Introduction
3D 공간에서 manipulation을 수행하는 전통적인 방식은 2D 이미지만을 이용하는데, 3D reasoning이 필요한 태스크를 잘 수행하지 못한다. 반면 explicit 3D 정보를 이용하는 모델들은 voxel과 같은 representation을 이용하는데, 연산 비용이 커 scalability를 저하시킨다. Voxel을 이용하는 모델인 PerAct의 경우는 8개의 V100 GPU에서 16일 동안 학습해야 한다.
따라서 본 논문은 성능이 뛰어나면서도 2D view 기반 모델들의 scalability까지 갖춘 모델인 RVT를 제안한다. RVT는 PerAct에 비해 학습 시간을 36배 단축하면서도 RLBench에서 평균 약 26% 더 높은 성능을 보인다. Inference 속도 또한 약 2.3배 향상시켰다.
RVT는 트랜스포머 아키텍쳐를 이용하여 multi-view 정보를 통합하는 방식을 사용한다. 또한 렌더링 방식으로 multi-view 이미지를 생성하기 때문에 몇몇 practical한 이점을 갖는다.
Method
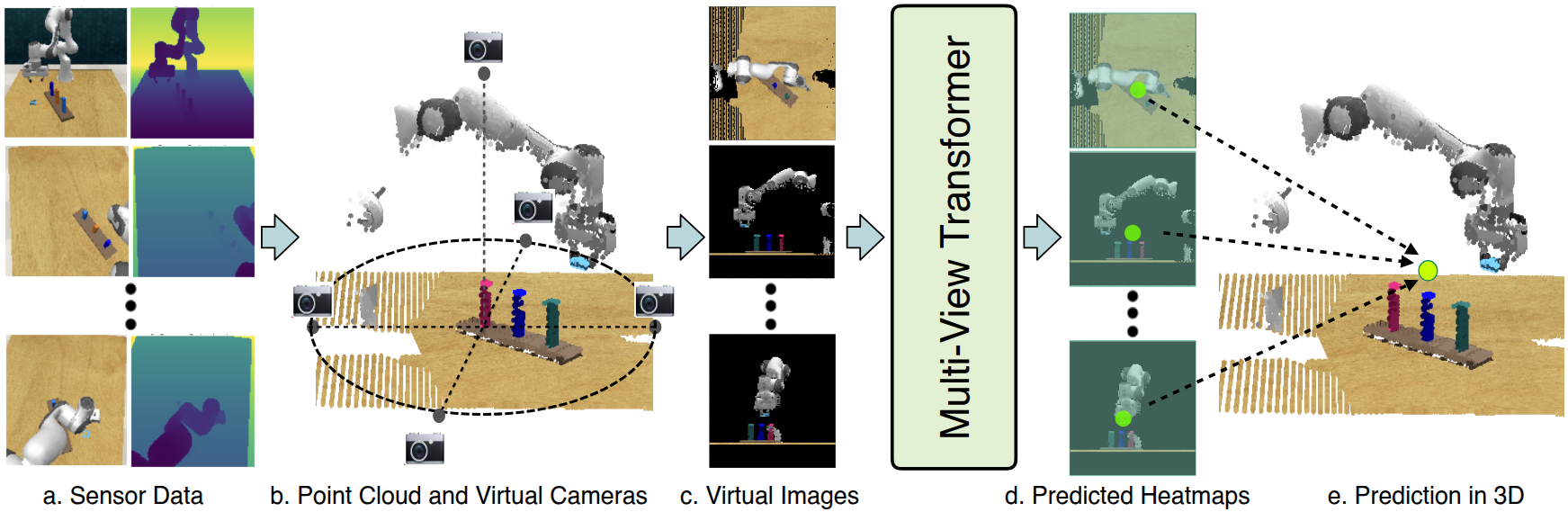
RVT는 하나의 모델로 다양한 범위의 manipulation task를 수행할 수 있다.
입력 데이터는 (1) 태스크에 대한 자연어 설명, (2) 현재의 이미지 정보 (RGBD), (3) 현재의 gripper state (open/closed)이다. 이를 이용하여 모델은 다음 keyframe의 target end-effector pose와 gripper state로 정의되는 action을 출력해야 한다. 이때 keyframe이란 태스크 수행에 필요한 중요한 frame들을 말한다. Target pose가 주어지면 low-level motion planner가 로봇을 그 pose로 움직일 수 있다고 가정한다. 학습을 위해서는 human expert demonstration 데이터셋을 사용한다.
RVT를 한 문장으로 요약하면, 로봇 주변의 가상 카메라로부터 로봇 workspace를 이미지로 렌더링하고, 트랜스포머 모델을 통해 각 view에 대한 output을 출력하고, 이를 3D로 back-project해서 gripper pose action을 예측한다.
Rendering
RGB-D 이미지 한 장 또는 여러 장이 주어지면, 먼저 scene에 대한 포인트클라우드를 생성한다. 이후 이 포인트클라우드는 로봇 주변의 가상 카메라들로 re-render된다. 이때 RGB, depth, point map(각 픽셀별 월드좌표계에서의 xyz 좌표)을 렌더링하여 총 7채널 이미지가 된다. 렌더링 툴로는 PyTorch3D를 사용하였다.
렌더링된 이미지를 트랜스포머에 입력하는 것은 몇 가지 장점이 있다. 첫째, 테이블 바로 위와 같이 실제로 카메라를 배치하기 어려운 뷰도 렌더링을 통해 얻을 수 있다. 둘째, 일반적인 perspective projection이 아니라 orthographic image로 렌더링할 수 있다. 셋째, 카메라로 찍은 이미지로는 얻기 어려운 3D point map을 활용할 수 있다. 이러한 부가적인 장점들은 실험적으로 검증하였다.
Joint Transformer
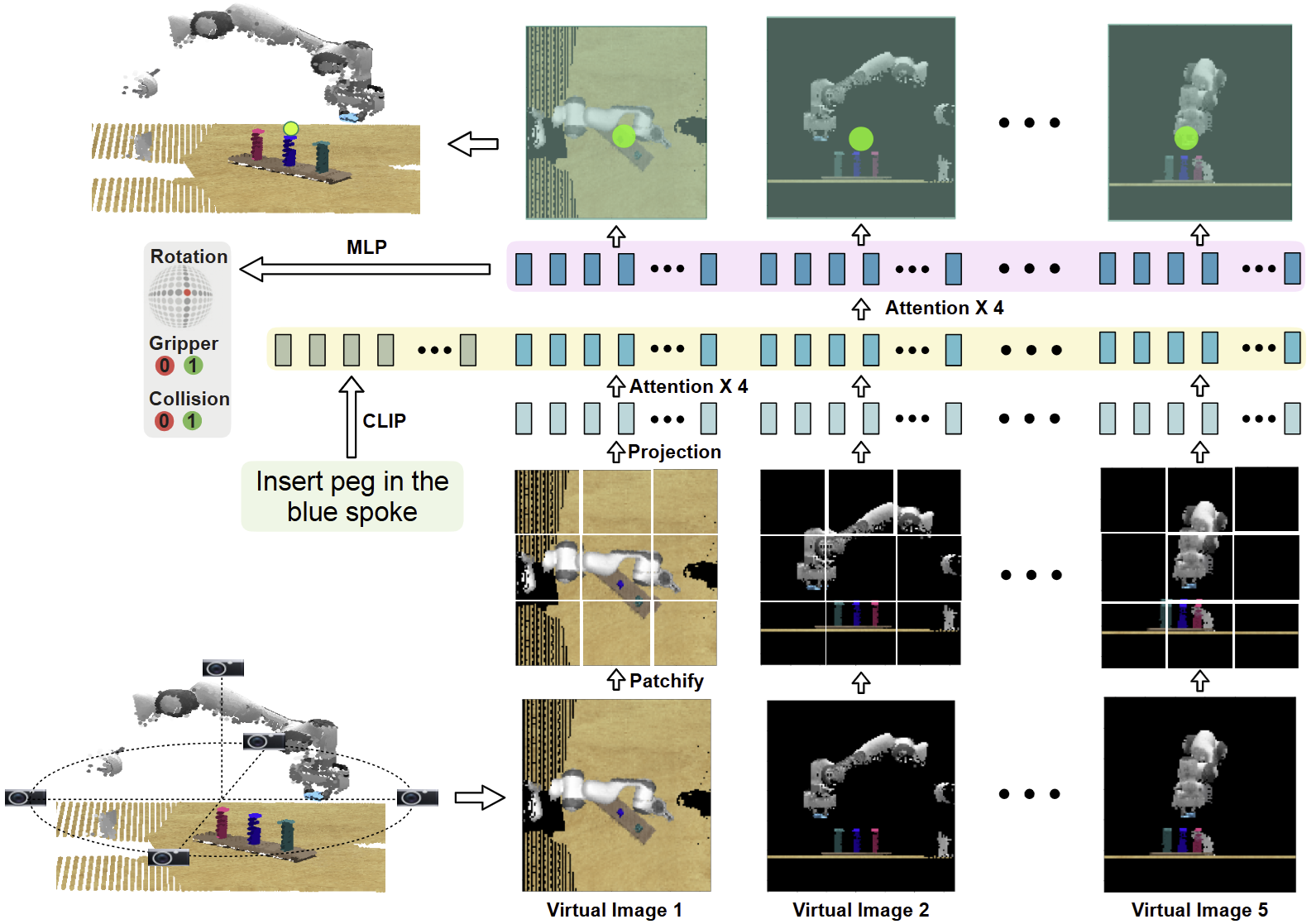
렌더링된 이미지, 텍스트 명령, gripper state는 위 그림과 같은 joint transformer model에서 처리된다. 텍스트는 CLIP을 사용하여 한 단어당 한 토큰으로 변환된다. 렌더링된 이미지는 $20 \times 20$ 크기의 패치로 분할된 후 MLP를 거쳐 이미지 토큰이 된다. 이는 ViT의 방식과 비슷하다. Gripper state는 PerAct와 비슷한 방식으로 MLP를 통과시킨 후 이미지 토큰에 concat한다. Positional embedding도 사용한다.
RVT는 8개의 self-attention layer로 구성된다. 첫 4개 레이어에서는 이미지 토큰은 같은 이미지에서 나온 다른 토큰들과만 attend하는 것이 허용된다. 이를 통해 네트워크는 각각의 이미지를 먼저 이해한 후 이미지간 정보를 공유하도록 유도된다. 각 토큰별 output은 다시 원래의 이미지 형태로 재배치되어 이후 과정에 사용된다.
Action Prediction
모델은 8차원의 action 벡터를 출력한다. Action은 6-DoF의 end effector pose(3차원 translation, 3차원 rotation), 1-DoF gripper state, motion planner에서 collision을 허용할지 결정하는 binary indicator로 구성된다.
Translation을 구하기 위해서는, 먼저 joint transformer에서 출력된 가상 카메라별 feature map을 이용하여 heatmap을 생성한다. 이후 여러 뷰에서의 heatmap이 back-project되어 3D 공간에서 로봇 주변 영역에서의 score를 dense하게 계산한다. 최종적으로, 가장 점수가 높은 위치가 end effector의 goal 위치가 된다. 이처럼 입출력의 spatial structure가 같기 때문에 sample efficiency가 좋다고 한다.
End effector rotation의 경우에는 PerAct와 같이 Euler angles representation을 사용한다. 각 각도는 $5^\circ$ 간격으로 discretized 되었다. Gripper state와 motion planner collision indicator는 binary variable로 표현된다. 이 세 가지 값들을 예측하기 위해 global features $\mathcal{G}$를 사용한다. Global feature는 아래 2가지의 concatenation이다.
- Image feature map을 translation heatmap을 weight로 하여 weighted sum한 것
- Image feature map을 max-pooling한 것
$i$번째 이미지의 image feature를 $f_i$, 예측된 translation heatmap을 $h_i$라고 하면 $\mathcal{G}$는 아래와 같이 계산된다.
$\mathcal{G} = \left[ \phi(f_1 \odot h_1); \cdots; \phi(f_K \odot h_K); \psi(f_1); \cdots; \psi(f_K) \right]$
이때 $k$는 이미지의 수, $\odot$은 element-wise 곱셈, $\phi$와 $\psi$는 각각 height와 width 차원으로의 sum 및 max-pooling 연산이다. Heatmap을 weight로 사용함으로써 예측된 goal 위치에서의 이미지 정보에 더 집중하도록 한다.
Loss Function
Heatmap은 cross-entropy loss를 사용하는데, 이때 ground truth는 target 3D 위치에 truncated Gaussian distribution을 위치시키고 이를 2D로 projection하여 사용하였다. Rotation은 각 Euler angle에 대해 cross-entropy loss를 사용하였다. 나머지 두 변수에는 binary classification loss를 사용하였다.
Experiments
시뮬레이션은 CoppelaSim을 사용하였고, PerAct와 같이 RLBench의 18개 task에 대해 실험을 진행했다. Baseline으로는 Image-BC, C2F-ARM-BC, PerAct를 사용하였다. 태스크별로 100개의 expert demonstrations을 학습에 사용하였다. Data augmentation을 위해서는 포인트클라우드를 작은 거리만큼 perturb하는 방식과 z축 기준으로 $\pm 45^\circ$ 랜덤 회전시키는 방식을 사용하였다.
Multi-Task Performance
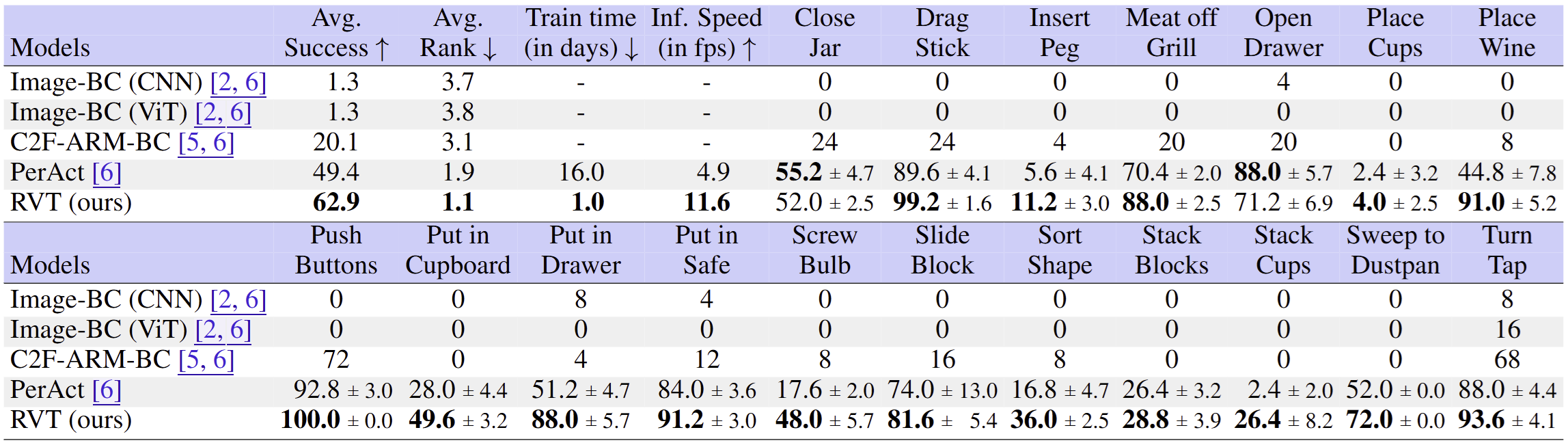
PerAct와 RVT는 다른 모델들보다 훨씬 좋은 성능을 보인다. RVT는 모든 베이스라인보다 뛰어난 성능을 보인다. 인상적인 것은, RVT는 PerAct보다 36배 적은 시간 학습하였음에도 대부분의 태스크에서 PerAct보다 성능이 높았다. Inference 시간도 RVT가 PerAct에 비해 2.3배 빠르다.
Ablation Study
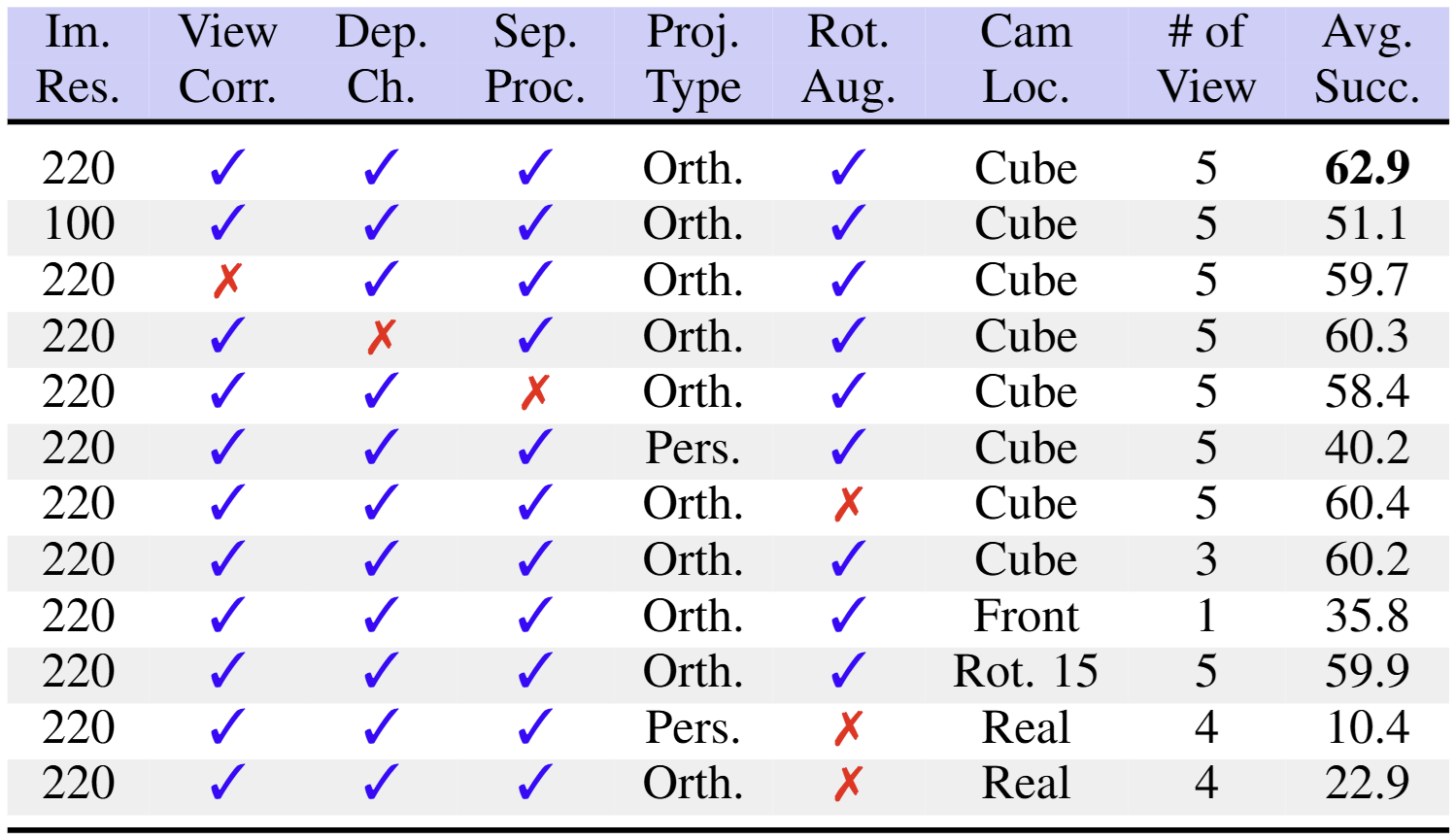
Ablation study 결과는 위와 같다.
- 이미지 해상도를 220으로 하는 것이 100으로 하는 것보다 성능이 좋았다.
- Point map을 이용해 view correspondence를 추가하는 것은 성능에 도움이 되었다.
- Depth를 사용하는 것도 성능에 도움이 되었다.
- 초반 4개 레이어에서 이미지 각각을 먼저 처리하는 방식 또한 성능 향상에 도움이 되었다.
- Orthographic projection을 사용하는 것이 perspective projection보다 좋았다.
- 3D rotation augmentation을 사용하는 것이 도움이 되었다.
- Robot과 table을 기준으로 5가지 방향(위, 앞, 뒤, 왼쪽, 오른쪽)에 가상 카메라를 배치하는 것이 가장 성능이 좋았다. 3개의 뷰만 사용하거나 카메라의 각도를 회전시키는 것은 성능에 좋지 않은 영향을 미쳤다.
- 실제 이미지보다 렌더링된 이미지를 사용하는 것이 더 좋았다. Augmentation을 적용하기 어렵고 실제 카메라의 위치가 suboptimal할 수 있기 때문인 것으로 보인다.
Real-World

실제 로봇에서의 실험 셋업은 위와 같다. Stack blocks, press sanitizer, put marker in mug/bowl, put object in drawer, put object in shelf의 5가지 태스크에 대해 실험을 진행하였다. Human demonstration을 통해 총 51개의 데이터를 수집하고 10K step 동안 학습을 진행하였다.
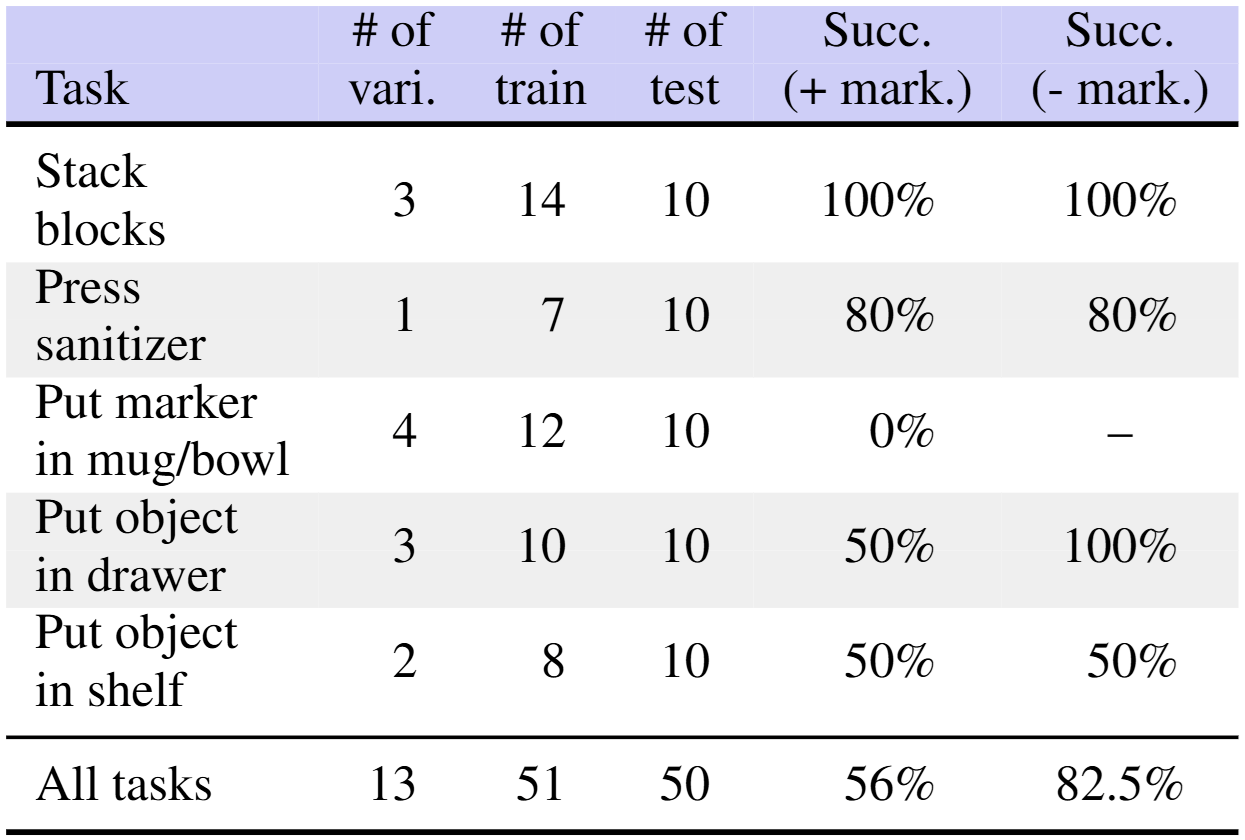
Stack block, press sanitizer 태스크에 대해서는 높은 성공률을 보였다. put object in drawer, put object in shelf와 같은 더 긴 태스크에 대해서도 50%의 성공률을 보였다.
RVT는 마커와 관련된 태스크에서는 성능이 떨어졌는데, 포인트클라우드가 sparse하고 noisy하기 때문으로 생각된다.
Conclusions
RVT는 3D object manipulation을 위한 multi-view transformer 모델이다. 다양한 3D manipulation 태스크를 높은 성공률로 수행할 수 있으며, 학습 또한 빠르고 scalable하다. RVT는 real world에서도 잘 작동할 수 있다.
가상 뷰 배치를 어떻게 하는 것이 효율적일지, 그리고 camera extrinsic calibration 없이 구현이 가능할지는 future work으로 남겼다.