Introduction
3D vision task를 위해서는 3D 데이터를 사용하는 것이 효과적이지만 데이터셋의 부족으로 인해 한계가 있다. UniVLG는 pre-trained 2D backbone과 함께 2D와 3D modality를 모두 입력받을 수 있는 새로운 decoder를 이용하여 2D 데이터를 효과적으로 3D 학습에 사용한다.
Method
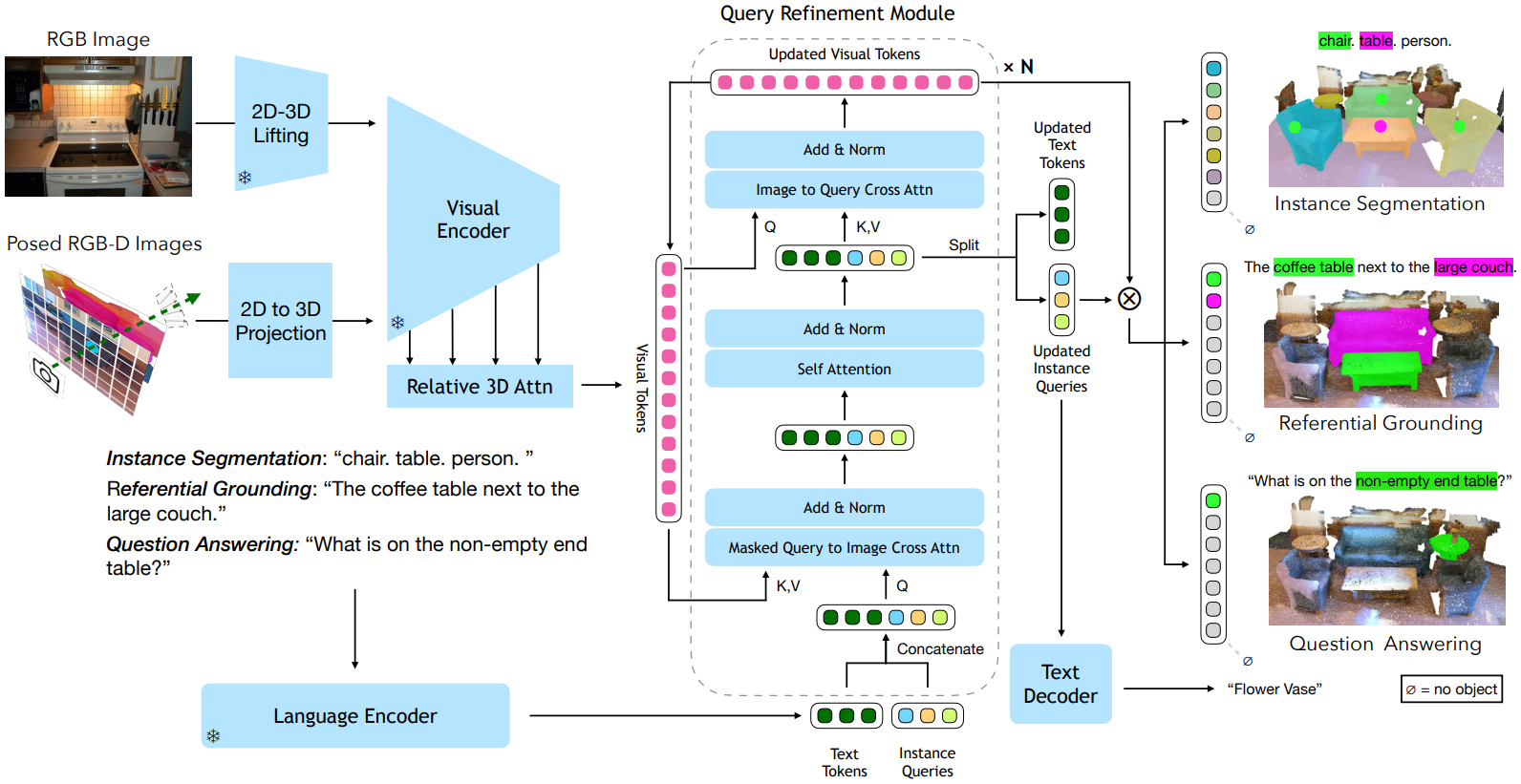
UniVLG 모델은 단일 RGB 이미지 또는 pose가 주어진 RGBD 이미지 시퀀스를 입력으로 받는다. ScanNet과 같이 RGBD 이미지의 경우 depth 정보에 따라 픽셀을 3D로 unprojection하고, 단일 RGB 이미지의 경우 depth prediction model을 이용해 예측한 depth를 이용해 픽셀을 unprojection한다. 이때 depth의 단위가 metric일 필요는 없다.
Visual and Language Encoder
입력된 이미지의 RGB 부분은 DINO VIT encoder로 입력된다. 이 encoder의 여러 layer의 feature map은 3D attention layer로 입력되는데, 이때 앞서 얻은 depth 정보가 positional embedding으로 사용된다.
텍스트 쿼리의 경우 JinaCLIP을 이용하여 토큰으로 변환된다. 단어의 개수가 $M$, embedding의 dimension이 $F$라면 토큰은 $M \times F$ 크기가 된다.
Language Conditioned Mask Decoder
Mask decoder는 트랜스포머 구조로, visual feature, text embedding을 입력으로 받아 언급된 object에 대한 3D segmentation mask를 출력한다.
우선 $M$개의 object query를 초기화한다. 이는 학습 가능한 벡터로, object instance를 decoding하는 데 사용된다. 이 object query를 앞서 구한 $M$개의 text token에 각각 concat한다.
이 $M$개의 벡터가 cross-attention의 query가 되고, visual feature는 key와 value가 된다. 이때 vanilla cross-attention 대신 Mask2Former의 구조를 사용한다. 각각의 query는 이전 layer에서 예측된 instance mask 내에 있는 point들만 attend하는 방식이다.
Cross-attention 이후 self-attention을 진행하여 업데이트된 text token과 object query를 얻는다.
그 후, 이번에는 visual feqture가 query가 되고 text와 object query가 concat된 벡터가 key, value가 되어 cross-attention을 진행한다. 이를 통해 visual feature도 업데이트한다. 본 논문에서는 이렇게 visual feature를 업데이트하는 것이 일반 3D segmentation이 아닌 3D referential grounding task에서 매우 중요하다고 한다.
최종적으로, 이렇게 업데이트된 visual feature와 M개의 업데이트된 object query를 각각 dot product해서 similarity를 구한다. 이 similarity score를 thresholding함으로써 텍스트 쿼리의 각 단어에 매칭되는 최종 segmentation mask를 구할 수 있다.
Supervision Objective
Mask Loss
Mask loss는 예측된 segmentation mask와 GT mask 사이의 유사도를 평가하는 loss이다. Binary cross-entropy와 Dice loss를 사용하였다.
Text Span Loss
예측된 3D object segmentation에 해당하는 object query와 입력 텍스트의 명사에 해당하는 language token과의 dot product를 하여 각 단어별 similarity score의 distribution을 구한다. 이 distribution을 binary cross-entropy로 학습시켜 매칭되지 않은 query는 작은 확률을 가지도록 한다.
Box Loss
Box loss는 본 논문에서 새롭게 제안한 loss이다. 이는 예측된 segmentation mask가 멀리 있는 점들을 소수 포함하는 경우, 또는 같은 물체 여러 개를 하나의 mask로 묶어 버리는 경우를 해결하기 위해 도입되었다.
Segmentation mask로부터 3D bbox를 구한 뒤 GT bbox와의 L1 loss와 GIoU 값을 얻어 box loss로 삼는다. 이를 통해 모델이 더 compact한 mask를 예측할 수 있도록 한다.
Text Generation Loss
Question answering task를 위해 UniVLG 모델은 텍스트를 출력하기도 하는데, 이 텍스트와 GT answer를 일반 cross-entropy를 이용해 학습한다.
최종 loss는 이 4가지 loss term을 합하여 아래와 같이 정의된다.
$\mathcal{L}_{\text{total}} = \lambda_{\text{mask}} \mathcal{L}_{\text{mask}} + \lambda_{\text{text}} \mathcal{L}_{\text{text}} + \lambda_{\text{box}} \mathcal{L}_{\text{box}} + \lambda_{\text{gen}} \mathcal{L}_{\text{gen}}$
Experiments
Evaluation on 3D Referential Grounding
BUTD-DETR의 setup에 따라, DET와 GT의 두 가지 셋업에서 실험을 진행하였다. DET는 GT bbox 없이 예측하는 실험이고 GT는 주어진 GT bbox 중에서 선택만 하는 실험이다. 또한 baseline 모델들을 mesh pc와 sensor pc로 구분하였는데, 센서로부터 얻은 raw point cloud를 바로 사용하면 sensor pc, 후처리가 적용된 mesh로부터 샘플링한 point cloud를 사용하면 mesh pc로 분류하였다. Raw point cloud에는 노이즈가 포함되어 있어 평가에 불리하게 작용하기 때문이다.
Metric으로는 top-1 accuracy를 사용한다. DET 셋업의 경우 bbox의 IoU가 특정 threshold (0.25, 0.5, 0.75) 이상일 때 정답인 것으로 본다. UniVLG는 bbox가 아닌 mask를 예측하기 때문에, mask로부터 bbox를 얻은 뒤 IoU를 구한다. GT 셋업의 경우, 주어진 GT bbox 내의 픽셀로부터 visual feature를 구하고 이를 pooling하여 mask별 하나의 feature를 얻는다. 이 feature들 중 정답 bbox에 해당하는 feature를 골랐을 때를 정답으로 본다.
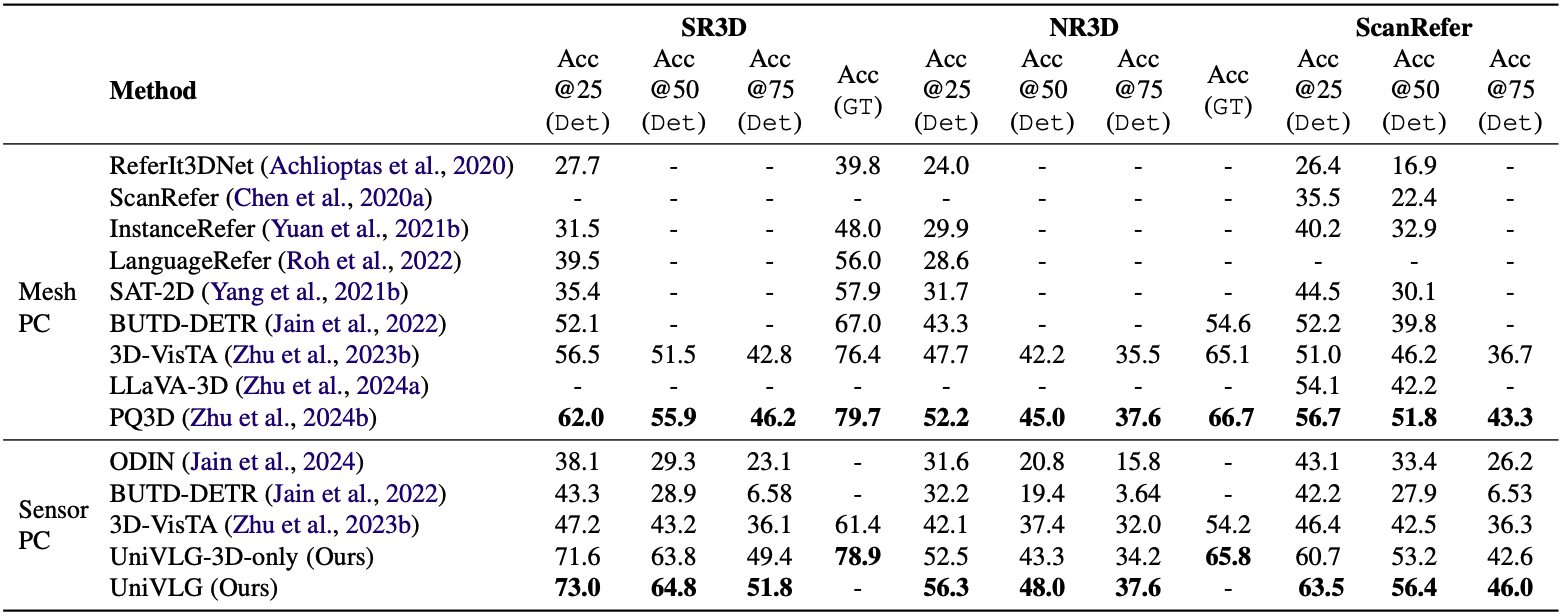
실험 결과는 위의 표와 같다. DET 셋업에서는 UniVLG가 가장 우수한 성능을 보인다. GT 셋업에서도 현재 SOTA 모델인 PQ3D와 유사한 결과를 보인다.
또한 3D 데이터만 이용해 학습했을 때보다 2D와 3D를 모두 이용했을 때 성능이 향상된 것도 확인할 수 있다.

Qualitative result는 위 그림과 같다.