Introduction
기존 3DGS segmentation 모델들은 2D pixel level에서의 동작에 집중했기 때문에 feature expressiveness가 낮고 2D-3D feature association이 부정확하다. 특히 고차원 CLIP feature를 저차원으로 projection하는 경우 feature의 성능이 낮아질 수밖에 없으며, feature vector를 먼저 렌더링한 후 2D에서 GT와 비교하는 경우 2D 픽셀과 3D 가우시안 간 1대1 대응 관계를 수립하기 어렵다.
이러한 이유로 인해 실제 기존 모델들은 occlude된 물체를 잘 인식하지 못하는 문제가 있다고 한다.
OpenGaussian은 3D point level instance feature를 학습하고 two-stage codebook을 활용함으로써 이 문제를 해결하였다.
Method

3D Consistency-Preserving Instance Feature Learning
OpenGaussian은 먼저 각 가우시안에 6차원 feature를 할당하면서 시작한다. 이 feature는 이후 클러스터링 단계에 사용되는 값으로, semantic 정보는 들어 있지 않고 단순히 같은 물체에 속하는 가우시안의 feature는 가까워지고 다른 물체에 속하는 가우시안끼리는 멀어지도록 contrastive learning 방식으로 학습된다.
우선 feature를 2D로 렌더링하고, GT RGB 이미지에서는 SAM mask를 구한다. 마스크 내부에서는 각 픽셀로 렌더링된 각각의 feature가 그 마스크에 속한 픽셀의 feature의 평균값에 가까워지도록 학습된다. 서로 다른 마스크끼리는 feature의 평균값이 서로 멀어지도록 학습된다.
이러한 과정을 multi-view에서 진행하여 3D 상에서 같은 물체에 속하는 가우시안끼리는 유사한 feature를 가지도록 학습된다.
여기서도 2D로 렌더링하고 SAM 마스크를 사용하긴 하지만, semantic 정보를 주입하지는 않는다. 즉 LangSplat 등이 2D로 렌더링하여 CLIP 등 semantic 정보를 학습하는 것과는 다르다.
Two-Level Codebook for Discretization
이렇게 학습한 feature를 그대로 이용해도 되지만, text query를 넣어 inference를 할 때는 threshold를 직접 설정해야 하며, 2D로 렌더링할 때는 alpha-blending으로 인해 feature 값이 희석될 우려가 있다.
이를 위해 가우시안으로 클러스터링을 하는 개념인 codebook을 도입하여 앞에서 학습한 6차원 feature가 각 클러스터 안에서는 완전히 같아지도록 한다.
클러스터링은 k-means clustering과 유사한 방식을 사용하는데, 본 논문에서는 coarse-to-fine 방식으로 두 단계로 나누어서 진행한다.
먼저 coarse level에서는 각 가우시안 중심점의 좌표와 6차원 feature를 concat한 벡터를 이용하여 k-means clustering을 진행한다. 이때 $k = 64$로 설정하였다.
이후 fine level cluster를 얻기 위해 coarse cluster 내부에서 다시 k-means clustering을 진행한다. 이때는 중심점의 좌표는 사용하지 않고 6차원 feature만을 사용한다. $k = 10$을 사용하였다.
클러스터링 후 각 클러스터에 속하는 가우시안의 6차원 feature는 전부 그 클러스터의 평균에 해당하는 값으로 대체한다.
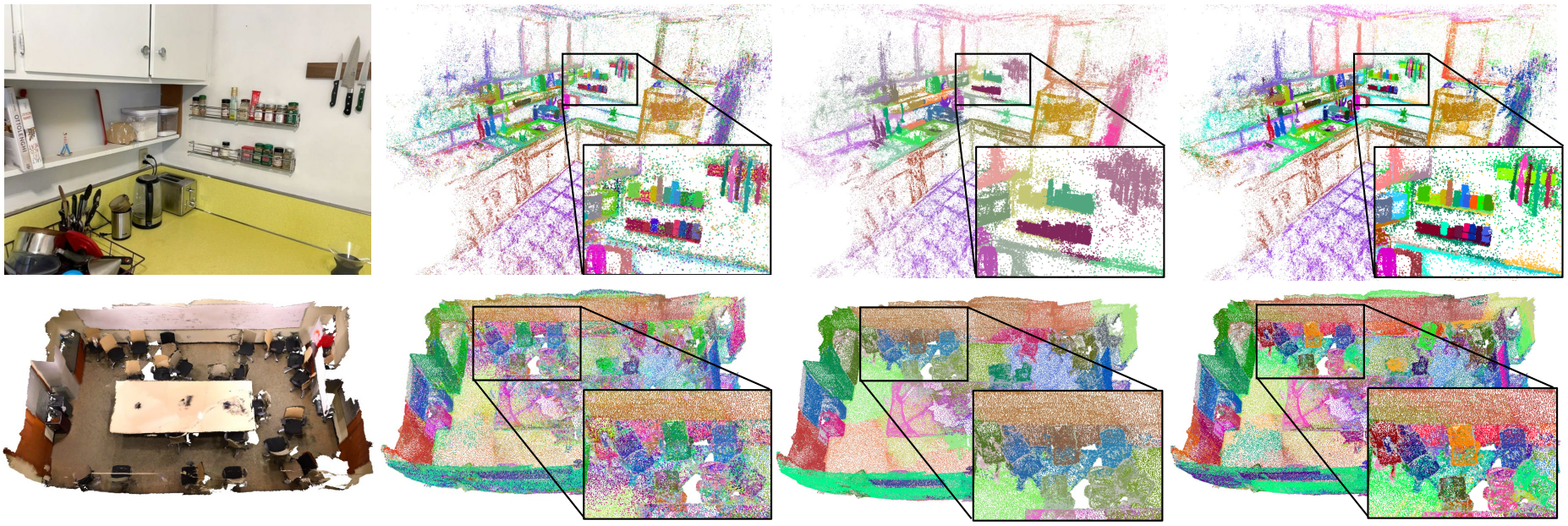
클러스터링 전, coarse level 클러스터링, fine level 클러스터링 결과는 각각 위와 같다.
Instance-Level 2D-3D Association without Depth Test
각 3DGS 클러스터와 2D 이미지로부터 얻은 CLIP feature를 association하는 과정이다. 우선 각각의 클러스터를 단독으로 2D로 렌더링한다. 이후 그 bbox와 가장 IoU가 높은 SAM mask를 찾는다.
그런데 그 view에서 occlusion이 발생할 경우 다른 물체에 해당하는 SAM mask와 IoU가 더 높게 나올 수도 있다. 따라서 IoU뿐만 아니라 전체 이미지를 렌더링했을 때 같은 SAM mask로 렌더링된 feature와의 유사도까지 비교한다.
최종적으로 IoU와 feature 유사도가 모두 높은 SAM mask에 해당하는 CLIP feature를 그 클러스터의 각 가우시안에 할당한다. Multi-view integration도 고려한다고 한다.
Experiments
Task 1: Open-Vocabulary Object Selection in 3D Space
Task: Open-vocab 텍스트가 주어질 때, 텍스트를 먼저 CLIP으로 변환하고 각 가우시안의 language feature와의 cosine similarity를 계산한다. 이후 유사도가 가장 높은 가우시안들만을 렌더링한다.
Baseline: LangSplat, LEGaussians와 성능을 비교하였다.
Dataset and Metrics: 데이터셋으로는 LERF-OVS를 사용하였고, metric으로는 average IoU와 acccuracy를 사용하였다.


실험 결과는 위 표 및 그림과 같다.
Task 2: Open-Vocabulary Point Cloud Understanding
Task: Open-vocab 텍스트가 여러 개 주어질 때, 각각의 가우시안이 어떤 텍스트와 가장 유사한지를 판단한다.
Baseline: LangSplat, LEGaussians와 성능을 비교하였다.
Dataset and Metrics: 데이터셋으로는 ScanNetV2를 사용하였고, metric으로는 average IoU와 acccuracy를 사용하였다. ScanNetV2에서 제공하는 point cloud를 그대로 이용하기 위해 학습 시 각 중심점의 좌표는 freeze했고 densification 또한 수행하지 않았다.
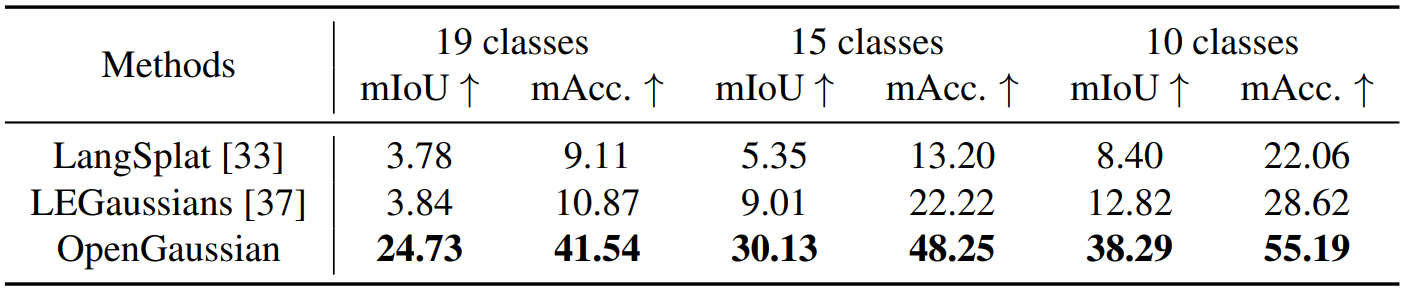

실험 결과는 위 표 및 그림과 같다. 텍스트가 총 19개, 15개, 10개일 때의 정확도를 각각 나타내었다.
Ablation Study
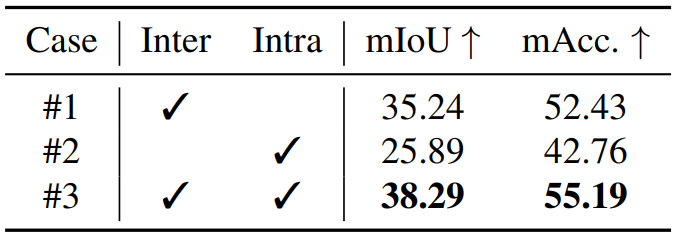
우선 각 가우시안의 feature를 처음 학습할 때 사용한 intra-mask loss와 inter-mask loss의 효과를 분석한다. Inter-mask loss의 영향이 더 큰 것을 볼 수 있다. 이는 하나의 가우시안이 여러 픽셀에 영향을 미치기 때문에 이미 각 마스크 내부에서는 smoothing 효과가 어느 정도 작용했기 때문이라고 해석할 수 있다.
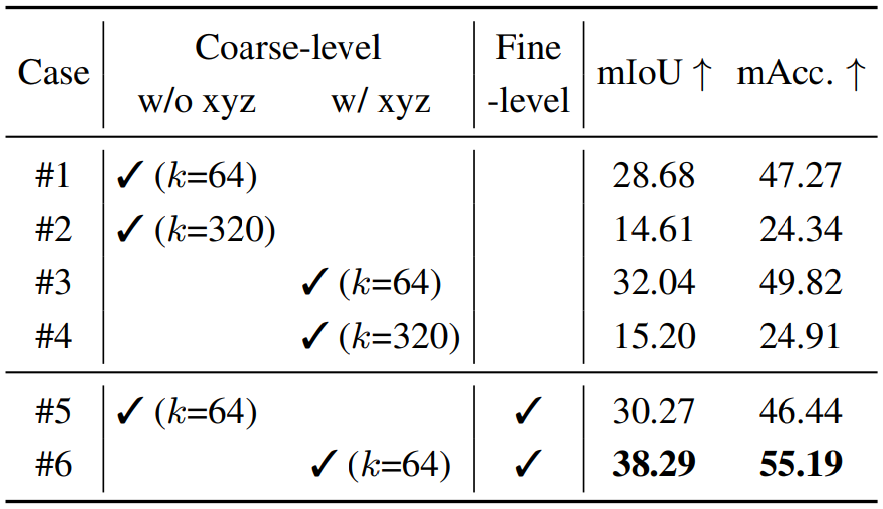
Codebook 생성 과정에서의 파라미터의 효과도 분석한다. 우선 coarse level만 사용할 경우는 coarse와 fine level을 모두 사용하는 경우에 비해 성능이 확연이 떨어진다. $k$의 값만 늘리는 것은 효과를 보지 못했다. 또한 coarse level에서 xyz 좌표값을 함께 사용하는 것이 효과가 있다는 것도 확인할 수 있다.
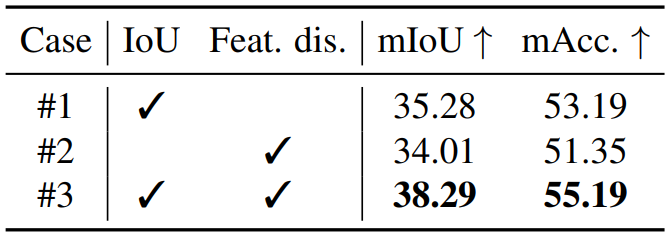
마지막으로 2D-3D association 과정에서 IoU와 feature distance를 사용하는 것의 효과를 분석한다. 둘 중 하나만 사용하더라도 어느 정도의 성능은 낼 수 있지만 둘 모두 사용했을 때 가장 성능이 좋은 것을 확인할 수 있다.
Conclusion
OpenGaussian은 codebook을 활용하여 3D point level에서 feature를 학습하고 open-vocabulary segmentation을 수행하는 모델이다. Limitation으로는 가우시안의 중심점, opacity, scale등이 고정된 채로 feature만 학습했다는 점, $k$의 값이 empirical하게 정해졌다는 점, 물체의 크기는 고려하지 않고 codebook을 생성했다는 점, static scene을 가정했다는 점이 있다.