Introduction
기존의 imitation learning 방식은 action chunking 방식을 사용하기 때문에 실시간 촉각 신호에 즉시 반응하기 어렵다. 또한 많은 teleoperation 시스템은 미세한 tactile이나 force feedback을 제공하기 어려워 가능한 task에 제한이 있다.
이러한 문제점들을 해결하기 위해, 본 논문에서는 TactAR라는 저비용 teleoperation 시스템을 제안한다. 증강현실을 이용해 tactile 신호를 실시간으로 제공해 줄 수 있다. 또한 Reactive Diffusion Policy (RDP)라는 새로운 slow-fast visual-tactile imitation learning 프레임워크를 제안한다.
RDP는 두 단계로 이루어져 있다. (1) slow latent diffusion policy는 느린 속도(1-2Hz)로 latent action chunk를 만들고, (2) fast asymmetric tokenizer는 실시간 tactile 신호와 latent action chunk를 융합하여 빠른 속도(20-30Hz)로 closed-loop 제어 신호를 출력한다.
Related Work
Robot Data Collection System
현재 대부분의 teleoperation 시스템은 VR controller, hand tracking, 또는 direct joint mapping 기반으로 구축되며, 시각 정보에만 의존하기 때문에 정밀한 contact-rich task를 수행하기 어렵다. Haptic feedback을 제공하는 시스템도 존재하지만, isomorphic hardware가 필요하거나 비용이 높거나 pose estimation이 부정확한 등의 한계가 있다. 본 논문의 TactAR는 저비용 VR 헤드셋(Meta Quest3, ~500 USD)만으로 AR을 통해 실시간 tactile/force feedback을 제공하며, 다양한 센서와 로봇 플랫폼에 유연하게 적용할 수 있다.
Visual-tactile Manipulation
Tactile sensing을 활용한 로봇 조작 연구는 오래전부터 있었지만, 대부분 task-specific modeling, hand-designed primitives, hand-crafted rewards에 의존하여 일반화가 어렵다. 최근 visual imitation learning에 tactile을 통합하려는 시도들이 있지만, 대부분 normal force reading만 사용하거나 visual input을 제외하는 등 제한적이다. 본 논문은 normal force, shear force, visual RGB를 모두 통합한 unified visual-tactile policy를 제안하여 더 넓은 범위의 task에 적용 가능하다.
Teleoperation System: TactAR
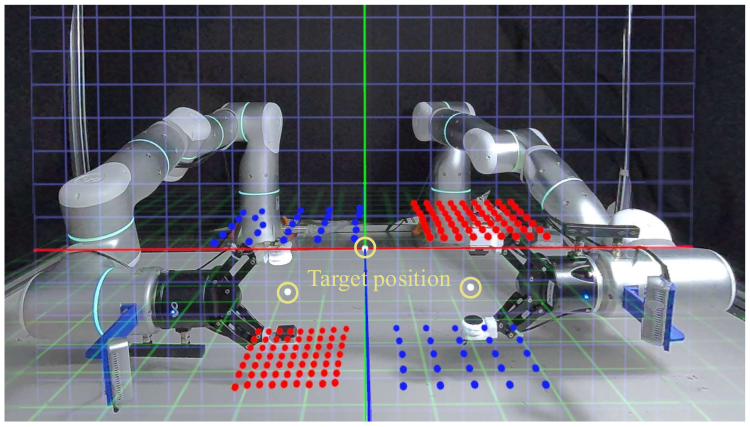
TactAR는 AR 기반 teleoperation 시스템으로, Meta Quest3의 color pass-through 모드를 활용한다. ROS2 기반 아키텍처로 tactile/force 센서, 로봇 컨트롤러, RGB 카메라의 데이터 스트림을 동기화한다.
3D Deformation Field Extraction
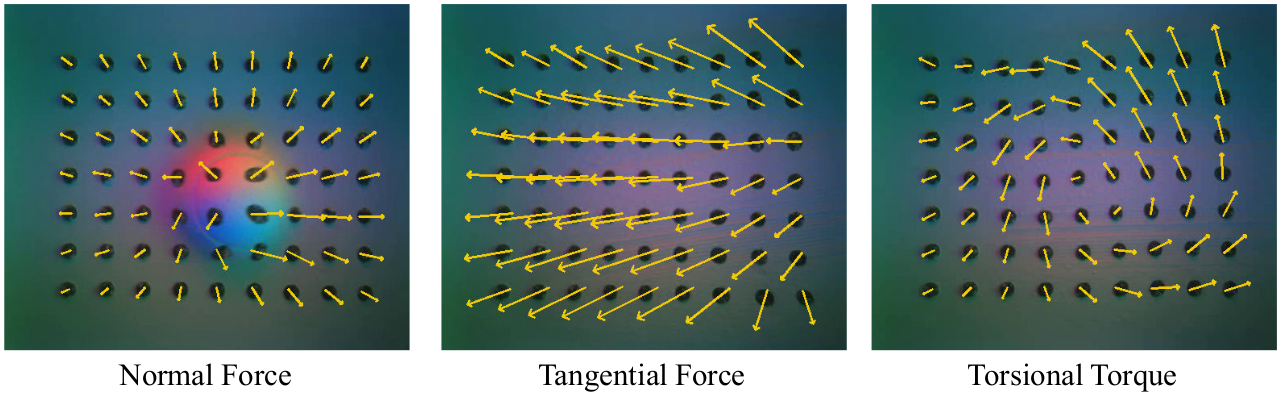
Optical tactile 센서(e.g., GelSight Mini)의 gel 표면 marker array에서 2D optical flow를 계산하여 3D deformation field를 추출한다. Tactile 이미지에서 marker 위치를 추출한 뒤, 초기 프레임과 현재 프레임 사이의 optical flow $F_t = Flow(D_0, D_t)$를 계산한다. 이를 z-offset과 합쳐 3D deformation field $V_t = [d_x, d_y, o_z]$로 만들어 AR에 렌더링한다. Force 센서의 경우 6D wrench(force + torque)를 직접 시각화한다.
Real-time Tactile/Force Feedback Rendering in AR
Quest3의 SLAM 알고리즘으로 헤드셋/컨트롤러 포즈를 추적하고, 간단한 calibration을 통해 AR과 로봇 좌표계를 정렬한다. 3D deformation field를 로봇 end-effector에 부착하여 AR로 렌더링함으로써, 사용자가 normal force, shear force, torsional torque 등의 접촉 정보를 실시간으로 인지할 수 있다.
Versatility and Accessibility
TactAR의 핵심 특성은 세 가지이다. (1) Cross-sensor: 3D deformation field를 통일된 표현으로 사용하여 GelSight Mini, MCTac, joint torque sensor 등 다양한 센서에 적용 가능하다. (2) Cross-embodiment: TCP 포즈와 3D deformation field만 있으면 되므로, 다양한 로봇 팔과 그리퍼에 배포 가능하다. Single-arm과 bimanual 모두 지원한다. (3) Low cost: Meta Quest3(~500 USD)와 optical tactile 센서(GelSight Mini ~549 USD, MCTac ~50 USD)만으로 구성 가능하다.
Learning Algorithm: Reactive Diffusion Policy
Tactile/Force Representation
Optical tactile 센서의 경우, marker deformation field $\mathbf{F}$에 PCA를 적용하여 저차원 표현을 생성한다. PCA 특성은 tracking 오류나 marker 노이즈에 강건하며, gel 교체에 따른 텍스처/조명 변화에도 강건하다. Force 센서의 경우 6D wrench(force + torque)를 observation vector에 직접 연결한다.
Slow-Fast Policy Learning
기존 action chunking 방식은 temporal consistency와 non-Markovian behavior 모델링에 효과적이지만, chunk 실행 중 open-loop이므로 실시간 tactile feedback에 반응할 수 없다. Temporal ensembling은 semi-closed-loop을 제공하지만, multi-modal distribution과 non-Markovian action 모델링 능력이 저하되고 smoothing coefficient에 민감하다.
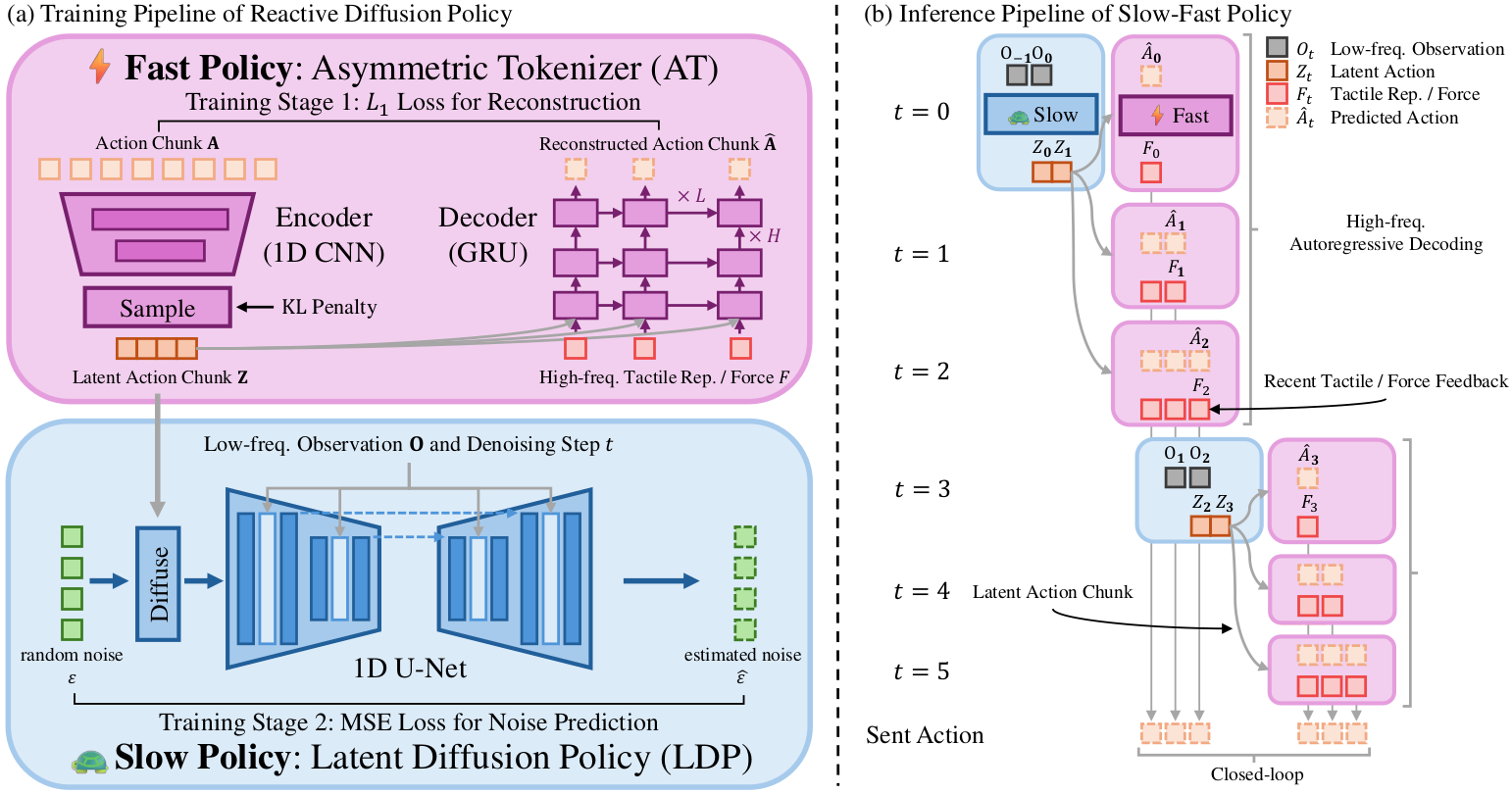
RDP는 이 trade-off를 해결하기 위한 slow-fast 프레임워크이다. 학습은 두 단계로 진행된다.
Fast Policy: Asymmetric Tokenizer (AT)
AT는 1D-CNN encoder와 GRU decoder로 구성된다. Encoder는 action chunk $\mathbf{A}$만을 입력으로 받아 latent action chunk $\mathbf{Z} = \mathcal{E}(\mathbf{A})$로 다운샘플링한다. Decoder는 latent action chunk과 tactile representation을 함께 받아 action을 복원한다: $\hat{\mathbf{A}} = \mathcal{D}(\text{concat}([\mathbf{Z}, \mathbf{F}^{reduced}]))$. AT는 L1 reconstruction loss와 KL penalty로 학습되며, 추론 시간은 1ms 미만이다.
$L_{AT} = \mathbb{E}_{(\mathbf{A}, \mathbf{F}^{reduced}) \in \mathcal{D}_{policy}} \left[ \|\mathbf{A} - \hat{\mathbf{A}}\|_1 + \lambda_{KL} L_{KL} \right]$
이때 $\lambda_{KL}$은 작게 유지하여 latent space를 smooth하게 만들되, generative model로 변하지 않도록 한다.
Slow Policy: Latent Diffusion Policy (LDP)
Slow policy는 latent action chunk에 대해 동작하는 Diffusion Policy이다. Stochastic Langevin Dynamics를 통해 noisy action을 iterative하게 denoising하여 clean action을 생성한다. Latent space에서 동작하므로 계산 비용이 줄어들고, AT의 비대칭 설계 덕분에 reactive behavior가 latent chunk에서 제외되어 diffusion policy의 학습이 용이해진다. CNN 기반 Diffusion Policy에 FiLM 기반 condition injection을 사용한다.
$L_{LDP} = \mathbb{E}_{(\mathbf{O}, \mathbf{A}^0) \in \mathcal{D}_{policy}, k, \epsilon^k} \|\epsilon^k - \epsilon_\theta(\mathbf{O}, \mathbf{Z}^0 + \epsilon^k, k)\|_2$
Implementing Suggestions for Slow-Fast Policy
추가적인 설계 요소로, (1) Relative trajectory: compounding error를 줄이기 위해 end-effector 기준의 relative pose trajectory를 사용한다. Base frame은 action chunk의 마지막 observation frame이다. (2) Latency matching: policy 추론과 action 실행 사이의 latency를 보상하기 위해, 처음 몇 action step을 버리고 정확하게 매칭된 action만 전송한다. 이는 action chunk 사이의 전환을 부드럽게 하고, out-of-distribution tactile 신호로 인한 비정상 action을 방지한다.
Experiments
Setup

Hardware
Flexiv Rizon 4 로봇 팔 2대와 Flexiv Grav 그리퍼 2대를 사용한다. Tactile/force 센서로 GelSight Mini, MCTac, built-in joint torque sensor 세 종류를 사용한다.
Baselines
Baseline으로는 vanilla Diffusion Policy (DP), DP with tactile image, DP with tactile embedding을 비교한다.
Tasks
세 가지 contact-rich task를 평가한다. (1) Peeling: 사람이 들고 있는 오이를 필러로 깎는 task. Precision과 fast response가 필요하다. (2) Wiping: 사람이 들고 있는 화병 표면을 지우개로 닦는 task. Adaptive force control과 fast response가 필요하다. (3) Bimanual Lifting: 두 팔로 종이컵을 집어 올리는 task. Precise force control과 bimanual coordination이 필요하다.
Evaluation Protocols
평가 시 모든 method에 대해 유사한 초기 상태를 설정한다. Peeling과 Wiping은 세 가지 test-time variation으로 평가한다: (a) no perturbation, (b) perturbation before contact, (c) perturbation after contact. Bimanual Lifting은 (a) soft paper cup, (b) hard paper cup 두 가지로 평가한다. 각 조건당 10회 시행한다.
점수 책정 방식은 task마다 다르다. Peeling은 깎인 오이 껍질 비율을 demonstration 평균 점수로 정규화한다. Wiping은 남은 글씨 잔여물 수준에 따라 1(demonstration 수준), 0.5(1/3 미만 잔여), 0(상당량 잔여)으로 평가한다. Bimanual Lifting은 종이컵을 찌그러뜨리지 않고 들어올리면 1, 부분적으로 찌그러지면 0.5, 들어올리지 못하거나 떨어뜨리면 0으로 평가한다.
Implementation Details
Diffusion Policy와 LDP는 open-loop 12 FPS action sequence를 예측한다. Fast policy(AT)는 24 FPS로 tactile/force observation을 받아 action을 갱신한다. 즉, slow policy 한 번 호출당 fast policy가 고정된 횟수만큼 실행되는 구조이다.
Results
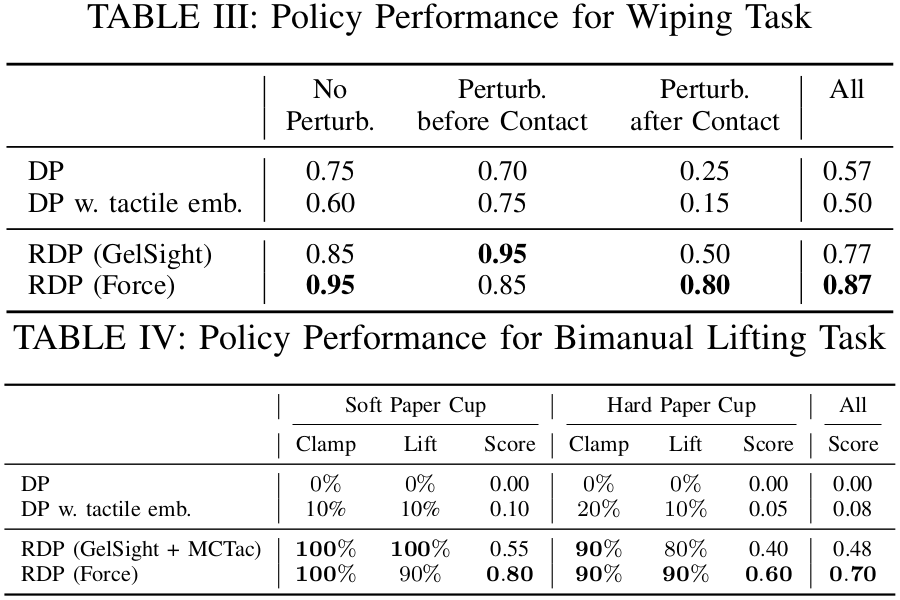

Q1: Tactile 신호가 성능을 향상시키는가?
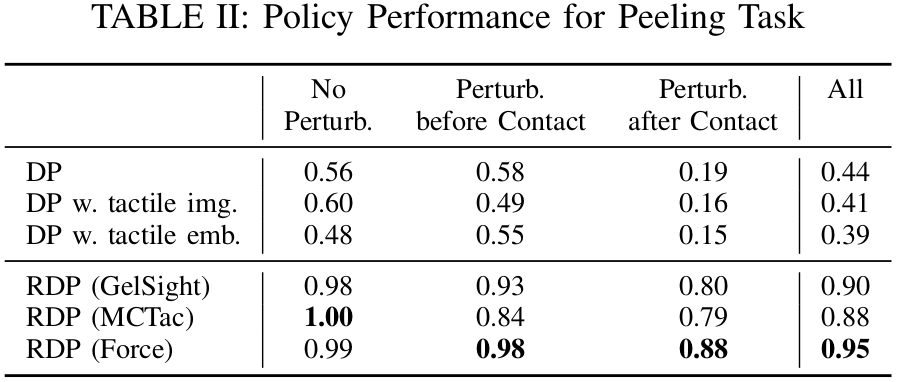
단순히 tactile 신호를 observation에 추가하는 것만으로는 성능이 향상되지 않는다. Peeling에서 DP(0.44), DP w. tactile img.(0.41), DP w. tactile emb.(0.39)로 오히려 비슷하거나 하락한다. Wiping에서도 DP(0.57) vs DP w. tactile emb.(0.50), Bimanual Lifting에서도 DP(0.00) vs DP w. tactile emb.(0.08)로 거의 차이가 없다.
흥미롭게도 두 DP baseline은 비슷한 성능이지만 failure mode가 다르다. Visual input만 사용하는 DP는 부정확한 trajectory를 예측하여 큰 접촉력을 발생시키는 반면, tactile embedding을 사용하는 DP는 큰 접촉력은 드물지만 접촉 시 stuck되는 경향이 있다. 이는 tactile embedding DP가 데이터에서 일부 reactive behavior를 학습하지만 (e.g., 접촉 시 위로, 느슨해지면 아래로), open-loop 실행이므로 정밀한 조정이 불가능하기 때문인 것으로 분석된다.
Q2: RDP의 성능은?
RDP는 세 가지 task 모두에서 DP baseline 대비 큰 성능 향상을 달성했다. Peeling에서 RDP(GelSight) 0.90 vs DP 0.44, Wiping에서 RDP(Force) 0.87 vs DP 0.57, Bimanual Lifting에서 RDP(Force) 0.70 vs DP 0.00이다. Case study 분석에서 RDP의 fast policy가 sub-millimeter 수준의 보정을 수행함을 확인했다. 예를 들어 peeler가 오이에 접촉할 때 접촉력이 급증하면 fast policy가 위쪽으로 보정하고, 오이 끝에 도달하면 아래쪽으로 보정하여 표면을 밀착 추적한다. 특히 Bimanual Lifting에서는 force input을 사용할 때 multi-modal behavior(두 가지 상향 trajectory)가 관찰되어, slow policy(LDP)가 diffusion model의 multi-modal 모델링 능력을 유지함을 확인했다.
Q3: 다양한 tactile/force 센서에 적용 가능한가?
Peeling에서 GelSight(0.90), MCTac(0.88), Force(0.95)로 세 종류 센서 모두 높은 성능을 보인다. GelSight Mini와 MCTac은 LED 색상(RGB vs white), gel 재질(hard vs soft), marker array(7x9 vs 5x7), 해상도(8MP vs 2MP), 프레임 레이트(25 vs 30 FPS)가 모두 다름에도 비슷한 성능을 달성했다. Bimanual Lifting에서는 서로 다른 센서(MCTac + GelSight)를 양손에 사용해도 0.48을 달성했다. Force 센서는 로봇 움직임 시 노이즈가 크지만, latency가 낮고 차원이 작아 학습이 용이하여 세 task 모두에서 최고 수준의 성능을 보인다.
Q4: 외부 perturbation에 즉시 반응하는가?
Perturbation after contact 조건에서 RDP와 DP의 차이가 가장 두드러진다. Peeling에서 RDP(GelSight) 0.80 vs DP w. tactile emb. 0.15, Wiping에서 RDP(Force) 0.80 vs DP w. tactile emb. 0.15이다. DP baseline은 contact를 잃으면 open-loop으로 나머지 trajectory를 실행하여 오이 껍질이 부러지거나 화병 글씨가 남는 반면, RDP는 fast policy로 즉시 trajectory를 보정하여 contact를 회복한다.

Q5: Ablation study
Slow-fast hierarchy 없이 closed-loop 제어 빈도를 높이는 대안을 검토했다. (1) Action chunk size를 8에서 2로 줄이면 grasp 성공률이 100%에서 20%로 급감한다. 작은 chunk는 non-Markovian behavior(e.g., 공중에서의 pause)에 취약하다. (2) Temporal ensembling은 smoothing coefficient $\tau$에 매우 민감하여, $\tau = 0.2$일 때 grasp 성공률 30%, $\tau = 0.5$일 때 0%, $\tau = 0.8$일 때 over-smoothing으로 reactivity가 저하된다. 또한 relative trajectory와 latency matching 모두 성능에 중요한 기여를 한다.
Q6-Q7: TactAR의 데이터 품질 기여
User study(10명)에서 70% 이상이 tactile/force AR feedback이 매우 도움이 된다고 응답했다. TactAR로 수집한 데이터는 기존 VR teleoperation 대비 normalized peeling length(0.72 → 0.91)와 stable contact force 비율(0.58 → 0.87)이 크게 향상되었다. 또한 고품질 데이터로 학습한 policy는 저품질 데이터 대비 30% 이상 높은 성능을 보여, 데이터 품질이 RDP 성능에 직접적인 영향을 미침을 확인했다.
Conclusion
본 논문은 저비용 AR 기반 teleoperation 시스템 TactAR와 slow-fast imitation learning 알고리즘 RDP를 제안했다. TactAR는 고가의 하드웨어 없이 AR을 통해 실시간 tactile/force feedback을 제공할 수 있음을 보여주었다. RDP는 slow network(LDP)로 complex trajectory를 모델링하고 fast network(AT)로 실시간 tactile feedback 기반 closed-loop 제어를 달성하여, sequence modeling과 closed-loop control 사이의 trade-off를 해결했다. 세 가지 contact-rich task에서 SOTA visual IL baseline 대비 큰 성능 향상을 달성했으며, cross-sensor 실험으로 다양한 tactile/force 센서에 대한 일반화 능력을 검증했다.
Limitations and Future Works
(1) TactAR의 AR 기반 tactile/force feedback은 직접적인 손 촉각만큼 직관적이지 않다. 센서 및 시스템 latency를 줄여 teleoperation 효율을 개선할 수 있다. (2) 현재 TactAR는 two-finger gripper용으로 설계되어 있다. Dexterous hand로 확장하는 것이 유망한 방향이다. (3) Fast policy는 현재 고주파 tactile/force 신호에만 반응하며, 고주파 이미지 입력은 처리하지 못한다. Fast network에 고주파 visual input을 통합하면 적용 가능한 task 범위가 넓어질 수 있다. (4) RDP는 현재 single-task에 한정되어 있다. VLA 모델의 tokenizer를 asymmetric tokenizer로 대체하여 RDP를 통합하면, VLA 내에서 closed-loop tactile/force 제어가 가능해질 수 있다.