Introduction
3D visual grounding은 user query를 기반으로 scene 내 target object의 3D 위치를 찾는 task이다. 기존 supervised learning 방법은 paired 3D point cloud-language 데이터로 end-to-end 모델을 학습하지만, 데이터셋이 부족하고 pre-defined vocabulary에 한정되어 open-world 적용이 어렵다.
최근 LLM 기반 zero-shot 방법들이 등장했지만, point cloud 기반 3D localization 모듈로 object를 검출한 뒤 속성을 텍스트로 변환하여 LLM이 선택하는 방식이므로 object-centric information만 사용한다. 이로 인해 "find the room with the most abundant natural light" 같은 detailed scene context가 필요한 query를 처리하기 어렵다.
본 논문은 VLM(Vision-Language Model)을 활용한 zero-shot 3D visual grounding agent인 VLM-Grounder를 제안한다. VLM-Grounder는 2D 이미지만을 사용하여 3D bounding box를 예측하며, reconstructed point cloud이나 object prior에 의존하지 않는다. 핵심 모듈은 (1) dynamic stitching: 이미지를 효율적으로 VLM에 전달하는 전략, (2) grounding and feedback: VLM의 reasoning과 자동 피드백 기반 재시도 메커니즘, (3) multi-view ensemble projection: 다중 view의 2D mask를 결합하여 정확한 3D bounding box를 추정하는 방법이다.
Related Work
3D Visual Grounding
3D visual grounding은 ScanRefer와 ReferIt3D에 의해 벤치마킹되었다. 기존 supervised 방법은 two-stage paradigm(3D detection/segmentation 이후 language feature fusion)이나 one-stage 방법(encoder-decoder로 직접 bounding box 예측)을 따른다. 최근 LLM이 backbone으로 활용되고 있으며, zero-shot 방법인 LLM-Grounder와 ZS3DVG는 LLM을 agent-based framework에서 사용한다. 그러나 이들은 reconstructed point cloud에 의존하고, text 기반 information만 LLM에 전달하여 spatial relationship 위주의 query만 처리할 수 있다.
Zero-shot LLM/VLM Agents for 3D Scene Understanding
LLM/VLM은 task reasoning, planning, tool use, code writing 등의 능력으로 다양한 off-the-shelf 모듈을 통합하는 AI agent를 가능하게 한다. Agent3D-Zero는 VLM으로 bird's-eye view를 이해하고, OpenEQA는 scene understanding 벤치마크를 제안했다. 본 논문의 VLM-Grounder는 2D 이미지만으로 3D bounding box를 직접 추정하며, reconstructed 3D scene이나 3D localization 모듈이 필요하지 않다는 점에서 차별화된다.
Methodology
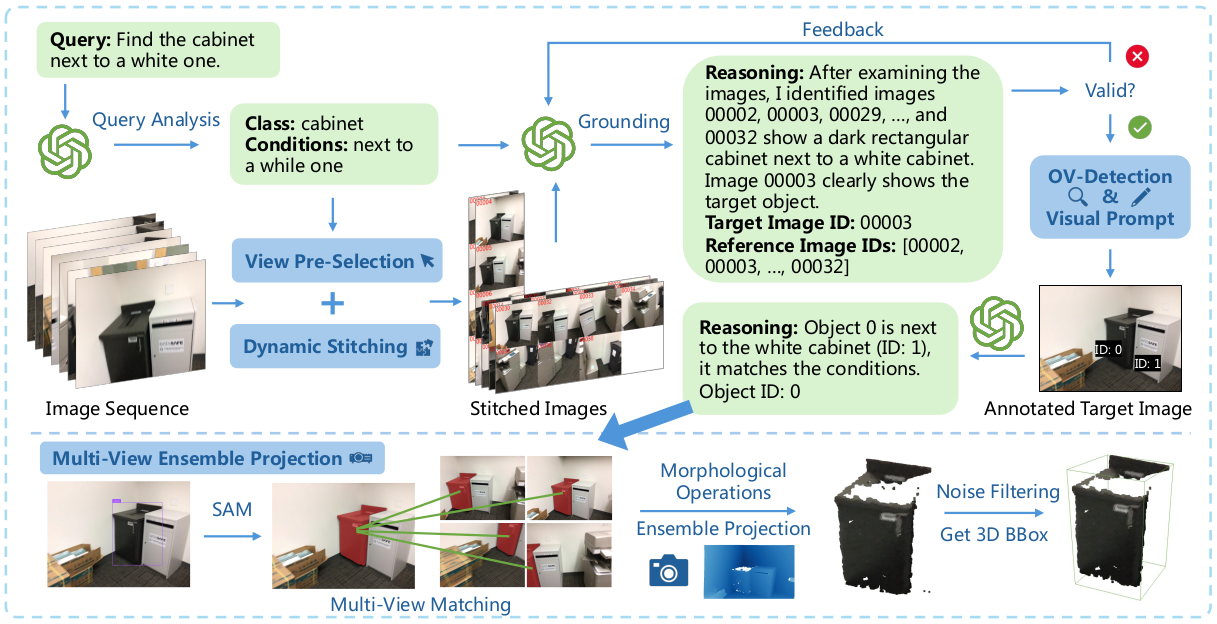
VLM-Grounder
VLM-Grounder는 scanned scene의 image sequence와 user query를 입력으로 받아 target object의 3D bounding box를 예측한다. 각 이미지의 intrinsic/extrinsic camera parameter와 depth image에 접근 가능하다고 가정하며, 이는 SLAM이나 SfM/MVS로 얻을 수 있다. VLM으로는 GPT-4V를 사용하며, 처리 과정은 다음과 같다:
- Query analysis: VLM이 query에서 target class label과 grounding condition을 식별한다.
- View pre-selection and dynamic stitching: 2D open-vocabulary detector로 target class가 포함된 이미지만 pre-select하고, dynamic stitching 전략으로 이미지를 효율적으로 결합한다.
- Grounding and feedback: VLM이 stitched image에서 target image와 object를 식별하고, 자동 피드백으로 유효성을 검증한다.
- Open-vocabulary detection and visual prompt: target image에서 OV detector로 같은 class의 object를 검출하고, 여러 instance가 있으면 ID를 annotate하여 VLM이 선택한다.
- Multi-view ensemble projection: SAM으로 fine-grained mask를 얻고, multi-view matching으로 추가 view를 찾아 ensemble projection으로 3D bounding box를 추정한다.
Dynamic Stitching
VLM에 image sequence를 전달할 때 세 가지 문제가 있다: (1) VLM의 최대 이미지 수 제한(e.g., GPT-4V는 Tier-1에서 10장), (2) 많은 이미지가 context를 과도하게 소비하여 성능 저하, (3) 추론 비용 및 시간 증가. 이를 해결하기 위해 여러 이미지를 grid layout으로 stitching하여 하나의 이미지로 합친다.
Stitching layout이 VLM의 visual understanding에 미치는 영향을 평가하기 위해 Visual-Retrieval Benchmark를 설계했다. 벤치마크 결과, GPT-4V에 최적인 상위 3개 layout은 (4, 1), (2, 4), (8, 2)이며, (4, 1)이 가장 낮은 information loss를 보인다. 본 논문은 이 상위 layout들을 동적으로 조합하는 dynamic stitching 전략을 제안한다. 이미지 수 $n$과 soft limit $L$에 따라 (4, 1)을 우선 사용하고, 필요시 (2, 4)와 (8, 2)로 확장한다.
Grounding and Feedback
VLM은 analyzed query와 stitched image를 받아 target object가 포함된 이미지를 식별한다. Grounding condition이 여러 view를 고려해야 할 수 있으므로, VLM이 reasoning process를 설명하고 참조한 이미지를 제공하도록 prompt한다. 이후 VLM의 예측에 대해 자동 validity check를 수행한다: (1) target image가 존재하지 않으면 "image-invalid" 피드백, (2) OV detector가 target class를 검출하지 못하면 "object-not-existing" 피드백, (3) object ID가 유효하지 않으면 "object-ID-invalid" 피드백을 message history에 추가하여 VLM이 재선택하도록 한다. 최대 $M$번 재시도 후 실패로 처리한다.
Multi-View Ensemble Projection
단일 이미지의 3D projection은 제한된 field-of-view와 부정확한 depth로 인해 불완전할 수 있다. 이를 해결하기 위해 image matching 방법 PATS를 사용하여 동일 target object의 추가 view를 찾고, 총 $N$개 이미지의 mask를 함께 사용하여 joint estimation을 수행한다. 동일 외관의 object가 많은 scene에서의 mismatched pair는 anchor point cloud과의 L2 Chamfer Distance로 필터링한다.
SAM과 depth map의 noise를 처리하기 위해 두 가지 morphological operation을 적용한다: (1) Erosion: mask border를 축소하여 noise를 제거하고 부정확한 border depth를 방지한다. (2) Component selection: 상위 2개 largest connected component만 유지하여 over-segmentation에 의한 incorrect mask를 제거한다. 최종적으로 valid point cloud의 union에서 axis-aligned 3D bounding box를 계산한다.
Experimental Results
Experimental Settings
Datasets
ScanRefer와 Nr3D 데이터셋에서 평가한다. ScanRefer는 ScanNet 기반으로 51,583개의 query-target object pair를 포함하며, "Unique"(scene 내 동일 class object 1개)와 "Multiple"(distractor 존재)로 분류된다. Nr3D는 ReferIt3D의 일부로 41,503개 query를 포함하며, "Easy"(distractor 1개)와 "Hard"(2개 이상), "View-Dependent"와 "View-Independent"로 분류된다. 비용 절감을 위해 각 데이터셋에서 250개 validation sample을 랜덤 선택하여 테스트한다.
Evaluation Metrics
ScanRefer는 Acc@0.25와 Acc@0.5를 사용한다. Predicted bounding box와 ground truth의 IoU가 0.25 또는 0.5 이상인 비율을 측정한다. Nr3D는 ground truth bounding box가 주어진 상태에서 top-1 selection accuracy를 측정한다. VLM-Grounder는 object prior가 필요 없으므로, predicted box 중 ground truth center에 가장 가까운 것을 매칭한다.
Implementation Details
ScanNet image sequence에서 매 20 프레임마다 1장을 샘플링한다. VLM은 GPT-4o-2024-05-13을 사용하며, temperature 0.1, top_p 0.3으로 설정한다. Retry limit $M = 3$, image count limit $L = 6$, ensemble image number $N = 7$이다. 2D open-vocabulary detector로 SAM-Huge와 Grounding DINO-1.5를 사용한다.
3D Visual Grounding Results
ScanRefer
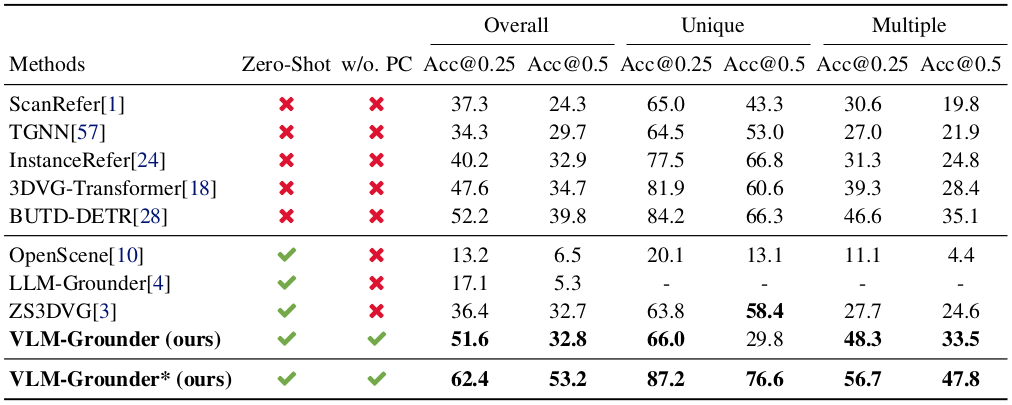
VLM-Grounder는 모든 기존 zero-shot 방법을 크게 능가한다. Overall Acc@0.25에서 51.6%를 달성하여 이전 SOTA인 ZS3DVG(36.4%) 대비 15.2%p 향상된다. Point cloud을 사용하지 않음에도 supervised 방법인 BUTD-DETR(52.2%)에 근접하며, InstanceRefer(40.2%)와 3DVG-Transformer(47.6%)를 능가한다.
Acc@0.25와 Acc@0.5 사이의 gap이 큰 이유는, VLM-Grounder가 2D mask를 camera parameter와 depth로 3D에 projection하기 때문이다. Depth의 부정확함과 outlier가 overly large bounding box를 만들 수 있다. Multi-view ensemble projection이 이를 완화하지만 완전히 해결하지는 못한다. 그럼에도 Multiple split에서는 Acc@0.25와 Acc@0.5 모두에서 ZS3DVG를 능가한다.
Nr3D
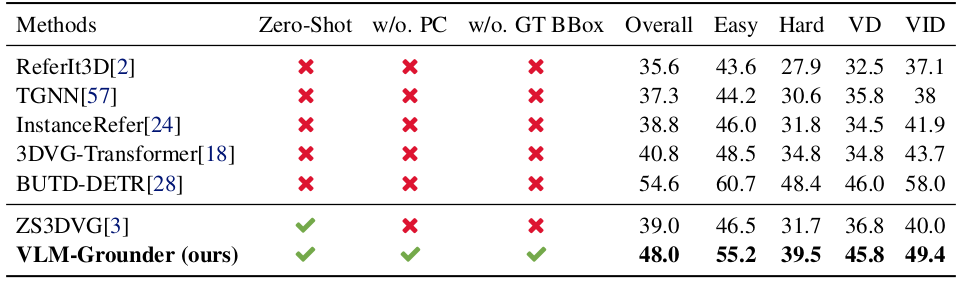
Nr3D에서 기존 zero-shot 방법은 GT 3D bounding box를 입력으로 사용하여 strong prior를 가지지만, VLM-Grounder는 object prior 없이도 overall accuracy 48.0%를 달성하여 ZS3DVG(39.0%)를 9%p 능가한다. 모든 query category에서 consistent한 향상을 보이며, supervised 방법인 InstanceRefer(38.8%)와 3DVG-Transformer(40.8%)와 비슷하다.
Ablation Studies

Stitching Strategies
Dynamic stitching(51.6%)이 fixed (8, 2)(48.4%), square strategy(49.2%)를 모두 능가한다. Stitching 없이(1, 1)는 timeout이 빈번하여 task 완료에 실패한다.
Image Limits
Soft image limit $L$을 다양하게 실험한 결과, $L$ < 10에서는 성능이 유사하지만, 이미지 수가 많아지면 추론 비용과 timeout 위험이 증가한다. 따라서 $L = 6$으로 설정하여 성능과 효율성의 균형을 맞춘다.
Projection Operations
Multi-view ensemble projection 모듈의 각 component를 점진적으로 추가하며 효과를 검증한다. 각 component가 모두 성능 향상에 기여한다는 것을 보였다.
Conclusion and Limitations
본 논문은 VLM agent 기반 zero-shot 3D visual grounding 프레임워크인 VLM-Grounder를 제안했다. Dynamic stitching, grounding and feedback, multi-view ensemble projection의 세 가지 핵심 모듈을 통해, point cloud이나 object prior 없이 2D 이미지만으로 3D bounding box를 추정한다. ScanRefer와 Nr3D에서 기존 zero-shot 방법을 크게 능가하며, 일부 supervised 방법과도 비교 가능한 성능을 달성한다.
한계점으로는 (1) 3D grounding 정확도가 부정확한 camera parameter와 depth map에 영향을 받는다. (2) Open-vocabulary detector가 target을 검출하지 못하면 grounding이 실패한다. (3) VLM API 호출 비용과 latency가 존재한다.