TL;DR
- 최초의 million-scale 3D vision-language 데이터셋인 SceneVerse를 소개한다. 68K개의 3D indoor scene과 2.5M개의 scene-language pair를 포함한다.
- 3D scene graph 기반 자동 생성 파이프라인으로 object caption, object referral, scene caption 세 가지 수준의 language description을 생성하며, template과 LLM rephrasing을 조합하여 다양성과 자연스러움을 모두 확보한다.
- Grounded Pre-training for Scenes (GPS)라는 multi-level contrastive alignment 프레임워크를 제안하여, 기존 3D visual grounding 및 QA 벤치마크에서 SOTA를 달성한다.
- Data scaling 효과가 GPS뿐만 아니라 3D semantic segmentation 등 다른 3D task에도 유익하며, zero-shot transfer에서도 강한 일반화 능력을 보인다.
Thoughts
이 논문의 핵심 기여는 3D-VL 분야에서 데이터 규모를 한 차원 끌어올린 것이다. 기존 데이터셋들이 수만 개 수준의 scene-text pair에 머물러 있던 것에 비해 2.5M pair라는 규모는 상당히 인상적이다. Scene graph 기반 자동 생성 파이프라인도 체계적으로 설계되어 있고, template 기반 생성과 LLM rephrasing을 조합한 접근은 실용적이면서도 확장 가능하다. 96.93%라는 자동 생성 텍스트의 품질 검증 pass rate도 파이프라인의 신뢰성을 뒷받침한다.
저자들도 인정하듯, synthetic scene(Structured3D, ProcTHOR)의 domain gap은 여전히 해결되지 않은 문제이다. Cross-domain transfer 실험에서 synthetic 데이터로만 학습한 모델이 real scene에 transfer할 때 성능이 크게 떨어지는 반면, real 데이터로 학습한 모델은 synthetic scene에도 비교적 잘 일반화되는 비대칭적 결과가 이를 보여준다. 단순한 scene 수 확장보다는 real scene의 다양성 확보가 더 중요할 수 있다는 점을 시사한다.
GPS 모델 자체의 아키텍처 기여는 제한적이다. Object point cloud encoder + spatial transformer + multi-level contrastive loss라는 구성은 2D-VL에서 이미 검증된 패턴을 3D로 옮긴 것에 가깝다. 실제로 scratch로 학습하면 기존 방법들보다 성능이 떨어지고, pre-training 데이터를 활용해야 비로소 SOTA를 달성한다는 점에서도 모델 설계보다 데이터 스케일이 핵심 동력임을 알 수 있다. 또한 3D-VisTA와 마찬가지로 off-the-shelf 3D object segmentation에 의존하는 object-centric representation의 한계를 공유하고 있어, object proposal이 놓치는 물체에 대해서는 근본적으로 처리할 수 없다.
Introduction
3D vision-language (3D-VL) grounding은 3D 물리 환경과 자연어를 연결하는 분야로, embodied agent 개발의 핵심이다. 2D-VL에서는 billion-scale 데이터셋과 대규모 pre-training이 큰 성과를 거두었지만, 3D-VL에서는 두 가지 근본적 문제가 남아있다.
- 데이터 부족: 3D 데이터 수집은 스캐닝 장비에 의존하므로 본질적으로 비용이 높다. 기존 데이터셋들은 수천 개 scene 수준에 머물러 있으며, 3D scene의 복잡성(다양한 object 구성, 속성, inter-object 관계)을 고려하면 필요한 language description의 양은 훨씬 많다.
- 통합 학습 프레임워크 부재: Grounded 3D 데이터로부터 지식을 추출하는 통합된 학습 방법이 없다.
이를 해결하기 위해 SceneVerse를 제안한다. 68K개 3D indoor scene을 통합하고, human annotation과 scene graph 기반 자동 생성을 통해 2.5M개의 scene-language pair를 구축한 최초의 million-scale 3D-VL 데이터셋이다. 또한 Grounded Pre-training for Scenes (GPS)라는 multi-level contrastive alignment 프레임워크를 제안하여, 기존 3D-VL 벤치마크에서 SOTA를 달성한다.
주요 기여는 세 가지이다.
- 68K 3D scene과 2.5M scene-language pair를 포함하는 최초의 million-scale 3D-VL 데이터셋 SceneVerse를 소개한다.
- Multi-level scene-text contrastive alignment으로 학습되는 transformer 기반 모델 GPS를 제안한다.
- Data scaling과 GPS의 효과를 검증하고, zero-shot transfer에서도 강한 일반화 능력을 보인다. Scaling 효과가 GPS에 국한되지 않고 semantic segmentation 등 다른 3D task에도 유익하다.
SceneVerse
Scene Curation
기존 3D scene 데이터의 부족을 해결하기 위해 다양한 소스에서 데이터를 통합한다. Real-world 데이터셋으로 ScanNet, ARKitScenes, HM3D, 3RScan, MultiScan을 사용하고, synthetic 환경으로 Structured3D와 ProcTHOR를 추가한다. 소스 간의 일관성을 보장하기 위해 room segmentation, point subsampling, axis alignment, 정규화, semantic label alignment 등의 전처리를 수행한다. 각 scan은 point cloud $\text{P} \in \mathbb{R}^{N \times 8}$로 표현되며, 각 point는 3D 좌표, RGB 색상, instance id, semantic label을 포함한다. 총 68,406개의 3D scene을 확보했다.
Referral Annotation by Humans
ARKitScenes, HM3D, MultiScan에서 96,863개의 human-annotated object referral을 수집했으며, 이는 현재까지 가장 포괄적인 규모이다. 한 명의 annotator가 최소 20 단어 이상의 referral text를 작성하고, 두 명의 reviewer가 독립적으로 검증하는 3단계 과정을 거쳤다. 검증을 통과하지 못한 referral은 재작성하도록 했다.
3D Scene Graph Construction
3D scene graph $\mathcal{G} = (\mathcal{V}, \mathcal{E})$를 정의한다. 각 node $v \in \mathcal{V}$는 하나의 3D object instance를 나타내며 centroid $\boldsymbol{p}_i$와 bounding box size $\boldsymbol{b}_i = (b_x, b_y, b_z)$로 parameterize된다. Edge $\mathcal{E}$는 spatial relationship을 나타내며, vertical proximity, horizontal proximity, multi-object relationship 세 가지를 고려한다.
Language Generation with LLMs
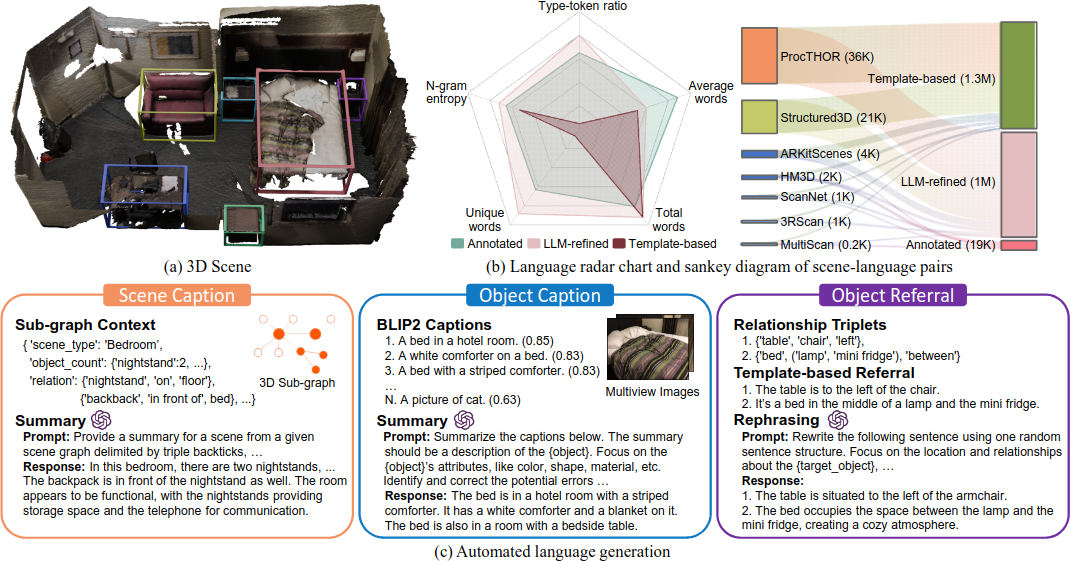
Scene graph를 기반으로 세 가지 granularity의 language description을 자동 생성한다.
- Object Captioning: Object의 point cloud를 multi-view 이미지에서 찾아 bounding box로 crop한 뒤, BLIP2로 초기 caption을 생성한다. CLIP similarity가 높고 occlusion이 적은 상위 10개 문장을 선택하여 LLM으로 요약하고 정제한다.
- Object Referral: Scene graph에서 추출한 spatial relationship triplet $(v_i, v_j, e_{ij})$를 기반으로 template을 사용해 description을 생성한다. (target-object, spatial-relation, anchor-object(s)) 형식으로 다양한 template을 설계했으며, LLM으로 rephrasing하여 자연스러움을 높인다.
- Scene Captioning: Scene graph에서 node와 edge의 subset을 random sampling하여 LLM에 입력하고, scene 전체를 설명하는 global caption을 생성한다. Room type이나 object attribute 같은 부가 정보도 활용한다.
Data Quality and Statistics
Human annotation은 AMT를 통해 수집했으며, 82명의 annotator와 18명의 verifier가 참여했다. Re-annotation rate은 4.8%로 낮았다. 자동 생성 파이프라인의 품질을 검증하기 위해 12K개의 object-level description을 random sampling하여 인간이 확인한 결과 96.93% pass rate를 달성했으며, 이는 ReferIt3D의 86.1%를 능가한다.
최종적으로 SceneVerse는 68,406개의 3D scene, 1.5M개의 object instance(2,290 카테고리), 21종류의 spatial relationship을 포함한다. Language description은 1M개의 template 기반 텍스트와 1M개의 LLM rephrased 텍스트로 구성되며, 기존 소스(294K)와 새로운 annotation(96K)을 합쳐 총 2.5M개의 scene-language pair를 포함한다.
Grounded Pre-training for Scenes (GPS)
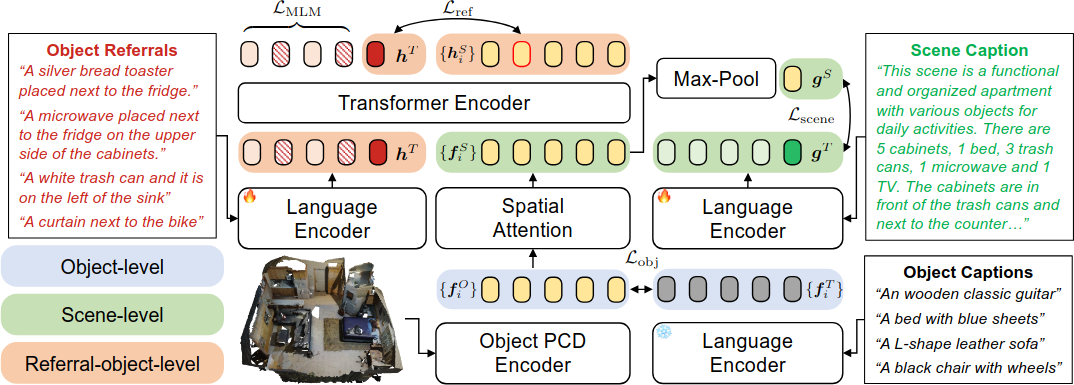
GPS는 3D scene과 text 사이의 multi-level contrastive alignment으로 학습되는 transformer 기반 모델이다. SceneVerse의 다양한 granularity의 language description을 활용하여 object-level, scene-level, referral-object-level 세 가지 수준에서 contrastive objective를 구성한다.
Object-level Grounding
3D scene point cloud $\mathcal{S}$를 off-the-shelf 3D object segmentation 모델로 $N$개의 object bag $\mathcal{S} = \{o_1, o_2, \cdots, o_N\}$으로 분해한다. Object point cloud encoder로 각 object의 feature $\{f_i^O\}$를, frozen language model로 object caption의 text feature $\{f_i^T\}$를 추출한 뒤, CLIP과 유사한 symmetric contrastive loss로 cross-modal alignment을 수행한다.
$\mathcal{L}_{\text{obj}} = -\cfrac{1}{2}\sum\limits_{(p,q)}\left(\log\cfrac{\exp(D^{\text{obj}}(p,q))}{\sum\limits_r \exp(D^{\text{obj}}(p,r))} + \log\cfrac{\exp(D^{\text{obj}}(p,q))}{\sum\limits_r \exp(D^{\text{obj}}(r,q))}\right)$
$D^{\text{obj}}(p,q) = f_p^O f_q^T / \tau$는 object feature와 text feature의 dot product이며, $\tau$는 learnable temperature parameter이다.
Scene-level Grounding
Aligned object feature에 spatial location 정보를 결합하여 scene을 encoding한다. Spatial transformer를 사용해 object feature $\{f_i^O\}$와 spatial location feature $\{l_i\}$를 결합하여 scene-object feature $\{f_i^S\}$를 얻는다. 이 feature들을 projection layer에 통과시킨 뒤 max-pooling하여 scene feature $g^S$를 구하고, scene caption의 text feature $g^T$와 scene-level contrastive alignment을 수행한다.
$\mathcal{L}_{\text{scene}} = -\cfrac{1}{2}\sum\limits_{(p,q)}\left(\log\cfrac{\exp(D^{\text{scene}}(p,q))}{\sum\limits_r \exp(D^{\text{scene}}(p,r))} + \log\cfrac{\exp(D^{\text{scene}}(p,q))}{\sum\limits_r \exp(D^{\text{scene}}(r,q))}\right)$
Referral-object-level Grounding
Referring expression에 담긴 object 간 관계를 모델링하기 위해, self-attention 기반 reasoning transformer를 사용한다. Scene-object feature $\{f_i^S\}$와 object referral $T^{\text{ref}}$를 함께 self-attention transformer에 넣어 aligned object feature $\{h_i^S\}$와 sentence-level referral feature $h^T$를 얻는다. Object-level과 scene-level에서는 inter-scene contrast를 사용했지만, referral-object-level에서는 intra-scene contrast를 사용한다. 같은 scene 내의 object들 사이에서 positive pair를 선택하여 fine-grained object grounding을 학습하기 위해서이다.
$\mathcal{L}_{\text{ref}} = -\log\cfrac{\exp(\bar{h}^S h^T / \tau)}{\sum\limits_p \exp(h_p^S h^T / \tau)}$
$\bar{h}^S$는 referred object의 feature이고, $p$는 같은 scene 내의 모든 object에 대해 iterate한다. 이는 2D-VL에서 region-word alignment에 사용되는 intra-image / inter-image contrast 방식과 유사하다.
학습은 두 단계로 진행된다. 먼저 object point cloud encoder를 object-level grounding objective로 학습한 뒤, scene grounding 단계에서 inter-scene과 intra-scene objective를 masked language modeling loss $\mathcal{L}_{\text{MLM}}$과 함께 학습한다. 전체 loss는 다음과 같다.
$\mathcal{L} = \mathcal{L}_{\text{obj}} + \mathcal{L}_{\text{scene}} + \mathcal{L}_{\text{ref}} + \mathcal{L}_{\text{MLM}}$
Experiments
3D Visual Grounding
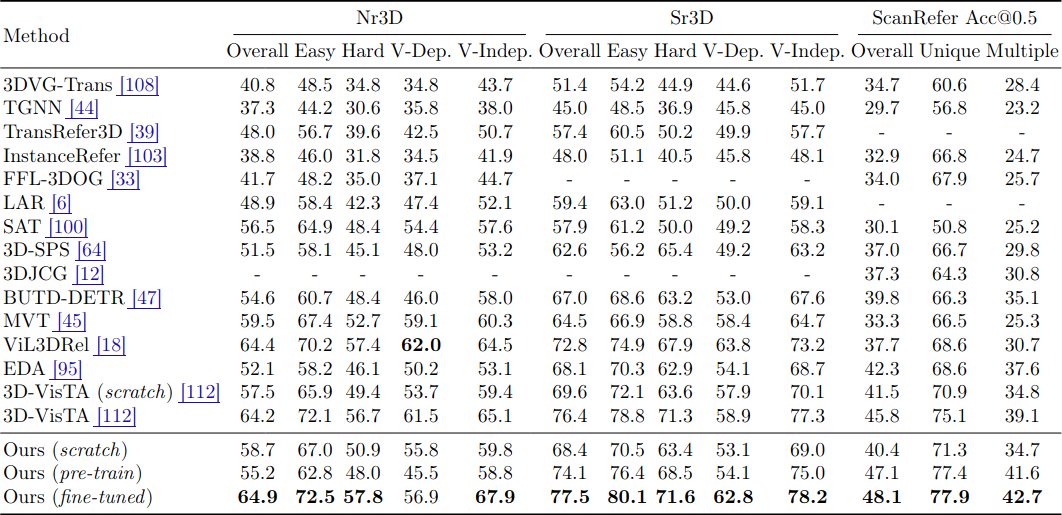
ScanRefer, Nr3D, Sr3D 세 가지 벤치마크에서 평가한다. Nr3D와 Sr3D에서는 ground-truth object mask를 사용하여 grounding accuracy를 보고하고, ScanRefer에서는 Mask3D로 object proposal을 생성하여 Acc@0.5 (IoU > 0.5)를 보고한다.
GPS를 scratch로 학습하면 기존 방법들보다 성능이 떨어지는데, 이는 contrastive alignment 패러다임이 data-intensive하다는 것을 보여준다. 하지만 SceneVerse로 pre-training하면 추가 fine-tuning 없이도 ScanRefer 같은 벤치마크에서 이미 SOTA에 근접한다. Fine-tuning까지 하면 모든 기존 방법을 일관되게 능가한다. 특히 GPS (fine-tuned)는 Nr3D Overall 64.9%, Sr3D Overall 77.5%, ScanRefer Overall/Unique/Multiple에서 48.1%/77.9%/42.7%를 달성하며, projection MLP 하나만 추가하고도 auxiliary architecture나 loss 없이 SOTA를 달성한다는 점이 주목할 만하다.
Zero-Shot Transfer
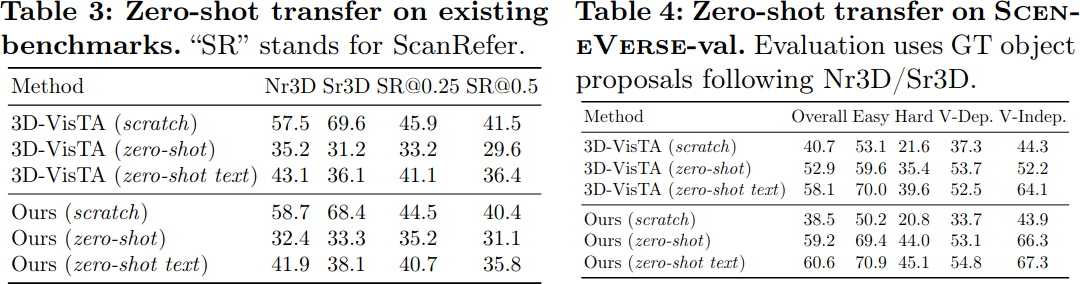
SceneVerse-val(MultiScan의 271개 scene에서 8.5K human-annotated object referral)을 구성하여 zero-shot transfer를 평가한다. 두 가지 설정을 실험한다.
- Zero-shot: Target 데이터셋의 모든 scene을 학습에서 제외하고, held-out unseen scene에서 테스트한다.
- Zero-shot text: Target 데이터셋의 training scene은 포함하되, SceneVerse에서 생성한 텍스트만으로 fine-tuning하고 unseen scene-text 분포에서 테스트한다.
GPS는 3D-VisTA 대비 unseen scene에 대한 일반화가 더 우수하다. 특히 zero-shot text 설정에서, 자동 생성된 scene-text pair만으로도 scene 분포를 효과적으로 학습하여 zero-shot 성능을 크게 향상시킨다. 이는 SceneVerse의 자동 생성 파이프라인이 실제로 유효한 knowledge를 제공한다는 것을 의미한다.
Additional 3D-VL Tasks
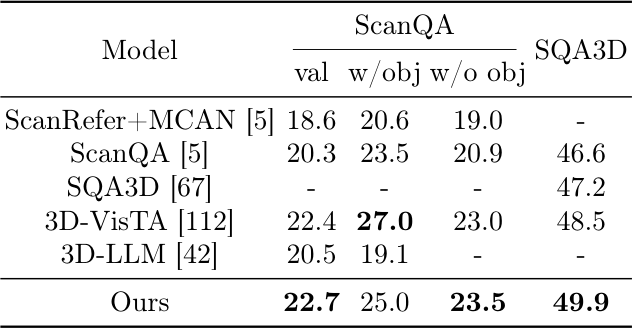
3D Question Answering
ScanQA와 SQA3D에서 평가한다. GPS는 ScanQA val에서 EM@1 22.7, SQA3D에서 49.9를 달성하여 3D-VisTA와 3D-LLM 등 강한 baseline을 능가한다. SceneVerse에 현재 description만 포함되어 있고 QA pair나 dialogue는 없으므로, 이런 유형의 language description을 추가하면 성능을 더 끌어올릴 수 있다.
Open-Vocabulary 3D Semantic Segmentation
SceneVerse의 data scaling 효과가 GPS에 국한되지 않음을 보이기 위해, RegionPLC 모델을 SceneVerse로 pre-training하여 open-vocabulary 3D semantic segmentation을 평가한다. SPUNet16 backbone 기준으로 mIoU가 1.7%, mAcc가 2.2% 향상되고, SPUNet32에서도 mIoU 2.3%, mAcc 2.8% 향상된다. SceneVerse의 collected data가 기존 3D 모델의 scene understanding 성능을 전반적으로 높일 수 있음을 확인한다.
Ablative Studies and Discussion
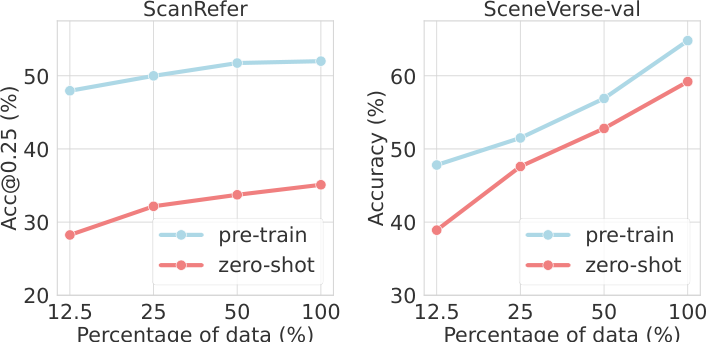
Data Scaling
SceneVerse 데이터의 1/8, 1/4, 1/2, 전체를 사용하며 data scaling 효과를 검증한다. Pre-train 설정과 zero-shot 설정 모두에서 데이터 규모가 커질수록 일관되게 성능이 향상된다.
Generated vs. Human-annotated Data
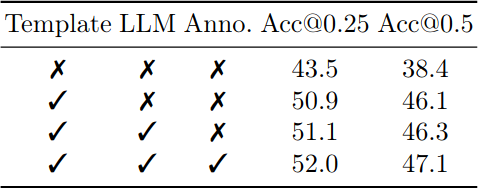
기존 ScanRefer만으로 학습한 모델은 ScanRefer Acc@0.25 43.5%에 그치지만, template 기반 텍스트를 추가하면 50.9%로 크게 뛰어오른다. 여기에 LLM rephrasing을 더하면 51.1%로 소폭 향상되고, human annotation까지 추가하면 52.0%에 도달한다. 자동 생성 텍스트가 가장 큰 성능 향상을 가져오며, human annotation의 추가 기여는 상대적으로 작다는 점이 인상적이다.
Cross-domain Transfer (Sim2Real)
Synthetic subset(Structured3D, ProcTHOR)으로만 학습한 모델은 해당 synthetic test set에서는 뛰어나지만 real scene이나 다른 synthetic scene으로 transfer할 때 성능이 크게 떨어진다. 반면 real scene으로 학습한 모델은 synthetic scene에 대한 일반화가 더 잘 된다. 이는 real scene과 synthetic scene 사이의 domain gap을 확인시켜 주며, 단순히 scene 수를 늘리는 것보다 자연스럽고 다양한 real 3D scene data를 수집하는 것이 더 중요하다는 점을 시사한다.
GPS Model Design
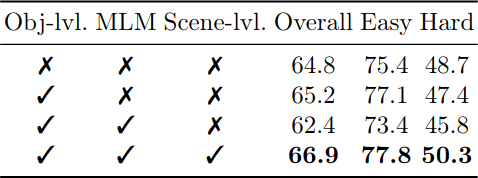
SceneVerse-val에서 각 alignment level의 효과를 ablation한다. Scene-level alignment을 제거하면 약 5%의 성능 하락이 발생하며, object-level(약 2% 하락)과 MLM(약 1.5% 하락)도 각각 기여한다. Scene-level objective가 referral object grounding에서 가장 큰 역할을 하며, 이는 scene 전체의 맥락을 이해하는 것이 개별 object grounding에도 핵심적이라는 것을 보여준다.
Conclusion
SceneVerse는 68K 3D scene과 2.5M scene-language pair를 포함하는 최초의 million-scale 3D-VL 데이터셋이다. Human annotation과 scene graph 기반 자동 생성 파이프라인을 결합하여 다양하고 high-quality한 데이터를 수집했다. GPS는 multi-level contrastive alignment으로 학습되며, 3D visual grounding과 QA 벤치마크에서 SOTA를 달성한다. Zero-shot transfer 실험을 통해 SceneVerse와 GPS의 일반화 능력을 확인했으며, data scaling 효과가 GPS에 국한되지 않고 3D semantic segmentation 같은 다른 task에도 유익하다는 점을 보였다.