Introduction
3D Gaussian Splatting을 활용한 3D semantic segmentation은 최근 많은 관심을 받고 있는 주제이다. 하지만 기존의 방법들은 각각의 scene에 대해 별개로 학습해야 하기 때문에 novel scene에서는 작동할 수 없다는 한계가 있다.
OVGaussian은 어떤 scene에서든 추가 학습 없이 바로 작동할 수 있는 segmentation network이다. 학습이 완료된 3D gaussian을 입력으로 받아 mask를 예측하기 때문에 완전히 새로운 scene에 대해서도 task를 수행할 수 있다. 또한 semantic을 2D image로부터 얻을 수밖에 없었던 기존 모델과는 달리, OVGaussian은 3D gaussian 정보로부터 직접 3D semantic을 얻는다. 이를 통해 더욱 풍부한 정보를 추출할 수 있다. 마지막으로 Text와 2D image, 3D gaussian이라는 3가지 multi-modal 데이터를 하나로 통합하여 다룰 수 있는 통일된 framework를 가진 덕분에 결과의 품질을 높일 수 있다.
이러한 OVGaussian 모델을 학습하기 위해 본 논문에서는 288개의 3DGS scene으로 이루어진 데이터셋 SegGaussian을 구축하였다.
Methodology
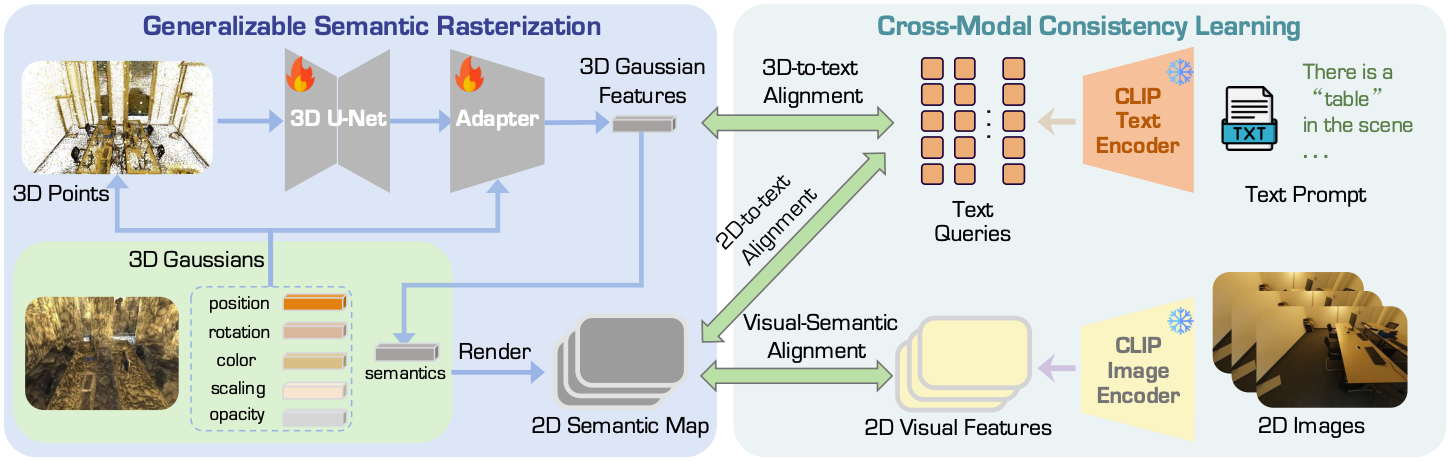
OVGaussian은 가우시안을 넣으면 각 가우시안에 대한 semantic이 출력되는 모델로, Generalizable Semantic Rasterization (GSR)과 Cross-modal Consistency Learning (CCL)으로 구성된다. GSR은 3D gaussian을 받아 semantic을 예측하는 네트워크에 해당하고, CCL은 GSR을 학습하기 위한 방법론이다.
Preliminary of 3D Gaussian Splatting
3D Gaussian Splatting은 3차원 scene을 수많은 3차원 가우시안 분포의 집합으로 표현할 수 있는 새로운 3D reconstruction 및 rendering 방법이다. 각 가우시안 분포는 아래의 식으로 표현된다.
$G(p; \Sigma) = \exp\left(-\cfrac{1}{2}(p - \mu)^\top \Sigma^{-1} (p - \mu)\right)$
$p = (x, y, z)$는 중심점의 위치, $\Sigma$는 분포의 모양과 방향을 결정하는 공분산 행렬이다. 이 외에도 가우시안의 색깔 $c = (r, g, b)$와 투명도 $\alpha$ 파라미터가 존재한다.
Generalizable Semantic Rasterization (GSR)
GSR은 3D gaussian을 받아 각각에 대한 semantic을 출력하는 모델로, voxelization, sparse 3D feature extraction, voxel-to-point adapter의 3단계로 구성된다.
먼저, 특정 scene의 모든 3D gaussian들의 집합을 $G = \{g_i\}_{i=1}^N$라 하자. 이때 $g_i$는 $i$번째 가우시안의 파라미터 (position, covariance, color 등)에 해당한다.
Voxelization 단계에서는 먼저 각각의 가우시안을 그 중심점으로 이루어진 point cloud로 변환한다. 이후 공간을 voxel로 쪼개고, 각 voxel 안에 속한 가우시안의 파라미터들을 조합하여 voxel마다의 feature를 생성한다.
Sparse 3D feature extraction 단계에서는 3D U-Net에 전체 voxelized space를 넣어 각 voxel별 feature vector $\{f_{\text{voxel}}(v_j)\}_{j=1}^{|V|}$를 출력한다. 입력으로 넣어 준 voxel feature와는 달리, 출력 feature map은 각 voxel끼리의 interaction을 거친 후에 나온 결과이다. 이때 $V$는 전체 voxel의 집합, $v_i$는 $i$번째 voxel을 의미한다.
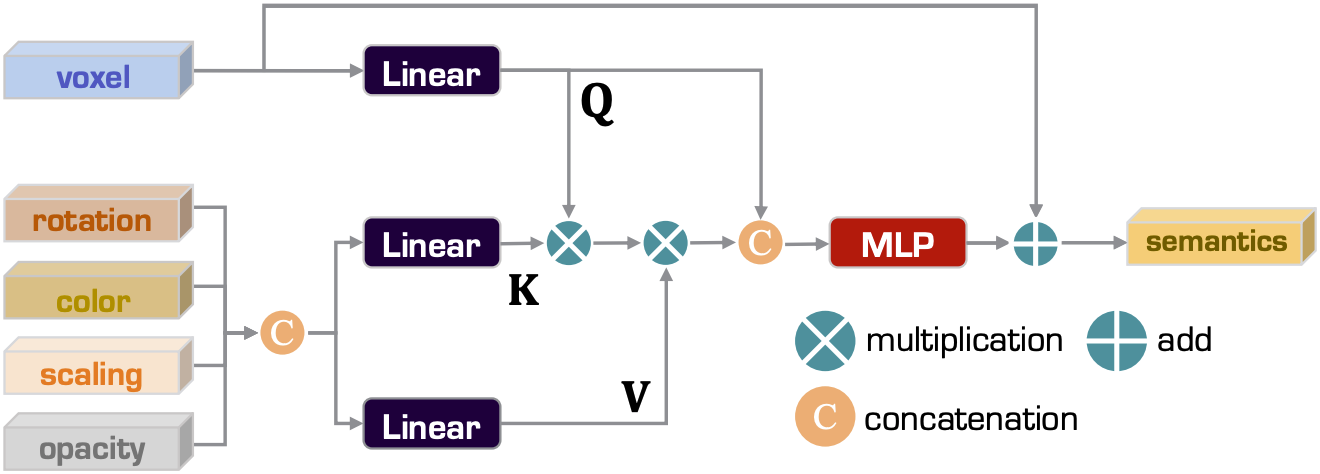
Voxel-to-point adapter는 앞 단계에서 출력된 voxel feature를 voxel에 포함된 각 가우시안에 할당해주는 단계이다. 위 사진과 같은 attention layer의 형태를 띠고 있는데, voxel feature가 query, 각 가우시안의 파라미터가 key와 value가 되는 방식이다.
$\begin{align*} m_i &= \text{MHSA}(\mathbf{Q}(T_p(f_{\text{voxel}}(v_j))), \mathbf{K}(T_p(g_i)), \mathbf{V}(T_p(g_i))) \\ s_i &= \text{MLP}(\text{Concat}(m_i, T_p(f_{\text{voxel}}(v_j))) + T_p(f_{\text{voxel}}(v_j))) \end{align*}$
즉, 각 가우시안이 속한 voxel의 feature와 그 가우시안 자체의 파라미터를 모두 고려하여 semantic feature를 생성한다고 볼 수 있다. 하지만 이 아키텍쳐 자체의 설계에 대해서는 설명이 부족한 면이 있다.
이렇게 생성된 가우시안별 feature는 RGB color와 마찬가지로 2D image로 렌더링될 수 있다. Color rendering과 같은 수식을 사용한다.
Cross-modal Consistency Learning (CCL)
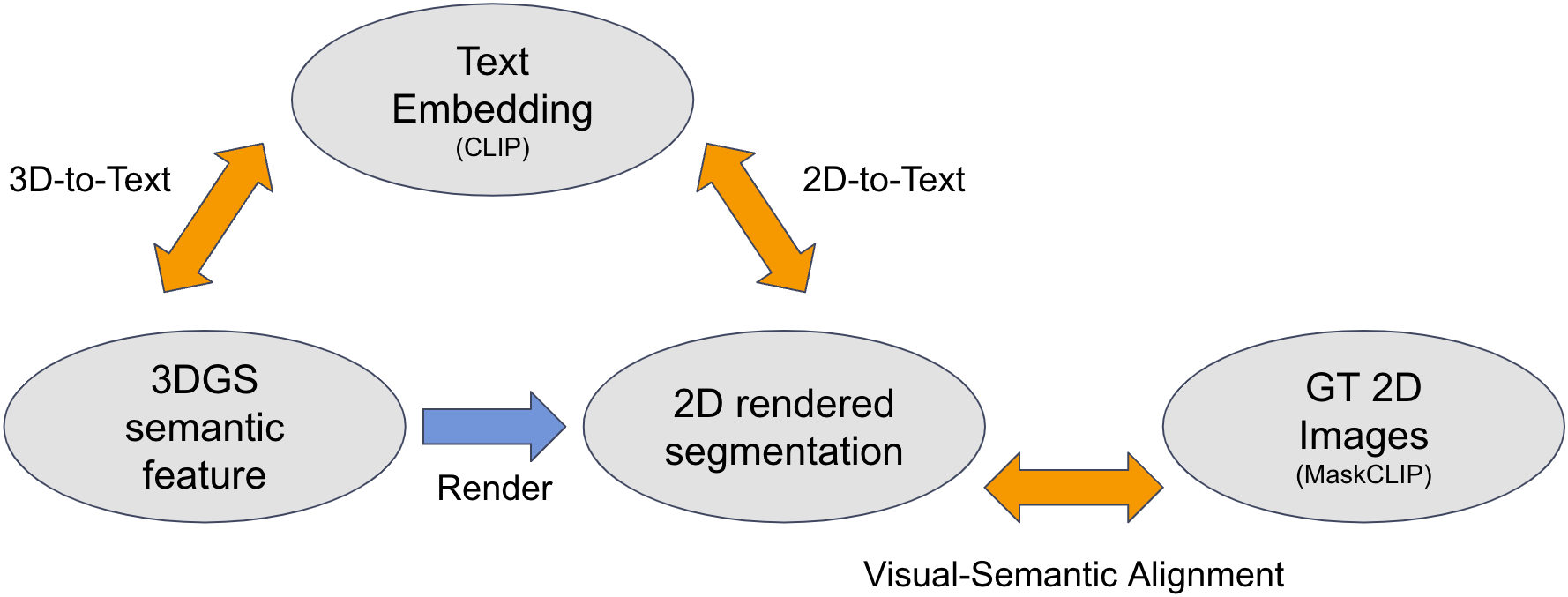
CCL은 GSR을 학습하기 위한 방법론으로, text embedding, 렌더링된 2D semantic image, 그리고 3D gaussian들의 semantic vector들을 서로 비교한다. 각 modality간의 distance function을 loss로 사용하여 일관된 feature가 학습될 수 있도록 한다. 위의 다이어그램은 논문의 figure를 조금 더 단순하게 직접 표현한 것이다.
우선 각 modality에 대해 살펴보자. Text embedding은 각 object의 label에 해당한다. 각 text를 CLIP을 이용하여 embedding space로 projection한다. 3DGS semantic feature는 GSR을 통해 얻은 각 가우시안별 feature vector이고, 2D rendered segmentation은 위에 언급한 대로 기존의 렌더링 방식을 이용해 semantic feature를 2D image로 렌더링한 것이다.
각각의 distance function에 대해 살펴보자. 우선 3D-to-text 부분의 수식은 아래와 같다.
$\mathcal{L}_{\text{semantic, 3D}} = - \sum\limits_{i=1}^{N} \log \cfrac{\exp(e_{\gamma_i}^\top \phi(s_i))}{\sum\limits_{m=1}^{M} \exp(e_m^\top \phi(s_i))}$
Cross-entropy loss를 이용하여 text embedding 벡터와 gaussian feature를 비교하고 있는 것을 알 수 있다. Cross-entropy loss를 이용해 classification을 할 때는 one-hot vector와의 차이를 계산하지만, open-vocabulary 상황에서 단순히 두 벡터 사이의 차이를 계산하는 데에도 사용할 수 있다. $e$는 text embedding, $\phi(s_i)$는 가우시안의 feature를 decoder network에 통과시킨 것을 의미한다.
$\mathcal{L}_{\text{semantic, 2D}} = - \sum\limits_{(x, y) \in P} \log \cfrac{\exp(e_{\gamma(x, y)}^\top \phi(\mathcal{M}(x, y)))}{\sum\limits_{m=1}^{M} \exp(e_m^\top \phi(\mathcal{M}(x, y)))}$
다음으로 2D-to-text 부분을 살펴보자. 3D-to-text와 마찬가지로 cross-entropy loss를 사용한다. $\mathcal{M}(x, y)$는 2D image상의 픽셀 좌표 $(x, y)$에서 렌더링된 2D feature vector를 의미한다. 이 feature를 동일한 decoder network $\phi$에 통과시킨 후 text embeddinig $e$와 비교한다.
$\mathcal{L}_{\text{semantic, 3D}}$와 $\mathcal{L}_{\text{semantic, 2D}}$를 통해 가우시안의 feature vector가 text embedding과 유사해질 수 있도록 학습한다.
마지막 부분은 visual-semantic alignment이다. 이 부분은 2D로 렌더링된 가우시안 feature가 GT image를 2D VLM으로 segmentation한 결과와 유사해지도록 학습하는 부분이다. Open vocabulary 상황에서 segmentation signal을 줄 수 있는 방법이 2D VLM을 통한 방법밖에 없기 때문에 이러한 구조를 선택한 것으로 보인다. OVGaussian은 2D VLM 모델로 MaskCLIP을 사용한다.
$\mathcal{L}_{\text{cosine}} = - \cfrac{1}{|P|} \sum\limits_{(x, y) \in P} \cfrac{S(x, y) \cdot \psi(\mathcal{M}(x, y))}{\|S(x, y)\| \|\psi(\mathcal{M}(x, y))\|}$
둘 사이의 loss로는 cosine similarity를 사용한다. $S(x, y)$는 픽셀 $(x, y)$에서의 MaskCLIP의 feature, $\psi$는 렌더링된 2D feature $\mathcal{M}(x, y)$을 받는 decoder network이다. 이러한 과정을 통해 모델이 open-vocabulary semantic을 학습할 수 있다.
최종 loss 함수는 $\mathcal{L} = \mathcal{L}_{\text{semantic, 3D}} + \mathcal{L}_{\text{semantic, 2D}} + \mathcal{L}_{\text{cosine}}$으로 정의된다. 학습 시에는 GSR과 CCL의 요소들을 동시에 학습한다.
Experiments
SegGaussian Dataset

본 논문에서는 OVGaussian을 학습하기 위한 데이터셋으로 SegGaussian이라는 데이터셋을 제시하였다. SegGaussian은 ScanNet++와 Replica 데이터셋에서 각각 280개와 8개의 scene을 가져와 annotation을 진행한 것이다. Point cloud와 2D image 모두에서 semantic, instance annotation을 수행하였다.
Experimental Setup
Baseline으로는 OpenScene, CLIP2Scene, LangSplat, Gaussian Grouping을 선정하였다.
Evaluation metric으로는 아래의 네 가지 항목을 선정하였다.
- Cross-scene Accuracy (CSA): Test scene의 모든 object에 대해 segmentation accuracy를 비교한다.
- Open-vocabulary Accuracy (OVA): Training 시 보여지지 않은 object에 대해 segmentation accuracy를 비교한다.
- Novel View Accuracy (NVA): Training 시 사용되지 않은 카메라 시점에 대해 segmentation accuracy를 비교한다.
- Cross-Domain Accuracy (CDA): ScanNet++ scene들로 training을 진행하고 Replica scene들로 segmentation accuracy를 비교한다.
Quantitative Results
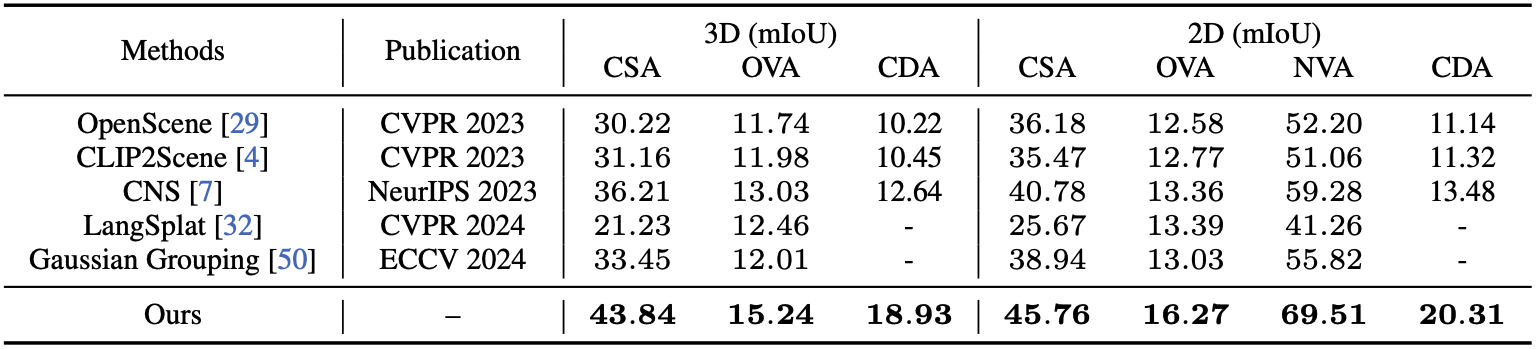
표를 보면 OVGaussian의 mIoU 값이 다른 모델들보다 뛰어난 것을 볼 수 있다.
Qualitative Results

각각의 사물을 어느 정도 잘 segmentation하는 것을 볼 수 있다.
Ablation Studies

mIoU 값의 변화를 볼 때 3D-to-text의 영향이 비교적 큰 것을 볼 수 있다.
Conclusions
OVGaussian은 scene에 국한되지 않고 3DGS를 open-vocabulary segmentation할 수 있는 모델이다. 다만 scene에 국한되지 않기 위해 수많은 scene에 대한 annotated 3DGS dataset이 필요했는데, 이를 SegGaussian이라는 새로운 데이터셋을 통해 해결했다. 3DGS를 직접 뉴럴 네트워크에 입력한다는 점에서 신선한 면이 있지만 전반적인 아키텍쳐나 실험 과정에 대한 설명이 조금 부족하다는 느낌을 받았다.