Introduction
3D Gaussian Splatting과 open-vocabulary scene understanding을 결합하면 텍스트를 통해 scene과 상호작용할 수 있다. 기존 연구에서는 2D 또는 3D 기반의 language feature를 3DGS에 distillation하는 방식을 사용한다.
본 논문에서 지적한 기존 연구의 문제점은 복잡하고 디테일이 많은 scene에서 segmentation에 어려움을 겪는다는 것이다. 특히, LangSplat과 같은 경우 2D VLM의 고차원 feature를 저차원으로 축소해야 하기 때문에 중요한 정보가 손실될 수 있다는 문제가 있다.
SuperGSeg는 LangSplat을 기반으로 만들어진 모델로, Neural Gaussian과 Super-Gaussian을 이용하여 정보 손실 없이 더 정밀한 scene representation이 가능하다. Neural Gaussians를 활용하여 2D VLM으로부터 얻은 instance 및 hierarchical segmentation features를 학습하며, Super-Gaussians을 생성하여 2D language features를 3D space로 효과적으로 distill한다.
Related Work
3D Gaussian Splatting
3DGS는 공간상의 3D 가우시안을 이용하여 3D scene을 표현하는 방식이다. 그 중 Scaffold-GS는 anchor point를 활용하여 hierarchical, region-aware 3D scene representation을 도입했다. 각 anchor points는 Neural Gaussian과 연결되어 있는데, anchor feature를 이용하여 가우시안의 파라미터를 학습한다. SuperGSeg는 Scaffold-GS를 확장하여 semantic과 language features까지 포함한다. 이를 통해 language query를 활용한 3D semantic segmentation이 가능하다.
Open-Set Segmentation
Open-vocabulary 상황에서 segmentation을 수행하기 위해 LERF, SPInNeRF, SA3D, OmniSeg3D 등의 모델이 제안되었다.
3D Open-Vocabulary Understanding
SAM, CLIP, DINO 등 2D 모델을 3D scene representation에 적용하려는 연구가 진행되고 있다. 특히 LangSplat과 같이 2D 기반 방식은 multi-view consistency를 활용하여 2D language features를 3D로 lift한다. 하지만 2D VLM의 고차원 feature를 저차원으로 축소해야 하기 때문에 중요한 정보가 손실될 수 있고, occlusion에 취약하며, 3D language query를 수행하지 못한다는 문제가 있다.
3D 기반 방식인 OpenGaussian는 coarse-to-fine codebook을 도입하여 3D point-level open-vocabulary segmentation을 수행한다. 하지만 pixel-level semantic segmentation이 어렵고, alpha blending을 decoupling하는 방식으로 인해 overlap이 있는 영역에서 semantic prediction의 신뢰성이 떨어지는 문제가 있다.
Method
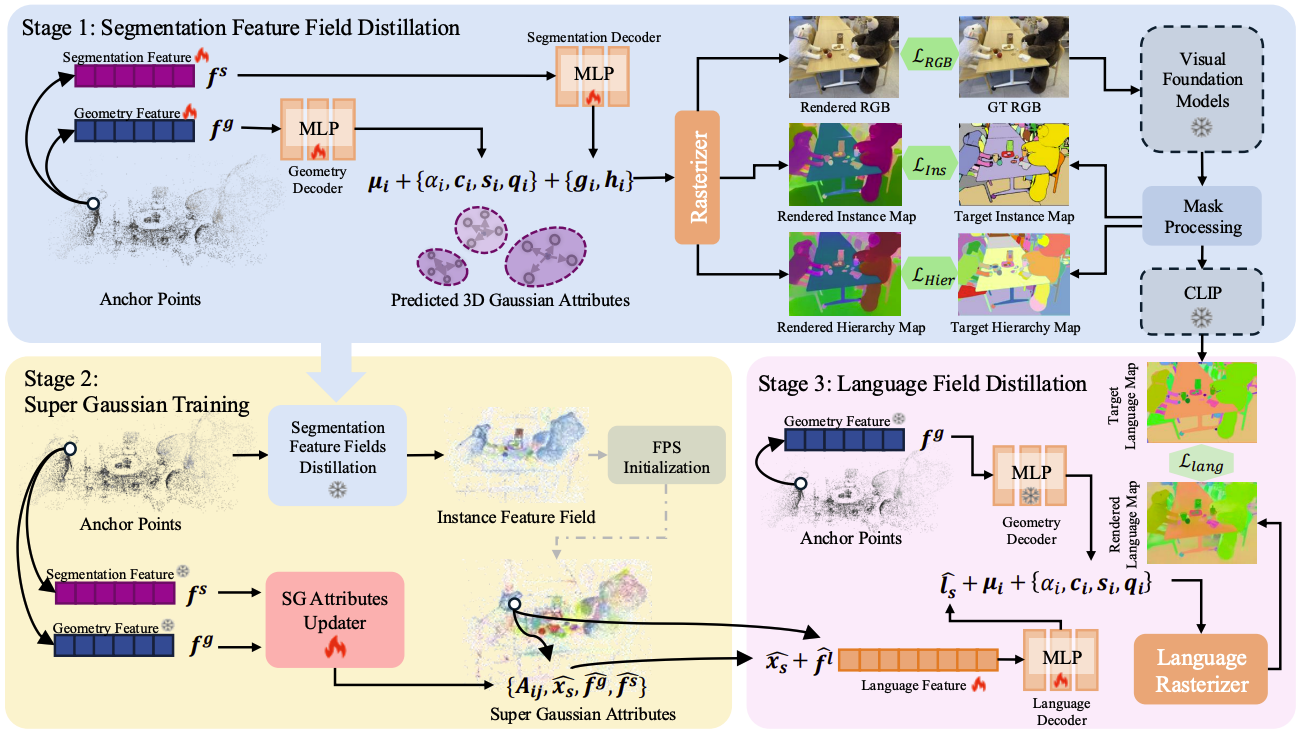
Neural Gaussian Splatting
각각의 3D 가우시안들에 고차원 feature vector를 할당하는 것은 비효율적이기 때문에, Scaffold-GS의 neural Gaussian을 도입한다. 먼저 3D 공간을 voxelize한 후, sparse한 anchor point를 생성한다. 각 anchor point는 그 점의 위치 $\mathbf{x}$, geometry feature $\mathbf{f}^g \in \mathbb{R}^{32}$, segmentation feature $\mathbf{f}^s \in \mathbb{R}^{32}$로 구성되어 있다.
$\mathbf{f}^g$는 MLP $F_\alpha, F_c, F_q, F_s$를 통해 그 anchor에 속한 가우시안들의 opacity, color, rotation, scale을 생성할 수 있고, $\mathbf{f}^s$는 MLP $F_g, F_h$를 통해 각 가우시안의 instance feature와 hierarchical feature를 생성한다.
가우시안의 중심점 $\mu$는 $\{\mu_0, \dots, \mu_{k-1} \} = \mathbf{x} + \{\mathbf{O}_0, \dots, \mathbf{O}_{k-1} \} \cdot l$로 계산되는데, 이때 $\mathbf{O}_i$는 learnable parameter이고 $l$은 그 anchor에 부여된 scaling factor이다. $k$는 해당 anchor에 속한 가우시안의 개수이다.
Segmentation Feature Field Distillation
LangSplat과 같이 기존 연구들은 각각의 granularity에 대해 따로 segmentation을 수행했으나, SuperGSeg는 instance-level과 hierarchical-level feature field를 동시에 학습한다.
SAM Mask Processing
SAM에서 생성된 2D binary segmentation mask를 $\mathcal{M}_{sam} = \{ M_m \in \mathbb{R}^{H \times W} \mid m = 1, \dots, |\mathcal{M}_{sam}| \}$라 하자. SAM mask는 multi-view consistency가 없기 때문에, 이를 해결하기 위해 먼저 mask가 겹치는 영역을 전부 개별 패치 $P_{hier}$로 나눈다. 이후 두 patch $P_i, P_j$의 correlation을 계산하는데, 두 patch가 동시에 속한 mask의 수로 정의한다. 이후 이러한 patch들을 overlap이 없는 instance mask $\mathcal{M}_{ins}$로 묶는다.
Instance and Hierarchical Feature Field
우선 각 anchor의 segmentation feature $\mathbf{f}^s$를 decode하여 $k$개의 instance feature $g$와 $k$개의 hierarchical features $h$를 얻는다. $k$는 해당 anchor에 속한 가우시안의 개수이다. 이후 이 feature들은 일반적인 가우시안 렌더링 수식을 통해 렌더링되어 instance feature map $\hat{G} \in \mathbb{R}^{16 \times H \times W}$와 $\hat{H} \in \mathbb{R}^{16 \times H \times W}$를 얻는다.
Multi-view consistency를 유지하면서 $\hat{G}$와 $\hat{H}$를 학습시키기 위해 OmniSeg3D의 contrastive learning을 사용한다. 즉, 같은 instance mask $\mathcal{M}_{ins}$나 같은 hierarchical patch $P_{hier}$에 속한 픽셀의 feature끼리는 유사해지고 아닌 픽셀의 feature끼리는 멀어지도록 한다.
렌더링된 RGB, $\hat{G}$, $\hat{H}$를 각각 GT RGB, target instance 및 hierarchy map과 비교하여 얻은 loss term을 각각 $\mathcal{L_c}, \mathcal{L}_g, \mathcal{L}_h$라 하면 이 단계에서의 loss는 아래와 같다.
$\mathcal{L}_{stage1} = \mathcal{L}_c + \lambda_g \mathcal{L}_g + \lambda_h \mathcal{L}_h$
Feature Distillation with Super-Gaussian
LangSplat과 같이 기존 연구들은 각 Gaussian에 개별적으로 language features를 부여했는데, 이러한 경우 각 instance를 구성하는 가우시안끼리 semantic inconsistency가 발생할 수 있다. 특히 여러 view에서 다른 instance mask에 속하거나 occluded된 영역에서는 일관된 feature 학습이 어렵다.
이를 해결하기 위해 본 논문에서는 Super-Gaussian이라는 sparse scene representation을 도입하여 고차원 language feature를 효율적으로 distill한다.
Super-Gaussian Initialization
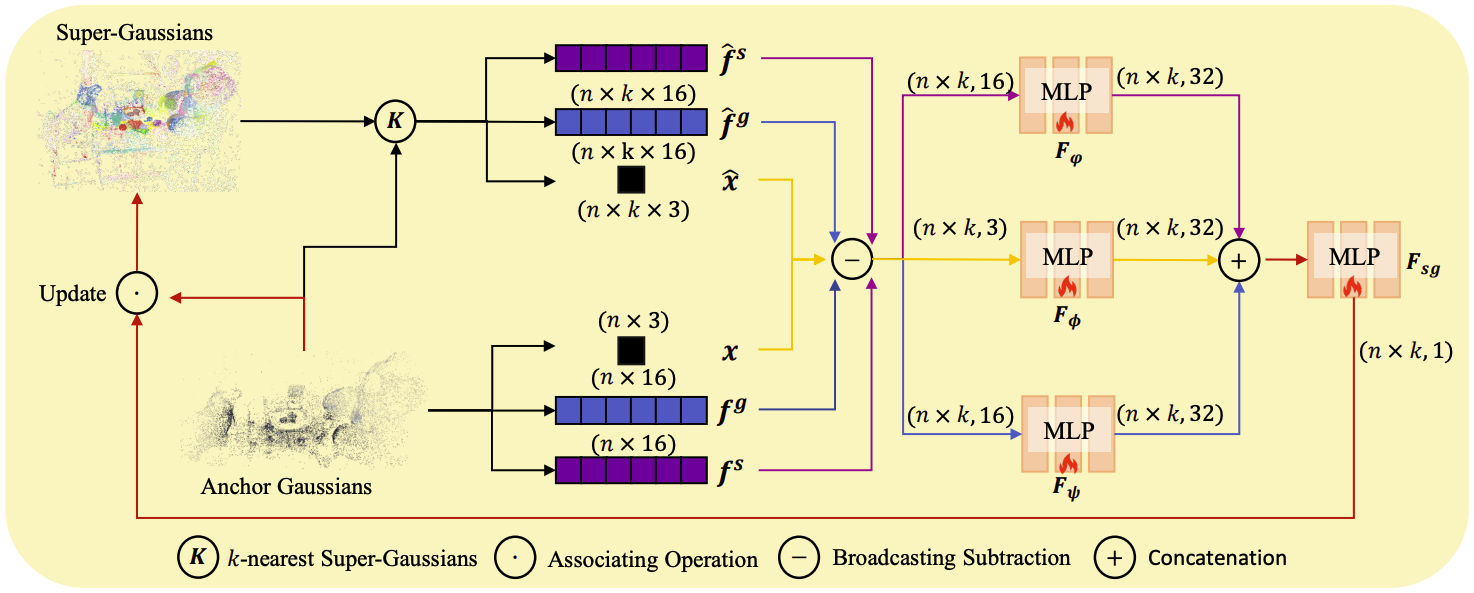
Super-Gaussian은 비슷한 instance 및 hierarchy feature를 가지는 neural Gaussian들의 그룹이다. Super-Gaussian을 초기화하기 위해 Farthest Point Sampling (FPS) 알고리즘을 사용하는데, point cloud와 샘플링한 점의 개수가 주어졌을 때 최대한 균등한 간격으로 점들을 고르는 방법이다.
S개의 Super-Gaussians의 중심점 $\hat{x}_s$가 주어지면 각 Super-Gaussian의 segmentation feature $\hat{f^s}$와 geometry feature $\hat{f^g}$를 랜덤으로 초기화한다.
이후 각 anchor와 Super-Gaussian pair에 대해 association probability를 구한다. $i$번째 anchor에 대해 k-nearest neighbor를 사용하여 가장 가까운 $k$개의 Super-Gaussian을 찾는다. 이 집합을 $\mathcal{N}_i$라 하자. 이후 $i$번째 anchor와 $j$번째 Super-Gaussian의 위치, geometry feature, segmentation feature를 아래와 같이 비교한다.
$\begin{gather} \phi(x_i, \hat{x}_j) = F_\phi (x_i - \hat{x}_j) \\ \varphi(f_i^s, \hat{f_j^s}) = F_\varphi (f_i^s - \hat{f_j^s}) \\ \psi(f_i^g, \hat{f_j^g}) = F_\psi (f_i^g - \hat{f_j^g}) \end{gather}$
이때 $F_\phi, F_\varphi, F_\psi$는 모두 MLP이다. 이렇게 얻은 MLP의 결과들을 모두 concat하여 또 다른 MLP $F_{sg}$에 입력하고 softmax를 취하면 association $A_{ij}$를 얻을 수 있다.
$A_{ij} = \text{softmax} \left( F_{sg} \left( \phi(x_i, \hat{x}_j) \parallel \varphi(f_i^s, \hat{f_j^s}) \parallel \psi(f_i^g, \hat{f_j^g}) \right) \right)$
Super-Gaussian Update
위에서 계산한 association probability $A \in \mathbb{R}^{N \times k}$를 이용하여 Super-Gaussian의 파라미터 $\hat{x}_s, \hat{f^s}, \hat{f^g}$를 iterative하게 업데이트한다. $N$은 anchor의 총 개수이다. 구체적으로, 각 anchor의 파라미터 $x_s, f^s, f^g$를 $A$를 이용하여 weighted sum한다.
$\hat{x}_j = \cfrac{1} {\sum\limits_{j=i}^{n} \mathbb{I}(j \in \mathcal{N}_i) A_{ij}} \sum\limits_{i=1}^{N} \mathbb{I}(j \in \mathcal{N}_i) A_{ij} x_i$
이때 $\mathbb{I}$는 indicator function으로, 괄호 안의 조건이 만족되면 1, 아니면 0을 반환한다.
이러한 Super-Gaussian의 feature들을 이용해 다시 anchor의 feature를 reconstruction할 수 있는지를 loss term으로 사용한다.
$\mathcal{L}_{recon, x} = \cfrac{1}{N} \sum\limits_{i=1}^{N} \left\| x_i, \sum\limits_{j \in \mathcal{N}_i} A_{ij} \hat{x}_j \right\|$
여기에 더해 아래 수식과 같이 compactness loss도 사용하는데, 두 anchor가 하나의 Super-Gaussian과 연결되어 있지만 두 anchor의 위치 자체는 멀리 떨어져 있는 경우를 처리하기 위해서이다.
$\mathcal{L}_{compact, x} = \cfrac{1}{S} \sum\limits_{j=1}^{S} \left\| \mathcal{X}_j - \hat{x}_j \right\|$
즉, Super-Gaussian이 연결된 anchor들의 중심과 가깝게 유지되도록 강제한다.
Language Field Distillation
Language feature vector $\hat{f^l}$은 각각의 Super-Gaussian에 할당되고, 아래 식과 같이 decoder $F_L$을 통해 CLIP space의 language feature가 된다.
$\hat{l_s} = F_L(\hat{f^l}, \hat{x}_s)$
이렇게 얻은 language feature를 렌더링하여 512차원 feature map $\hat{L}$을 얻는다. 이후 앞 단계에서 생성한 instance mask $\mathcal{M}_{ins}$로 crop한 이미지를 CLIP으로 변환한 feature map과 비교하여 아래와 같이 cosine similarity loss를 얻는다. 이때 language feature와 decoder $F_L$을 제외한 나머지 파라미터는 모두 freeze한다.
$\mathcal{L}_{lang} = 1 - \cos(\hat{L}, L)$
Experiments
Experimental Setup
데이터셋으로는 ScanNet v2, LERF-OVS를 사용하였다. Baseline으로는 LangSplat, Legaussian, OpenGaussian을 선정하였다. Metric으로는 mIoU와 mAcc를 사용하였다.
학습 순서는 다음과 같다. 먼저 Scaffold-GS를 30000 iteration 학습한다. 이후 geometry와 hierarchy feature를 freeze하고 Super-Gaussian clustering network를 30000 iteration 학습한다. 마지막으로 language feature를 10000 iteration 학습한다.
Results on the ScanNet Dataset
Quantitative Results
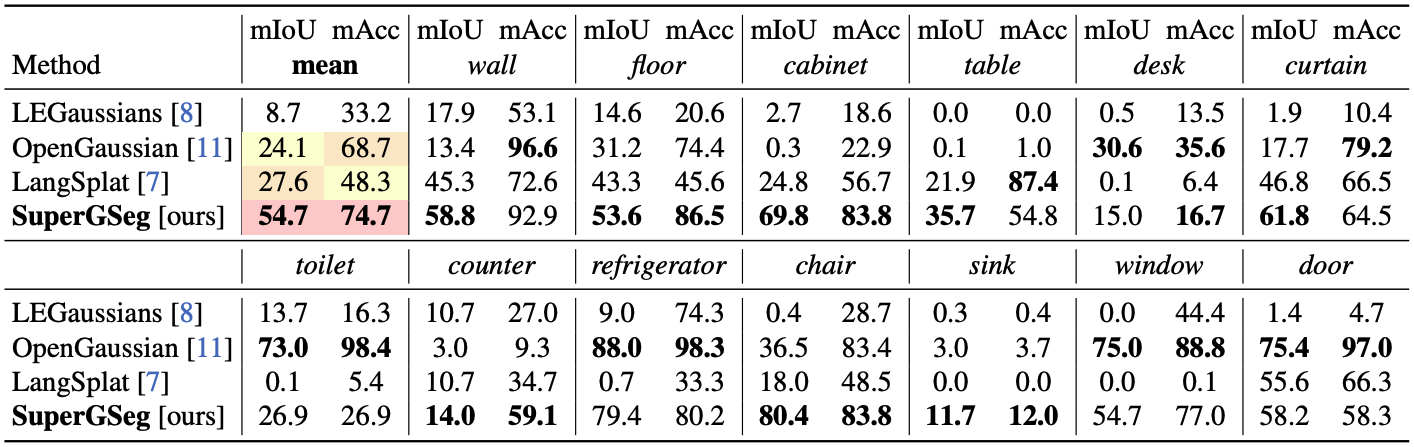
SuperGSeg는 다양한 물체에 대해 기존 방법들보다 높은 평균 mIoU와 mAcc를 달성하였다. 다른 모델들은 특정 물체에 대해 전혀 segmentation을 하지 못하는 경우가 있다.
Qualitative Results

렌더링된 segmentation 결과를 보아도 SuperGSeg가 기존 방법보다 훨씬 더 정확하다는 것을 볼 수 있다.
Results on the LERF-OVS Dataset
Quantitative Results

SuperGSeg이 전반적으로 우수한 성능을 보이며, 특히 figurines, Waldo kitchen과 같이 복잡한 환경에서 가장 높은 mIoU를 기록한 것을 볼 수 있다.
Qualitative Results
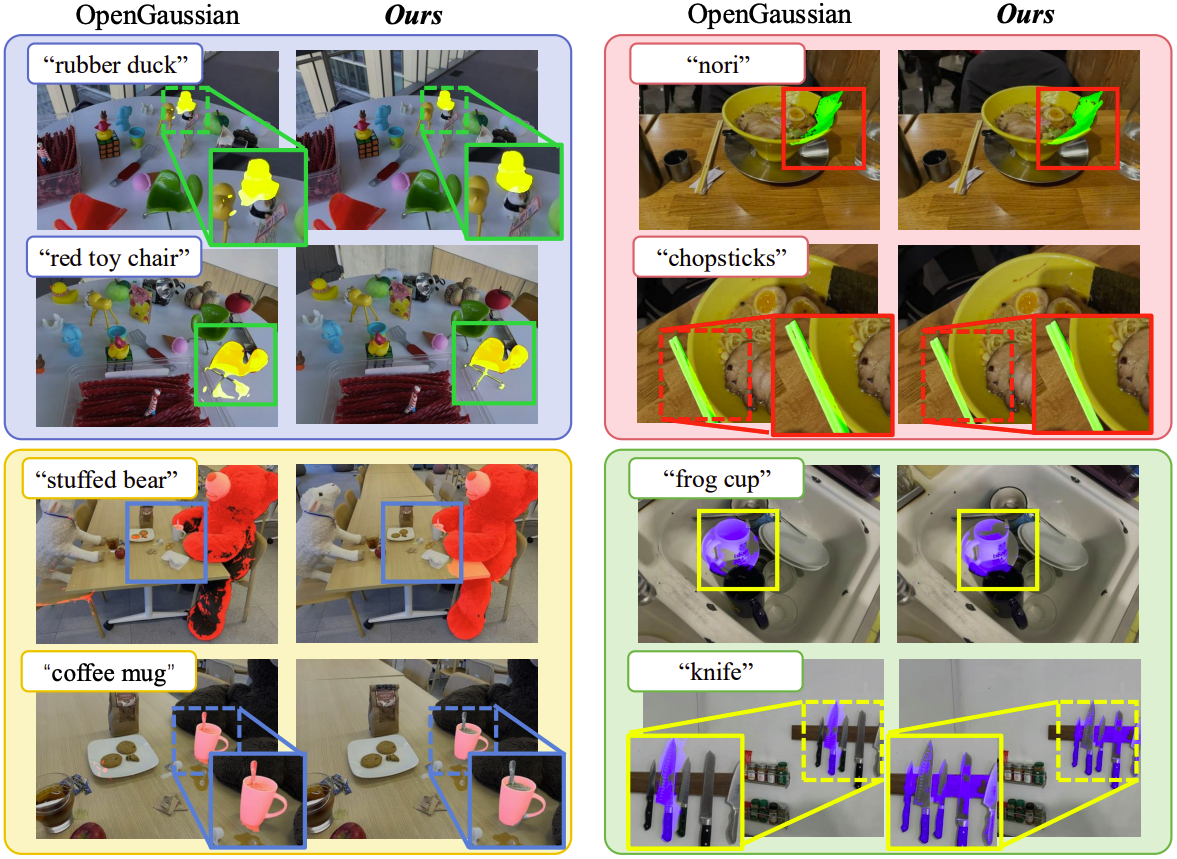
동일한 물체가 여러 개 있는 상황에서, OpenGaussian은 모든 물체를 찾지 못하지만 SuperGSeg는 모든 물체를 찾을 수 있다. 또한 SuperGSeg는 coffee mug 안에 숟가락이 있는 상황에서 coffee mug만을 명확히 구분할 수 있다. 이는 Super-Gaussian을 통한 세밀한 feature distillation이 효과적이라는 것을 보여준다.
Ablation Study

Instance와 hierarchy feature field의 유무가 가장 큰 영향을 주는 것을 볼 수 있다.
Conclusion
SuperGSeg는 neural Gaussian을 활용하여 hierarchical segmentation features를 학습하였고, 이러한 features를 Super-Gaussian으로 distill하여 language-based feature rendering을 가능하게 하였다. 그 결과 SuperGSeg는 open-vocabulary 3D segmentation tasks에서 우수한 성능을 보여준다.