Introduction
Point-SLAM is a dense neural SLAM system for monocular RGBD input that directly operates on point clouds. Neural feature is anchored in each point itself and describe the geometry and appearance of each point location. This strategy allows the system to be more accurate while being more memory-efficient than previous works. Since the system is point-based, the point cloud map can be directly used for tracking, while other methods employ off-the-shelf methods for tracking which causes a data redundancy.
The main contribution of this work is their point-based feature anchoring method, which can be used for both tracking and mapping.
Related Work
Dense Visual SLAM and Mapping
Traditional 3D reconstruction strategies employed truncated signed distance functions (TSDF). Lately, methods relying on test time optimization have become popular since they can generalize to unseen environments. Neural Radiance Fields (NeRF) is one of the most popular methods in this category. However, none of the neural SLAM approaches supports a point-based scene encoding with high fidelity.
Scene Representations
Most dense 3D reconstruction works can be separated into three categories: (1) gridbased, (2) point-based, (3) network-based.
Grid-based representations use dense grids, hierarchical octrees, or voxel hashing. This enables fast neighborhood lookups and context aggregation. However, their fixed resolution can cause memory inefficiency in low-complexity areas and insufficient detail in high-complexity regions.
Point-based representations address grid limitations and are effective for 3D reconstruction, as point density can vary across the scene without preset resolution. By focusing points around surfaces, memory usage is minimized. However, neighborhood searches are challenging due to the lack of structure. For dense SLAM, this can be mitigated by projecting points onto 2D keyframes or registering them in a grid. Point-SLAM propose a hybrid approach combining point flexibility with grid-based search.
Network-based methods provide a continuous, compressed 3D scene representation using MLP weights, enabling high-quality map and texture recovery. However, they struggle with online reconstruction due to limited local updates and fixed network capacity. We address this by using neural implicit representations anchored to 3D points, enabling scalability and local updates.
Method
Neural Point Cloud Representation
The neural point cloud consists of a set of N points defined as:
$p = \{ (p_i, f^g_i, f^c_i) | i = 1, ..., N \}$
where $p_i$ is the 3D point location, and $f^g_i$ and $f^c_i$ are geometric and color feature descriptors.
During each mapping phase, pixels are sampled across the image, some uniformly and others among pixels with the highest color gradient. Using depth information, these pixels are unprojected into 3D, and neighbors are searched within a radius $r$.
If no neighbors are found, three neural points are added along the ray adjacent to the input depth value. If neighbors exist, no points are added. Feature vectors $f^g_i$ and $f^c_i$ are initialized with normal distribution.
To optimize memory and computation, neighbor search radius $r$ is adjusted based on scene complexity, which is estimated by the color gradient. Therefore, the system can maintain low density in simple areas and high density in detailed regions.
Rendering
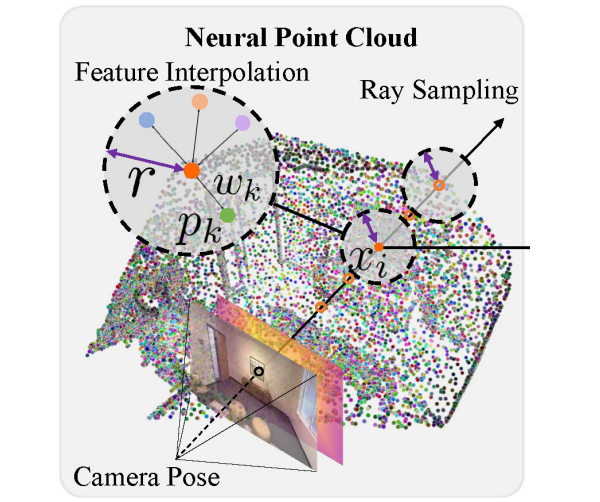
To render depth and color, Point-SLAM adopts a volume rendering strategy. Given a camera origin $O$ and direction $d$, points along the ray are defined as:
$x_i = O + z_id, \quad i \in \{ 1, ..., M \},$
where $z_i$ is the point depth. Unlike feature grid-based methods, Point-SLAM only samples 5 points near the sensor depth per ray. This can be done since the system knows the depth of the surface.
Since any point in the space can be sampled by the nature, the geometric and color features should be interpolated from the neighboring points. This is done by a weighted sum of the features, where the weight is the inverse distance to the point.
Next, the interpolated feature is decoded by the MLP. For each sampled point $x_i$, the occupancy $o_i$ and color $c_i$ are decoded using MLPs. The MLP for the occupancy is pretrained, and the MLP for the color is trainable. Gaussian positional encoding is used here.
Finally, these occupancy and color values are accumulated along the ray using the volume rendering equation.
Mapping and Tracking
During mapping, we render $M$ uniformly sampled pixels and minimize the re-rendering loss to the ground truth depth and color using:
$L_{map} = \sum\limits_{m=1}^M | D_m - \hat{D}_m |_1 + \lambda_m | I_m - \hat{I}_m |_1,$
where $D_m$ and $I_m$ are the ground truth depth and color values, and $\hat{D}_m$ and $\hat{I}_m$ are the rendered estimates. The hyperparameter $λ_m$ balances the depth and color losses. This loss optimizes both geometric and color features $(f^g, f^cv)$ and the decoder parameters.
For tracking, we first initialize the new pose using a constant speed assumption based on the previous poses. We then sample $M_t$ points from the incoming image and use them to optimize the camera pose $(R, t)$ by a separate loss:
$L_{track} = \sum\limits_{m=1}^{M_t} \cfrac{|D_m - \hat{D}_m|_1}{\sqrt{\hat{S}_D}} + \lambda_t |I_m - \hat{I}_m|_1,$
where $\hat{S}_D$ is the depth variance along the ray, and $λ_t$ adjusts the weight of the color term.
Experiments
For datasets, Replica, TUM-RGBD, and ScanNet datasets are used. For evaluation, different types of metrics are used. For mesh quality, F-score is used. For depth accuracy, depth L1 is used. For tracking, ATE RMSE is used. For rendering quality, PSNR, SSIM, LPIPS are used. Baseline methods are NICE-SLAM, Vox-Fusion, and E-SLAM.
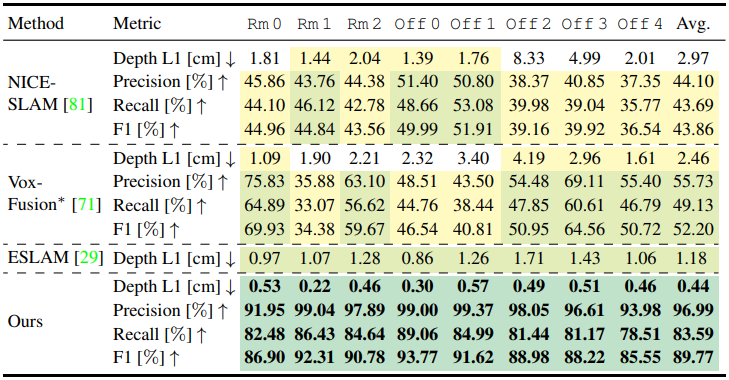
The table above shows the geometric reconstruction accuracy. Point-SLAM outperforms outperform all methods on all metrics.
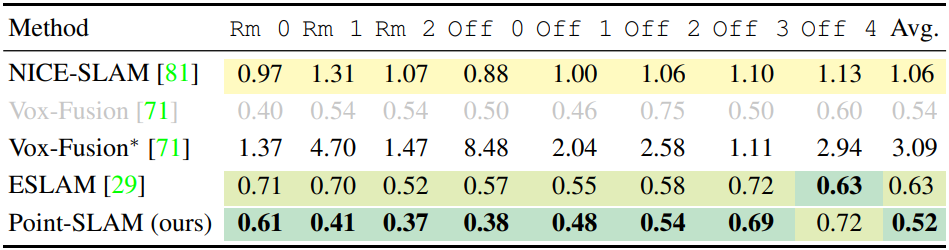
On average, Point-SLAM outperform the existing methods. Nevertheless, there is still a gap to traditional methods which employ more sophisticated tracking schemes including loop closures when evaluated on the TUM-RGBD dataset.
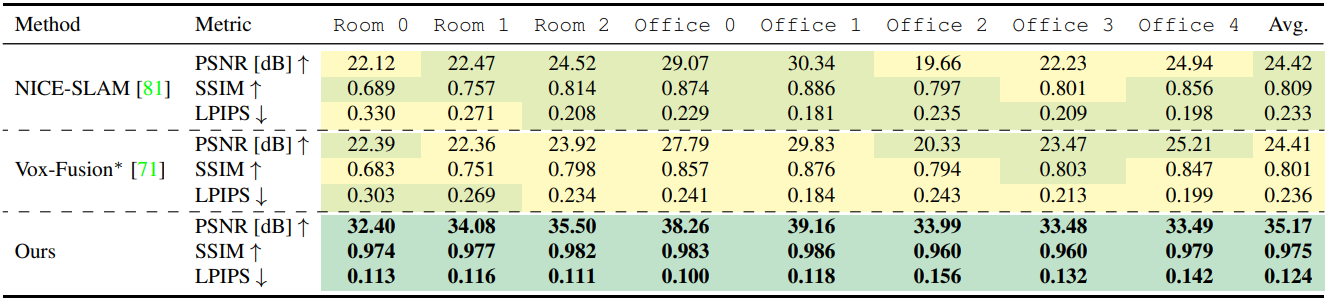
Point-SLAM yields more accurate details than the baselines.
Conclusion
Point-SLAM is a dense SLAM system that uses a neural point cloud for mapping and tracking. By anchoring features to actual surface locations, Point-SLAM efficiently balances memory and computation, resulting in a more accurate 3D scene representation. Point-SLAM significantly improves reconstruction and rendering accuracy while remaining competitive in tracking performance, runtime, and memory usage compared to state-of-the-art methods.
Robustness against depth noise could be enhanced by allowing on-the-fly optimization of point locations. Also, our heuristic-based local density adaptation and several hyperparameters could benefit from adaptive learning. Additionally, our system is sensitive to motion blur and specularities.