Introduction
In order to make a SLAM system useful for real-world applications, the following properties are essential:
- Real-time performance
- Ability to predict unseen areas
- Scalability
- Robustness
However, traditional SLAM systems are unable to make plausible estimation for unobserved regions. On the other hand, learning-based SLAM systems lack scalability.
This paper found multi-level grid-based features can help to address the scalability issue. Therefore, this paper combines hierarchical scene representation with neural implicit representations to achieve the desired properties above.
The key idea is to represent the scene geometry and appearance with hierarchical feature grids and incorporate the inductive biases of neural implicit decoders pretrained at different spatial resolutions.
Related Work
Dense Visual SLAM
Traditional SLAM systems store occupancy or TSDF values in voxel grids. However, these representations cannot predict unseen areas. NICE-SLAM also adopts the voxel-grid representation, however, NICE-SLAM stores implicit latent codes of the geometry and directly optimize them.
Neural Implicit Representations
Neural implicit representations are good at predicting and representing object geometry and appearance. However, some assume given camera poses and others are not suitable for real-time applications. iMAP shares the same goal as NICE-SLAM, but they use single MLP to represent the entire scene, which causes the forgetting issue. DI-Fusion also uses a feature grid, but it contains holes and tracking is not robust. NICE-SLAM can handle large-scale scenes and is robust to challenging scenarios.
Method
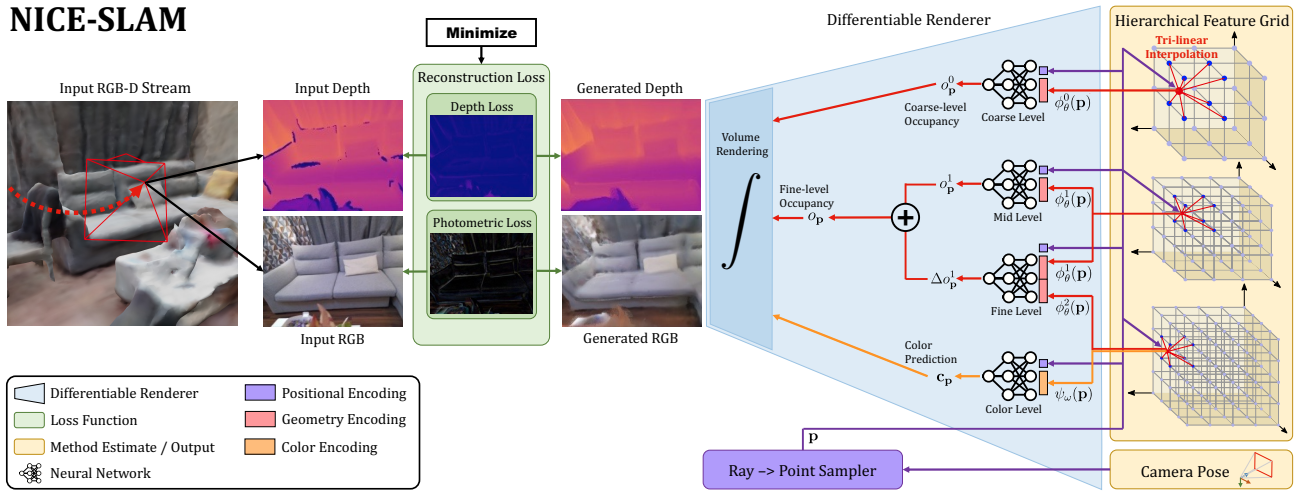
Hierarchical Scene Representation
The scene geometry is encoded into total four feature grids: 1) coarse-level, 2) mid-level, 3) fine-level, 4) scene appearance. Four pre-trained neural implicit decoders are attached to each feature grid. These feature grids themselves act as the map.
First, the system extracts the occupancy values by decoding the latent codes from the mid-level grid. Then, the system refines the geometry by decoding the latent codes from the fine-level grid.
Second, the coarse-level grid is used to predict the appoximate occupancy values of the unseen areas. It aims to capture high-level geometry, such as walls and floors. The occupancy values are also decoded from the feature grid. The optimization of this coarse-level grid is independent from the other grids.
Pre-training is done as a part of ConvONet. These pre-trained decoders are frozen during the training process to stabilize the optimization.
Color information provides additional cues for tracking. Color is decoded by its own decoder from the color feature grid. This decoder is not frozen during the training, but is optimized during the mapping process. The color of the entire scene is represented by one decoder MLP, which may lead to the forgetting issue.
Depth and Color Rendering
The system uses a differentiable rendering process, similar to NeRF, to integrate the predicted occupancy and colors from the hierarchical feature grids. It first performs stratified sampling along the viewing ray, and also performs uniform sampling near the object surface.
For every point, their coarse-level occupancy probability, fine-level occupancy probability, and color are computed using the pre-trained MLPs. Then, along the ray, the depth and color are integrated as the NeRF system does.
Mapping and Tracking
Depth loss and color loss are used to track the camera pose and optimize the feature grids. These losses are computed every frame. For each frame, the system samples total $M$ pixels from the current frame and the selected keyframes to calculate losses.
The depth loss is an $L_1$ loss between the predicted depth of the current frame and the ground truth depth. The color loss is an $L_1$ loss between the predicted color of the current frame and the ground truth color.
The camera tracking is formulated as the minimization problem that searches for the optimal camera pose $\{\mathbf{R},\mathbf{t}\}$ that minimizes the depth and color losses.
For mapping, the system conducts a local bundle adjustment to jointly optimize feature grids, the color decoder, as well as the camera poses of all selected keyframes. This is also a minimization problem.
Finally, the system filters out pixels with large depth/color losses to avoid dynamic objects.
Keyframe Selection
The system maintains a global keyframe list similar to iMAP. For mapping and tracking, however, only a subset of keyframes are selected for optimization. The keyframe selection strategy is as follows:
- The most recent keyframe is selected.
- $K-2$ Keyframes are randomly selected among those that have visual overlap with the current frame .
Including the current frame, total $K$ frames are involved in the optimization process. Thanks to this keyframe selection strategy, the system is able to make local updates to the feature grids. That is, the geometry outside of the current view remains static. This results in a very efficient optmization process.
Experiments
Experimental Setup
Datasets – Replica, ScanNet, TUM RGB-D, Co-Fusion, and a self-captured multi-room dataset are used for evaluation.
Baselines – TSDF-Fusion, DI-Fusion, iMAP, and the re-implementation version of iMAP are used as baselines.
Metrics – For 2D metric, the L1 loss is used on 1000 randomly-sampled points from both reconstruction and the ground truth. For 3D metrics, Accuracy [cm], Completion [cm], and Completion Ratio [< 5cm%] are used. For tracking metric, ATE RMSE is used.
Evaluation of Mapping and Tracking

In mapping, NICE-SLAM significantly outperforms baseline methods on almost all metrics, while keeping a reasonable memory consumption. Qualitatively, NICE-SLAM produces sharper geometry and less artifacts. The reconstruction results are shown in the figure above.
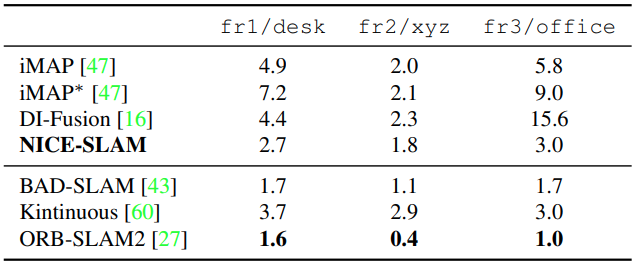
The table above shows ATE RMSE of the tracking results on the TUM RGB-D dataset. NICE-SLAM outperforms all of the baselines in the neural implicit representation family. Although the traditional feature-based methods, such as ORB-SLAM2, outperform NICE-SLAM, NICE-SLAM reduces the gap between these two categories.
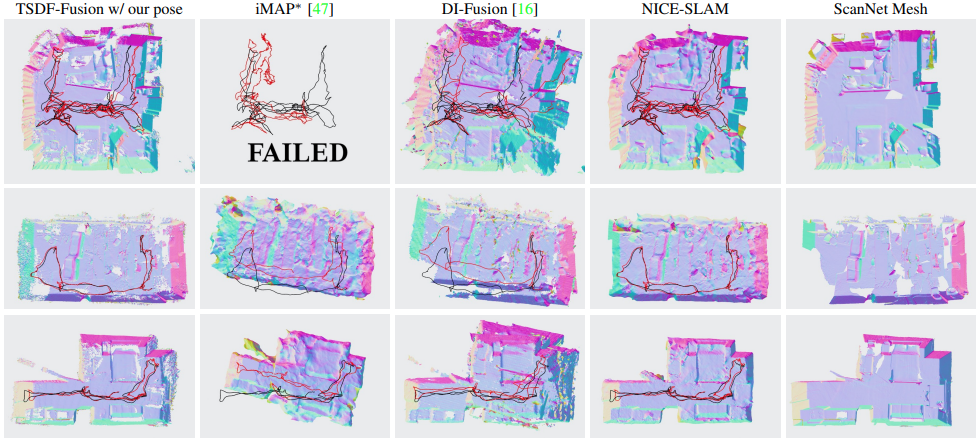

The figure and table above shows the scalability evaluation results on ScanNet, which contains large-scale scenes. ATE RMSE is used for evaluation in the table.
For the geometry shown in the figure above, NICE-SLAM produces sharper and more detailed geometry over the baseline methods.
In terms of tracking, iMAP* and DI-Fusion either completely fails or introduces large drifting, while NICE-SLAM successfully reconstructs the entire scene. Quantitatively, as shown in the table above, the tracking results of NICE-SLAM are also significantly more accurate than the baseline methods .

The figure above shows the reconstruction results of larger scenes from self-captured multi-room dataset. NICE-SLAM has comparable results with the offline method, while iMAP* and DI-Fusion fails to reconstruct the full sequence.
Performance Analysis

The table above compares the number of floating point operations (FLOPs) needed for one 3D point and the runtime for tracking and mapping using the same number of pixel samples.
NICE-SLAM requires only 1/4 FLOPs of iMAP and is over 2x and 3x faster than iMAP in tracking and mapping. This indicates the advantage of using feature grids with shallow MLP decoders over a single heavy MLP.

The white colored area is the region with observations, and cyan indicates the unobserved but predicted region. Thanks to the use of coarse-level scene prior, NICE-SLAM has better prediction capability compared to iMAP*. This in turn also improves the tracking performance.
Ablation Study
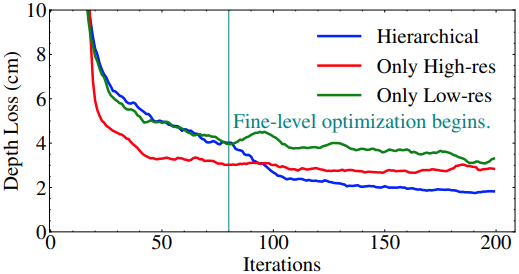
The hierarchical architecture is first evaluated. The figure above shows the convergence trend of the hierarchical, high-only, and low-only architectures. The hierarchical architecture converges better.

The usefulness of local BA, color representation, and the keyframe selection strategy is also investigated. The table above shows the ATE RSME results of each ablation study. All three components play important roles in camera tracking.
Conclusion
NICE-SLAM is a dense visual SLAM system that combines hierarchical scene representation with neural implicit representations. The system is more scalable, fine-detailed, accurate, fast, and less computationally expensive thanks to local scene updates. Besides, NICE-SLAM is able to fill small holes and predict unobserved regions which stabilizes the camera tracking.
There are also some limitations. The predictive ability of NICE-SLAM is restricted to the scale of the coarse representation. In addition, NICE-SLAM does not perform loop closures.