Introduction
Open-vocabulary 3D scene understanding은 컴퓨터 비전 분야에서 매우 중요한 task이다. 최근 3DGS를 이용한 방법들이 주목받고 있는데, 대부분의 경우 각 가우시안에 semantic feature를 할당하고 color와 함께 joint training하는 방식을 사용한다. 이때 semantic 정보는 보통 CLIP과 같은 2D foundation model로부터 distill된다.
Semantic Gaussians 또한 기존과 같이 각 가우시안에 semantic feature를 할당하고 2D 모델로부터 distill하여 feature를 학습하는 방식이다. 기존과 다른 점은 새로운 semantic projection framework를 통해 추가 학습 없이도 각 가우시안에 semantic feature를 할당할 수 있다는 것이다.
여기에 더해, 각 raw 가우시안을 입력으로 받아 semantic 정보를 예측하는 3D semantic network를 도입하여 inference 속도를 더 빠르게 할 뿐만 아니라 3D geometry 정보를 이용하여 semantic의 품질을 향상시킨다.
Related Work
Open-Vocabulary Scene Understanding은 2D와 3D 두 가지 측면에서 연구가 진행되고 있다. 2D에서는 text-image pair가 풍부하기 때문에 CLIP과 같은 large VLM을 만들 수 있고 이를 이용해 zero-shot understanding이 가능하다. 하지만 이를 3D scene에 직접 이용하게 되면 frame간 inconsistency가 발생한다는 문제가 있다.
3D에서는 2D pretrained model로부터 knowledge distillation을 하여 feature vector를 학습시키고 이를 3D 공간상에 explicit 또는 implicit하게 저장하는 방법이 사용된다. Point cloud, NeRF, 3DGS 등 여러 representation이 사용되는데, point cloud는 high-quality rendering이 어렵다는 단점이 있다. NeRF의 경우 정확한 렌더링이 가능하지만 implicit하기 때문에 inference에 시간이 걸리고 수정이 어렵다는 단점이 있다. 3DGS의 경우도 마찬가지로 semantic feature를 distillation을 통해 학습하는 방식이고, Semantic Gaussians도 이러한 방식을 사용한다.
Approach
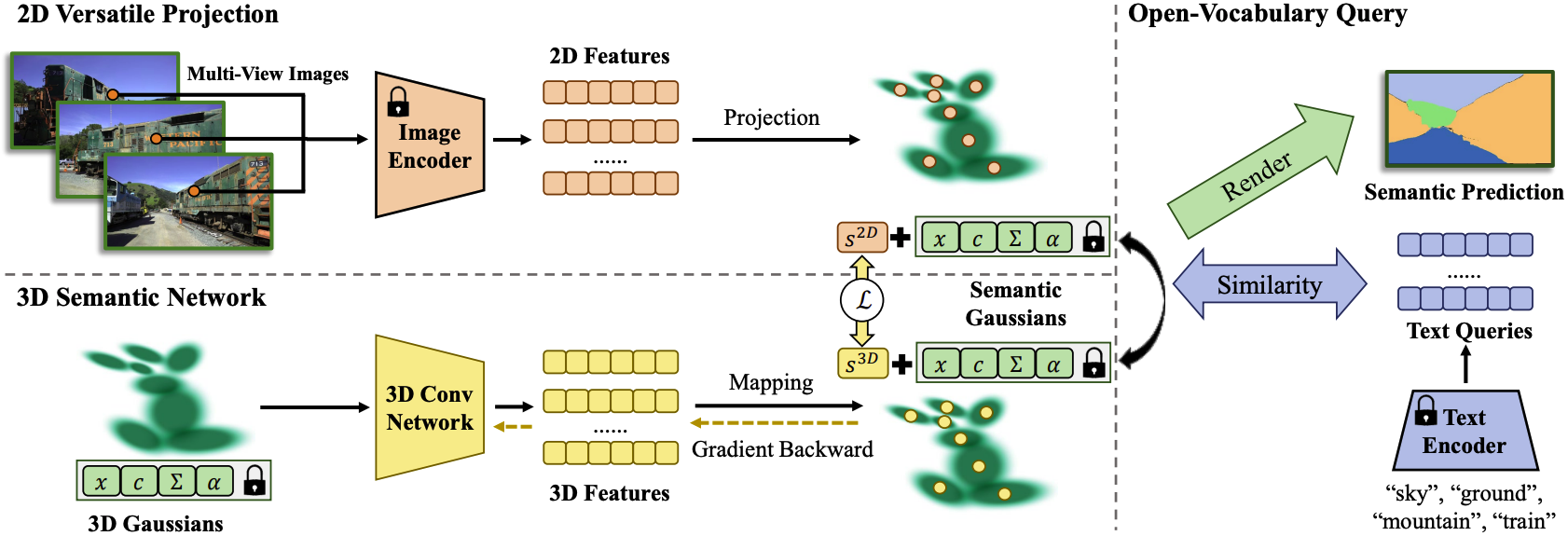
2D Versatile Projection
이 단계는 2D 이미지에서 얻은 semantic feature를 각 가우시안에 할당하는 단계로, 그 자체로도 inference에 쓰이고 뒤에 설명할 3D semantic network를 학습하는 supervision target으로도 사용된다.
우리의 목표는 픽셀별 semantic feature $s \in \mathbb{R}^{H \times W \times C}$를 얻는 것이다. 이를 위해 2D VLM을 이용하게 되는데, Semantic Gaussians는 여러 종류의 VLM 중 원하는 것들을 사용하여 feature를 생성한다.
구체적으로 살펴보면, pixel-level segmentation model인 OpenSeg와 LSeg, instance-level model인 GroundingDINO와 VLPart, image-level model인 CLIP 등을 동시에 사용한다. 또한 SAM까지 사용하여 feature 추출을 보조한다.
- Pixel-level segmentation model을 먼저 살펴보면, 전체 이미지를 모델에 입력시켜 feature map을 얻는다. 그 후 SAM을 이용하여 mask를 얻고, 동일한 mask 안에 속하는 픽셀들의 feature를 모두 평균한 뒤 그 평균값을 각 픽셀의 feature로 대체한다.
- Instance-level model은 2D 이미지에서 dense segmentation을 수행하는 모델이다. 먼저 2D segmentation map을 얻은 뒤, 이를 bounding box로 변환하고 SAM의 prompt로 입력하여 mask를 얻는다. 그 후 이 mask를 이용하여 crop된 이미지를 CLIP에 넣어 embedding을 구하고, 이 embedding을 그 mask에 속하는 모든 픽셀에 할당한다.
- Image-level model의 경우, 먼저 SAM에 'everything' prompt를 넣어 나온 mask들을 이용해 이미지를 crop하고, 이 crop된 이미지들을 CLIP과 같은 image-level model에 넣어 embedding을 구한다. 각 mask에 속하는 모든 픽셀에 그 embedding을 할당한다.
위에 언급한 VLM들 중 downstream task에 맞게 하나 또는 여러 개를 사용하여 embedding을 얻는데, 여러 모델을 사용했을 때 각 embedding들을 어떻게 합치는지는 논문에 나와 있지 않다.
각 픽셀별로 하나의 합쳐진 feature vector을 얻고 나면, 이들을 3D gaussian으로 projection한다. 각 픽셀에서 ray를 따라 opacity를 누적할 때, 특정 threshold를 넘는 순간의 가우시안을 그 픽셀과 매칭한다. 여러 frame에서 이 과정을 진행하면 한 가우시안에 여러 픽셀들이 매칭될 수 있는데, 각 픽셀의 feature vector를 평균내어 최종적인 그 가우시안의 feature vector로 저장한다.
3D Semantic Network
2D segmentation만으로는 3D 공간에 대한 정보를 알 수 없기 때문에 각 가우시안의 파라미터 자체를 입력으로 받아 feature vector를 예측하는 네트워크를 도입한다. Backbone으로는 MinkowskiNet을 사용한다. 2D Versatile Projection에서 얻은 feature를 supervision target으로 사용하기 위해 아래의 loss를 사용한다.
$\mathcal{L} = 1 - \cos(\mathbf{s}^{\text{3D}}, \mathbf{s}^{\text{2D}})$
$\mathbf{s}^{\text{3D}}$는 모델이 예측한 feature vector, $\mathbf{s}^{\text{2D}}$는 2D Versatile Projection에서 얻은 feature vector이다. 두 벡터가 유사해지도록 cosine similarity를 사용한다. 3D 정보를 그대로 이용하기 때문에 여러 view에서 본 결과가 더욱 consistent하다.
Inference
Open-vocabulary language query를 받으면, 먼저 query를 CLIP feature로 변환한다. 이후 이 feature와 모든 가우시안 feature vector 사이의 cosine similarity를 계산한다. 이때 $\mathbf{s}^{\text{2D}}$와 $\mathbf{s}^{\text{3D}}$를 각각 계산하고, 더 큰 값을 그 가우시안의 최종 similarity로 정한다. 최종적으로 이 similarity가 높은 가우시안들을 선택한다.
Experiments
Experimental Setup
데이터셋으로는 ScanNet을 이용해 2D segmentation을 평가했고, LERF를 이용해 3D object localization을 평가했다. 추가적으로 MVImgNet, CMU Panoptic, Mip-NeRF 360을 이용해 qualitative evaluation을 수행하였다.
Implementation Details로는 기본 3DGS를 10000 iteration, 3D semantic network를 10000 iteration 학습하였다.
Quantitative Results
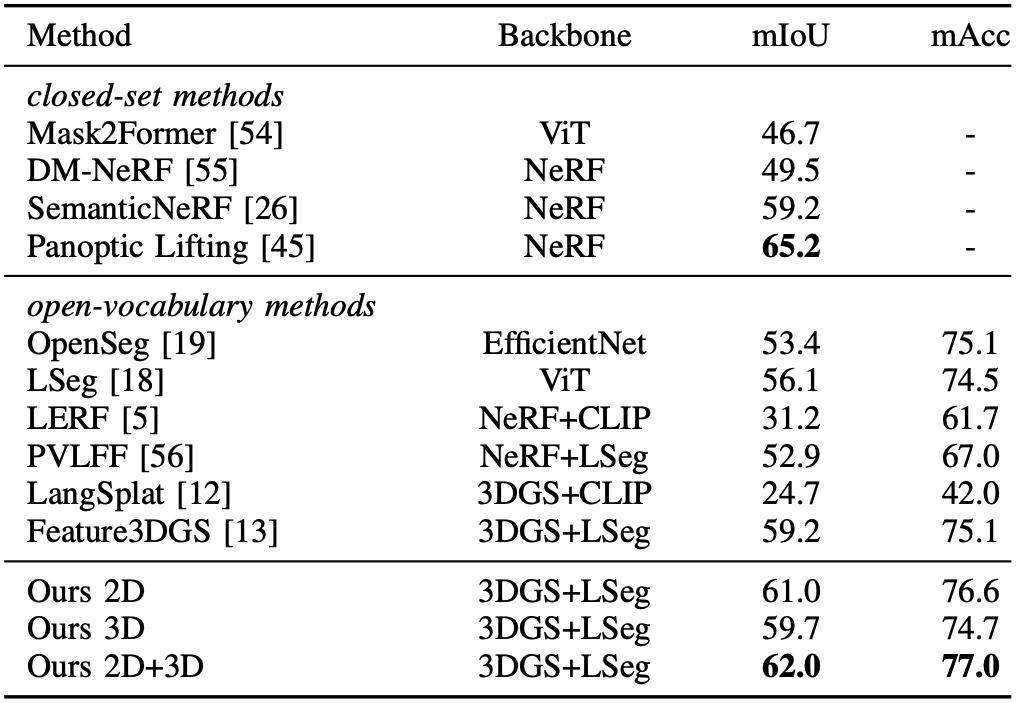
2D semantic segmentation 성능을 비교했을 때, 다른 open-vocabulary 모델에 비해 성능이 뛰어나고 closed-set 모델에 근접한 성능을 보인다. 또한 2D와 3D feature를 함께 사용했을 때 성능이 가장 좋은 것을 보아 두 feature가 서로 보완적인 역할을 하고 있다고 해석할 수 있다.
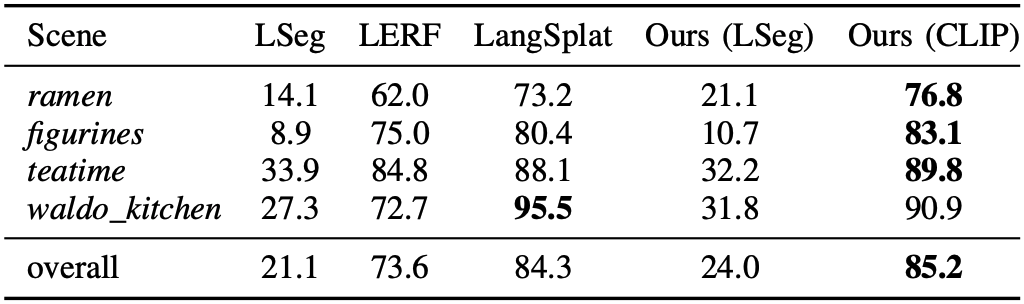
3D object localization 결과는 위와 같다. CLIP을 feature extraction model로 사용했을 때 성능이 다른 모델을 뛰어넘는 것을 볼 수 있다. 하지만 LSeg을 사용했을 때는 성능이 훨씬 떨어지는데, 이것은 LSeg이 long-tail object를 식별하는 능력이 떨어지기 때문인 것으로 생각된다.
Qualitative Results

위 그림은 2D semantic segmentation 결과를 나타낸 것이다. LERF, LangSplat 등이 낮은 정확도를 보이는 것에 반해 Semantic Gaussians는 훨씬 정확한 결과를 보여준다.
Ablation Study
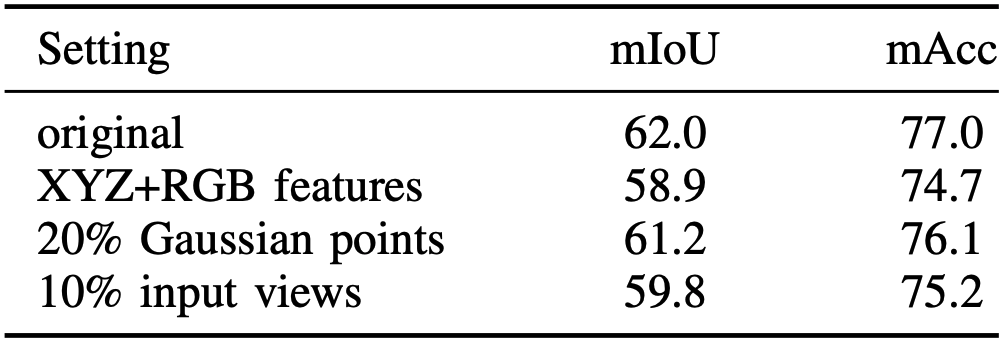
XYZ+RGB features는 3D semantic network의 입력으로 가우시안의 중심점과 색깔만을 입력한 경우이다. 3D semantic network의 입력을 줄였을 때 성능이 가장 많이 떨어지는 것을 볼 수 있다. 가우시안의 개수를 20%만 사용한 경우, input view를 10%만 사용한 경우에도 성능 하락을 확인할 수 있다.
Downstream Tasks
Downstream task로 part segmentation, spatiotemporal tracking, scene-level instance segmentation, language-guided editing이 있다. Semantic Gaussians는 상황에 따라 다른 2D feature extractor를 사용할 수 있기 때문에 각각의 task에서 모두 좋은 성능을 보인다.
Conclusion
Semantic Gaussians는 2D pixel-level embedding을 3D 가우시안으로 distillation할 수 있는 모델이다. 또한 3D semantic network을 도입, 3D geometry 정보까지 이용하여 성능을 향상시켰다.
한계점으로는, Semantic Gaussians는 2D feature extractor의 성능을 향상시키는 역할밖에 못 한다는 것이다. 2D feature extractor를 여러 모델 중에서 선택할 수 있기 때문에 여러 downstream task에서 모두 좋은 성능을 보이지만, 이 모델 자체의 contribution은 기존 모델에서 향상시킨 몇 퍼센트 정도가 아닌가 하는 생각이 든다. 결국 2D feature extractor의 성능에 의존한다는 것이 이 모델의 한계점이다.