Introduction
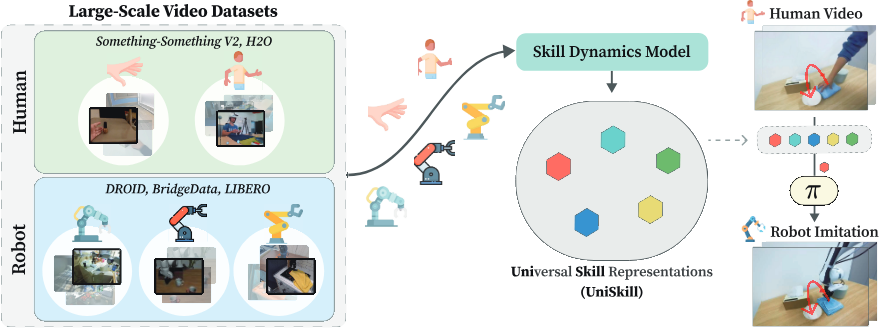
사람 비디오는 robot-specific 데이터 부족 문제를 해결하는 scalable한 접근법이다. Human-object interaction 같은 일상적 행동을 풍부하게 포함하며, 로봇 학습에 유용한 skill의 원천이 될 수 있다. 핵심 질문은: 로봇이 대규모 human demonstration을 관찰하여 cross-embodiment skill representation을 획득할 수 있는가?
기존 방법들은 human video를 robot-executable skill representation으로 변환하기 위해 paired human-robot dataset, predefined semantic skill label, 또는 multi-view camera setup과 task/scene alignment 등의 제약을 필요로 했다. 이는 real-world in-the-wild human video로의 scalability를 제한한다.
본 논문은 Universal Skill representation(UniSkill)을 제안한다. UniSkill은 대규모 in-the-wild video data에서 label이나 alignment 없이 embodiment-agnostic skill representation을 학습하여, unseen human video demonstration을 robot-executable skill sequence로 변환한다. 핵심 아이디어는 image-editing pipeline을 활용하여 video frame 간의 dynamic region(움직이는 부분)을 자연스럽게 강조하고, 그 결과의 motion pattern을 skill representation으로 encoding하는 것이다. 이를 통해 임의의 embodiment-agnostic video dataset을 학습에 사용할 수 있어, cross-embodiment skill representation learning을 web-scale로 확장할 수 있다.
Related Work
In-the-wild video에서 action (skill) representation을 학습하는 것은 action label이 없어 어렵다. Latent action model 연구(LAPO, Genie, LAPA)는 inverse/forward dynamics를 통해 action-relevant information을 추출하지만, 학습된 latent action을 pseudo label로만 활용한다. UniSkill은 latent action을 explicit skill representation으로 취급하고, 이에 직접 conditioned되는 policy를 학습한다.
또 다른 연구 방향은 2D/3D trajectory나 flow field 같은 explicit action representation을 통해 human video에서 robot으로 정보를 transfer하는 것이다. MimicPlay, EgoMimic, Motion Tracks는 multi-view video나 wearable sensor에서 3D hand trajectory를 추출하고, ATM과 Im2Flow2Act는 task-labeled video에서 2D motion path나 flow를 예측한다. 이들은 calibrated camera, pose tracking, environment-specific 제약이 필요하여 off-the-shelf video dataset으로의 확장이 어렵다. UniSkill은 raw RGB video에서 직접 학습하여 이런 제약을 완전히 제거한다.
가장 유사한 연구인 XSkill은 Sinkhorn-Knopp clustering으로 human과 robot video 간 skill을 align하여 embodiment-agnostic skill prototype을 학습한다. 그러나 shared prototype 기반 clustering이 human-robot video 간의 domain/task alignment을 암묵적으로 가정한다. UniSkill은 future frame forecasting을 통한 predictive representation 학습으로 이 제약을 완전히 제거하여, 전혀 관련 없는 human video에서도 유용한 skill을 학습할 수 있다.
Method
Problem Formulation
Cross-embodiment imitation 문제를 다룬다: skill-conditioned robot policy $\pi(\mathbf{o}_t, \mathbf{z}_t)$가 다른 embodiment(예: 인간)의 prompt video $\mathcal{V}^p = \{I_1^p, \ldots, I_{N_p}^p\}$에서 시연된 behavior를 재현한다. Prompt video에서 뽑은 temporally distant frame pair $(I_t^p, I_{t+k}^p)$로부터 embodiment-agnostic skill representation $\mathbf{z}_t$를 추출하고, 이를 robot policy에 conditioning한다.
학습에는 두 종류의 dataset을 사용한다: (1) 대규모 unlabeled cross-embodiment video dataset $\mathcal{D}_u$ (human + robot video, raw RGB frame만 포함), (2) 소규모 robot demonstration dataset $\mathcal{D}_a$ (observation-action pair 포함). $\mathcal{D}_u \gg \mathcal{D}_a$이며, prompt video $\mathcal{V}_p$는 학습 시 사용되지 않는다.
Universal Skill Representation Learning
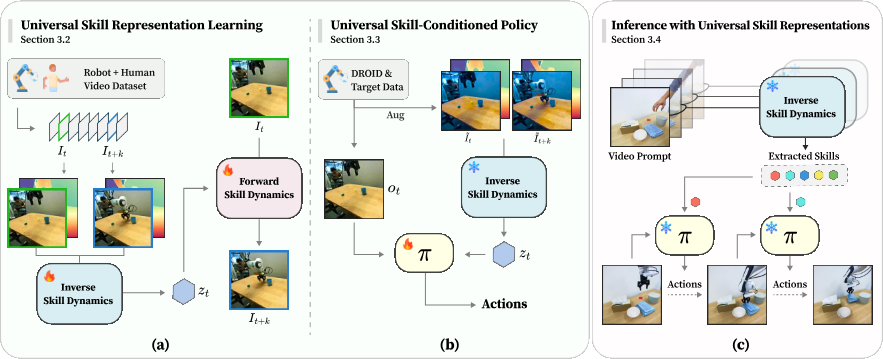
Latent skill $\mathbf{z}_t$가 두 frame $I_t$와 $I_{t+k}$ 사이의 dynamics를 효과적으로 압축하되, embodiment-agnostic해야 한다는 요구사항을 충족하기 위해, Inverse Skill Dynamics(ISD) 모델과 Forward Skill Dynamics(FSD) 모델을 jointly 학습한다.
Inverse Skill Dynamics Model (ISD)
Temporally distant한 두 frame $I_t$와 $I_{t+k}$를 입력으로 받아 universal skill representation $\mathbf{z}_t$를 출력한다:
$\mathbf{z}_t = ISD(I_t, I_{t+k})$
Raw RGB frame에만 의존하면 demonstrator의 외형이나 scene context 같은 embodiment-specific detail이 encoding될 수 있다. 이를 완화하기 위해, 각 frame에 대해 off-the-shelf monocular depth estimator로 depth map을 생성하여 intermediate representation으로 활용한다(외부 depth input 불필요, 모델 내부에서 predicted depth 사용).
Forward Skill Dynamics Model (FSD)
현재 frame $I_t$와 skill representation $\mathbf{z}_t$가 주어졌을 때 future frame $I_{t+k}$를 예측한다:
$I_{t+k} = FSD(I_t, \mathbf{z}_t)$
$\mathbf{z}_t = I_{t+k}$라는 trivial solution을 방지하기 위해 $\mathbf{z}_t$에 information bottleneck을 적용한다. $I_t$와 $I_{t+k}$가 같은 video의 $k$ frame 차이이므로, dynamics가 전체 scene에서 embodiment와 관련된 부분에만 minimal한 변화를 유발한다. 따라서 이 prediction을 image editing task로 formulate한다: diffusion 기반 image editing method인 InstructPix2Pix를 채택하여, language instruction 대신 skill representation $\mathbf{z}_t$로 conditioning한다. Latent diffusion objective를 최소화하여 ISD가 dynamic information을 $\mathbf{z}_t$에 compactly encode하도록 유도한다.
Universal Skill-Conditioned Policy
Robot policy network $\pi_\phi(\mathbf{a}_{t:t+h} \mid \mathbf{o}_t, \mathbf{z}_t)$를 학습한다. Robot dataset $\mathcal{D}_a$에서 두 observation $\mathbf{o}_t$, $\mathbf{o}_{t+k}$를 sampling하고, pre-trained frozen ISD로 skill representation $\mathbf{z}_t = ISD(I_t, I_{t+k})$를 추출한다. Policy $\pi_\phi$는 $\mathbf{o}_t$와 $\mathbf{z}_t$에 conditioned되어 action sequence $\mathbf{a}_{t:t+h}$를 예측한다. Behavioral cloning으로 학습한다:
$\phi^* = \text{argmax}_\phi \mathbb{E}_{(\mathbf{o}_t, \mathbf{o}_{t+k}, \mathbf{a}_{t:t+h}) \sim \mathcal{D}_a} [\log \pi_\phi(\mathbf{a}_{t:t+h} \mid \mathbf{o}_t, \mathbf{z}_t)]$
Cross-embodiment imitation 실험에서, policy는 학습 시 robot video에서 추출한 $\mathbf{z}_t$를 받지만, inference 시에는 다른 embodiment의 video에서 추출한 $\mathbf{z}_t$를 받는다. 이 discrepancy를 완화하기 위해, 학습 시 $I_t$와 $I_{t+k}$ 모두에 augmentation을 적용하여 $\tilde{I}_t$, $\tilde{I}_{t+k}$를 생성하고, 이로부터 추출한 skill로 conditioning한다.
Cross-Embodiment Imitation with Universal Skill Representations
Inference 시, prompt video $\mathcal{V}_p$에서 frozen ISD로 skill representation set $\{\mathbf{z}_i\}_{i=1}^{N_z}$를 추출한다($N_z < N_p$). Skill-conditioned policy $\pi_\phi$가 각 $\mathbf{z}_i$에 순차적으로 conditioning되어 해당 action을 실행한다. ISD가 학습한 universal skill representation 덕분에, $\pi_\phi$는 어떤 embodiment의 video prompt에도 conditioning될 수 있다.
Experiments
Experimental Setup
대규모 cross-embodiment video dataset에서 학습한다:
- Human video: Something-Something V2(egocentric simple action), H2O(ego-centric + third-person, two-handed manipulation)
- Robot video: DROID(Franka), BridgeV2(WidowX 250), LIBERO(simulated Franka)
Real-world 실험은 Franka robot으로 5개 tabletop task와 3개 kitchen task를 수행하며, task당 100개 demonstration으로 skill-conditioned policy를 fine-tune한다. Tabletop 평가에서는 Franka prompt(same embodiment)와 Human prompt(unseen embodiment) 두 유형으로 평가하고, kitchen benchmark에서는 추가로 Anubis prompt(unseen Aloha-like robot, unseen environment)도 사용한다. LIBERO simulation benchmark에서도 8개 task를 평가한다.
Baselines
- GCBC (Goal-Conditioned Behavioral Cloning): Goal image에 conditioning하는 diffusion-policy 기반 baseline. Hindsight relabeling으로 학습하며, inference 시 20 frame 앞의 sub-goal image에 conditioning한다. Skill representation 대신 goal image를 사용하는 것 외에 모든 조건이 동일하다.
- XSkill: Self-supervised learning으로 cross-embodiment shared skill representation을 학습하는 방법. Scene-aligned dataset이 필요하며, human demonstration이 robot과 동일한 environment에서 동일한 task를 수행해야 한다. 이 데이터 없이는 모든 tabletop task에서 0% 성공률을 보인다.
Cross-Embodiment Imitation
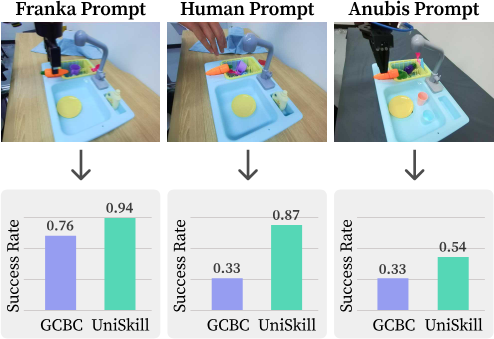
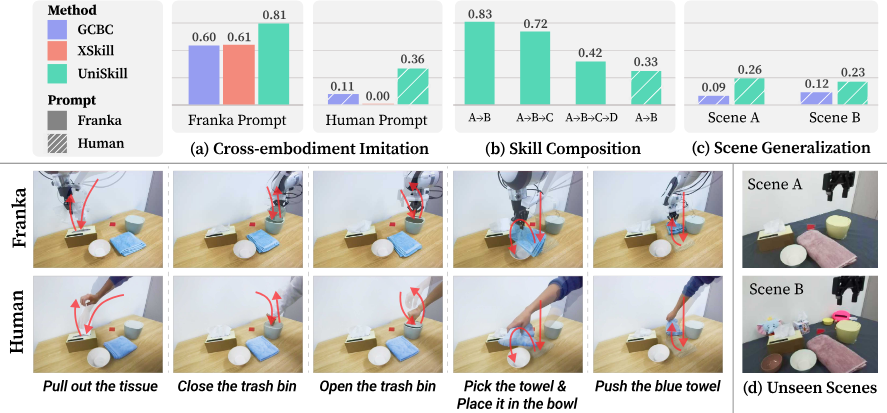
UniSkill은 real-world tabletop, kitchen benchmark, LIBERO simulation 모두에서 baseline을 consistently 능가한다. XSkill은 scene-aligned human demonstration이 추가로 제공되어도 human prompt에 대한 imitation에 실패하는데, 이는 CLIP 기반 contrastive learning이 frame 간 dynamics를 효과적으로 포착하지 못하기 때문이다. 반면 UniSkill의 image-editing 기반 objective는 temporal dynamics를 명시적으로 모델링하여 human과 Anubis(전혀 다른 morphology의 unseen robot) prompt 모두에 잘 일반화한다.
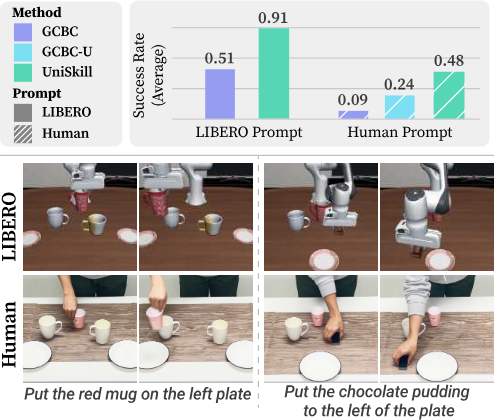
Cross-Embodiment Skill Representations
Unseen Compositional Tasks
ISD가 두 frame 사이의 motion pattern을 low-level skill로 압축하므로, 개별 task demonstration으로만 학습해도 inference 시 skill을 조합하여 novel task combination을 수행할 수 있다. Tabletop benchmark에서 skill composition 평가 결과, GCBC는 모든 조합에서 실패하는 반면 UniSkill은 human prompt에서도 robust한 성능을 보인다. 이는 UniSkill이 특정 task에 overfitting하지 않고 diverse skill의 combinatorial space를 포착함을 시사한다.
Unseen Environments
배경과 물체를 변경한 Scene A와 distractor를 추가한 Scene B에서 평가한다. UniSkill은 novel하고 visually modified된 scene에서도 comparable한 성능을 유지하여 background과 distractor variation에 resilient함을 보인다. LIBERO simulation에서도 human prompt가 전혀 다른 환경에서 촬영되었음에도 성공적으로 의도된 task를 추론하고 실행한다.
Benefits of Human Videos
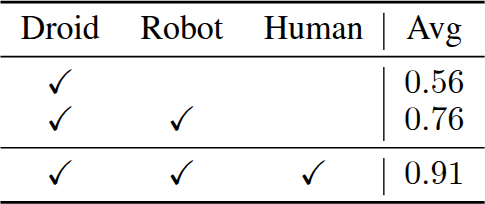
Training dataset의 영향을 분석한다. DROID만 사용 시 평균 0.56, robot dataset(BridgeV2, LIBERO) 추가 시 0.76으로 20%p 향상, 대규모 human video(Something-Something V2, H2O) 추가 시 0.91로 15%p 추가 향상된다. UniSkill이 robot dataset scaling뿐 아니라 diverse human video 활용에서도 이점을 얻으며, embodiment-agnostic skill representation learning의 효과를 입증한다.
Dynamic Information Capture
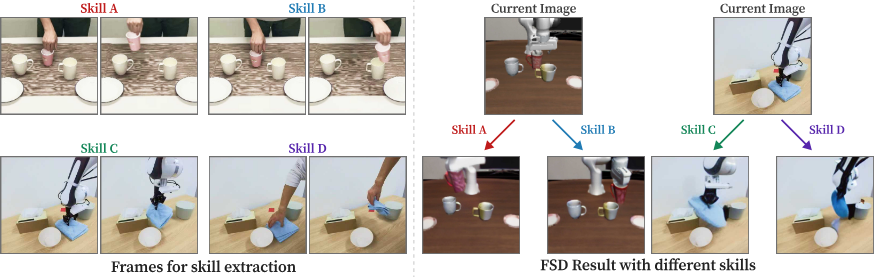
FSD를 이용한 future frame prediction의 qualitative 결과를 분석한다. 동일한 current image에 서로 다른 skill representation $\mathbf{z}_t$를 conditioning하면, encoding된 motion에 따라 predicted future frame이 달라진다. 이는 skill representation이 meaningful한 motion dynamics를 포착함을 확인한다.
Embodiment-Agnostic Properties
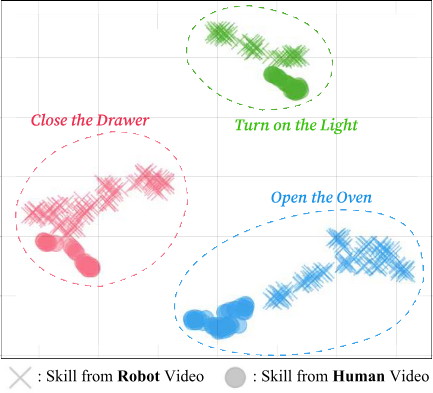
FSD로 predicted된 future frame이 skill representation이 다른 embodiment에서 추출되었더라도 원래 embodiment를 올바르게 보존한다. 이를 활용하여 GCBC의 sub-goal image를 FSD-predicted frame으로 교체한 GCBC-U variant를 도입하면 15%p 성능 향상을 달성한다. t-SNE visualization에서 UniSkill embedding은 embodiment-specific cluster가 아닌 task-specific cluster를 형성하여, representation 자체가 embodiment-agnostic skill을 encode함을 보여준다.
Conclusion
본 논문은 scene-aligned cross-embodiment dataset 없이 cross-embodiment imitation을 달성하는 UniSkill을 제안했다. 대규모 unlabeled video dataset에서 embodiment-agnostic skill representation을 학습하고, 이를 통해 human video prompt를 robot-executable skill sequence로 변환한다. Simulation과 real-world 모두에서 기존 방법을 능가하며, compositional task와 unseen environment로의 일반화, human video 활용에 따른 성능 향상, embodiment-agnostic representation의 t-SNE 시각화 등을 통해 학습된 skill representation의 효과를 검증했다.
Limitations
UniSkill은 세 가지 주요 한계가 있다. 첫째, fixed skill interval에 의존하여 human과 robot 간의 execution speed 차이에 적응하기 어렵다. 둘째, egocentric human video처럼 abrupt viewpoint change가 있는 video에서 coherent한 dynamic information 추출이 어렵다. 셋째, language instruction과 같은 semantic cue 없이 motion imitation에만 의존하므로 robotic behavior가 잘 드러나는 prompt video에서 잘 동작한다. 향후 VLA framework과의 통합이 유망한 방향으로 제시된다.