사실상 이미지의 공간 정보를 average out 하고 1024 크기의 벡터로 만든다. 3차원 tensor에 FC layer를 바로 적용하는 것이 아닌 Global Average Pooling을 거침으로써 파라미터 수와 연산 횟수를 크게 감소시킬 수 있다.
ResNet
ResNet은 2015년 ImageNet Challenge에서 우승한 모델로, VGG보다 더 깊은 152개의 Layer를 가지고 있다. ResNet은 Residual Block과 Batch Normalization을 도입하여 훨씬 깊은 모델로 높은 성능을 달성하였다.
ResNet은 152개의 깊은 layer를 가지고 있다. 기존에는 Deep model이 overfitting한다고 생각했지만 실제로는 underfitting하고 있었고, optimization을 잘 하면 깊은 모델은 얕은 모델을 충분히 그대로 따라할 수 있다고 보았다. 20개의 layer를 가진 모델과 10개의 layer를 가진 모델이 있을 때 처음 10개는 동일하게 하고 뒤에 10개의 identity mapping을 추가하면 두 모델은 동일한 출력을 내기 때문이다.
따라서 layer를 추가하되 네트워크 구조를 바꾸어 identity function을 학습하기 쉽도록 하여 깊은 모델에서 optimizing이 어려운 문제를 해결하였다. 이러한 구조를 Residual Block이라고 한다.
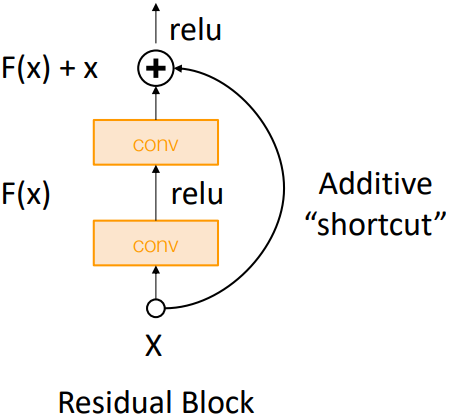
Residual Block은 위 그림과 같이 identity function을 학습하기 쉽도록 shortcut connection을 추가한 것이다. 중간의 두 conv layer를 모두 0으로 만들면 identity function이 된다. Regularizaion을 통해, 모델이 적은 수의 layer로도 충분할 경우 identity function을 학습하여 residual block을 0으로 만든다.
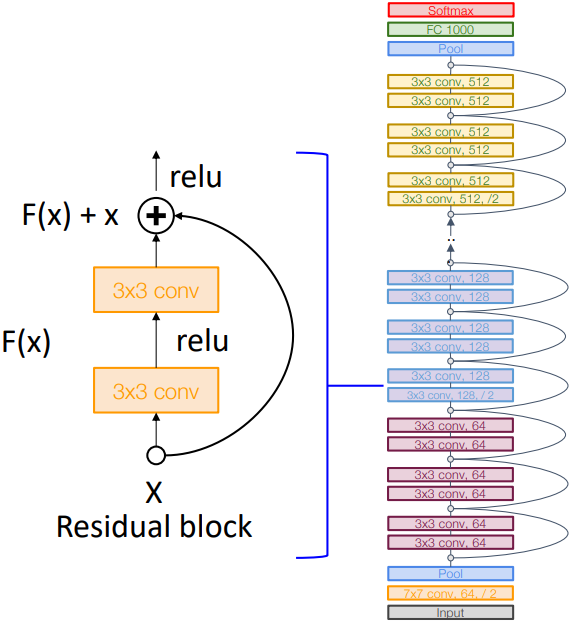
ResNet은 VGG와 같이 반복 구조를 이용하여 구성된다. 또한 GoogLeNet과 마찬가지로 초반에 강하게 downsampling을 하는 부분과 마지막에 Global Average Pooling을 사용하는 부분이 있다.
ResNet-18의 경우 각 stage의 구성은 다음과 같다.
- Stem: 1 conv layer
- Stage 1 (C = 64): 2 res. block = 4 conv
- Stage 2 (C = 128): 2 res. block = 4 conv
- Stage 3 (C = 256): 2 res. block = 4 conv
- Stage 4 (C = 512): 2 res. block = 4 conv
- Global Average Pooling
연산량은 1.8 GFLOP이다.

위 그림과 같이 residual block을 다른 방식으로 구성하는 트릭이 있다. Bottleneck Residual Block이라고 불리는데, 1x1 conv layer를 사용하여 채널 수를 축소한 후 3x3 conv를 수행하고 다시 채널 수를 복원시킨다. 이러한 방식을 이용해 layer를 추가하여 non-linearity를 증가시키면서도 연산량은 감소시킬 수 있다.
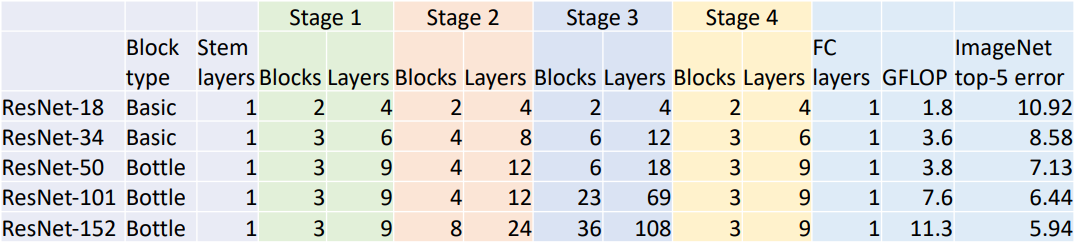
위 표와 같이 Bottleneck 구조를 이용하여 더욱 깊고 성능을 개선한 모델을 만들 수 있다. 특히 ResNet-34와 ResNet-50을 비교하면 같은 stage 구성에 block만 bottleneck 구조로 바꾼 형태인데 연산량이 비슷하지만 ResNet-50이 더 높은 성능을 보이는 것을 알 수 있다.
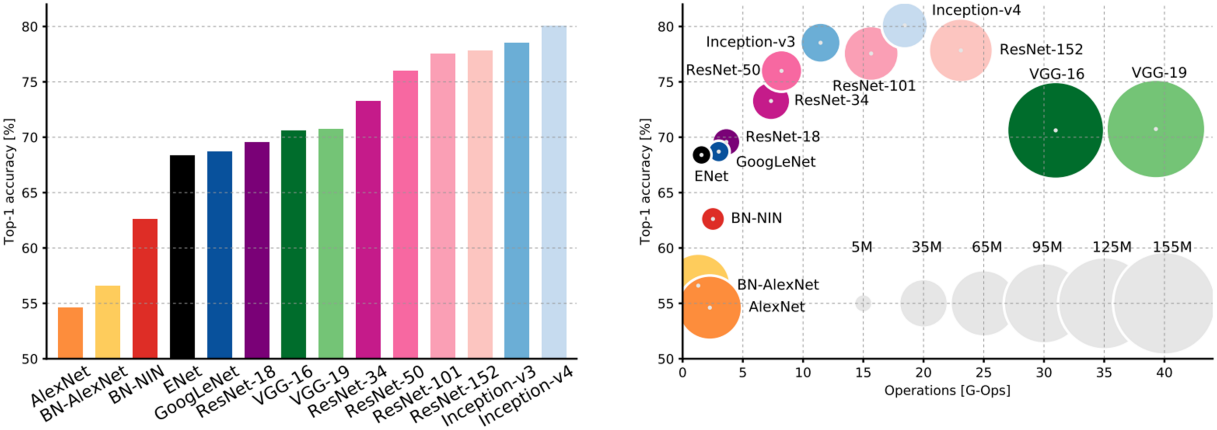
지금까지 등장한 모델들을 비교해 보면 위 그래프와 같다. ResNet은 VGG보다 더 깊은 모델을 만들면서도 연산량을 크게 줄일 수 있었고, GoogLeNet의 경우 연산량이 매우 적은 것을 볼 수 있다.