Introduction
인간은 감각 정보를 통합하여 세상에 대한 internal model을 학습하고, 이를 통해 미래 상태를 예측하며 새로운 상황에서도 계획을 세울 수 있다. 본 논문은 internet-scale video data와 소량의 robot interaction data를 결합하여, physical world를 understand, predict, plan할 수 있는 모델을 self-supervised 방식으로 학습하는 접근법을 제안한다.
Interaction data로만 학습하는 모델과는 달리, self-supervised learning은 internet-scale 비디오를 사용할 수 있게 해 준다. 이를 통해 비디오 representation과 그 representation space에서의 world dynamics를 모두 학습할 수 있다. 또한 pixel 레벨이서 생성하는 video generation과 달리, JEPA 기반이기 때문에 scene의 예측 가능한 부분 (움직이는 물체의 궤적)에 집중하고 예측 불가능한 부분 (들판 위 풀잎의 위치) 등은 배제할 수 있다.
V-JEPA 2의 학습은 두 단계로 이루어진다: (1) 1백만 시간 이상의 internet video에서 action-free self-supervised pretraining, (2) 62시간의 unlabeled robot data로 action-conditioned world model(V-JEPA 2-AC) post-training.
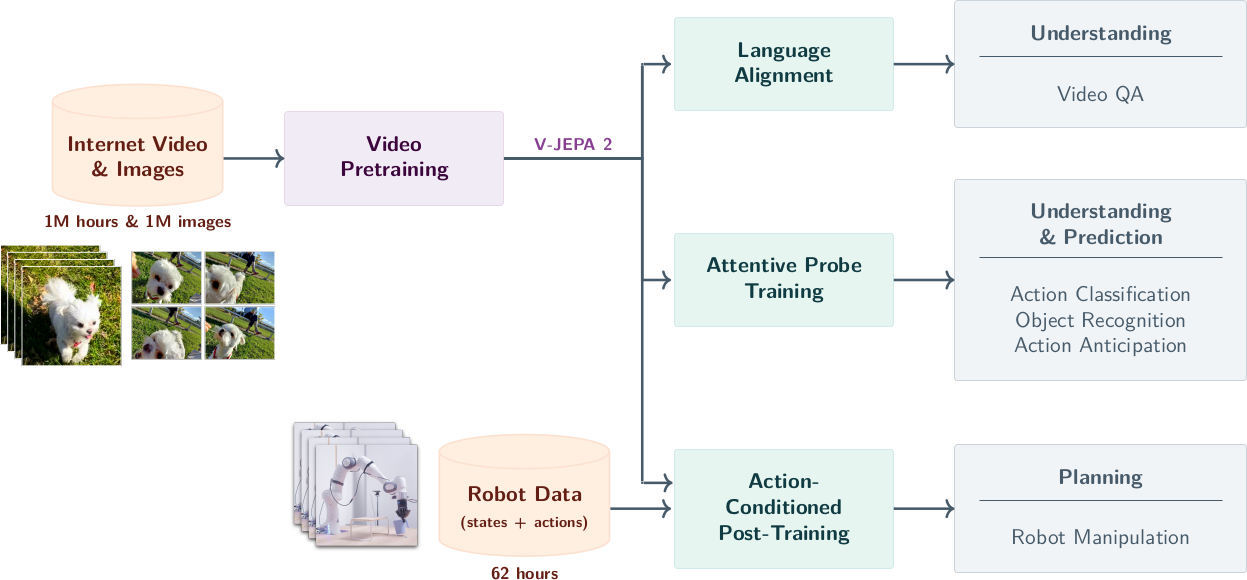
핵심 결과는 다음과 같다.
- Understanding (Probe-based Classification): V-JEPA 2는 motion understanding task에서 SOTA를 달성한다. SSv2에서 77.3 top-1 accuracy(attentive probe 사용).
- Understanding (Video QA): LLM과 alignment하여 8B 모델 클래스에서 SOTA VidQA 성능을 달성한다. PerceptionTest 84.0, TempCompass 76.9, TOMATO 40.3 등. Language supervision 없이 pretrained된 video encoder가 language model과 align되어 SOTA를 달성한 최초의 사례이다.
- Prediction: Epic-Kitchens-100 action anticipation에서 39.7 recall-at-5로 SOTA를 달성하며, 이전 최고 모델 대비 44% relative improvement이다.
- Planning: V-JEPA 2-AC는 62시간의 unlabeled Droid data만으로 학습되며, 새로운 환경의 Franka robot arm에서 zero-shot으로 grasp, pick-and-place 등의 manipulation task를 수행한다.
V-JEPA 2: Scaling Self-Supervised Video Pretraining
Methodology
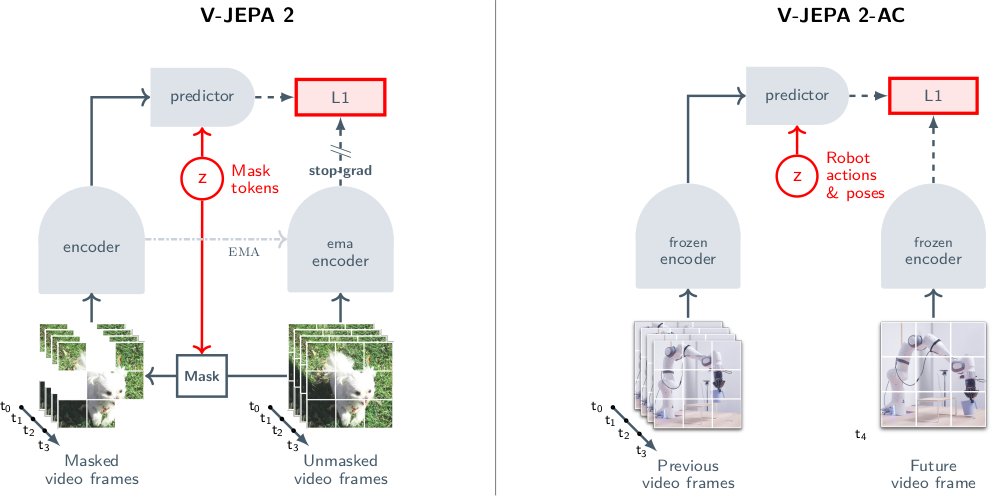
V-JEPA 2의 self-supervised training task는 V-JEPA의 mask-denoising objective를 기반으로 한다. Encoder $E_\theta(\cdot)$가 video representation을 추출하고, predictor $P_\phi(\cdot)$가 masked video part의 representation을 예측한다.
$\text{minimize}_{\theta, \phi, \Delta_y} \quad \| P_\phi(\Delta_y, E_\theta(x)) - \text{sg}(\overline{E}_{\overline{\theta}}(y)) \|_1$
V-JEPA 1과의 주요 차이점으로, position encoding에 absolute sincos 대신 3D-RoPE(Rotary Position Embedding)를 사용한다. Feature dimension을 temporal, height, width 축으로 3등분하여 각각 1D rotation을 적용한다. 이는 대규모 모델의 학습 안정성을 높인다. Patchification과 multiblock masking 전략은 V-JEPA 1과 동일하다.
Key Scaling Ingredients
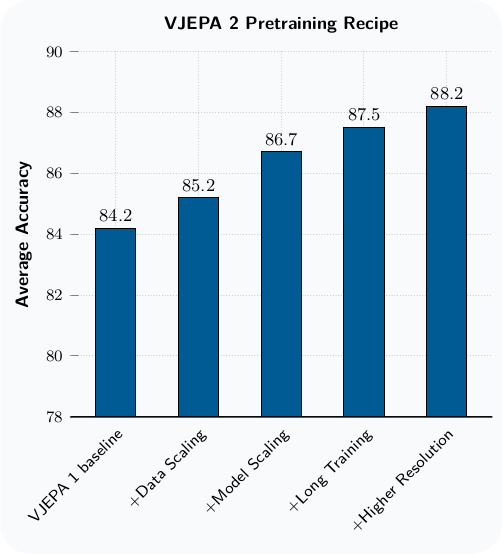
V-JEPA 1 recipe에서 4가지 scaling ingredient를 도입한다.
- Data scaling: Dataset을 2M에서 22M video로 확대(VideoMix22M).
- Model scaling: Encoder를 ViT-L(300M)에서 ViT-g(1B)로 확대.
- Longer training: Warmup-constant-decay learning rate schedule을 채택하여 90K에서 252K iteration으로 확장.
- Higher resolution: Progressive resolution training으로 spatial resolution($256 \rightarrow 384$)과 temporal duration($16 \rightarrow 64$ frames)을 점진적으로 증가.
Pretraining Dataset

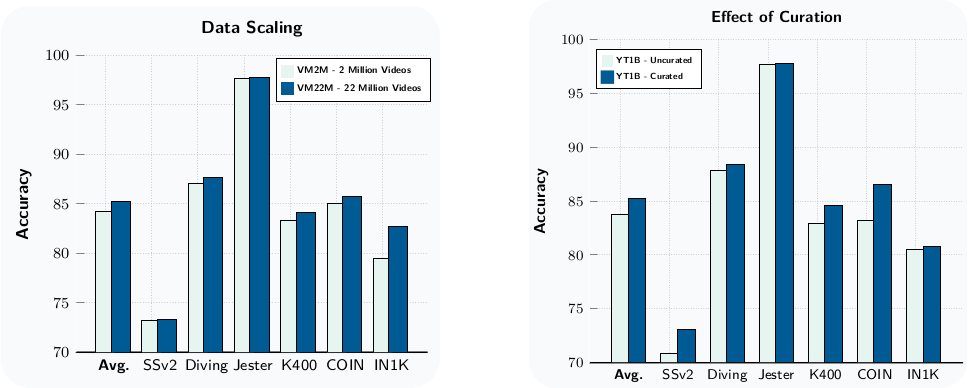
VideoMix22M(VM22M)은 SSv2, Kinetics, HowTo100M, YT-Temporal-1B, ImageNet을 결합한 22M sample dataset이다. Image는 16-frame video로 duplicate하여 사용한다. 각 data source에 sampling weight를 적용하여 학습한다.
VM22M 학습은 VM2M 대비 average performance +1점 향상을 가져오며, appearance 기반 task(K400, COIN, ImageNet)에서 개선이 두드러진다. YT-1B의 경우 retrieval 기반 curation을 적용하여 noisy content를 필터링하면 +1.4점 향상된다.
Pretraining Recipe
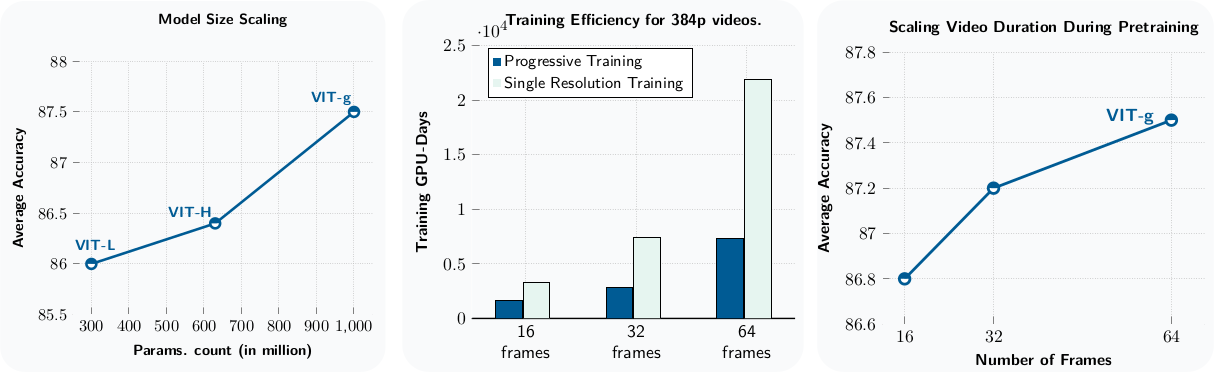
Scaling Model Size
ViT-L(300M)에서 ViT-g(1B)로 scaling하면 average performance가 +1.5점 향상된다. Motion과 appearance understanding task 모두 scaling의 이점을 받는다.
Efficient Progressive-Resolution Training
Full resolution($64 \times 384 \times 384$)으로 처음부터 학습하면 약 60 GPU-year가 필요하다. 이를 줄이기 위해 progressive resolution strategy를 채택한다: warmup과 constant phase에서는 $16 \times 256 \times 256$으로 학습하고, cooldown phase에서만 resolution과 duration을 증가시킨다. 이를 통해 8.4배 GPU time 절감을 달성한다.
Scaling Temporal and Spatial Resolution
Pretraining 시 clip duration을 16에서 64 frame으로 늘리면, 16-frame evaluation 기준으로도 +0.7점 향상된다. Evaluation 시에도 duration과 resolution을 높이면 추가 향상이 관찰된다.
V-JEPA 2-AC: Learning an Action-Conditioned World Model
Action-Conditioned World Model Training
V-JEPA 2 pretraining 후, frozen encoder 위에 action-conditioned predictor를 학습하여 latent world model을 얻는다. Droid dataset에서 약 62시간의 unlabeled robot video(Franka Panda arm)를 사용해 학습한다. Reward, task label, 성공 여부 등의 meta-data는 사용하지 않는다.
각 학습 iteration에서 4초짜리 video clip을 mini-batch로 sampling한다. $256 \times 256$ resolution, 4 fps로 sampling하여 16-frame clip $(x_k)_{k \in [16]}$을 얻는다. 각 frame의 end-effector state $s_k \in \mathbb{R}^7$는 robot base 기준 cartesian position(3D), extrinsic Euler angle orientation(3D), gripper state(1D)로 구성된다. Action $a_k \in \mathbb{R}^7$는 연속 frame 간 state 변화량 $a_k = s_{k+1} - s_k$로 정의한다.
Frozen V-JEPA 2 encoder를 image encoder로 사용하여 각 frame을 독립적으로 encoding한다($z_k = E(x_k) \in \mathbb{R}^{H \times W \times D}$, 실제로는 $16 \times 16 \times 1408$). Feature map, end-effector state, action의 시퀀스 $(a_k, s_k, z_k)_{k \in [15]}$를 temporally interleave하여 transformer predictor $P_\phi(\cdot)$에 입력하고, 다음 frame의 representation $\hat{z}_{k+1}$을 autoregressive하게 예측한다.
Loss는 두 가지를 결합한다.
$L(\phi) = \mathcal{L}_{\text{teacher-forcing}}(\phi) + \mathcal{L}_{\text{rollout}}(\phi)$
- Teacher-forcing loss: 각 time step에서 ground-truth encoding을 입력으로 사용하여 다음 frame의 representation을 예측. $\cfrac{1}{T} \sum_{k=1}^{T} \| \hat{z}_{k+1} - z_{k+1} \|_1$
- Rollout loss: Predictor 자신의 이전 output을 입력으로 사용하여 여러 step 앞을 예측. Autoregressive rollout 시 error accumulation을 줄이기 위한 것이다.
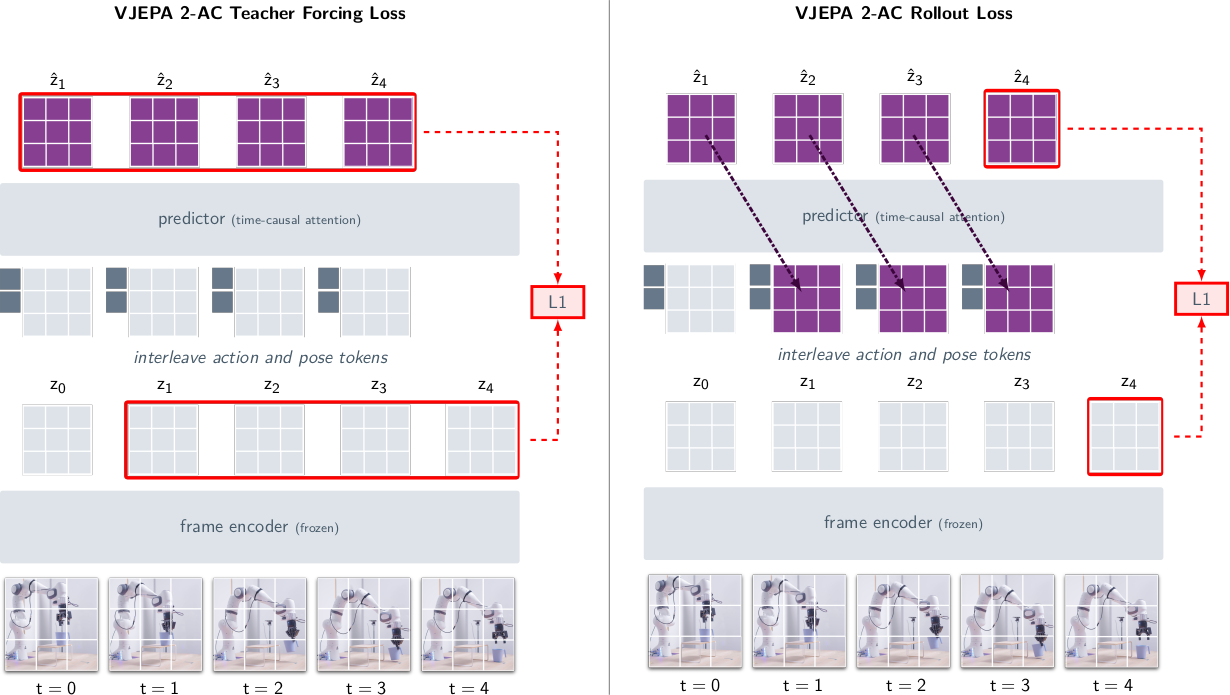
Predictor는 ~300M parameter transformer(24 layer, 1024 hidden dim, 16 head)이며, block-causal attention을 사용하여 각 time step의 patch feature가 같은 time step과 이전 time step의 feature, action, state에만 attend할 수 있도록 한다.
Inferring Actions by Planning
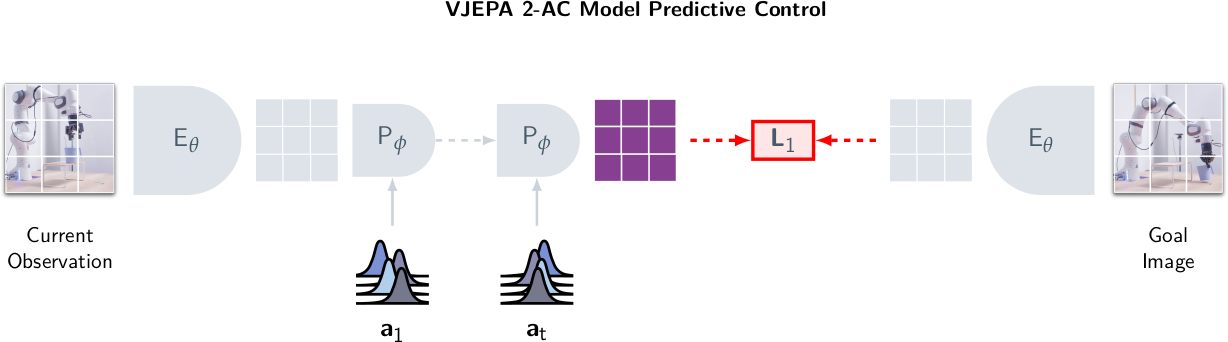
Goal image가 주어지면, 매 time step마다 goal-conditioned energy function을 최소화하는 action sequence를 planning한다.
$\mathcal{E}(\hat{a}_{1:T};\ z_k, s_k, z_g) := \| P(\hat{a}_{1:T};\ s_k, z_k) - z_g \|_1$
World model이 autoregressive하게 예측한 $T$ step 후의 state representation과 goal representation 간의 $L_1$ distance를 최소화하는 action sequence를 Cross-Entropy Method(CEM)으로 최적화한다. 각 planning step에서 Gaussian distribution으로부터 action을 sampling하고, top-k trajectory의 statistics로 distribution을 업데이트하는 과정을 반복한다. 첫 번째 action만 실행하고 re-plan한다(receding horizon control).
Planning: Zero-shot Robot Control
Experimental Setup
V-JEPA 2-AC를 두 개의 다른 lab에 있는 Franka Emika Panda arm에서 실험한다. 두 lab 모두 Droid dataset에 포함되지 않은 환경이다. Baseline으로 Octo(behavior cloning 기반 VLA 모델)와 Cosmos(action-conditioned video generation 모델)를 비교한다.
Results
Single-Goal Reaching
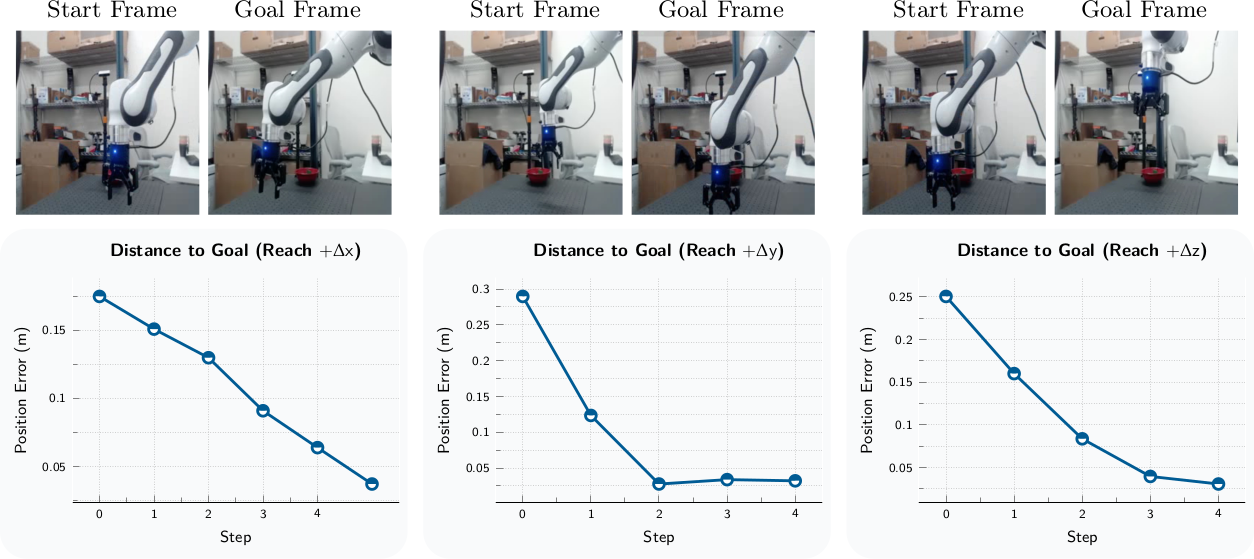
End-effector를 goal image의 위치로 이동시키는 task이다. 모든 경우에서 4 step 이내에 goal position의 4cm 이내로 도달하며, monotonic하게 error가 감소한다.
Prehensile Manipulation

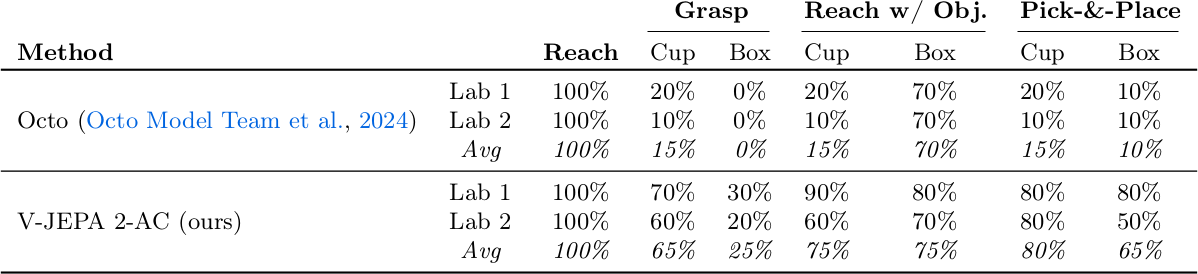
Grasp, reach with object, pick-and-place의 세 가지 manipulation task를 평가한다. Pick-and-place의 경우 3개의 sub-goal image를 순차적으로 제시한다. V-JEPA 2-AC는 모든 task에서 Octo를 크게 능가하며, 평균 grasp 65%/25%, reach w/ obj 75%, pick-and-place 80%/65%(cup/box) 성공률을 달성한다.

Cosmos world model과의 비교에서, V-JEPA 2-AC는 단일 4090 GPU에서 action당 16초로 planning하는 반면, Cosmos는 action당 4분이 소요된다. V-JEPA 2-AC가 10배 많은 sample을 사용하면서도 더 빠르고, 모든 robot skill에서 더 높은 성능을 달성한다.
Limitations
- Camera positioning 민감성: Explicit camera calibration 없이 monocular RGB로부터 action coordinate axis를 implicit하게 추론해야 하므로, camera 위치에 민감하다.
- Long horizon planning: Autoregressive prediction의 error accumulation과 search space의 기하급수적 증가로 인해 long horizon task가 어렵다.
- Image goal: 현재 goal specification이 image 기반이므로, language 기반 goal specification으로의 확장이 필요하다.
Understanding: Probe-based Classification
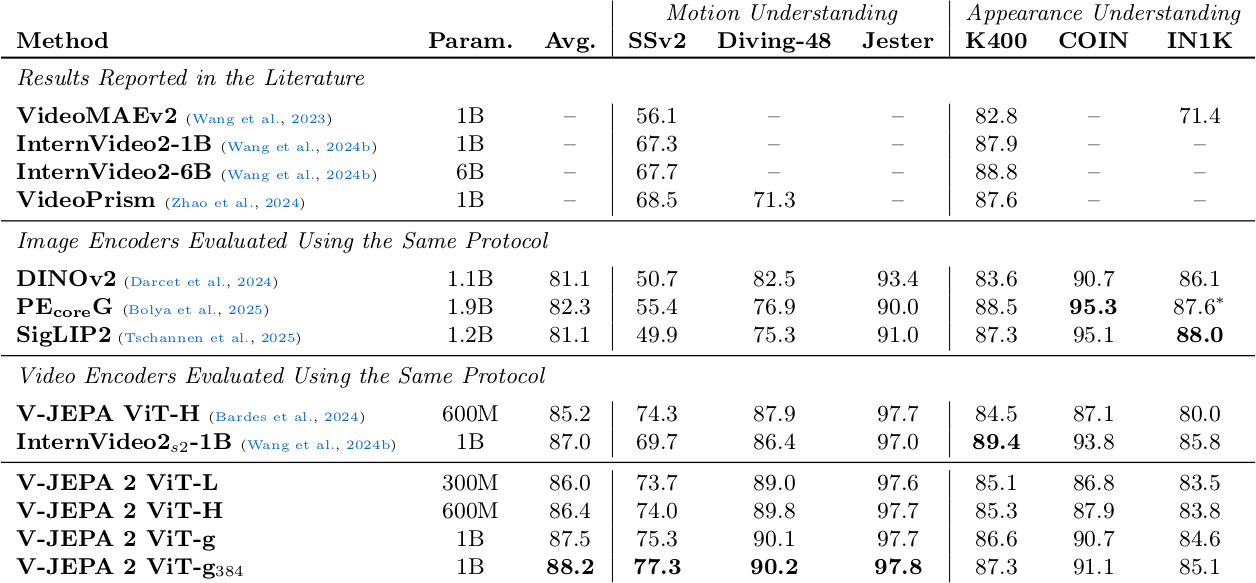
Frozen V-JEPA 2 encoder 위에 4-layer attentive probe를 학습하여 6가지 motion/appearance task에서 평가한다. Motion understanding task는 SSv2, Diving-48, Jester이고, appearance understanding task는 K400, COIN, ImageNet이다.
V-JEPA 2 ViT-g는 motion understanding에서 다른 모든 video/image encoder를 크게 능가한다(SSv2 75.3, Diving-48 90.1). Appearance task에서도 competitive하며(K400 97.7, ImageNet 84.6), 6개 task 평균 87.5로 최고 성능을 달성한다. Higher resolution V-JEPA 2 ViT-g$_{384}$는 평균 88.2로 추가 향상된다.
Prediction: Probe-based Action Anticipation
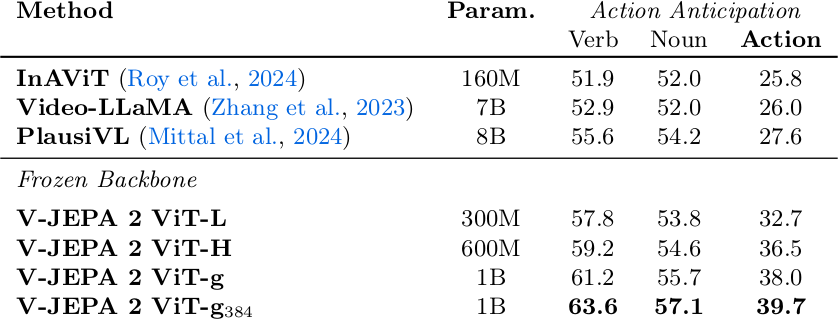
Epic-Kitchens-100 (EK100) benchmark에서 action anticipation 성능을 평가한다. Context video clip이 주어지면 1초 후의 action(verb + noun)을 예측하는 task이다. Frozen V-JEPA 2 encoder와 predictor 위에 attentive probe를 학습한다.
V-JEPA 2는 model size에 따라 linear하게 성능이 향상된다. ViT-g$_{384}$는 action recall-at-5 39.7을 달성하여, 8B parameter의 PlausiVL 대비 +12.1점(44% relative improvement)으로 SOTA를 달성한다.

Understanding: Video Question Answering
V-JEPA 2 encoder를 LLaVA framework으로 LLM과 align하여 Video QA를 수행한다. Vision encoder output을 learnable projector(MLP)로 LLM embedding space에 mapping한다. 3-stage progressive training을 수행한다: (1) projector만 학습, (2) large-scale image QA 학습, (3) large-scale video captioning/QA 학습.
Comparing with Image Encoders
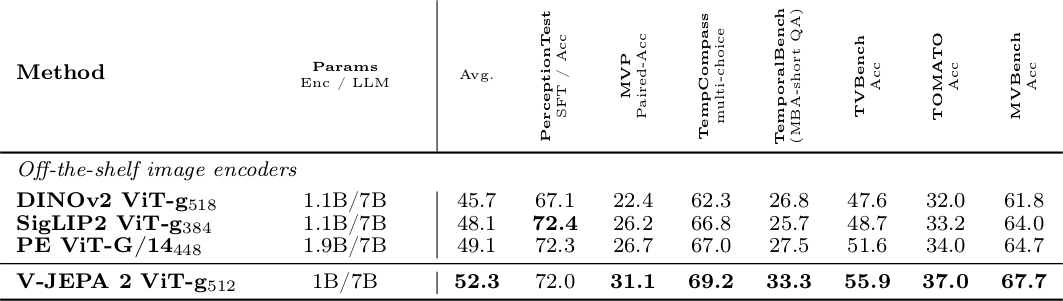
Controlled setup(동일 LLM backbone Qwen2-7B, 동일 데이터 18M sample, frozen vision encoder)에서 DINOv2, SigLIP-2, Perception Encoder와 비교한다. V-JEPA 2는 PerceptionTest를 제외한 모든 benchmark에서 image encoder를 능가한다. 특히 temporal understanding이 중요한 MVP, TemporalBench, TVBench에서 두드러진 향상을 보인다. Language supervision 없이 pretrained된 video encoder가 language-supervised image encoder를 능가할 수 있음을 입증한다.
Scaling Vision Encoder Size and Input Resolution
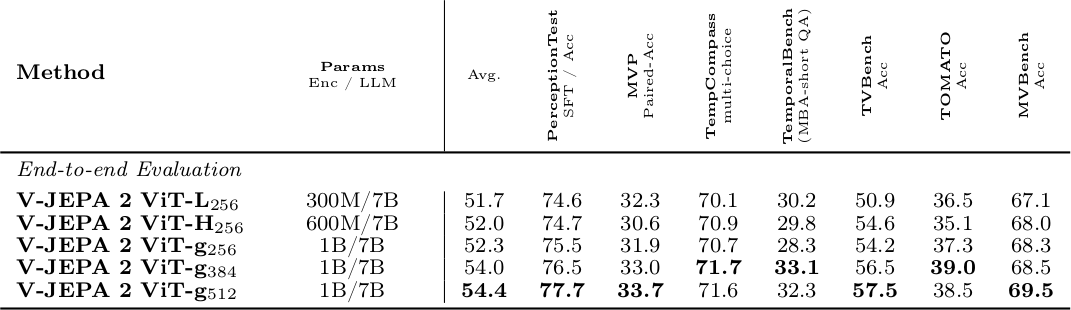
Vision encoder를 300M에서 1B로, input resolution을 256에서 512로 scaling하면 VidQA 성능이 일관되게 향상된다. ViT-g$_{512}$는 average 54.4로, encoder scaling과 resolution 증가 모두 유효하다.
Improving the State-of-the-Art by Scaling Data
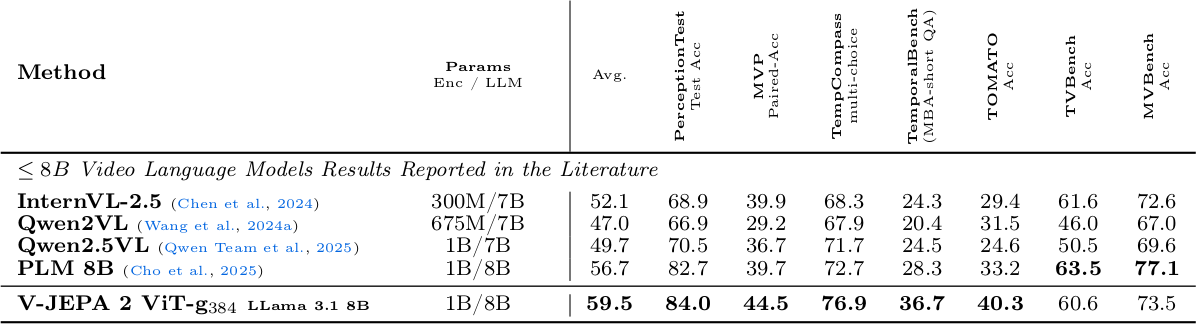
Alignment data를 88.5M sample로 확대하고 Llama 3.1 8B backbone을 사용하면, 8B 모델 클래스에서 multiple benchmark에서 SOTA를 달성한다. PerceptionTest 84.0(+1.3), MVP 44.5(+4.8), TempCompass 76.9(+4.2), TemporalBench 36.7(+8.4), TOMATO 40.3(+7.1)으로 이전 SOTA(PLM 8B) 대비 큰 향상을 보인다.
Conclusion
V-JEPA 2는 JEPA를 통한 self-supervised learning이 web-scale data와 소량의 robot interaction data로부터 understanding, prediction, planning이 가능한 world model을 만들 수 있음을 보여준다. Action classification에서 SOTA, action anticipation에서 SOTA, LLM과 align하여 VidQA에서도 SOTA를 달성한다. V-JEPA 2-AC는 62시간의 unlabeled robot data만으로 학습되어 새로운 환경에서 zero-shot prehensile manipulation을 수행한다.
향후 과제로는 16초 이상의 long-horizon prediction, language 기반 goal specification, 그리고 1B 이상으로의 추가 scaling이 있다.