Introduction
3D visual grounding은 주어진 텍스트 설명에 해당하는 물체를 3D scene에서 찾는 task이다. 기존 연구들은 모델을 소수의 데이터셋만을 이용하여 학습시키거나 LLM을 이용하여 3D 데이터셋에 대한 의존을 줄였다. 하지만 소수의 데이터셋만을 이용한 경우 scalability가 제한적이며, LLM을 이용한 모델의 경우 시각적 정보를 무시하고 텍스트에만 의존한다는 한계가 있다.
SeeGround는 2D VLM을 이용하여 텍스트와 이미지를 이용한 zero-shot 3DVG를 구현하였다. 2D VLM에 3D 정보를 넣어 주기 위해 렌더링된 2D 이미지와 3D spatial description 텍스트를 함께 사용한다. 이때 텍스트 쿼리로부터 2D 이미지를 렌더링할 카메라 viewpoint를 예측하는 것이 특징이다. 또한 2D에서 렌더링된 이미지에 있는 물체와 3D spatial description 텍스트에서 설명하고 있는 물체를 associate하기 위해 이미지의 픽셀에 마커를 놓는 새로운 방법을 제안하였다.
Methodology
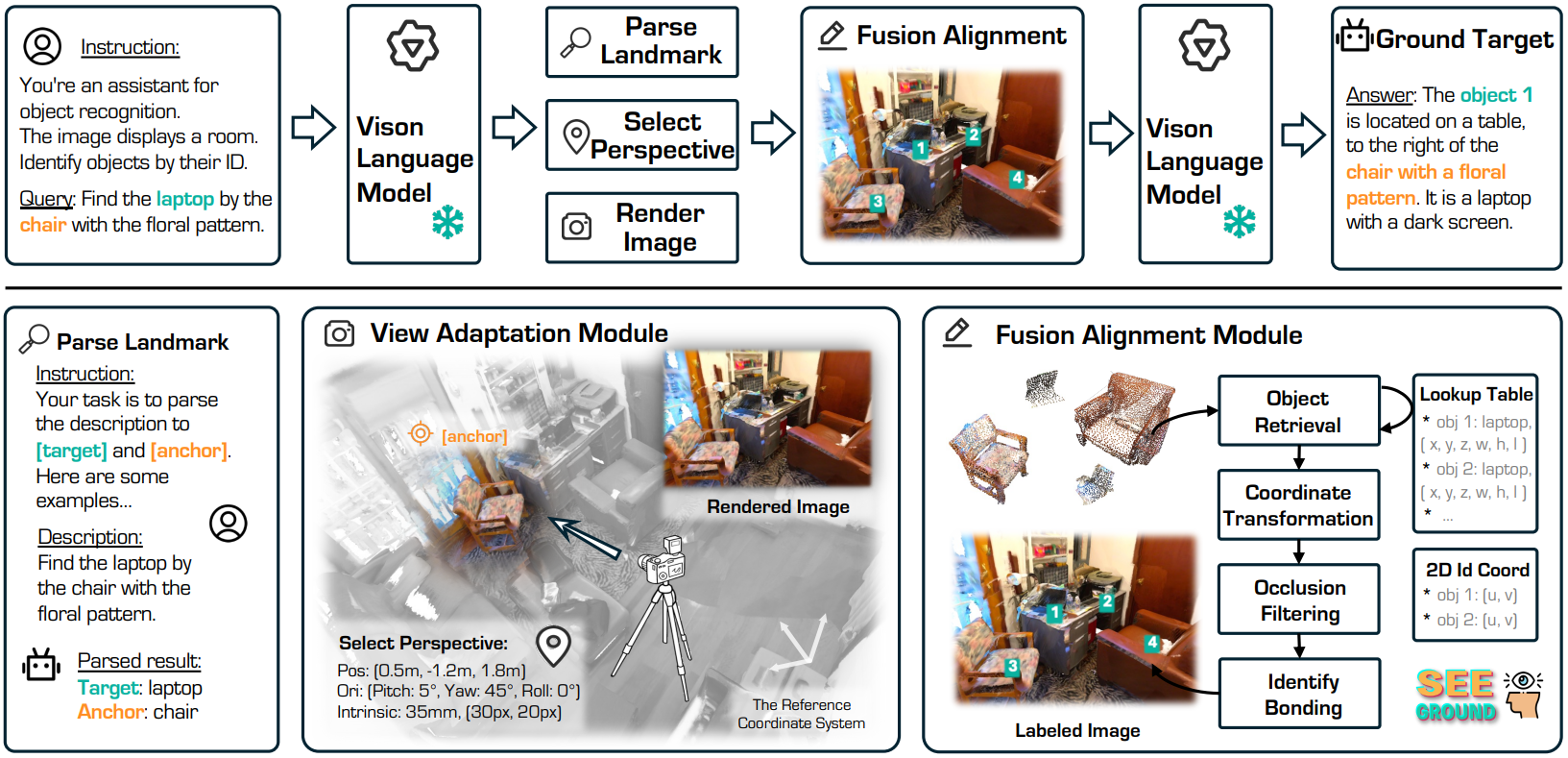
Multimodal 3D Representation
본 논문에서는 렌더링된 2D 이미지와 텍스트 기반의 3D spatial description을 융합하는 hybrid representation을 도입한다.
우선 3D scene 내의 모든 object를 detect하여 각 물체의 bbox와 semantic label을 얻는다. 이 bbox와 label의 쌍을 Object Lookup Table (OLT)이라 한다. OLT를 이용하여 3D spatial description을 생성한다.
텍스트로 물체의 위치와 간단한 위치관계를 설명할 수 있지만 더 복잡한 시각적 정보를 표현하기 위해 2D 이미지와 텍스트 정보를 융합한다. 뒤에 설명할 PAM과 FAM을 거쳐 3D scene은 렌더링된 2D 이미지와 간단한 텍스트로 표현된다.
Perspective Adaptation Module (PAM)
PAM 모듈은 텍스트 쿼리가 어느 view에서 생성되었을지를 추정하여 그 view에서 2D 이미지를 렌더링한다.
우선 2D VLM을 이용하여 텍스트 쿼리에서 anchor object과 target object의 후보를 뽑는다. Viewpoint는 처음에는 scene의 중심에 위치하고 하나의 선택된 anchor object의 중심을 바라보도록 초기화된다. 이후 카메라를 여러 방향으로 움직이며 더 넓은 범위를 담을 수 있도록 한다.
이후 PyTorch3D의 point cloud rendering 함수를 이용해 이미지를 렌더링한다.
Fusion Alignment Module (FAM)

FAM은 앞서 얻은 물체별 3D point cloud와 렌더링된 이미지상의 물체를 associate하는 모듈이다. 우선 물체별 point cloud를 2D 이미지로 projection한다. 이후 각 물체의 중심에 해당하는 픽셀 위치에 위 그림과 같이 마커를 놓는다. 각 물체에 번호를 부여해서 2D VLM이 물체의 번호를 출력할 수 있도록 하기 위해서이다. 위 그림의 마커는 시각화를 위해 더 크게 표시되었다.
기본적으로는 렌더링된 물체의 중심에 마커를 놓는다. 하지만 다른 물체에 의해 물체의 중심이 가려졌을 경우, depth map을 이용해 가려진 점들을 제외한 점들 중 하나에 마커를 놓는다.
최종적으로는 2D VLM에 마커가 포함된 2D 이미지와 텍스트 설명을 입력하여 target object의 category ID를 얻는다.
Experiments
Experimental Settings
데이터셋으로는 ScanRefer와 NR3D를 사용하였다.
VLM으로는 Qwen2-VL-72B를 사용하였다.
Quantitative Results
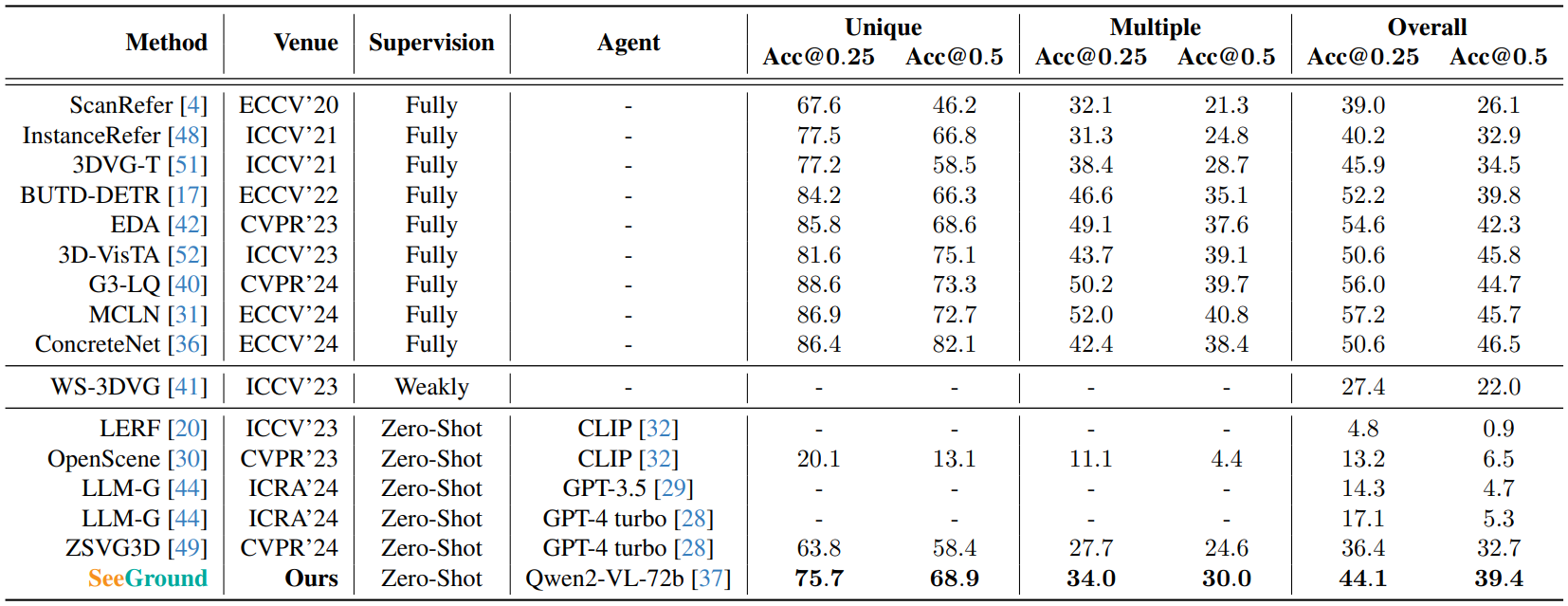
ScanRefer 데이터셋에서의 결과는 위와 같다.
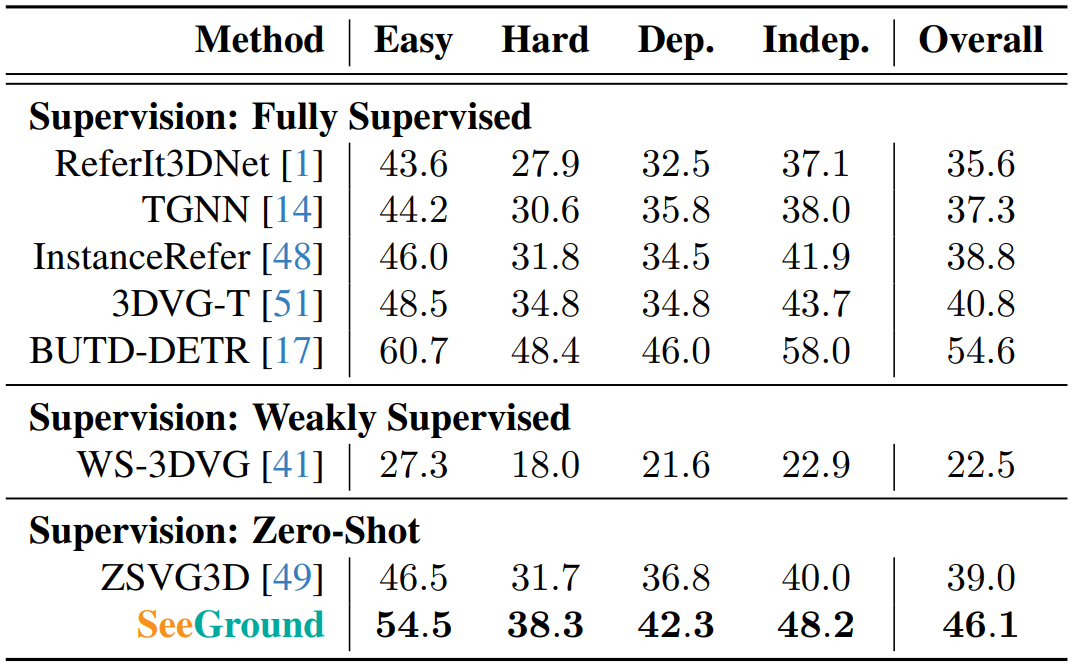
NR3D 데이터셋에서의 결과는 위와 같다.
Qualitative Results
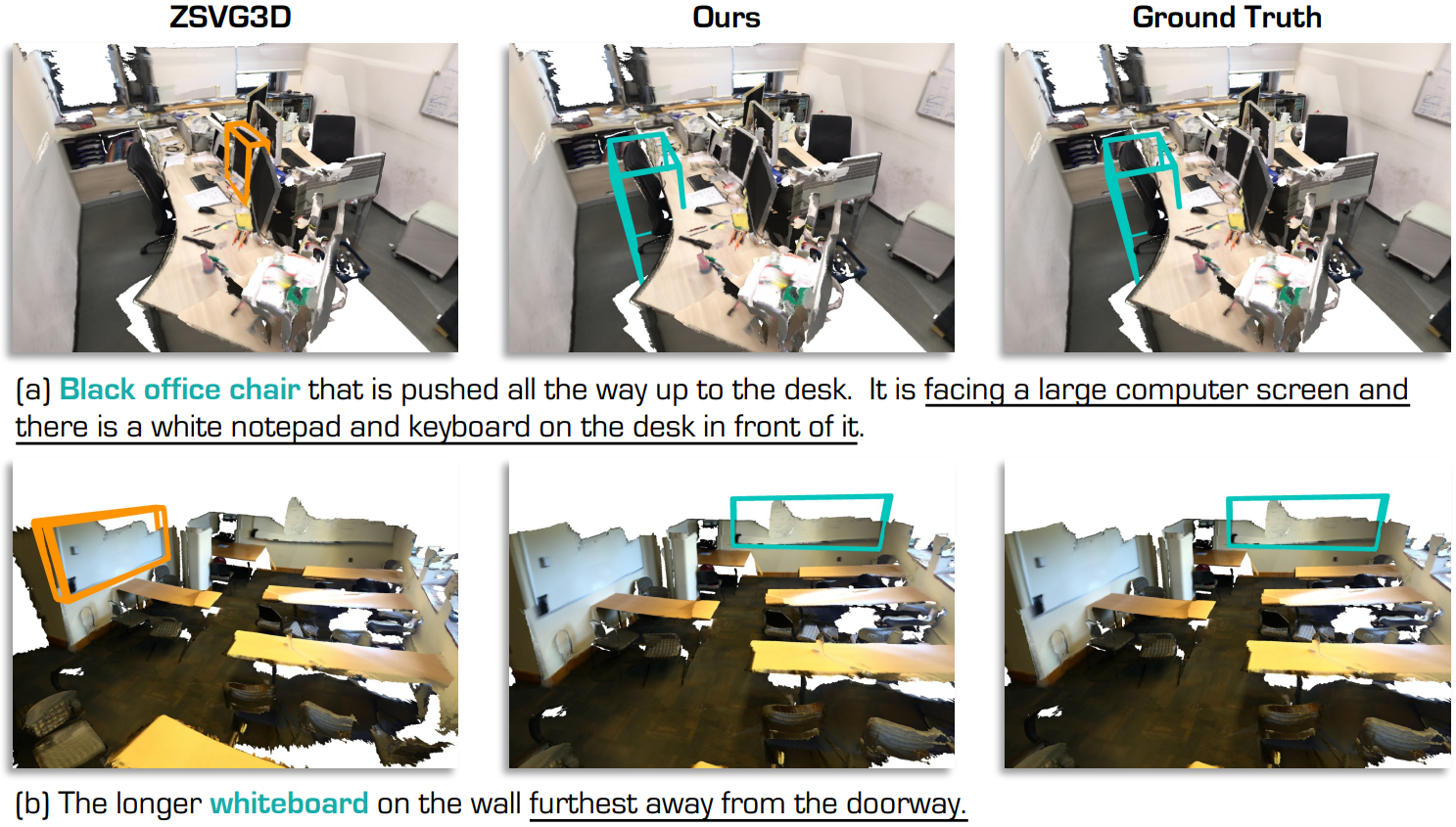
SeeGround 실행 결과를 시각화하면 위와 같다.
Conclusion
SeeGround는 2D VLM을 이용하여 2D와 3D 정보를 융합, zero-shot 3D visual grounding을 수행하는 모델이다. OLT를 이용하여 3D에 대해 직접적인 학습을 하지 않고도 3D scene을 이해할 수 있도록 하였다.