Introduction
인간은 망막에서 오는 low-level 신호를 semantic한 spatio-temporal understanding으로 변환하는 능력을 갖고 있다. 이를 설명하는 유력한 가설은 시간적으로 인접한 sensory stimuli의 representation이 서로 predictive해야 한다는 것이다. 본 논문은 feature prediction이 video로부터 unsupervised visual representation을 학습하기 위한 standalone objective로서 얼마나 효과적인지를 연구한다.
V-JEPA는 pretrained image encoder, text, negative example, human annotation, pixel-level reconstruction 없이 오직 feature prediction만으로 학습된다. V-JEPA 모델은 약 2백만 개의 공개 비디오로 학습되며, downstream image/video task 모두에서 강력한 성능을 보인다. 핵심 결과는 다음과 같다:
- Feature prediction은 frozen backbone으로 motion 기반 task(SSv2)과 appearance 기반 task(K400) 모두에서 versatile한 representation을 학습한다. SSv2에서 기존 방법 대비 +6% 향상을 달성한다.
- Feature prediction으로 학습한 모델은 frozen evaluation에서 pixel prediction 방법보다 우수하며, fine-tuning 시에도 훨씬 짧은 training schedule로 대등한 성능을 달성한다.
- Feature prediction 모델은 label-efficient하다. Labeled example 수를 줄일수록 V-JEPA와 pixel-reconstruction 모델 간의 성능 gap이 더 벌어진다.
Related Work
Slow Features
Feature들이 시간적으로 천천히 변하도록 하는 접근법이다. 초기 연구(SFA, SSA, Simulated Fixations)는 spectral method나 contrastive estimation으로 temporal invariance를 구현했다. 본 논문은 temporal invariance를 넘어 masked modeling을 통한 feature prediction 방법을 탐구한다.
Predictive Features
한 time-step의 frame/clip representation을 다른 time-step의 representation으로 mapping하는 연구들이다. 기존 방법들은 frozen pretrained image/video encoder에 predictor를 얹어서 학습하거나, supervised action forecasting loss, contrastive loss 등의 추가 supervision을 필요로 했다. V-JEPA는 JEPA framework을 video data로 확장하여, 어떤 추가 supervision 없이 feature prediction만으로 encoder와 predictor를 동시에 학습한다.
Feature Prediction vs Pixel Reconstruction
Pixel space에서 prediction하는 방법은 세부 디테일까지 모두 표현하기 위해 상당한 capacity와 연산량을 소비해야 한다. 반면 latent space에서 prediction하는 방법은 필요한 정보와 무관하거나 예측하기 어려운 pixel-level detail을 배제하는 유연성을 가진다. 또한 linear probing이나 low-shot adaptation에서 우수하고, pretraining 시 효율성도 좋아진다. V-JEPA는 이를 video 도메인으로 확장한다.
Method: Video-JEPA
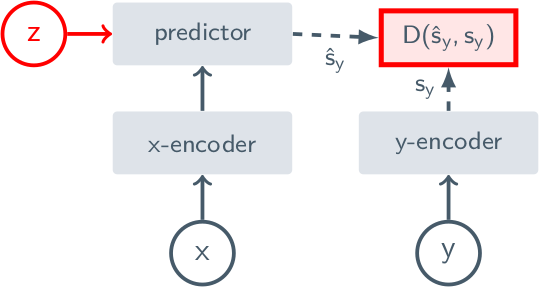
JEPA는 input $x$의 representation으로부터 다른 input $y$의 representation을 예측하는 모델로, 추가적인 변수 $z$는 $x$에서 $y$를 계산하는 데 필요한 transformation을 제공해 준다.
Training Objective
Visual encoder $E_\theta(\cdot)$를 학습하여, video의 한 부분 $y$에서 계산된 representation이 다른 부분 $x$에서 계산된 representation으로부터 predictable하도록 한다. Predictor network $P_\phi(\cdot)$는 $x$의 representation을 $y$의 representation으로 mapping하며, $y$의 spatio-temporal position을 나타내는 conditioning variable $z \leftarrow \Delta_y$를 입력받는다.
Naive한 regression objective는 encoder가 constant representation을 출력하는 trivial solution을 허용한다. 이를 방지하기 위해 다음의 modified objective를 사용한다:
$\text{minimize}_{\theta, \phi} \quad \| P_\phi(E_\theta(x), \Delta_y) - \text{sg}(\overline{E}_\theta(y)) \|_1$
여기서 $\text{sg}(\cdot)$는 stop-gradient operator이고, $\overline{E}_\theta(\cdot)$는 encoder $E_\theta(\cdot)$의 exponential moving average(EMA)이다. $\ell_1$ regression을 사용한다.
이론적으로, predictor가 optimal할 때 encoder의 expected gradient는 $\nabla_\theta \text{MAD}(Y | E_\theta(x))$가 되어, encoder는 target의 deviation을 최소화하기 위해 video에 대한 정보를 최대한 capture해야 한다. EMA를 사용하면 predictor가 encoder보다 빠르게 evolve하여 collapse를 방지한다.
Prediction Task: Predicting $y$ from $x$
Masked modeling formulation을 사용한다. Video에서 $y$는 여러 개의 spatially continuous block을 sampling하고, $x$는 그 complement이다. 큰 continuous block을 masking하는 것은 spatial/temporal redundancy로 인한 information leakage를 제한하고, 더 어려운 prediction task를 만든다.
두 종류의 mask를 사용한다.
- Short-range mask: 8개의 randomly sampled target block(각 frame의 15%)의 union. 전체 temporal dimension에 걸쳐 반복된다.
- Long-range mask: 2개의 randomly sampled target block(각 frame의 70%)의 union. 역시 전체 temporal dimension에 걸쳐 반복된다.
두 mask를 합치면 평균 약 90%의 masking ratio가 된다.
Network Parameterization
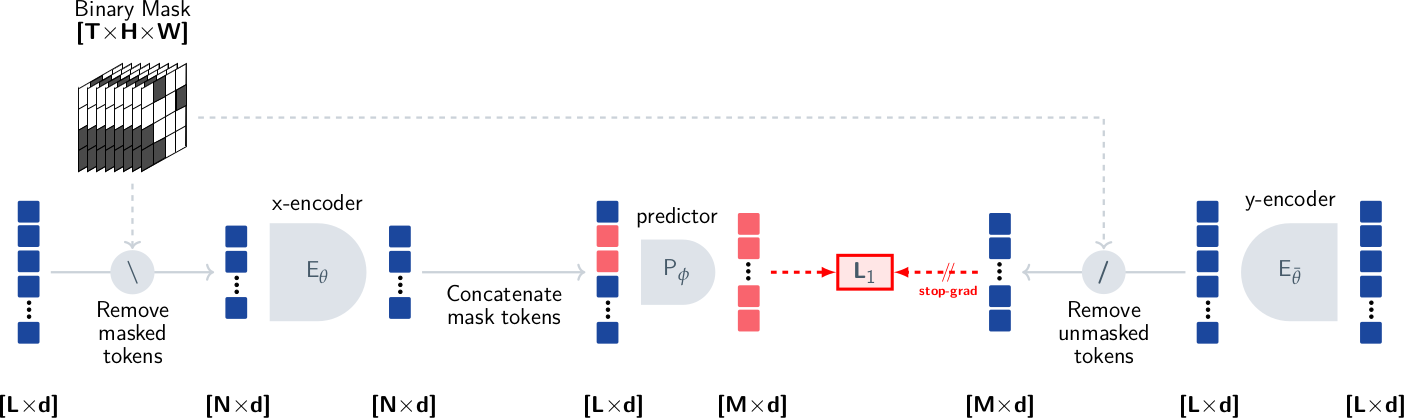
Vision Transformer(ViT)를 video backbone으로 사용한다. Video clip을 $16 \times 16$ pixel, 2 frame 크기의 spatio-temporal patch로 분할하여 token sequence를 생성한다. x-encoder의 경우 입력에 masking을 적용하여 visible token만 처리하고, y-encoder의 경우 output에서 masked position의 token만 추출하여 contextualized target을 구성한다.
Predictor는 12 block, embedding dimension 384의 narrow transformer로 구현된다. x-encoder의 output에 learnable mask token(masked position의 positional embedding 포함)을 concatenate하여 predictor에 입력하고, 각 mask token에 대한 embedding vector를 출력한다.
Pretraining Data and Evaluation Setup
여러 공개 dataset을 결합하여 VideoMix2M이라는 unsupervised pretraining dataset을 구성한다. HowTo100M(HT), Kinetics-400/600/700(K710), Something-Something-v2(SSv2)의 비디오를 합치고, validation set과의 overlap을 제거하여 약 2백만 개의 비디오를 확보한다. ViT-L/16, ViT-H/16, ViT-H/16$_{384}$ 세 가지 모델을 학습한다.
Downstream 평가는 video task(K400 action recognition, SSv2 motion classification, AVA action localization)와 image task(ImageNet, Places205, iNaturalist 2021)에서 수행한다. K400는 appearance 기반, SSv2는 motion 기반 understanding을 평가한다.
What Matters for Learning Representations from Video?
Predicting Representations vs Pixels

ViT-L/16 모델을 feature prediction loss(V-JEPA)와 pixel prediction loss(masked autoencoder)로 각각 학습하여 비교한다. Feature space에서 prediction하는 것이 frozen evaluation과 end-to-end fine-tuning 모두에서 pixel space prediction보다 일관되게 우수하다.
Pretraining Data Distribution
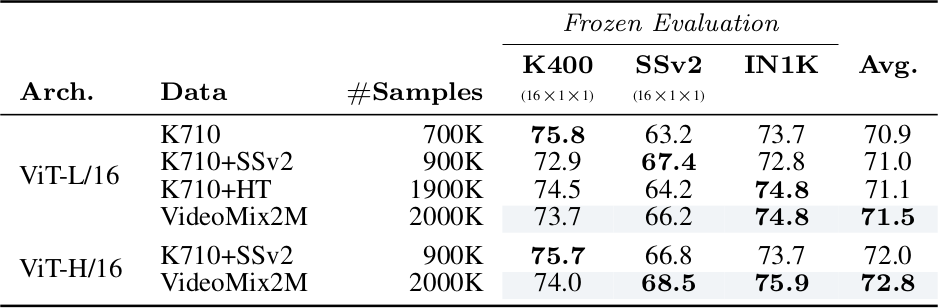
Pretraining dataset 크기가 커질수록 평균 성능이 monotonically 증가한다. 단, task-specific 최적 성능은 각 task에 맞는 data를 독립적으로 선택할 때 달성된다. 예를 들어 ViT-L/16은 SSv2 성능은 K710+SSv2에서, K400 성능은 K710 단독에서 최고이다. 모든 task의 평균 성능은 VideoMix2M에서 가장 높다.
Evaluation: Attentive Probing

V-JEPA의 prediction objective는 unnormalized이므로 encoder output이 linearly separable한 subspace를 형성할 이유가 없다. 따라서 average pooling 대신 learnable cross-attention layer를 사용하는 attentive probing을 도입한다. Learnable query token으로 cross-attention을 수행하고, 그 output을 query token에 residual connection으로 더한 뒤, 2-layer MLP와 linear classifier를 통과시킨다. Attentive probing은 K400에서 +17점, SSv2에서 +16.1점의 큰 향상을 가져온다.
Prediction Task: Masking Strategy

Masking 전략을 ablation한다: (1) random-tube[r]: tube(전체 temporal dimension에 걸친 spatial patch)의 fraction $r$을 random하게 제거, (2) causal multi-block[p]: $x$를 첫 $p$ frame으로 제한 후 multi-block masking, (3) multi-block: 전체 video에서 random spatio-temporal block masking. Multi-block이 가장 좋은 성능을 보인다. Causal multi-block은 $x$가 초기 frame에만 국한되어 성능이 하락하고, random-tube는 90%를 random하게 masking하면 low-semantic feature가 학습된다.
Comparison with Prior Work
Comparison with Pixel Prediction

동일한 ViT-L architecture를 사용하여 pixel prediction 방법(OmniMAE, VideoMAE, Hiera)과 비교한다. Frozen evaluation에서 V-JEPA는 ImageNet을 제외한 모든 downstream task에서 baseline을 능가한다. Fine-tuning에서도 ViT-L 모델 중 최고 K400 성능을 달성하고, SSv2에서는 Hiera-L에 match한다. 훨씬 적은 sample로 이 결과를 달성하여, feature prediction의 learning principle으로서의 효율성을 입증한다.
Comparison with State-of-the-Art
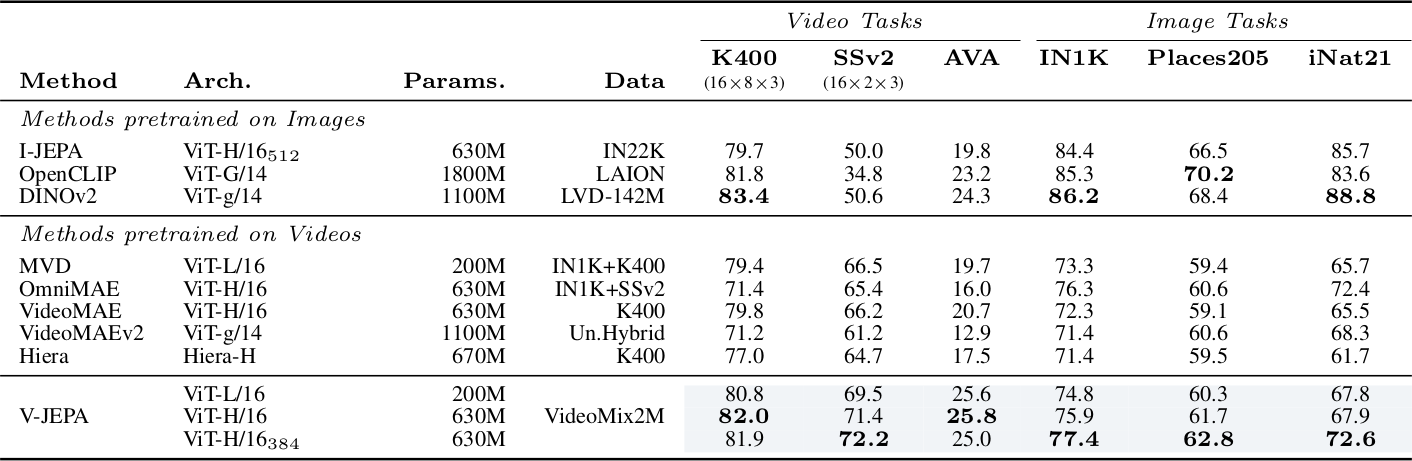
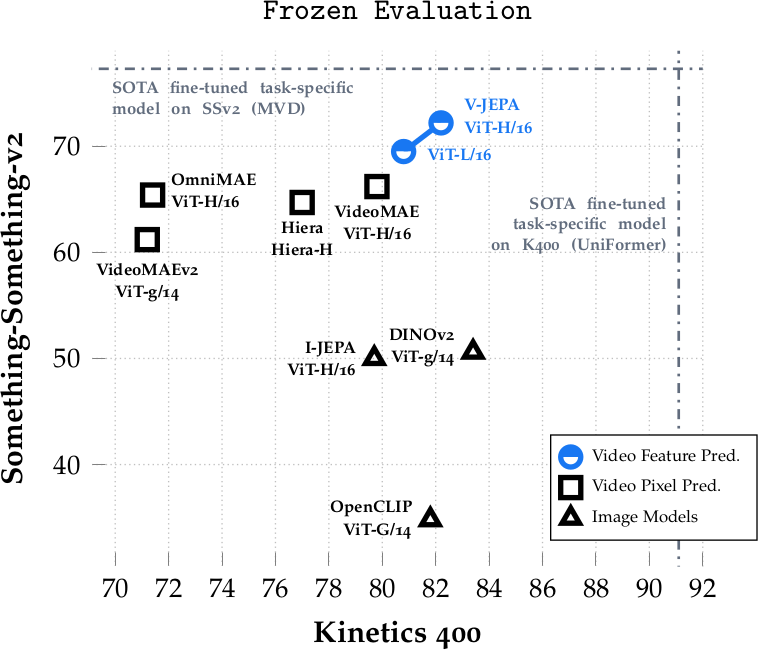
Frozen backbone에서 attentive probe를 학습하여 SOTA self-supervised image/video 모델과 비교한다. Video 모델 baseline(VideoMAE, OmniMAE, Hiera, VideoMAEv2, MVD)과 비교하여 V-JEPA는 모든 downstream video/image task에서 일관되게 우수하다. ViT-H/16 모델은 SSv2에서 +5점, K400에서 +2점, AVA에서 +5점, IN1K에서 +1점, Places205에서 +2점 향상을 보인다.
Image 모델(I-JEPA, OpenCLIP, DINOv2)과 비교하면, motion understanding이 필요한 SSv2에서 +21점 이상의 큰 향상을 보인다. K400에서는 appearance 기반으로 풀 수 있어 image 모델도 잘 수행하지만, V-JEPA도 competitive하다(H/16 기준 82.0% vs DINOv2 83.4%). Image task에서는 V-JEPA가 ImageNet에서 77.4%를 달성하여 video-only pretraining임에도 image 모델과의 gap을 줄인다.
Label Efficiency

Attentive probe를 학습할 때 사용하는 labeled example의 비율을 5%, 10%, 50%로 줄여가며 frozen model의 label efficiency를 비교한다. V-JEPA는 다른 self-supervised video 모델보다 label-efficient하다. Labeled example 수를 줄일수록 V-JEPA와 baseline 간의 성능 gap이 더 벌어진다. 예를 들어 K400에서 label을 10배 줄이면 V-JEPA는 12%p 하락하는 반면, VideoMAEv2는 30%p, VideoMAE는 16%p, MVD는 15%p 하락한다.
Evaluating the Predictor

V-JEPA predictor의 feature-space prediction을 시각적으로 분석하기 위해, pretrained encoder와 predictor를 freeze하고 conditional diffusion decoder를 학습하여 predicted representation을 pixel로 변환한다. Decoder는 masked region의 predicted representation만 입력받고, unmasked region에는 접근하지 않는다.
시각화 결과, V-JEPA의 feature prediction은 spatially/temporally grounded되어 있다. 다양한 random seed에서 공통적으로 나타나는 특성이 predictor representation에 encoding된 정보를 나타낸다. Predictor는 positional uncertainty를 올바르게 capture하며, 다양한 위치에서 consistent한 motion을 생성한다. 일부 sample은 partial occlusion 후에도 object가 유지되는 object permanence에 대한 이해도 보여준다.
Conclusion
본 논문은 feature prediction이 video로부터의 unsupervised learning을 위한 standalone objective로서 효과적임을 보였다. V-JEPA는 self-supervised feature prediction objective만으로 학습된 vision model family로, frozen backbone으로 다양한 downstream image/video task를 해결할 수 있다. Action recognition, spatio-temporal action detection, image classification에서 이전 video representation learning 방법을 능가한다. Video에서의 V-JEPA pretraining은 특히 fine-grained motion understanding이 필요한 downstream task에 효과적이며, label-efficient한 학습을 가능하게 한다.