Introduction
Can large pretrained vision-language models be integrated directly into low-level robotic control to boost generalization and enable emergent semantic reasoning?
RT-2는 이 질문에 대한 답을 위해 제안된 모델이다. Internet-scale data로 학습된 VLM을 robot action 데이터로 파인튜닝해서, 텍스트 형식으로 로봇의 low-level action을 출력하게 했다. 이를 위해 저자들은 (1) action을 텍스트 토큰으로 변환시키고, (2) VQA와 같은 일반적인 vision-language task와 action task를 혼합하여 VLM을 파인튜닝하는 co-fine-tuning 전략을 사용했다. RT-2는 RT-1을 기반으로 하면서 large vision-language backbone을 사용하는 것으로 아키텍쳐를 확장했다.
이처럼 vision과 language를 입력받아 action을 직접 출력하는 모델을 vision-language-action models (VLA)라 지칭한다.
Methodology
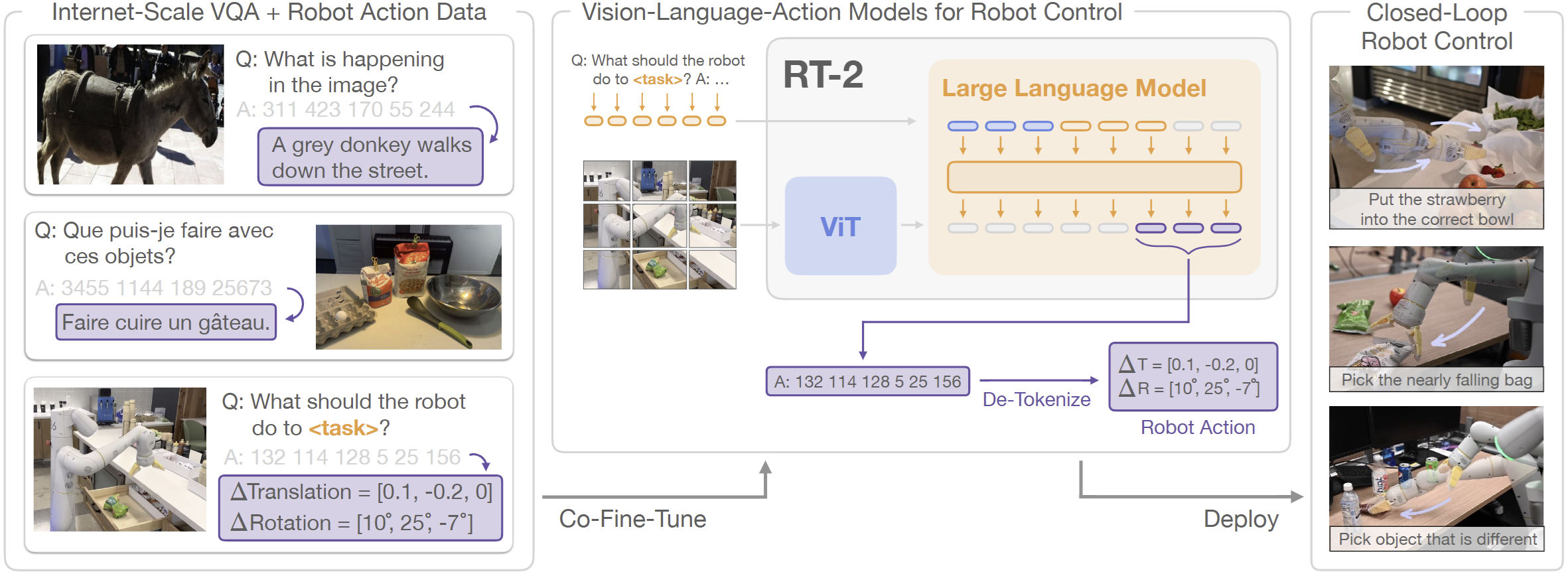
Action Encoding
본 논문에서는 PaLI-X와 PaLM-E라는 VLM을 기반으로 RT-2-PaLI-X와 RT-2-PaLM-E를 구현하였다. 로봇의 액션을 텍스트로 출력하도록 하는 action encoding 방식은 RT-1 논문을 기반으로 한다. 6-DoF end effector pose, gripper extension, 그리고 episode 종료 여부를 각각의 변수로 표현하는데, 이때 end effector pose와 gripper extension은 연속적인 변수이므로 256개의 bin으로 uniformly discretization한다.
$\mathrm{terminate} \ \ \Delta \mathrm{pos}_x \ \ \Delta \mathrm{pos}_y \ \ \Delta \mathrm{pos}_z \ \ \Delta \mathrm{rot}_x \ \ \Delta \mathrm{rot}_y \ \ \Delta \mathrm{rot}_z \ \ \mathrm{gripper\_extension}$
즉, 하나의 action은 위와 같이 8개의 정수로 표현되고, 이러한 값들을 표현하기 위해 256개의 토큰이 필요하다. PaLI-X 모델의 경우 최대 1000까지의 정수가 unique한 토큰으로 정해져 있기 때문에 각 숫자를 그대로 활용한다. 반면 PaLM-E의 경우 이러한 숫자 토큰이 없기 때문에 가장 적게 쓰이는 256개의 토큰을 overwrite한다.
이러한 표현을 이용한 question-answer 데이터의 예시는 아래와 같다.
- Q: what action should the robot take to [task instruction]?
- A: 1 128 91 241 5 101 82 127
Co-Fine-Tuning
RT-2에서는 이러한 로봇 데이터만을 100% 사용해서 파인튜닝을 진행하지 않는다. 대신 기존 VLM을 pretrain할 때 사용된 일반적인 VQA 데이터셋과 일정 비율 혼합하여 사용한다. 이 방식 덕분에 모델이 기존에 학습된 지식을 forget하지 않아 더 좋은 일반화 성능을 낸다고 한다. 실제 로봇에서 실행하는 경우 로봇의 action만을 출력해야 하기 때문에 이때는 가능한 출력 토큰을 256개의 action token들만으로 한정한다고 한다.
Real-Time Inference
거대 VLM을 실시간으로 inference 하기 위해, TPU cloud service를 이용한다. 55B 파라미터인 RT-2-PaLI-X-55B 모델의 경우 1-3Hz의 control frequency로 로봇을 제어할 수 있다.
Experiments
How does RT-2 perform on seen tasks and more importantly, generalize over new objects, backgrounds, and environments?

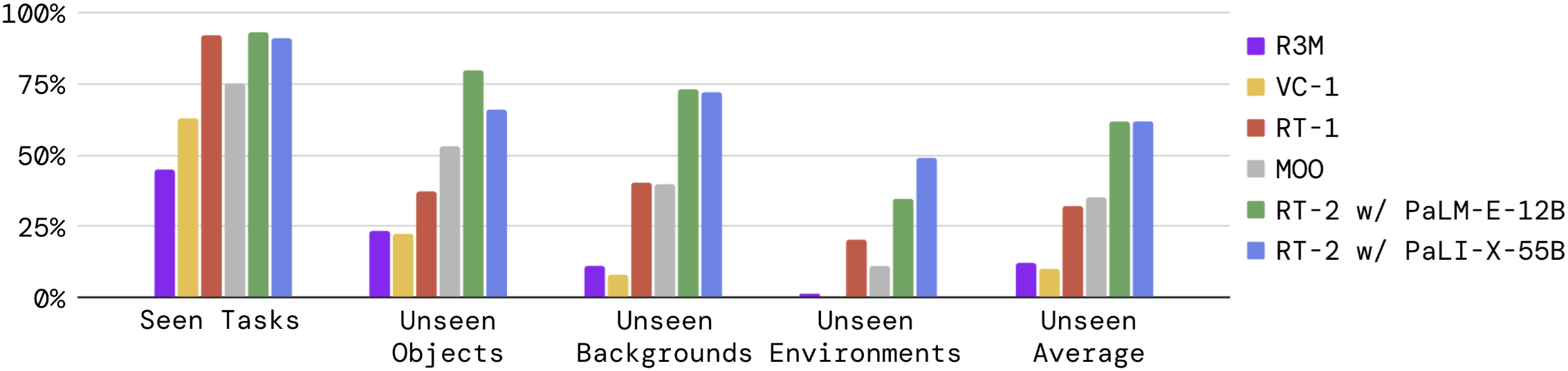
본 논문에서는 RT-2와 다른 baseline들을 200개 이상의 seen task 및 280개 이상의 unseen objects, backgrounds, environments로 시험하였다. 위 그림과 같이 seen task에서는 RT-1과 RT-2의 성능이 유사하지만 unseen scenarios에서는 평균적으로 RT-2가 RT-1 및 다른 모델들보다 2배 이상 좋은 성능을 보이는 것을 알 수 있다. 이를 통해 internet-scale pretraining을 활용하는 것의 효과를 확인할 수 있다.
Can we observe and measure any emergent capabilities of RT-2?
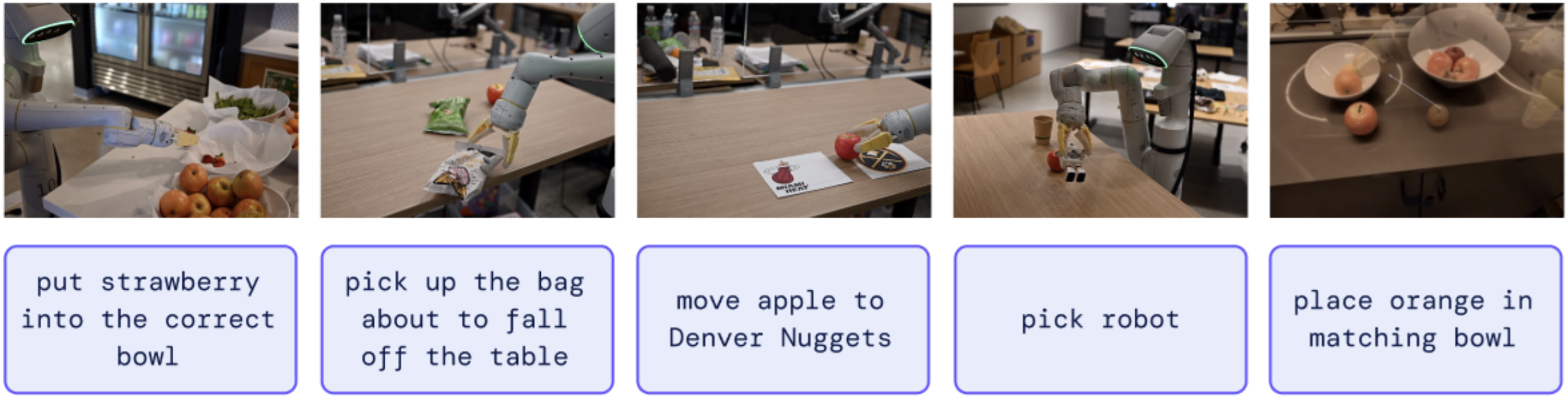
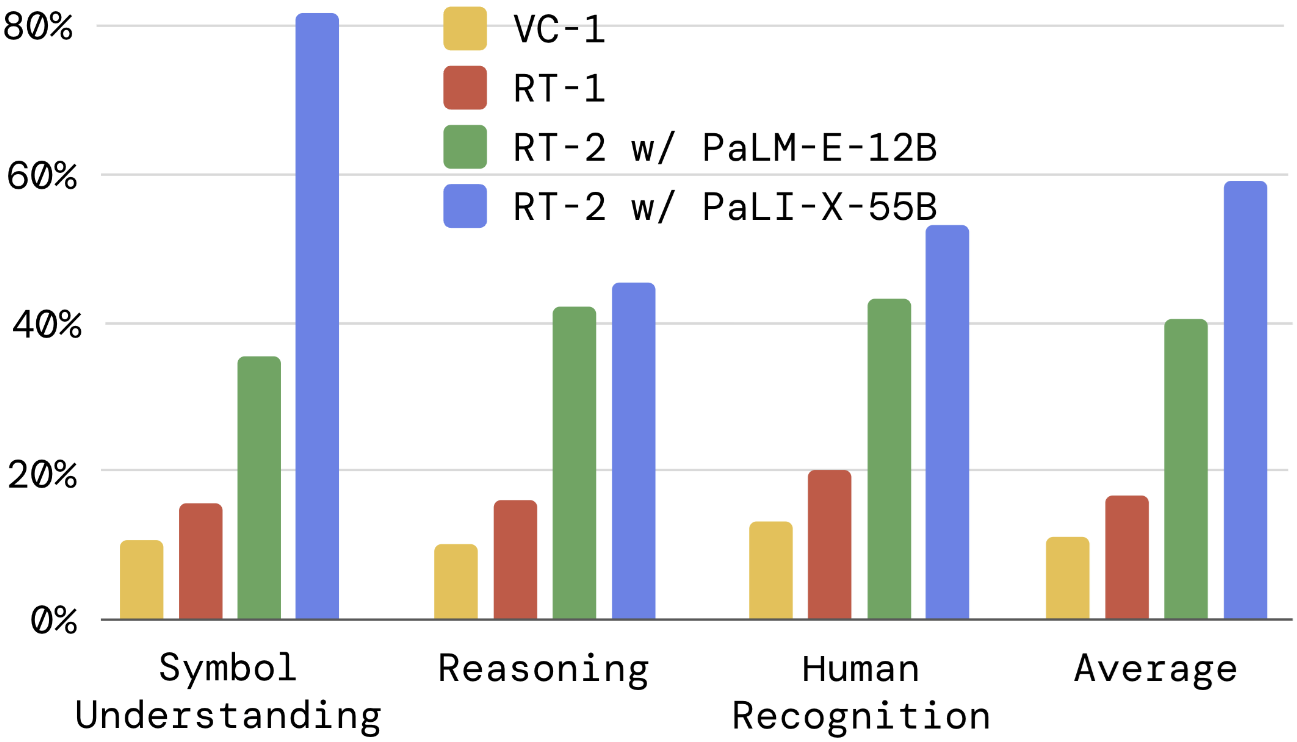
모델이 새로운 물체나 물체간 관계에서도 성능을 유지하는지를 살펴본다. 이때 새로운 로봇 동작은 제외한다. 아래의 총 3가지의 subtask로 나누어 성능을 측정하였다.
- symbol understanding: 숫자, 기호와 같은 새로운 모양을 얼마나 잘 이해하는지.
- reasoning: 추론 능력을 얼마나 잘 사용하는지.
- human recognition: 사람 얼굴을 얼마나 잘 인식하는지.
RT-2는 VLM의 추론 능력 덕분에 다른 baseline들보다 월등한 성능을 보였고, 특히 더 큰 모델인 RT-2-PaLI-X-55B이 작은 RT-2-PaLM-E-12B보다 더 좋은 성능을 보였다.
How does the generalization vary with parameter count and other design decisions?
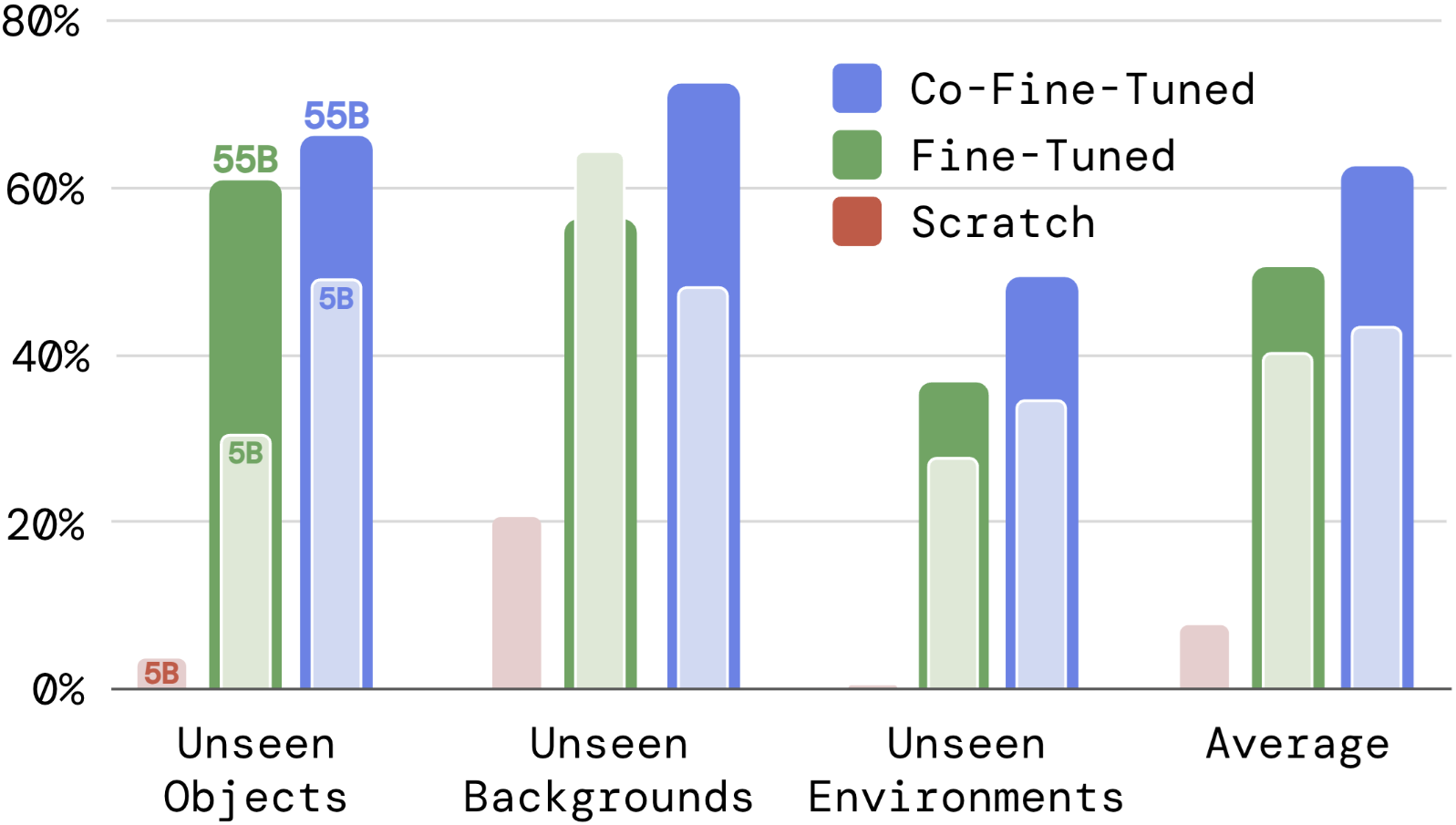
이 부분에서는 VLM 파라미터 크기와 co-fine-tuning 전략의 효과를 일반화 성능 측면에서 알아본다. 우선 로봇 데이터만으로 from scratch 학습하는 것은 아주 poor한 성능을 보인다. 또한 모든 model size에서 co-fine-tuning을 하는 것이 로봇 데이터만으로 fine-tuning하는 것보다 더 좋은 성능을 보였다. 이는 모델이 기존에 가진 지식을 forget하지 않았기 때문으로 추정한다. 마지막으로, 모델의 크기가 클수록 더 좋은 일반화 성능을 보였다.
Can RT-2 exhibit signs of chain-of-thought reasoning similarly to vision-language models?

RT-2의 chain-of-thought 능력을 확인하기 위해, 텍스트에 "Plan" 단계를 추가해서 수백 step 더 fine-tuning한 후 성능을 측정하였다. Plan 단계에서는 아래와 같이 action을 하는 목적을 자연어로 설명하고, 그 후 그에 따른 액션 토큰을 넣어 준다.
"Instruction: I'm hungry. Plan: pick rxbar chocolate. Action: 1 128 124 136 121 158 111 255."
그 결과, 상단의 그림과 같이 모델의 출력으로 Plan이 나온 후에 Action이 출력된다. CoT를 적용한 모델의 경우 더 세밀한 명령을 잘 수행하는 것을 qualitative하게 확인했다. 이는 planner 역할의 LLM이나 VLM과 low-level 제어를 담당하는 policy가 하나의 VLA 모델로 합쳐질 수 있는 가능성을 보여 준다.
Conclusions
VLM과 로봇 데이터를 결합함으로써 vision-language-action (VLA) models을 만들 수 있다. 특히, action을 text token으로 표현하고 기존 vision-language 데이터와 co-fine-tuning함으로써 RT-2-PaLM-E와 RT-2-PaLI-X 모델을 구현했다. 이러한 모델은 더 나은 policy, 더 좋은 일반화 성능 및 emergent capabilities를 보인다.
Limitations
RT-2는 새로운 장면을 인식할 수는 있어도 새로운 동작 (motion)을 만들어낼 수는 없다. 다양한 action에 대한 데이터를 수집함으로써 해결할 수 있을 것으로 보인다. 또한 VLM을 실시간으로 연산하는 데 시간적 비용이 많이 든다. 따라서 quantization, distillation과 같은 기법을 활용해 large model을 더 빠른 속도로, 더 낮은 등급의 하드웨어에서도 작동하도록 하는 것은 앞으로 연구해야 할 영역으로 보인다. 마지막으로, 이 시점에는 오픈소스로 사용할 수 있는 VLM이 많지 않은데, 더 많은 VLM이 공개된다면 VLA 모델을 만드는 데 도움이 될 것이다.