Introduction
본 논문은 equirect 이미지를 트랜스포머에서 다루는 방법을 종합적으로 설명한다.
기존 핀홀 이미지로 학습된 모델은 equirect 이미지에 적용하기 적합하지 않다. 특히, equirect 이미지는 좌우 양 끝이 이어져 있는데, 이는 핀홀 모델로 표현 불가능하다. 또한 equirect 이미지의 특성으로 인해 기존 트랜스포머 아키텍쳐와 positional encoding 방식도 달라져야 한다.
PanoSwin은 equirect 이미지에 특화된 트랜스포머로, contribution은 아래와 같다.
- Pano-style 윈도우 attention 제안
- 좌우 양 끝의 연결성을 유지한 positional encoding
- 핀홀 이미지로 먼저 학습 후 knowledge distillation 가능
Related Work
Vision Transformer
지금까지 다양한 ViT 구조가 제안되었지만, 핀홀 기반 ViT는 파노라마 구조를 반영하기 어렵다.
Panorama Representation Learning
초기에는 구면에서 CNN 기반으로 모델을 구축하였다(e.g. S2CNN, SpherePHD). 최근에는 파노라마를 위한 transformer 시도가 존재한다(e.g. PanoFormer).
Method
Preliminaries of Swin Transformer
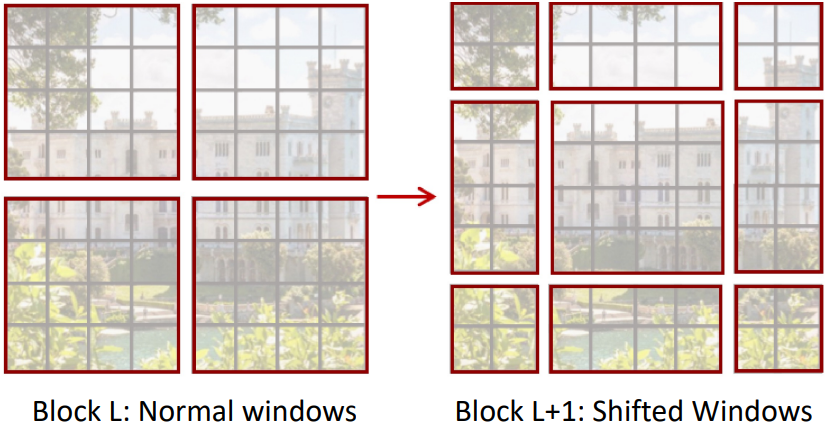
Window attention은 Swin Transformer에서 새롭게 도입한 개념이다.
- 각 window 안에서만 self-attention 수행
- Layer별로 window의 위치를 shift
- 피라미드 구조 $\rightarrow$ layer가 깊어질수록 window를 합쳐서 size 감소, 채널 수 증가
Pano-style Shift Windowing Scheme
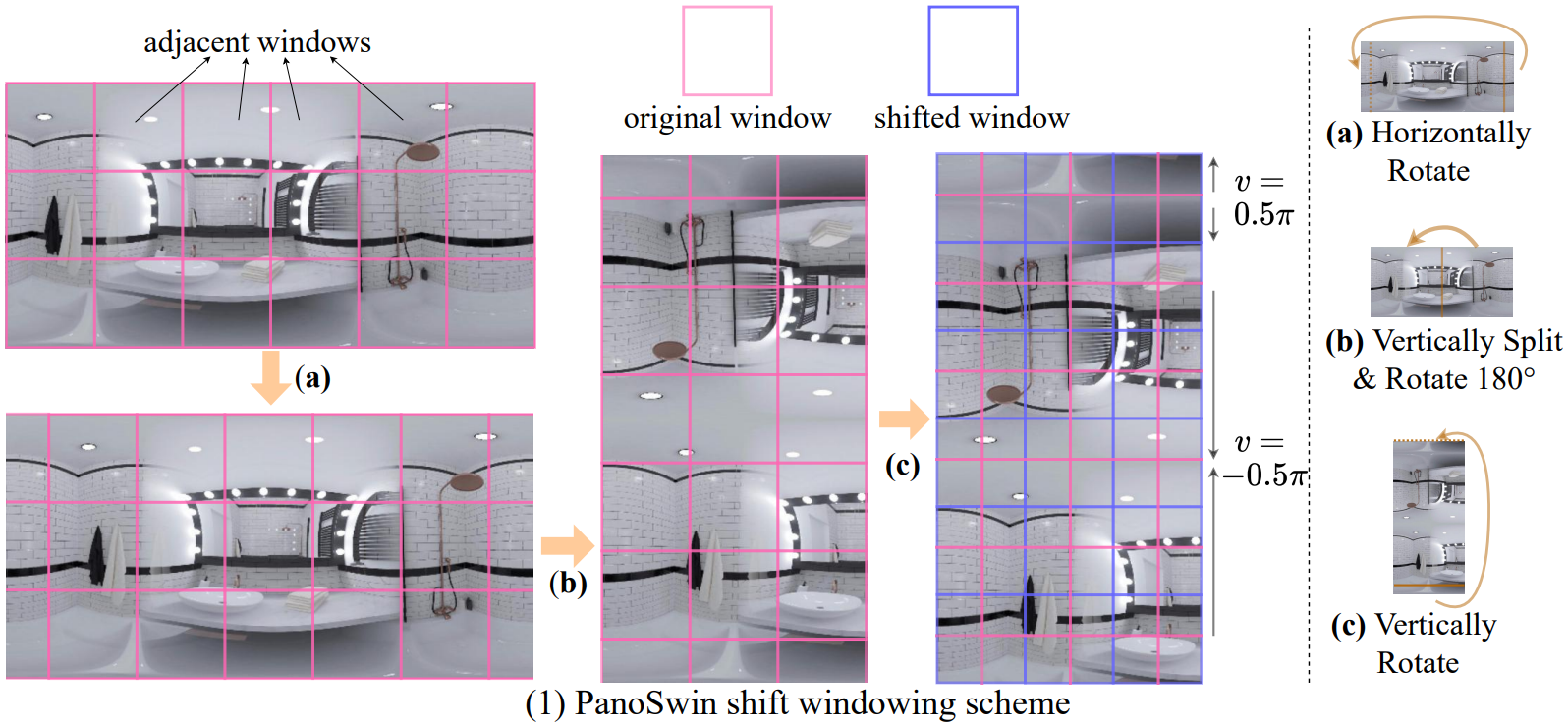
- 파노라마 이미지는 왼쪽/오른쪽이 연결됨
- Window가 수평/수직 경계를 넘어가면 반대쪽 window와 연결되도록 설정
- 옮긴 window 내부에서 attention 수행
Panoramic Rotation
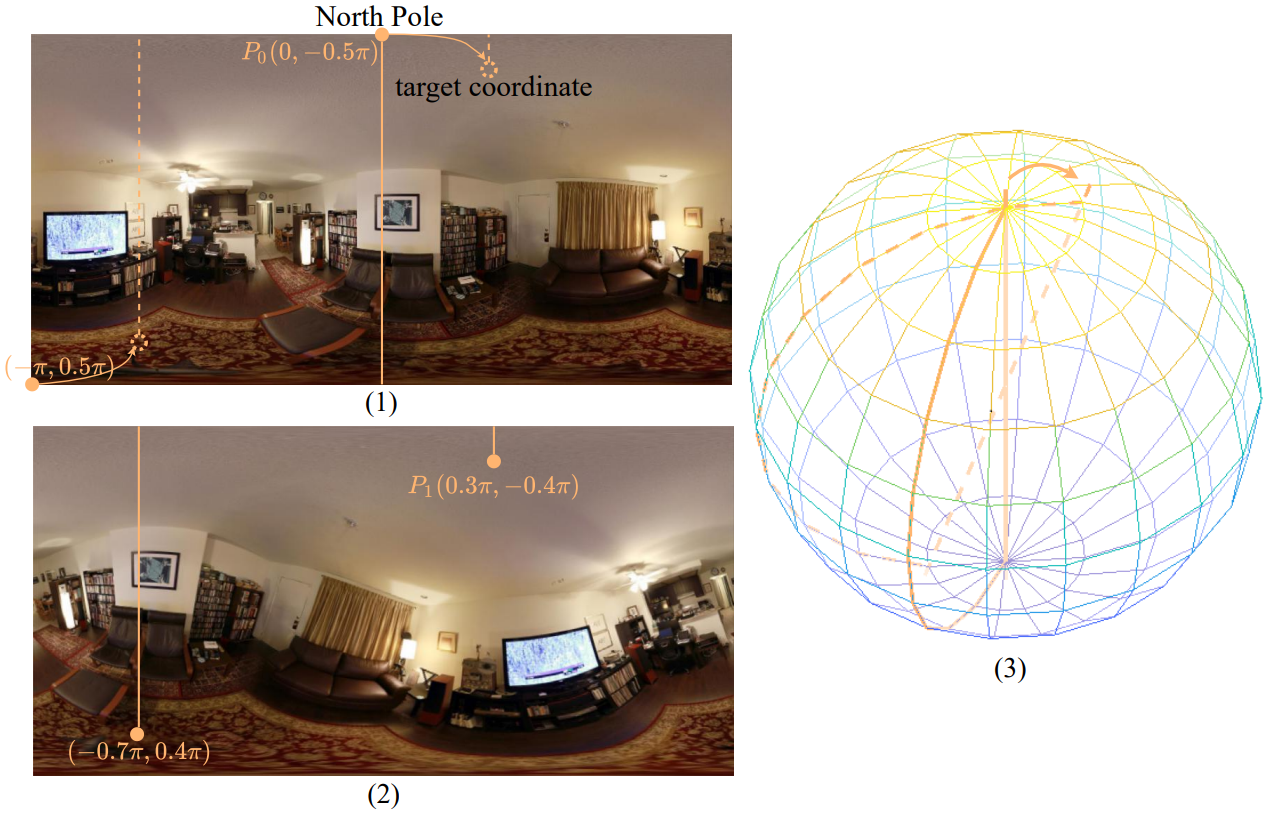
Data augmentation에 사용되는 방식으로, equirect 이미지의 north pole을 옮김으로써 발생하는 이미지의 왜곡을 모델링한다.
Pitch Attention Module
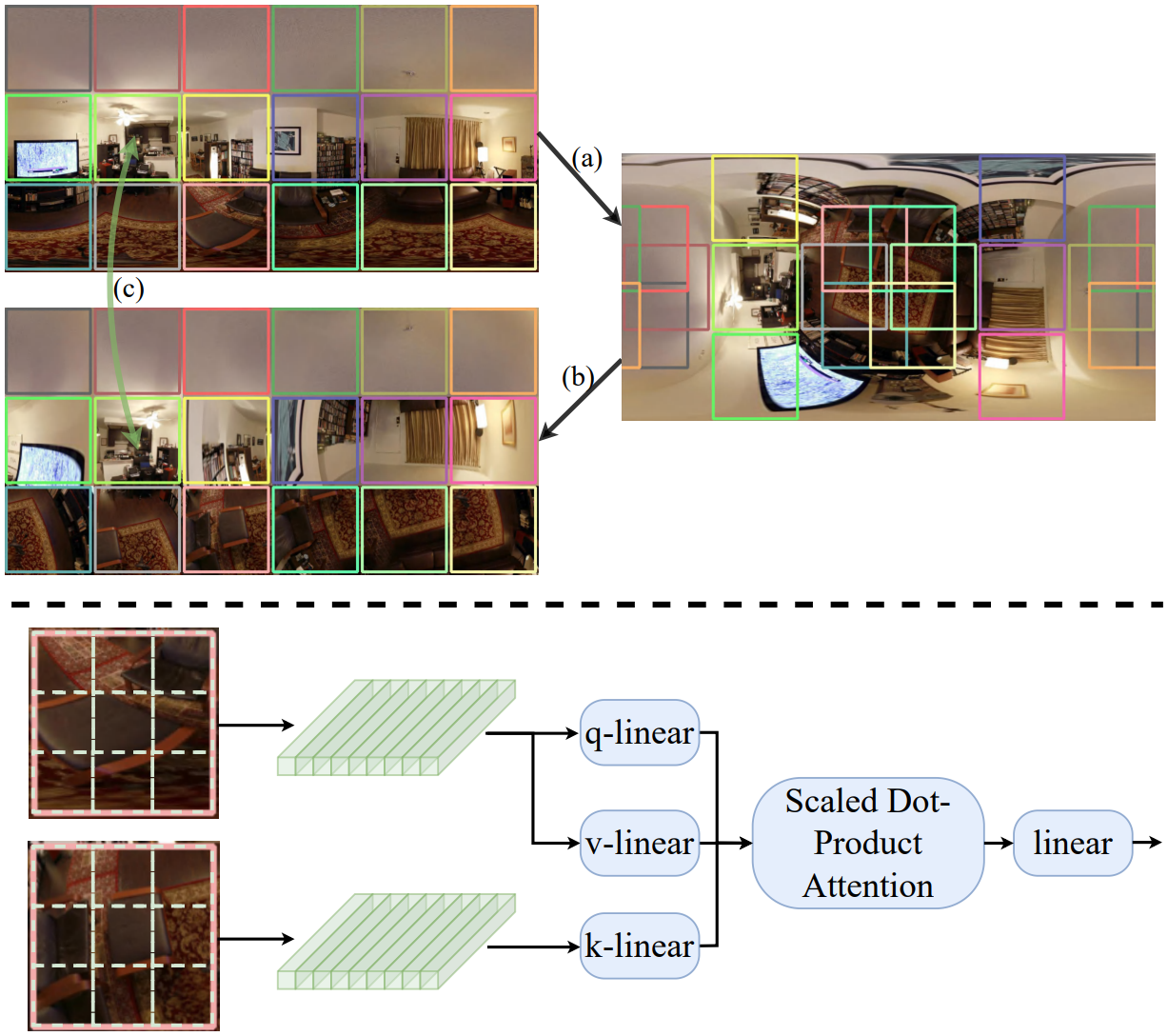
North/south pole 부분의 왜곡을 완화하는 모듈이다. 왜곡이 심한 영역을 회전시켜 덜 왜곡된 시야에서 다시 보게 만든다. 아래의 3단계로 구성되어 있다.
- 90도 아래를 보도록 회전 (Panoramic Rotation 공식 이용)
- 원래 이미지에서의 window 중심점을 회전시킨 이미지로 projection하고, 새롭게 window 설정
- 기존 window들과 새로운 window들 간 cross-attention
Pano-style Positional Encodings
각 window의 절대적 위치와 window간 상대적 위치를 모두 활용한다. APE로는 직교좌표계 및 구면좌표계 좌표를 모두 활용한다. 좌표값을 MLP에 통과시켜 얻은 벡터를 각 window의 embedding에 더해 준다.
RPE로는 구면 거리인 great-circle distance를 활용한다.
Two-Stage Learning Paradigm
최종 아키텍쳐는 아래와 같다.

(W: 기본 window attention, PSW: pano shift attention, PA: pitch attention, PM: patch merging)
학습은 planar stage와 panoramic stage의 두 단계로 나뉘어 이루어진다.
Planar stage: 핀홀 모델처럼 학습
Equirect 이미지를 핀홀 이미지로 간주하고 downstream task에 대해 학습한다. Pitch attention을 기본 cross attention으로 대체하고 구면좌표계에서의 positional encoding 모두 disable한다. Equirect 이미지의 중심 부분은 왜곡이 적으므로 그 정보를 학습하는 것이 목적이다.
Panoramic Stage: Equirect 이미지로 distillation
앞서 학습한 모델을 teacher로 삼아 equirect 이미지를 처리할 수 있도록 학습한다. Pitch attention 및 positional encoding 모두 enable한다. 이 단계에서는 KP loss를 도입하는데, 중앙 영역은 teacher를 따라가고, 주변 영역은 panorama-aware하게 fine-tuning하는 역할을 한다.
KP loss의 식은 아래와 같다.
$\mathcal{L}_{KP} = \cfrac{1}{\sum\limits_{i}^{N} w_i} \sum\limits_{i}^{N} w_i \left\| A(\mathcal{S}(x))^{(i)} - \mathcal{T}_s(x)^{(i)} \right\|_2^2$
$w_i = \cos^2(v_i) \cos^2\left( \cfrac{1}{2} u_i \right)$
Experiments
Main Results
Panoramic classification과 panoramic object detection 태스크에 대한 성능을 평가하였다.
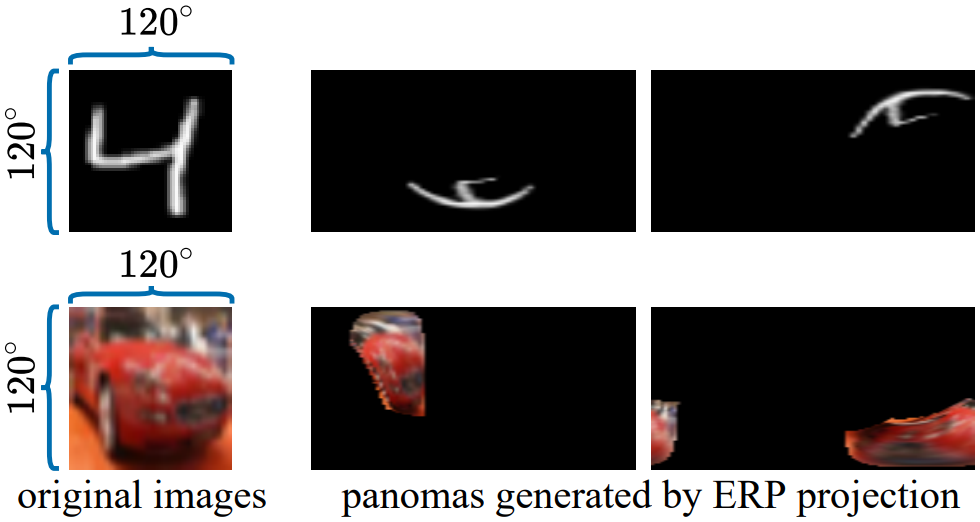
Panoramic classification 태스크로는 위 그림과 같이 MNIST와 CIFAR10 데이터셋을 equirect로 projection한 SPH-MNIST와 SPH-CIFAR10을 사용하였다.
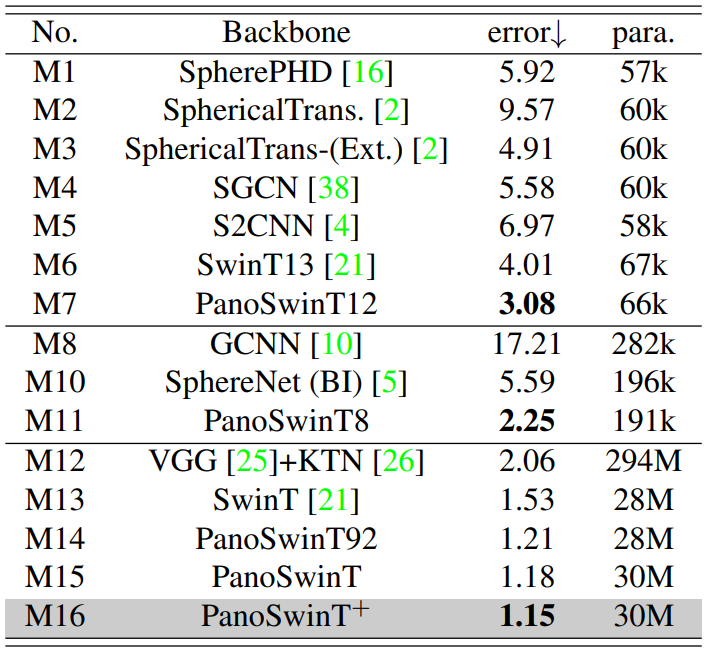
SPH-MNIST 결과는 위의 표와 같다.
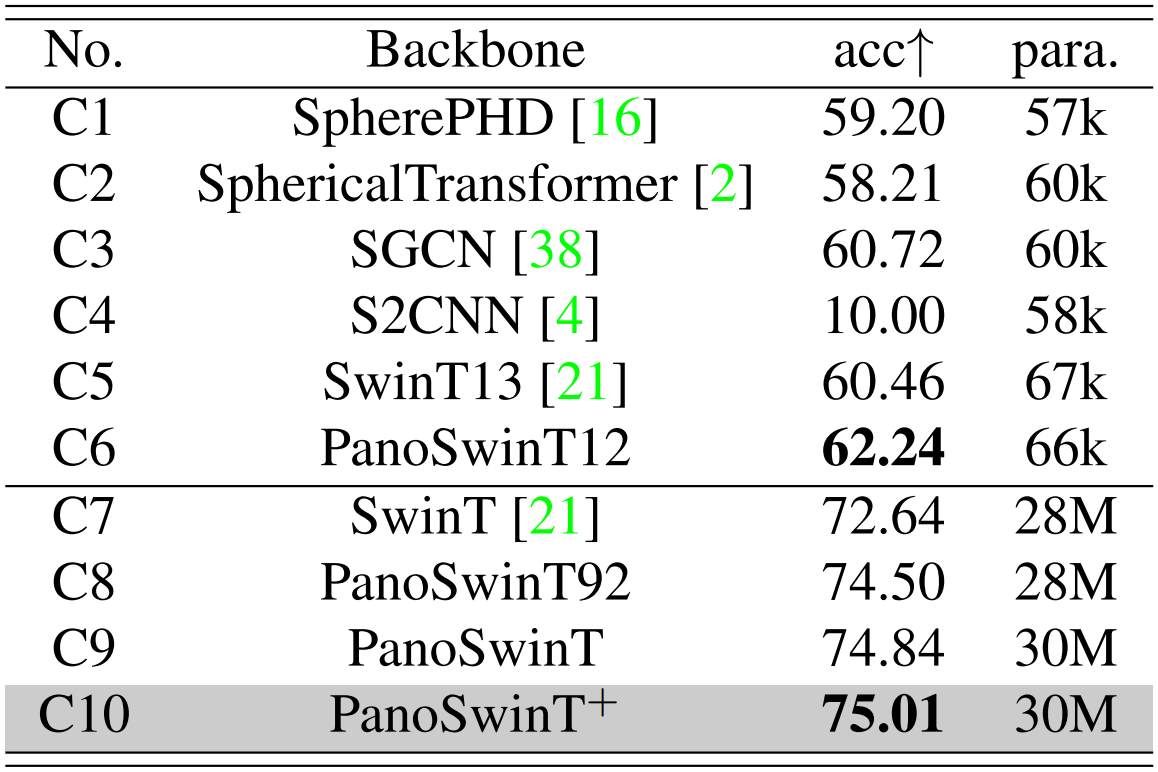
SPH-CIFAR10 결과는 위의 표와 같다.
Panoramic object detection 태스크로는 360-Indoor와 StreetView 데이터셋을 사용하였다.
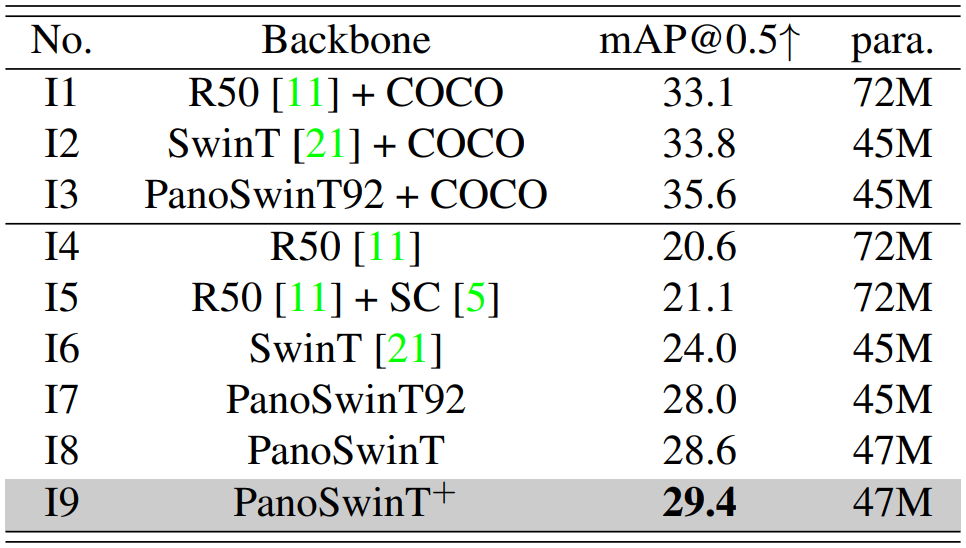
StreetView 결과는 위의 표와 같다.
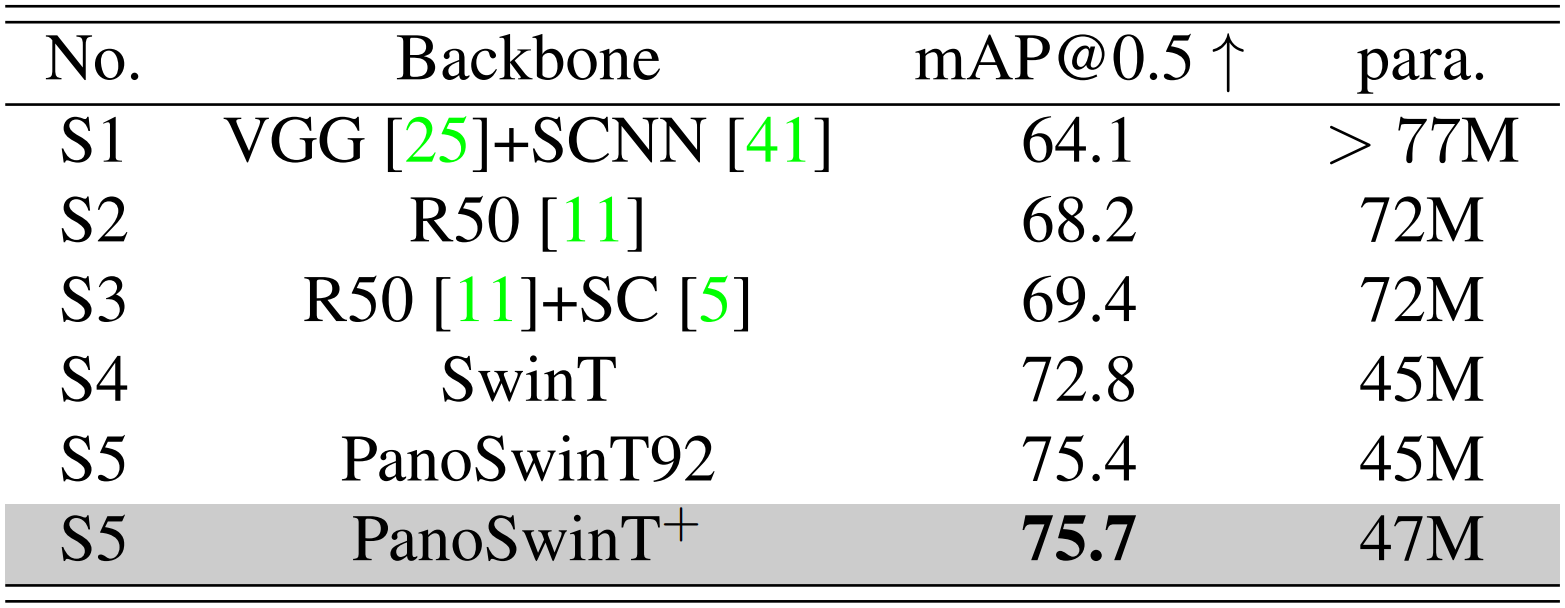
또한 object detection 태스크에서 물체가 저위도에 있을 때와 고위도에 있을 때의 정확도를 비교하였는데, 기본 ResNet50이 5.8%의 mAP@50 값 차이를 보인 것에 반해 PanoSwin 모델은 1.9%밖에 차이가 나지 않았다.
Ablation Study
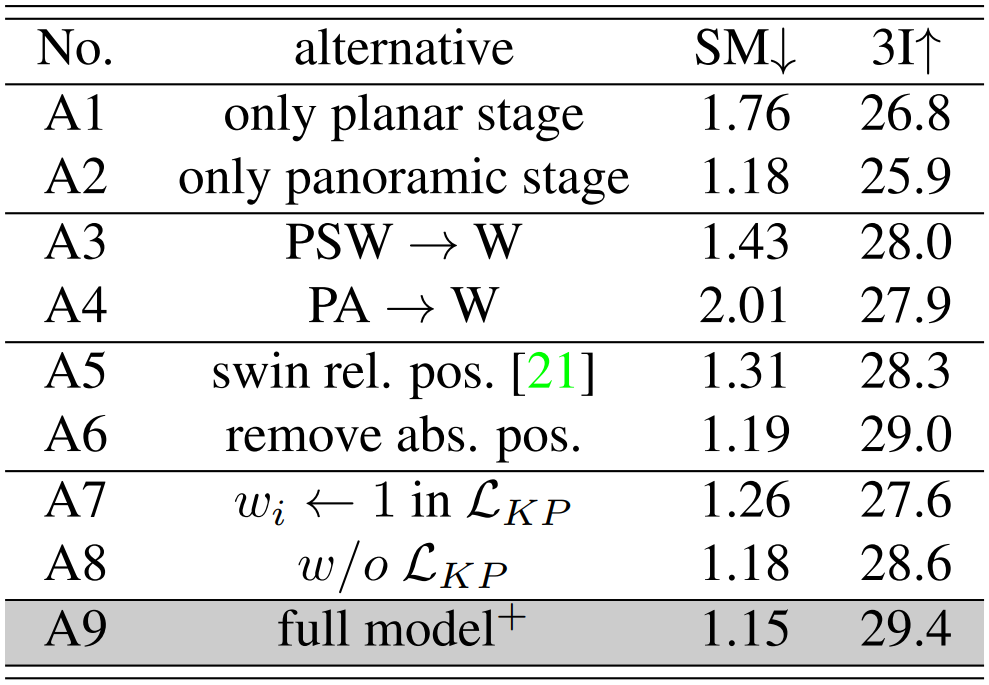
Ablation study 결과는 위와 같다. 각각의 모듈이 미치는 영향이 그렇게 크지 않지만, 2-stage learning 방식은 그나마 효과가 있다고 볼 수 있다.
Conclusion
PanoSwin은 equirect image에서 feature를 학습하고 다양한 태스크를 수행할 수 있도록 하는 새로운 트랜스포머 기반 모델이다. Pano-style shift windowing을 통해 불연속적인 이미지 경계면에서의 픽셀들을 연속적으로 다루었고, pitch attention을 통해 equirect image에서의 고위도 부분 distortion 문제를 해결하였다. 또한 KP-loss를 활용한 2-stage learning을 이용해 pinhole image로 얻은 지식을 distillation한다.
이와 같은 새로운 attention 방식이나 positional encoding 등 기본적인 아이디어들을 참고할 만하다고 생각한다. 또한 inference time은 1초 내외로 준수한 속도를 보인다.