Introduction
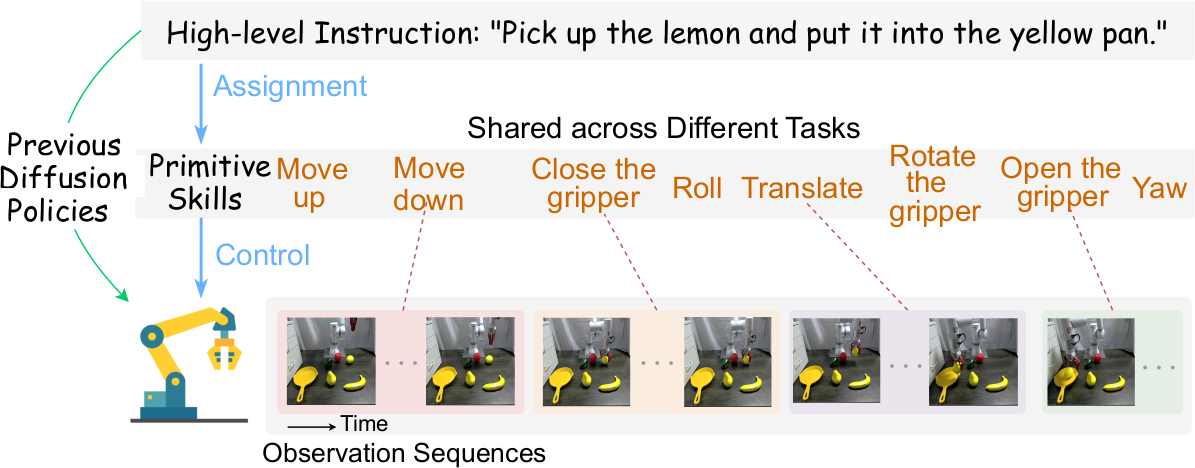
Diffusion policy(DP)는 robotic manipulation에서 action generation을 위한 유망한 접근법이다. 그러나 기존 방법들은 high-level language instruction을 직접 short-term control signal로 매핑하여, instruction의 granularity와 실제 action 사이의 misalignment가 발생한다. 예를 들어 "Pick up the lemon and put it into the pan"이라는 high-level instruction은 gripper를 닫는 등의 세밀한 동작을 직접 지시하기에는 너무 추상적이다.
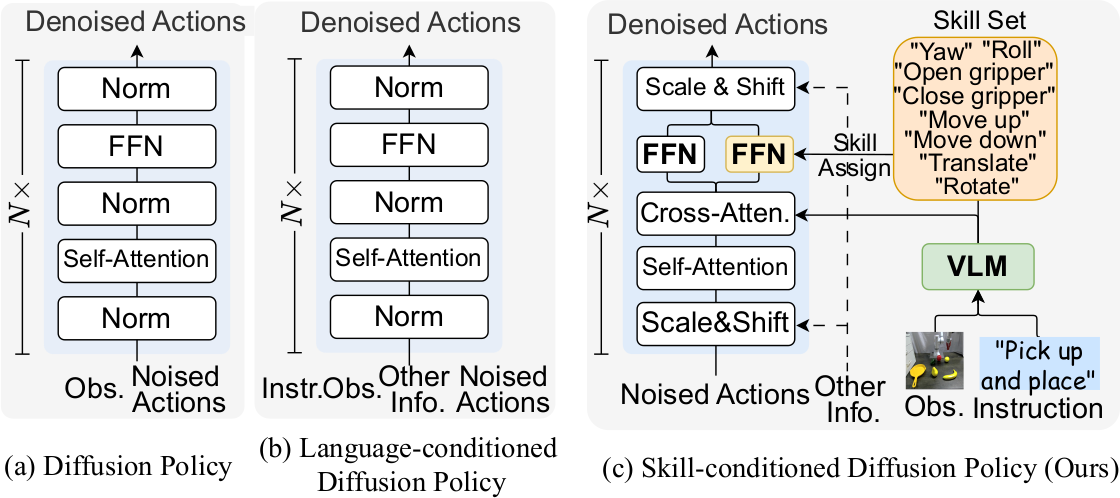
본 논문은 fine-grained, short-horizon manipulation인 primitive skill(예: "move up", "close the gripper")이 로봇 학습에 더 직관적이고 효과적인 interface를 제공한다고 주장한다. 이를 기반으로, skill learning과 conditional action planning을 통합한 skill-conditioned diffusion policy인 SDP를 제안한다. SDP는 다양한 task의 short-term manipulation을 8개의 reusable primitive skill로 추상화하고, VLM(Vision-Language Model)을 활용하여 visual observation과 language instruction에서 discrete representation을 추출한다. Lightweight router network가 각 state에 적절한 skill을 동적으로 할당하고, 할당된 skill이 diffusion policy의 FFN layer를 parameterize하여 skill-aligned action을 생성한다.
Related Work
Diffusion Policy in Robot Manipulation
Diffusion model 기반 robotic manipulation 연구는 robot data representation(2D trajectory, 3D point cloud, sensory input 조합), model architecture(LLM 결합, transformer, variational autoencoder), diffusion strategy(reinforcement learning, self-supervised learning, classifier guidance) 세 방향으로 발전해왔다. 기존 방법들은 대부분 high-level instruction을 직접 short-term action으로 매핑하는 반면, SDP는 executable primitive skill을 학습하고 skill-conditioned diffusion policy를 훈련하여 더 정밀하고 coherent한 로봇 제어를 달성한다.
Planning by VLM
복잡한 instruction을 manageable sub-goal로 분해하면 로봇이 정교한 task를 더 안정적으로 수행할 수 있다. 최근 연구들은 VLM의 real-world knowledge를 활용하여 자동으로 task plan을 생성한다. SDP는 두 가지 점에서 차별화된다: (1) human-understandable primitive skill set을 제안하여 유연한 task 조합이 가능하고, (2) 기존 방법이 skill을 implicitly 학습하는 것과 달리 VLM output에 기반한 lightweight neural network로 각 state에 skill을 explicitly 할당하여 더 transparent하고 controllable한 behavior를 구현한다.
Parameter Synthesis
Hypernetwork은 context information을 입력으로 받아 다른 network의 parameter를 생성하는 neural network이다. HyperDistill은 다른 physical structure의 로봇을 위한 policy를 hypernetwork으로 학습한다. SDP는 이에 영감을 받아, skill과 action prediction 사이의 dependency를 diffusion policy의 FFN layer를 parameterize하여 구축한다.
Preliminaries
Robotic demonstration set $\mathcal{T} = \{\tau_i\}_{i=1}^{|\mathcal{T}|}$가 주어지며, 각 trajectory $\tau_i = \{(s_n, \overline{a}_{n,k}, l_i)\}_{n=1}^N$은 state $s_n \in \mathbb{R}^{d_s}$, action sequence $\overline{a}_{n,k} \in \mathbb{R}^{7 \times k}$, high-level language instruction $l_i$를 포함한다. Language-conditioned diffusion policy는 denoising score matching으로 학습된다:
$\mathcal{L}_{\text{SM}}(\theta; s, \overline{a}, l) = \mathbb{E}_{\sigma, \overline{a}, \epsilon} \left[ \frac{1}{\sigma_t} \| D_\theta(\overline{a} + \epsilon, s, l, \sigma_t) - \overline{a} \|_2^2 \right]$
여기서 $\epsilon$은 noise, $\sigma_t$는 step $t$의 density이다. 학습 후 DDIM을 사용하여 $N_d$ denoising step 내에서 action을 sampling한다. 그러나 이 formulation은 global instruction $l$을 직접 local action으로 매핑하므로, task specification이 정밀한 short-term action을 guide하기에 너무 추상적이다.
Proposed Approach
Approach Overview
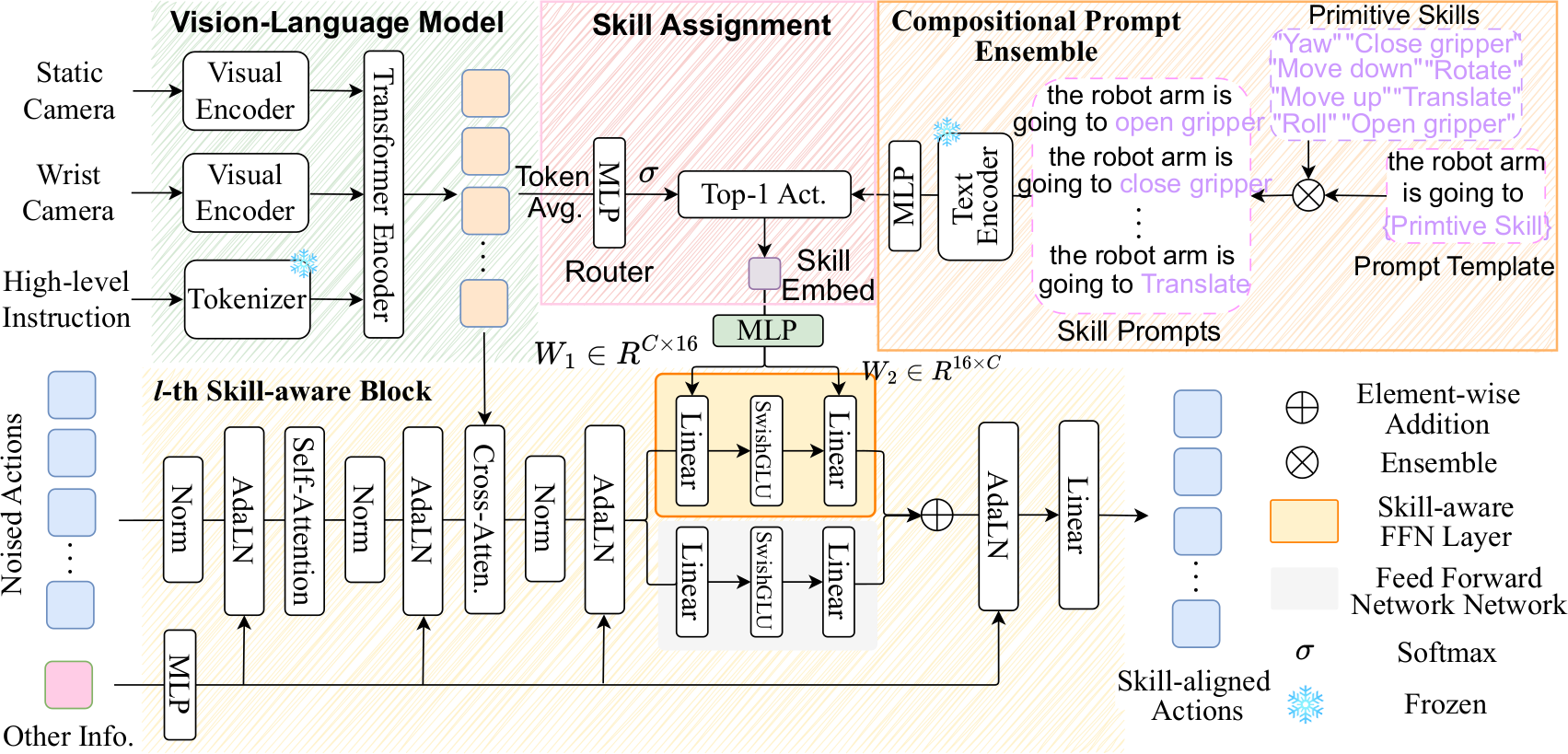
SDP는 high-level instruction의 imprecise execution 문제를 해결하기 위한 skill-conditioned diffusion policy이다. 위 다이어그램의 윗부분에서 primitive skill을 예측하고, 아랫부분에서는 single-skill policy가 state information을 통합하여 action을 생성한다. VLM의 vision-language representation을 사용하여 skill을 할당함으로써, task 실행이 interpretable하고 comprehensible하다.
Primitive Skill Assignment
Compositional Prompt Ensemble (CPE)
다양한 task의 basic manipulation을 8개의 reusable primitive skill $P$로 추상화한다: "roll", "yaw", "open the gripper", "translate", "close the gripper", "move up", "move down", "rotate". 통일된 text template "the robot arm is going to {skill}."을 설계한다.
Frozen CLIP text encoder와 MLP $f$로 prompt embedding $p = f(\text{CLIP}_{\text{text}}(P_{\text{En}})) \in \mathbb{R}^{8 \times C_{\text{img}}}$를 얻는다. 거의 모든 task가 이 primitive skill들의 조합으로 구성되며, 이러한 embedding들을 미리 계산하여 inference 시 효율적으로 사용한다.
Vision-Language Model
CPE가 각 skill에 대한 concrete prompt를 제공하므로, 어떤 skill을 수행할지 결정하기 위해 vision-language representation을 활용한다. Static/wrist 카메라의 visual observation $I_s, I_w \in \mathbb{R}^{3 \times H \times W}$를 shared image encoder $f_{\text{img}}$로 visual embedding으로 인코딩하고, high-level instruction $l$은 tokenizer와 word embedding layer로 text embedding $f_t(l) \in \mathbb{R}^{N_t \times C_{\text{txt}}}$로 변환한다. Vision token과 text token을 concatenate하여 transformer $\Phi$에 입력하면 vision-language representation $z_{vl}$을 얻는다.
Primitive Skill Selection
Skill prompt embedding $p$와 vision-language representation $z_{vl}$을 기반으로, lightweight router network가 각 state에 skill을 선택한다. $z_{vl}$을 token dimension에서 average하여 $z_{\text{avg}} \in \mathbb{R}^{C_{\text{img}}}$를 얻고, MLP layer가 이를 각 skill의 importance를 나타내는 logit으로 변환한 뒤, softmax와 top-1 operation으로 가장 적합한 skill을 선택한다:
$R(z_{vl}) = \text{top-1}(\sigma(\text{MLP}(\text{Avg}(z_{vl}))))$
최종 skill embedding은 $z = \sum\limits_{i=1}^{8} R(z_{vl})_i \cdot p_i$로 선택된다. 기존의 VQ 등이 discrete latent code를 implicitly 학습하는 것과 달리, SDP는 shared primitive skill을 explicitly 추상화하고 skill assignment가 human-understandable하다.
Skill-conditioned Diffusion Policy Learning
Priors Injection
각 state에서 time step, proprioception, visual observation, high-level instruction이 제공된다. 소형 MLP 기반 encoder로 time step과 proprioception을 처리하고, modified AdaLN으로 distinct modulation signal을 모든 layer에 주입한다. Visual/linguistic information은 RMSNorm 후 linear projection을 거쳐 Cross-Attention으로 각 block에서 conditional injection된다.
Skill-dependent FFN Layer
Primitive skill과 action generation 사이의 dependency를 구축하기 위해, LoRA-like FFN layer를 original $\text{FFN}_{\text{ori}}$에 추가한다. 새로운 FFN은 SwishGLU activation과 두 행렬 $W_z^1 \in \mathbb{R}^{C \times 16}$, $W_z^2 \in \mathbb{R}^{16 \times C}$를 포함하며, 이들은 skill embedding $z$로부터 MLP가 생성한다:
$\text{FFN}(x) = W_z^2(\text{SwishGLU}(W_z^1 x)) + \text{FFN}_{\text{ori}}(x)$
이 LoRA-like FFN은 skill 정보를 feature extraction에 명시적으로 반영하면서 전체 parameter 수를 줄인다. 이 구조는 mixture of experts의 변형으로 볼 수 있으며, 첫 번째 항이 skill-dependent expert, 두 번째 항이 shared expert 역할을 한다.
Training Objective
Skill prompt 간의 pairwise cosine similarity를 줄이기 위한 orthogonal loss $\mathcal{L}_{\text{Orth}}(\theta)$를 추가한다:
$\mathcal{L}(\theta) = \mathcal{L}_{\text{SM}}(\theta) + \gamma \mathcal{L}_{\text{Orth}}(\theta)$
여기서 $\mathcal{L}_{\text{Orth}} = \cfrac{1}{64} \sum_{i=1}^{8} \sum_{j=1}^{8} \text{Cos}(p_i, p_j)$이고 $\gamma = 0.01$이다.
Experiments
Experiment Setup and Implementation Details
Simulated Benchmarks
CALVIN과 LIBERO 벤치마크에서 평가한다. CALVIN은 4개 scene configuration(split A-D), 34개 task, 24,000개 language-annotated demonstration으로 구성된다. ABC→D(환경 A, B, C에서 학습, D에서 zero-shot 평가)와 ABCD→D 설정을 채택하며, 1,000개 unique instruction chain(각 5개 연속 task)으로 평가한다. LIBERO는 multiple task suite(LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, LIBERO-Long)로 구성되어 있고, 각 suite에 10개 task, task당 50개 demonstration이 제공된다.
Real-world Evaluation
6-DoF Lebai robot arm으로 9개 task를 설계한다. Task당 30개 trajectory를 수집하고, 20회 trial의 평균 성공률을 보고한다.
- Multi-task learning: spatial awareness(레몬 집어 팬에 넣기 등), tool usage(빗자루, 숟가락 사용), semantic understanding(물 따르기, 큐브 쌓기) 3개 범주 6개 task.
- Visual generalization: unseen object(사과, 바나나)에 대한 일반화와 complex distractor 존재 시 robustness 평가 3개 task.
Implementation Details
12-block Diffusion Transformer 기반으로 OpenX에서 pretrain한다. Simulated task는 A100 GPU 4대에서 40 epoch, batch size 64, learning rate $10^{-4}$, AdamW optimizer로 fine-tune한다. 이미지는 $224 \times 224$로 resize하고 $N_d = 4$ denoising step을 사용한다. Real-world 평가는 static 카메라만 사용하여 200 epoch 학습한다.
Performance on Simulated Robotic Manipulation
CALVIN
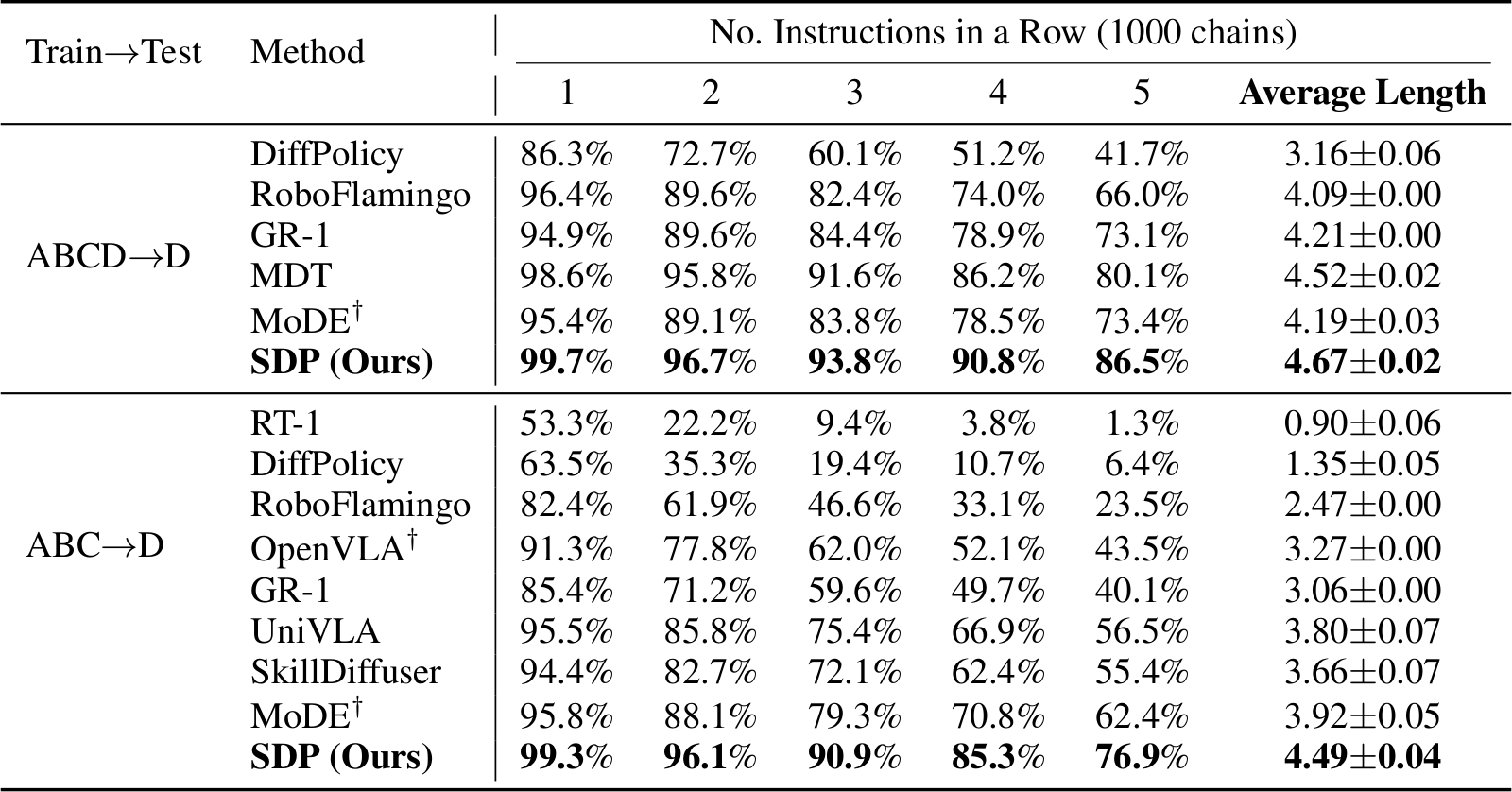
SDP는 CALVIN의 두 설정 모두에서 모든 SOTA를 능가한다. ABCD→D에서 average length 4.67±0.02를 달성하며, 5개 연속 task 성공률 86.5%를 기록한다. 또한 ABC→D에서 76.9% 성공률로 이전 best인 MoDE(62.4%)를 14.5%p, 최근 UniVLA(56.5%)를 20.4%p 능가한다. 평균 연속 완료 task 수는 UniVLA의 3.80에서 4.49로 증가한다. SDP는 단 4 denoising step만 사용하여, 10 step을 사용하는 MDT와 MoDE보다 효율적이다.
LIBERO
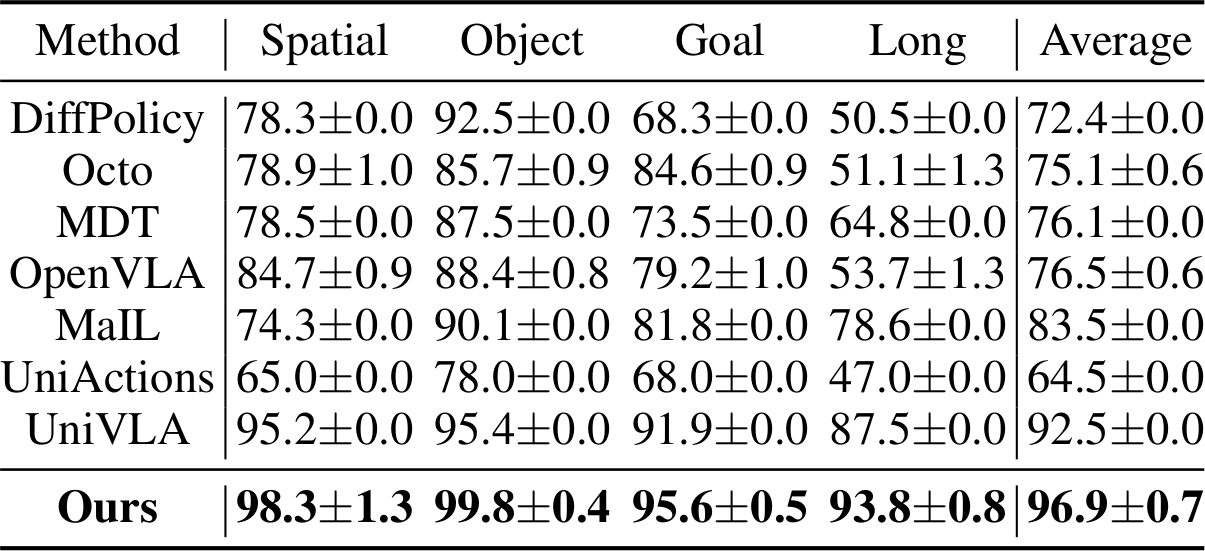
SDP는 LIBERO의 4개 evaluation suite 모두에서 뛰어난 성능을 보인다. LIBERO-Long에서 성공률 90%를 초과하는 유일한 policy이며, 평균 96.9%로 diffusion 기반 MDT를 13.4%p, UniVLA를 4.4%p 능가한다.
Performance on Real-world Robot Manipulation
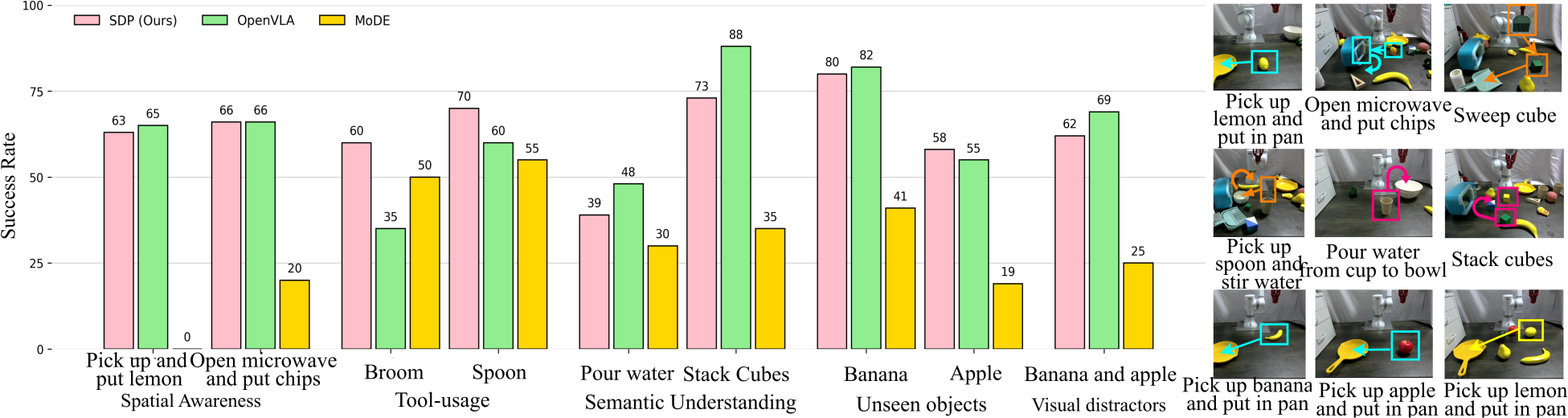
Multi-task Learning
SDP는 모든 task에서 일관되게 최고 성능을 달성하며, spatial awareness, tool usage, semantic understanding 전반에서 clear advantage를 보인다. "Open microwave and put chips", "Pour water" 같은 복잡한 task에서 다른 방법을 significant margin으로 능가한다.
Visual Generalizability
Unseen object과 visual distractor에 대한 일반화를 평가한다. SDP는 학습 시 사용한 레몬과 형태가 유사한 사과를 성공적으로 manipulate하지만, 형태가 다른 바나나에서는 성능이 감소한다. Visual distractor 존재 시에도 성공률이 75%에서 65%로 소폭 하락하는 반면, baseline들은 distractor에 혼란을 겪어 크게 하락한다. 이는 SDP가 task를 skill로 분해하여 skill-aware action을 생성하기 때문이다.
Effectiveness of Design Choices
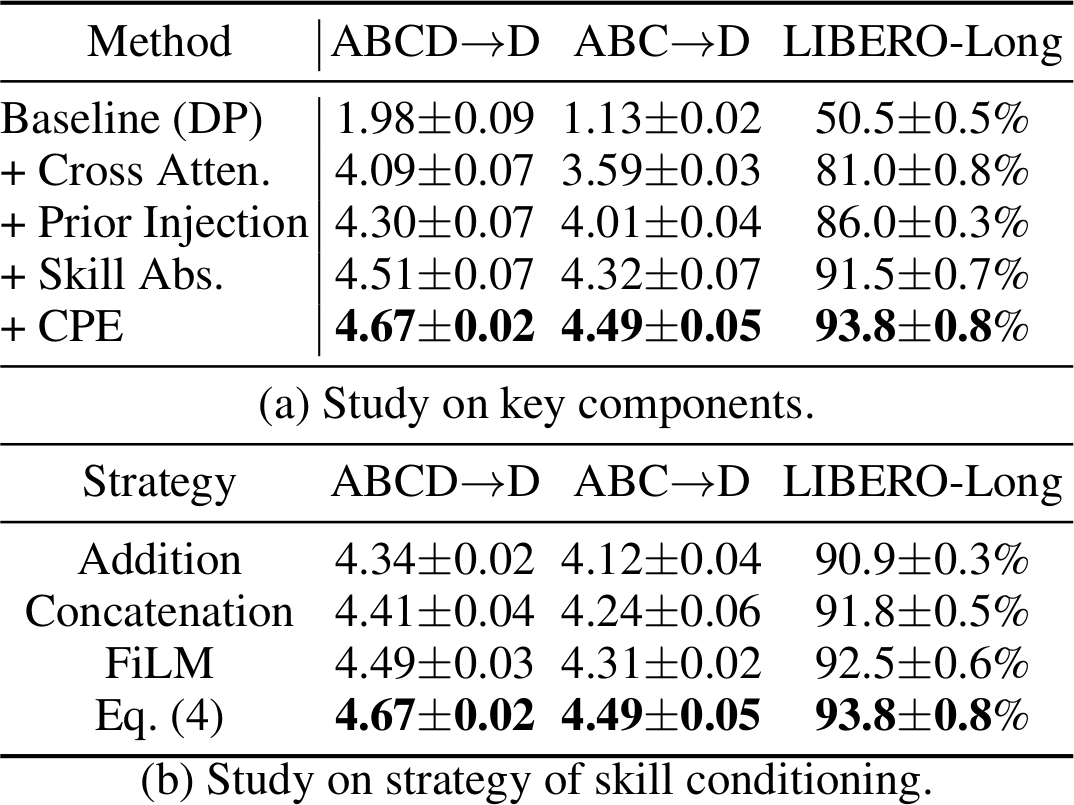
Study on Key Components
SDP의 각 component를 점진적으로 추가하며 효과를 검증한다. Baseline DP에서 시작하여: (1) Cross-attention 추가로 vision-language information 주입 시 큰 성능 향상, (2) AdaLN을 통한 prior injection으로 추가 개선, (3) Skill abstraction(skill-dependent FFN) 도입 시 LIBERO-Long에서 5.5%p 향상, (4) CPE 추가로 최종 최고 성능 달성. 모든 component가 성능 향상에 기여한다.
Study on Skill Conditioning
Skill-dependent FFN의 conditioning 전략을 비교한다. Element-wise addition, concatenation, FiLM과 비교하여, 본 논문의 Eq. (4) 방식(LoRA-like FFN parameterization)이 모든 설정에서 일관되게 최고 성능을 달성한다. LIBERO-Long에서 addition(90.9%) 대비 93.8%를 기록한다.
Complexity Analysis
SDP는 Diff-P-T(286M)와 MoDE(780M) 대비 더 큰 model size(1017M)와 computational cost를 가지지만, inference time 증가는 14.6ms로 negligible하며, 모든 task에서 일관되게 높은 성능을 달성한다.
Visualization Analysis

각 timestep에서 할당된 skill과 해당 observation을 시각화한다. SDP는 학습 과정에서 reusable skill을 할당하는 것을 학습하고, inference 시 이들을 순차적으로 조합하여 전체 task를 완수한다. Explicit supervision 없이도 visual observation이 할당된 skill과 잘 align되어 있어, SDP의 effectiveness와 interpretability를 검증한다.
Conclusion
본 논문은 fine-grained skill learning과 conditional diffusion planning을 통합한 skill-conditioned diffusion policy인 SDP를 제안했다. 다양한 task의 primitive skill을 추상화하고 적절한 skill을 할당하여 action generation을 guide한다. Simulated benchmark(CALVIN, LIBERO)와 real-world robot deployment 모두에서 기존 SOTA를 능가하며, ablation study와 visualization을 통해 각 design choice의 effectiveness와 interpretability를 검증했다.