Introduction
VLM 모델들은 다양한 멀티모달 task에서 뛰어난 성능을 보이지만, 단어를 넘어 문장 구조에 따른 의미의 변화를 이해하는 것은 아직 풀리지 않은 문제다. 예를 들어, CLIP 모델은 "An astronaut is riding a horse", "A horse is riding an astronaut"과 같이 같은 단어로 이루어져 있지만 문장 구조가 다른 문장들을 구분하지 못한다. CLIP 모델은 단순한 bag-of-words 접근법과 유사하게 작동한다고 볼 수 있다.
이러한 문장 구조를 포함한 semantic 정보를 본 논문에서는 structured representation이라고 칭한다.
Structure-CLIP은 Scene Graph Knowledge (SGK)를 활용하여 structured representation 능력을 향상시켰다. 첫 번째로, SGK를 활용하여 더욱 효과적인 Negative Sample들을 생성한다. 두 번째로, 본 논문에서 도입한 Knowledge-Enhanced Encoder (KEE)는 SGK를 입력으로 받아 structured representation을 향상시킨다.
Related Work
Vision-Language Pretraining
VLM은 다양한 이미지와 텍스트 사이 공통된 representation을 학습하는 것을 목표로 한다. Downstream task에 따라 아래와 같이 다양한 모델 아키텍쳐가 존재한다.
- Dual-encoder: CLIP, ALIGN
- Fusion-encoder: LXMERT, UNITER
- Encoder-decoder: ALBEF, SimVLM
- Unified Transformer: OFA, BEiT3
Downstream task의 종류로는 아래의 4가지가 있다.
- Cross-Modal Masked Language Modeling: 문장에서 특정 단어를 마스킹하고 복원하는 방식.
- Cross-Modal Masked Region Prediction: 이미지의 특정 부분을 마스킹하고 복원.
- Image-Text Matching: 주어진 이미지와 텍스트가 서로 매칭되는지 여부를 예측.
- Cross-Modal Contrastive Learning: positive example과 negative example을 비교하며 학습.
CLIP 등 최근 연구들은 주로 Cross-Modal Contrastive Learning에 집중하고 있다.
Structured Representation Learning
Structured Representation이란, 동일한 단어로 이루어져 있지만 문장의 구조가 달라 의미가 다른 텍스트를 구분하는 능력을 말한다.
Winoground는 문장에서 동일한 단어를 사용하지만 다른 의미를 갖는 400개의 샘플로 이루어진 데이터셋을 제안했다. 여러 VLM 모델들을 평가한 결과, 기존 모델들은 이러한 텍스트들을 전혀 구분하지 못했다.
NegCLIP은 문장에서 랜덤으로 두 단어를 바꾸어 negative example을 생성하는 방법을 제안했다. 하지만 문장 구조 자체를 고려하여 단어를 바꾸는 것이 아니었기 때문에 negative example의 퀄리티가 좋지 않았다.
Scene Graph Generation
Scene graph는 structured knowledge의 일종으로, object, attribute, 그리고 object간 relation를 구조적으로 표현하는 방식이다. Scene Graph Generation (SGG) 모델은 아래의 세 모듈로 이루어진다.
- Proposal Generation: 객체의 bounding box를 탐지.
- Object Classification: 탐지된 객체를 classify.
- Relationship Prediction: 객체 간 relation를 예측.
기존 연구들은 RNN이나 GCN, 또는 dynamic tree structure를 활용하였다.
Scene Graph는 image captioning, image retrieval, visual question answering, multi-modal sentiment classification, image generation, vision-language pretraining 등 task에 큰 도움을 주었다.
Methodology
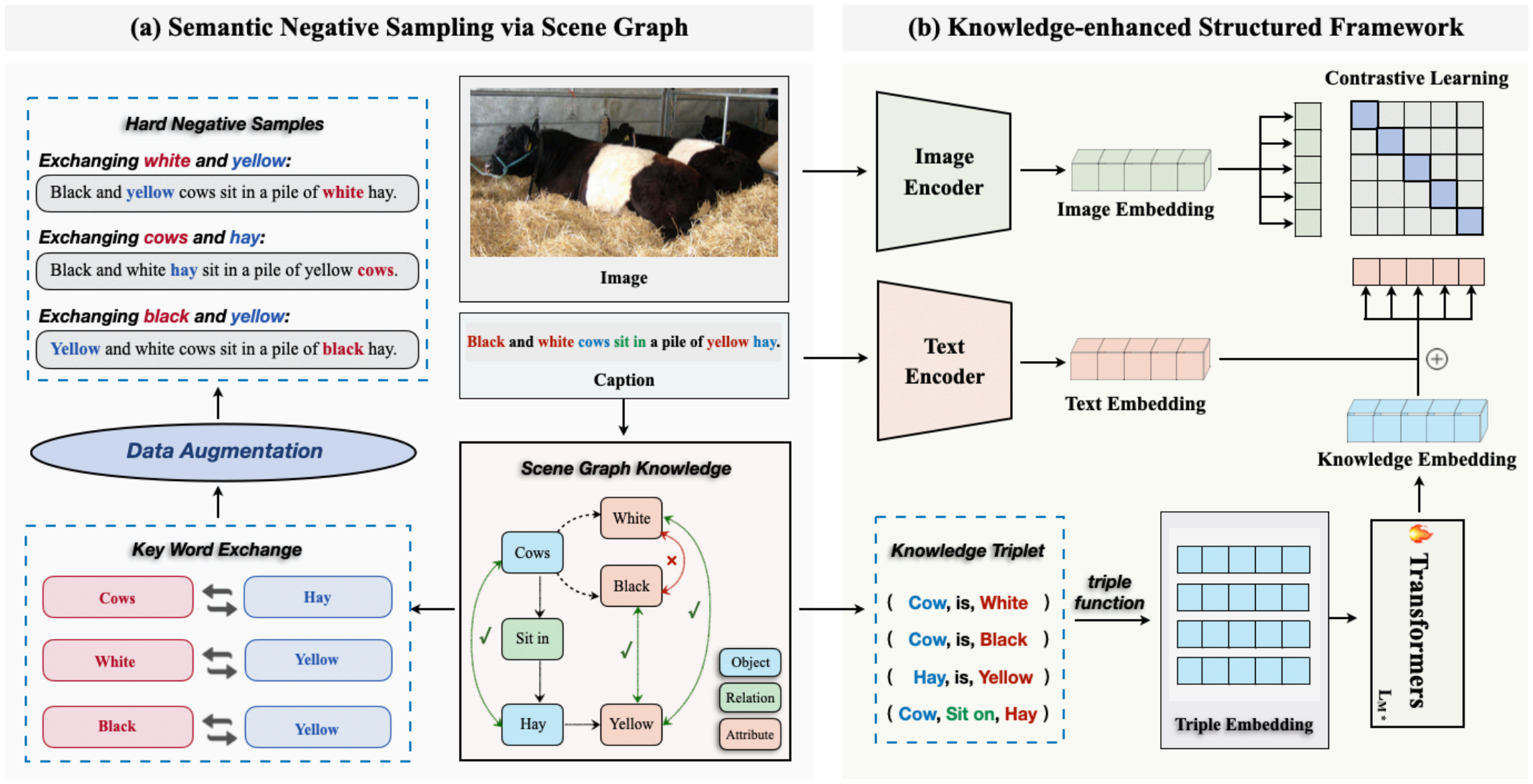
Semantic Negative Sampling via Scene Graph
이 파트에서는 scene graph 정보를 이용하여 structured representation 학습에 사용할 negative example들을 생성하는 방법을 다룬다.
Scene Graph Generation
Structure-CLIP은 Scene Graph Parser를 이용하여 주어진 문장 $W$를 scene graph $G(W)$로 변환한다. $G(W) = \lt O(W), E(W), K(W) \gt$로, $O(W)$는 문장 $W$에 언급된 물체들, $E(W)$는 물체간 relation을, $K(W)$는 물체의 속성을 나타낸다.
예를 들어, "Black and white cows sit in a pile of yellow hay."라는 문장에서 물체는 "cows", "hay", 속성은 "black", "white", "yellow", relation은 "sit in"이 된다. 이러한 캡션은 이미지와 함께 데이터셋에서 제공된다.
Choice of Semantic Negative Samples
Contrastive learning에서는 positive sample끼리는 가까워지도록, negative sample끼리는 멀어지도록 학습한다. 따라서 본 논문에서는 scene graph를 활용, 단어 구성은 같지만 의미적으로 다른 문장들을 생성하여 structured representation learning을 진행한다.
이미지 $I_i$와 캡션 $W_i$, 그 캡션으로부터 생성한 scene graph $G(W_i)$가 있을 때, $W_i^-$는 아래와 같이 정의된다.
$W_i^{-} = Swap((O_1, R, O_2)) = (O_2, R, O_1)$
즉, 어떤 관계가 있는 두 물체의 순서를 바꾸는 것이다. 예를 들어, "An astronaut is riding a horse"을 "A horse is riding an astronaut"으로 바꾸는 것에 해당한다.
또한 두 물체와 각각의 속성이 있는 경우 아래와 같이 $W_i^-$를 생성한다.
$Swap((A_1, O_1), (A_2, O_2)) = (A_2, O_1), (A_1, O_2)$
예를 들어, "A red dress and a blue book"을 "A blue dress and a red book"으로 바꾸는 것에 해당한다.
Contrastive Learning Objective
Contrastive learning을 위해, 이미지 $I_i$와 원래 캡션 $W_i$는 가까워지도록, $I_i$와 $W_i^-$는 멀어지도록 해야 한다. 이를 위해 아래의 loss를 도입한다.
$\mathcal{L}_{\text{hinge}} = \max(0, \gamma - d + d')$
$\gamma$는 margin, $d$는 $I_i$와 $W_i$ 사이의 거리, $d'$는 $I_i$와 $W_i^-$ 사이의 거리이다.
이 loss term을 기존의 InfoNCE loss와 합하여 최종 loss를 계산한다. InfoNCE loss는 image to text와 text to image 두 방향으로 진행한다.
$\mathcal{L}_{i2t} = -\log \cfrac{\exp\left( (\tilde{v}_i, e_{\text{text}_i}) / \tau \right)} {\sum\limits_{k=1}^{N} \exp\left( (\tilde{v}_i, e_{\text{text}_k}) / \tau \right)}$
$\mathcal{L}_{t2i} = -\log \cfrac{\exp\left( (e_{\text{text}_i}, \tilde{v}_i) / \tau \right)} {\sum\limits_{k=1}^{N} \exp\left( (e_{\text{text}_i}, \tilde{v}_k) / \tau \right)}$
최종 loss는 아래와 같다.
$\mathcal{L}_{\text{final}} = \mathcal{L}_{\text{hinge}} + (\mathcal{L}_{i2t} + \mathcal{L}_{t2i}) / 2$
Knowledge-Enhanced Encoder
이 파트에서는 scene graph를 입력으로 받아 text에 대한 structured representation을 얻는 KEE 모델에 대해 다룬다.
우선, 기존 CLIP 모델을 이용하여 이미지 $I_i$와 원래 캡션 $W_i$를 각각의 embedding vector 로 변환한다.
$\tilde{v} = CLIP_{vis}(I_i), \quad \tilde{z} = CLIP_{text}(W_i)$
하지만 기본 CLIP 모델만으로는 부족하기 때문에 scene graph 정보를 입력으로 넣기 위해 새로운 데이터 형식인 triplet을 도입한다.
$\mathcal{T}_{in} = \{ (h_i, r_i, t_i) \mid i \in [1, k] \}$
$h_i$는 head entity로 주어, $r_i$는 relation entity로 동사, $t_i$는 tail entity로 목적어나 형용사에 해당한다. 문장이 두 object와 relation으로 이루어진 $(O_1, R, O_2)$ 형태인 경우 그대로 triplet이 된다. 한 object와 한 attribute로 이루어진 $(A, O)$ 형태인 경우 중간에 "is"를 넣어 $(O, \text{is}, A)$ 형태로 triplet을 만든다.
이후 각 triplet $\mathcal{T}_{in}$에 대해, BERT의 tokenizer와 Word Vocabulary Embeddings를 이용하여 각 entity에 대한 embedding을 생성한다.
$w_x = \mathit{WordEmb}(x), \quad x \in [h, r, t]$
각 entity에 대한 embedding을 합쳐 triplet $\mathcal{T}_{in}$에 대한 embedding을 만든다.
$e_{\mathit{triple}_i} = \mathit{ENC}_{\mathit{triple}}(h_i, r_i, t_i) = w_{h_i} + w_{r_i} - w_{t_i}$
이 방식은 Head와 Tail의 순서가 바뀌었을 때 의미를 구별할 수 있도록 한다.
이렇게 얻은 각 이미지에 대한 embedding들을 여러 개의 transformer layer에 넣어 최종 structured knowledge를 얻을 수 있다.
$e_{KE} = \mathit{TRMs}([e_{\mathit{triple}_1}, \cdots, e_{\mathit{triple}_K}])$
마지막으로 기존 CLIP embedding과 structured knowledge embedding을 합쳐 최종 embedding을 얻는다.
$e_{text} = \tilde{z} + \lambda e_{KE}$
이 $e_{text}$가 위 섹션의 $\mathcal{L}_{i2t}$와 $\mathcal{L}_{t2i}$에 들어가게 된다.
Experiments
Datasets
Pretraining datasets으로는 MSCOCO를 이용하였다. Pretraining 평가 지표로는 Image-to-Text Retrieval (IR), Text-to-Image Retrieval (TR)에 대한 Recall@1을 사용하여 전반적인 representation 성능을 측정하였다.
Downstream task에 대한 데이터셋으로는 NegCLIP에서 제안한 Visual Genome Relation (VG-Relation)과 Visual Genome Attribution (VG-Attribution)을 사용하였다. 각 데이터셋은 이미지-캡션 pair로 구성되어 있는데, 캡션이 정확할 수도 있지만 앞에서 소개한 예시처럼 relation 또는 attribute가 swap된 캡션이 포함되어 있다.
Overall Results
Structured Representation Tasks
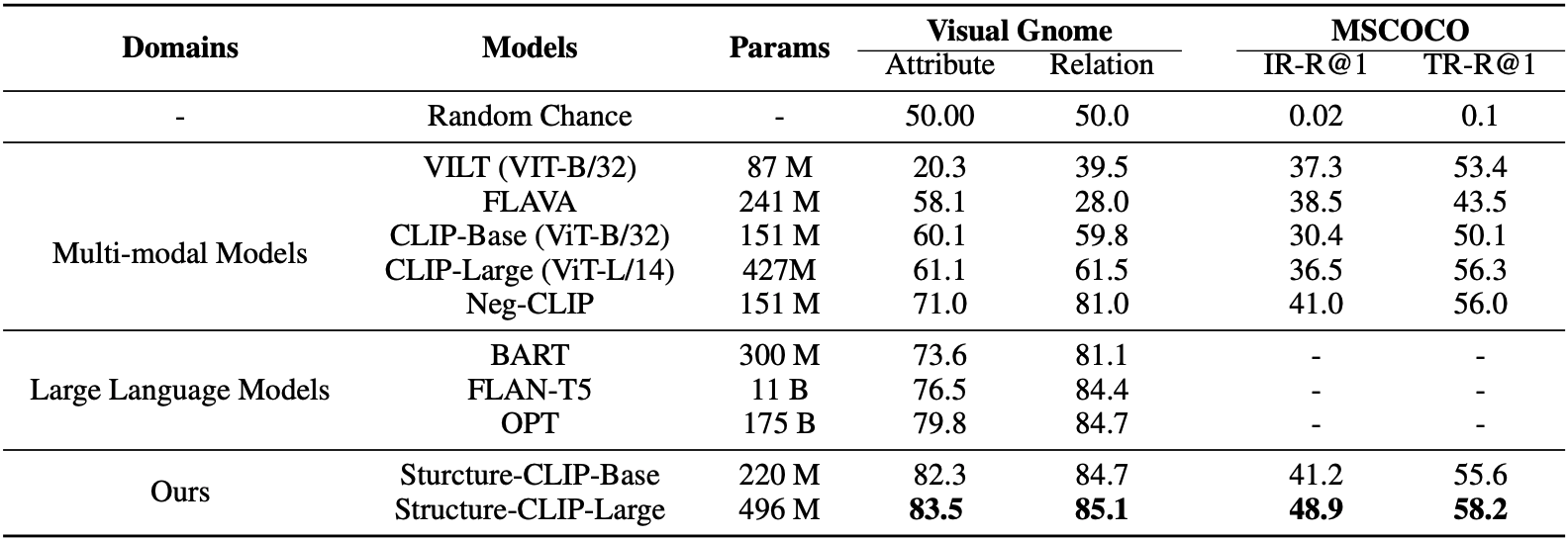
Structure-CLIP은 VG-Relation 및 VG-Attribution 데이터셋에서 기존 최신 모델 대비 SOTA 성능을 달성했다. CLIP과 비교하여 NegCLIP의 성능이 더 좋은 것을 통해 negative example을 통한 학습이 효과적이라고 볼 수 있다. 또한 Structure-CLIP이 NegCLIP보다도 성능이 좋은 것을 통해 scene graph를 활용하는 것이 큰 영향을 미쳤다고 볼 수 있다.
LLM과 비교하였을 때, 파라미터 수에서 큰 차이가 있음에도 Structure-CLIP이 더 우수한 성능을 보였다.
General Representation Tasks
위 표의 MSCOCO 항목을 보면, Structure-CLIP-Base 모델은 NegCLIP과 동등한 성능이고, Large 모델은 더 향상됭 성능을 보인다. 즉, structured representation을 포함하면서도 general representation 성능까지도 유지한다.
Ablation Studies
Component Analysis
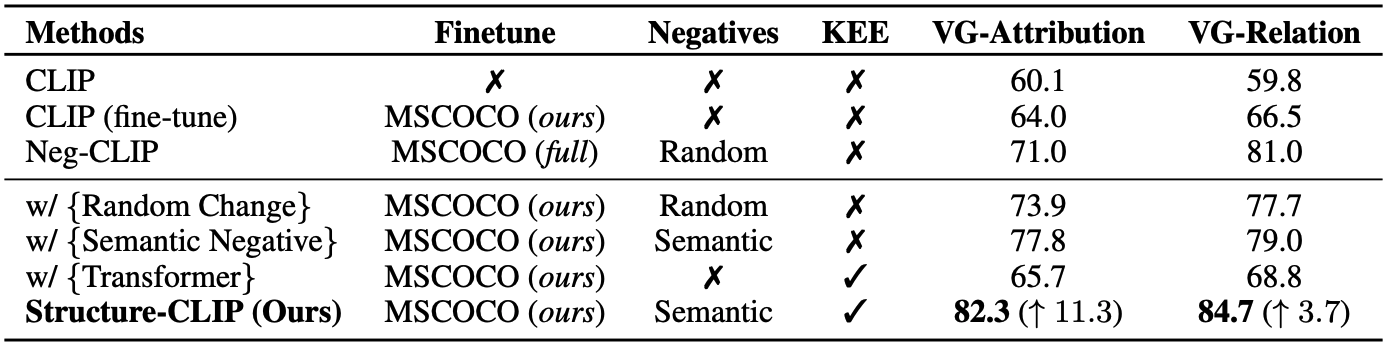
4, 5번 줄을 통해 random하게 negative example을 만드는 것보다 scene graph를 이용하는 전략이 더 효과적이라는 것을 알 수 있다. 또한 5, 7번 줄을 통해 KEE가 더해지면 성능이 더 크게 향상됨을 알 수 있다. 반면 2, 6번 줄을 보면, random negative와 KEE를 사용했을 때 성능 향상이 미미한 것을 볼 수 있다. 즉 두 요소가 함께 사용되어야 함을 의미한다.
Hyperparameter Analysis
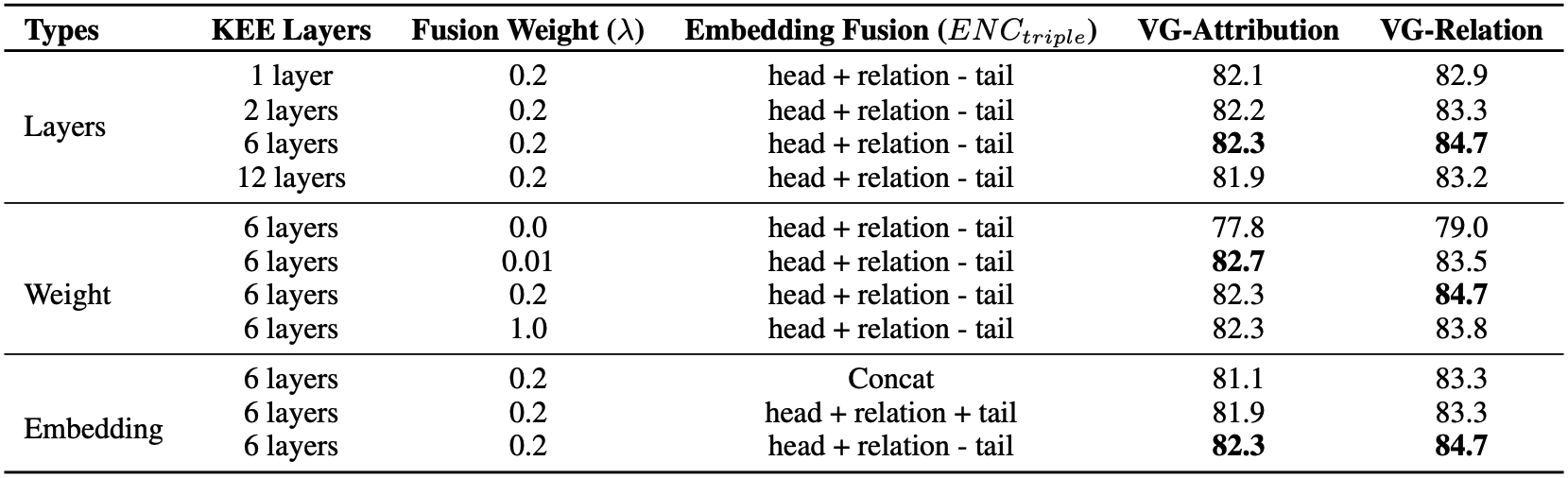
KEE의 layer에 따른 성능의 변화를 볼 때, layer의 수가 6개일 때 성능이 가장 좋은 것을 볼 수 있다. Layer가 너무 많으면 overfitting이 발생하는 것으로 추정한다.
또한 $e_{text}$를 구하는 과정에서 scene graph knowledge에 대한 가중치 $\lambda=0$으로 설정했을 때 모델 성능이 크게 저하됨을 확인할 수 있다.
Triple embeddings
각 triplet에 대한 embedding을 생성하는 함수 $\mathit{ENC}_{\mathit{triple}}(h_i, r_i, t_i) = w_{h_i} + w_{r_i} - w_{t_i}$에 대해서도 ablation study를 진행하였다.
$w_{h_i}$, $w_{r_i}$, $w_{t_i}$를 단순히 concat했을 때는 각 entity의 순서는 고려하지만 각 entity간의 관계는 잘 구분하지 못한다. 셋을 모두 더했을 때는 각 entity간의 관계는 구분하지만, head와 tail의 순서가 바뀌어도 구별하지 못한다.
즉 $w_{h_i} + w_{r_i} - w_{t_i}$의 형태가 각 entity의 순서와 관계를 모두 반영할 수 있는 방식이다.
Case Study
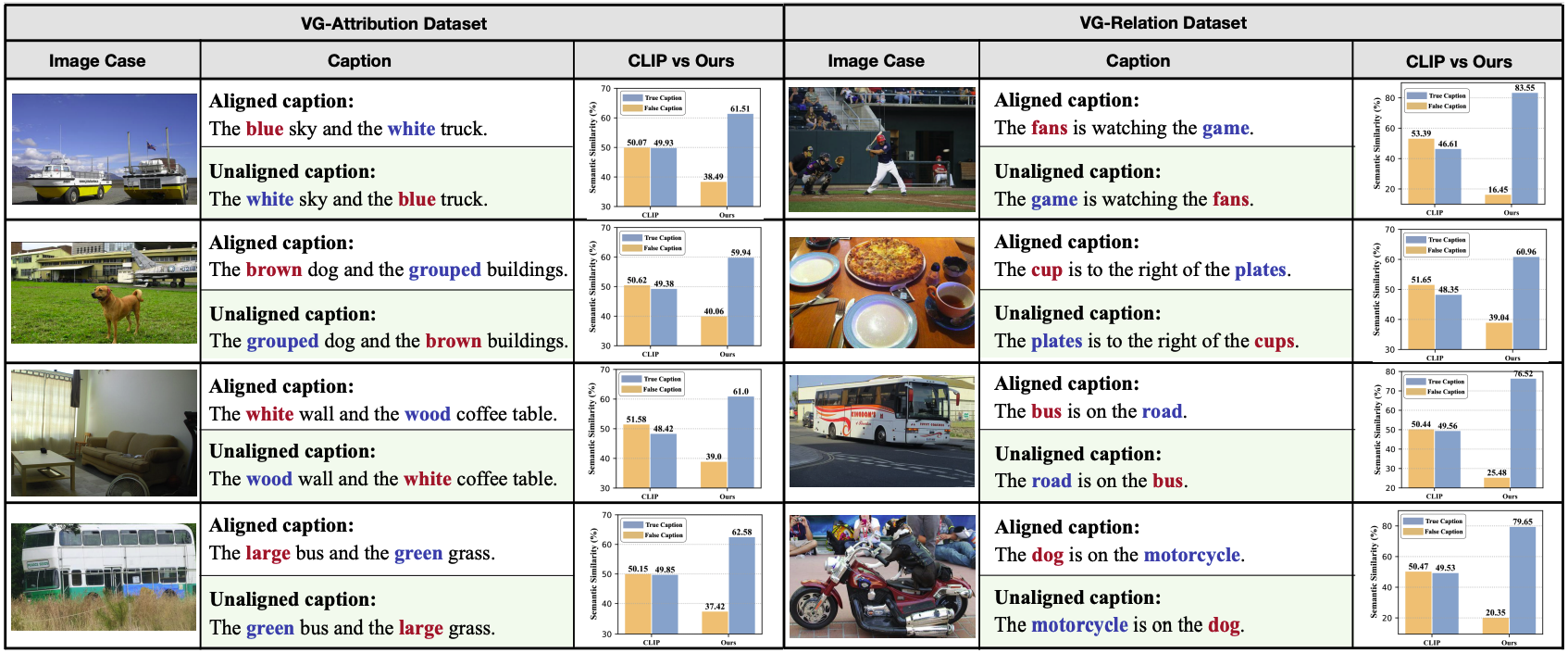
CLIP 모델은 negative example에 대해 의미적 차이를 제대로 구별하지 못하지만 Structure-CLIP은 큰 차이로 정확한 캡션을 구별해내는 것을 볼 수 있다.
Conclusion
Structure-CLIP은 scene graph를 기반으로 negative example을 생성하여 모델이 structured representation을 더 효과적으로 학습할 수 있도록 유도하였다. 또한 scene graph 정보를 KEE 모델로 직접 입력받아 text embedding에 통합, 문장의 세부 의미를 보다 정확하게 반영하도록 개선하였다.
결론적으로 Structure-CLIP은 멀티모달 시나리오에서 더욱 세밀한 의미를 이해하고, 강건한 표현 학습이 가능함을 입증하였다.