Introduction
3D visual grounding은 최근 관심을 받고 있는 주제지만 데이터의 형식이 복잡하고 공간적 위치관계가 훨씬 다양하다. 2-stage 모델들은 먼저 모든 물체들을 detect한 후 텍스트에 가장 적합한 하나를 고르는 방식이다. 하지만 기존 모델들은 2D visual grounding 방식을 적용했기 때문에 3D 공간상의 특징을 잘 반영하지 못한다.
2D visual grounding 방식은 viewpoint에 따라 달라지는 위치의 변화를 잘 감지하지 못한다(왼쪽/오른쪽 등). 하지만 실제 로봇이 사람의 명령을 수행해야 하는 상황에서는 사람과 로봇의 위치가 다를 수 있기 때문에 viewpoint에 관계없이 grounding을 할 수 있는 3D visual grounding 모델이 필요하다.
MVT는 여러 viewpoint로 회전시킨 물체의 point cloud를 이용하여 view-robust representation을 학습한다.
Related Work
기존 모델들은 2-stage로 이 문제를 해결하였다. 먼저 모든 물체의 proposal을 얻는다. 이는 GT로 제공되거나 3D object detector로 얻을 수 있다. 이후 matching problem으로 접근하여 주어진 텍스트와 가장 잘 align된 물체를 하나 선택한다.
Method
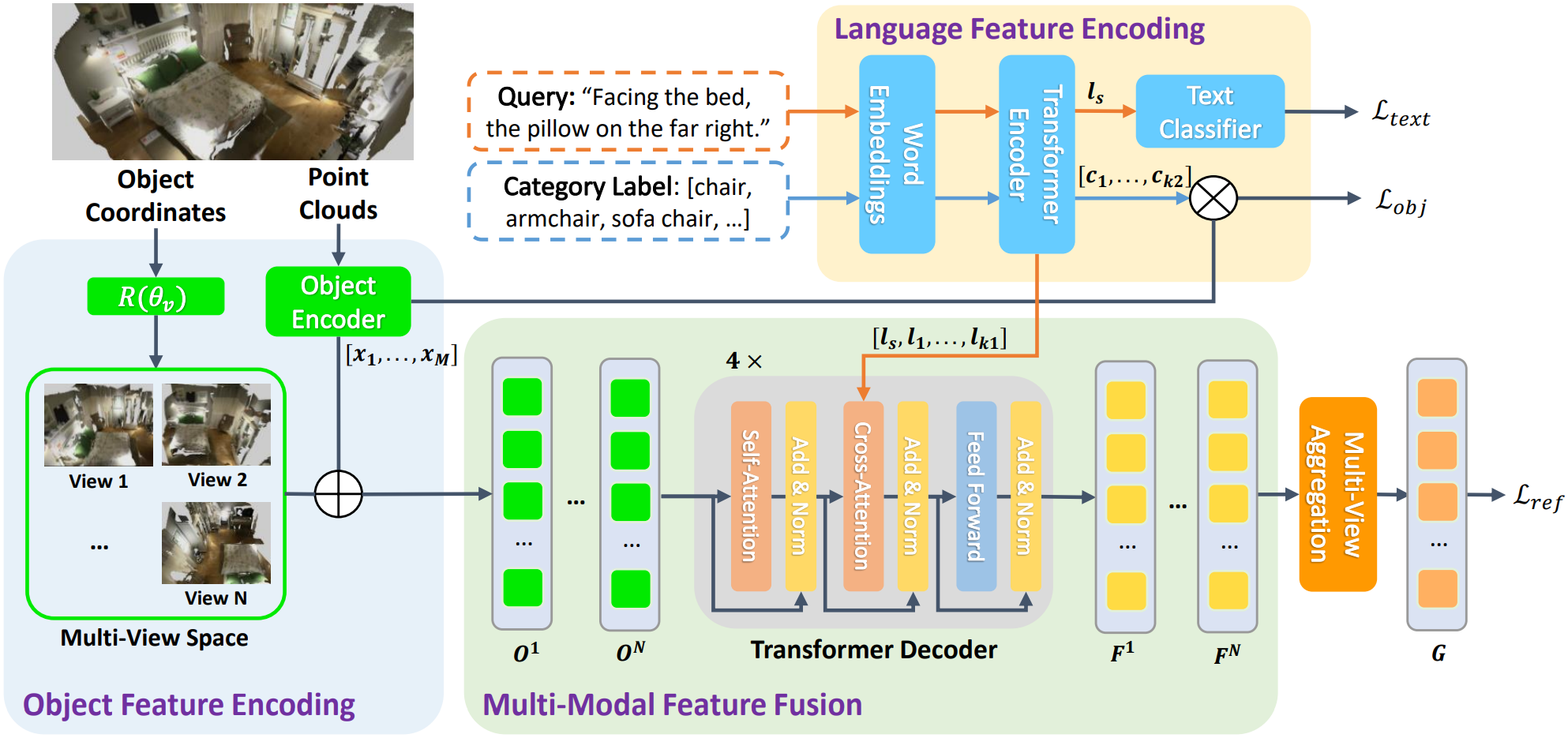
Multi-View 3D Visual Grounding
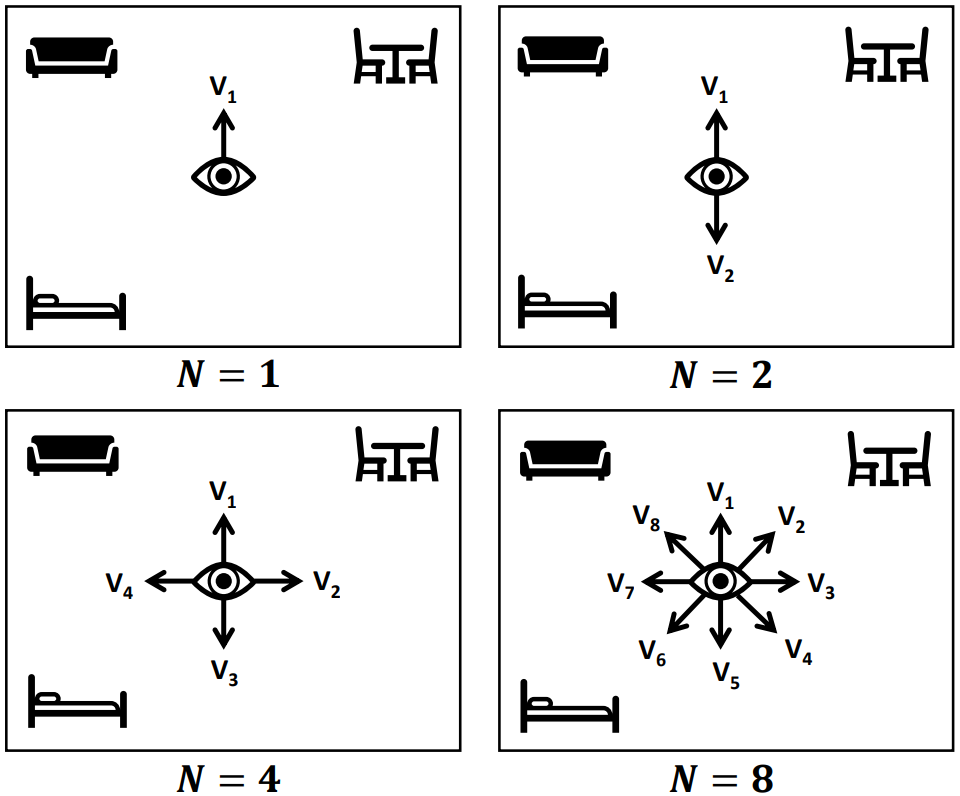
View에 independent한 representation을 학습하기 위해, 먼저 전체 scene을 여러 각도로 회전시킨다. 이때 아래 그림과 같이 원하는 view의 개수 $N$에 따라 동일한 각도로 회전시킨다.
Object Feature Encoding
특정 scene $S$에 대해 $M$개의 candidate object들이 있다고 하자. 먼저 각 물체별로 1024개의 점을 subsampling한다. 각 점은 RGB color와 xyz 좌표를 가지고 있다. 즉, $i$번째 물체에 대한 point cloud는 $pc_i \in \mathbb{R}^{1024 \times 6}$이다.
$x_i = \text{LN} (W_x \cdot \text{PointNet++}(pc_i))$
이후 위 수식을 사용해 각 object별 feature vector $x_i$를 얻는다. $W_x$는 projection matrix, $\text{LN}$은 layer normalization에 해당한다.
물체의 위치에 대한 정보는 별도로 인코딩한다. 각 물체의 bounding box의 중심점을 $\{ b_1, \dots, b_M \}$라 하자. $j$번째 view에 해당하는 회전 각도 $\theta_v^j$에 대해 중심점을 회전시키면 $b_i^j = R(\theta_v^j) \times b_i$가 된다.
$\text{PE}(b_i^j) = \text{LN} (W_b [b_i^j, r_i])$
이후 위 수식을 사용해 positional encoding $\text{PE}(b_i^j)$를 얻는다. $r_i \in \mathbb{R}^1$는 box 의 크기, $W_b$는 projection matrix, $[\cdot, \cdot]$는 concat 연산이다.
$o_i^j = x_i + \text{PE}(b_i^j)$
최종적으로 위 수식을 이용해 $j$번째 view에 대한 final object feature $O^j = \{ o_1^j, \dots, o_M^j \}$를 얻는다.
Multi-Modal Feature Fusion
텍스트 데이터는 BERT 모델을 이용해 인코딩된다. Query $Q$가 $k_1$개의 단어로 구성되어 있을 때, 문장 전체와 각 단어를 인코딩하여 아래의 feature를 얻을 수 있다.
$L = \{ l_s, l_1, \dots, l_{k_1} \} = \text{BERT}(Q)$
$l_s$는 문장 전체에 대한 feature, $l_i$는 각 단어별 feature다.
BERT를 fine-tuning하기 위해 $l_s$를 2개의 FC layer에 통과시켜 그 텍스트가 지칭하는 object category를 예측하고, cross-entropy loss $\mathcal{L}_{text}$를 얻는다.
이후 transformer decoder를 이용하여 feature fusion을 진행한다.
$F^j = \text{Decoder}(O^j, L)$
먼저 object feature $O^j$가 self-attention 모듈을 통과하고, 그 output과 $L$이 cross-attention 모듈을 통해 합쳐진다. 그 후 Feed forward network까지 총 3개의 stage가 총 4번 반복된다. 이를 통해 fused feature $F^j = \{ f_i^1, \dots, f_i^{N} \}$을 얻는다.
Multi-View Aggregation
이 과정은 앞서 얻은 각 view에 대한 feature $F^j$를 하나로 합치는 과정이다. View의 순서에 무관하도록 하기 위해 단순 평균을 사용한다.
$g_i = \sum\limits_{j=1}^{N} \cfrac{f_i^j}{N}$
이렇게 얻은 최종 multi-modal feature $G = \{ g_1, \dots, g_M \}$를 두 개의 FC layer에 통과시켜 최종 grounding score를 얻는다. Cross-entropy loss를 이용하여 $\mathcal{L}_{ref}$를 얻는다.
Improving Object Encoder
Object encoder를 더욱 향상시키기 위해 추가적인 classification task를 수행한다. 우선 주어진 category label에 해당하는 단어들을 BERT를 이용해 feature $C = \{ c_1, \dots, c_{k_2} \} \in \mathbb{R}^{k_2 \times d}$로 변환한다. $k_2$는 단어의 개수, $d$는 각 벡터의 dimension이다.
이후 object feature $x_i$와 $C$의 각 element를 inner product하여 $i$번째 물체가 어떤 카테고리에 속하는지 classification한다. Cross-entropy loss를 이용하여 $\mathcal{L}_{obj}$를 얻는다.
Overall Loss Functions
$\mathcal{L}_{total} = \mathcal{L}_{ref} + \alpha (\mathcal{L}_{text} + \mathcal{L}_{obj})$
3개의 loss term을 위 식과 같이 조합하여 최종 loss를 계산한다.
Experiments
Experimental Setting
- 데이터셋: ReferIt3D, ScanRefer
- Pretrained object detector(ScanRefer dataset): PointGroup
- Pretrained text encoder: BERT의 첫 3개 layer
- MetricAcc@mIoU를 사용하였다.
Quantitative Results
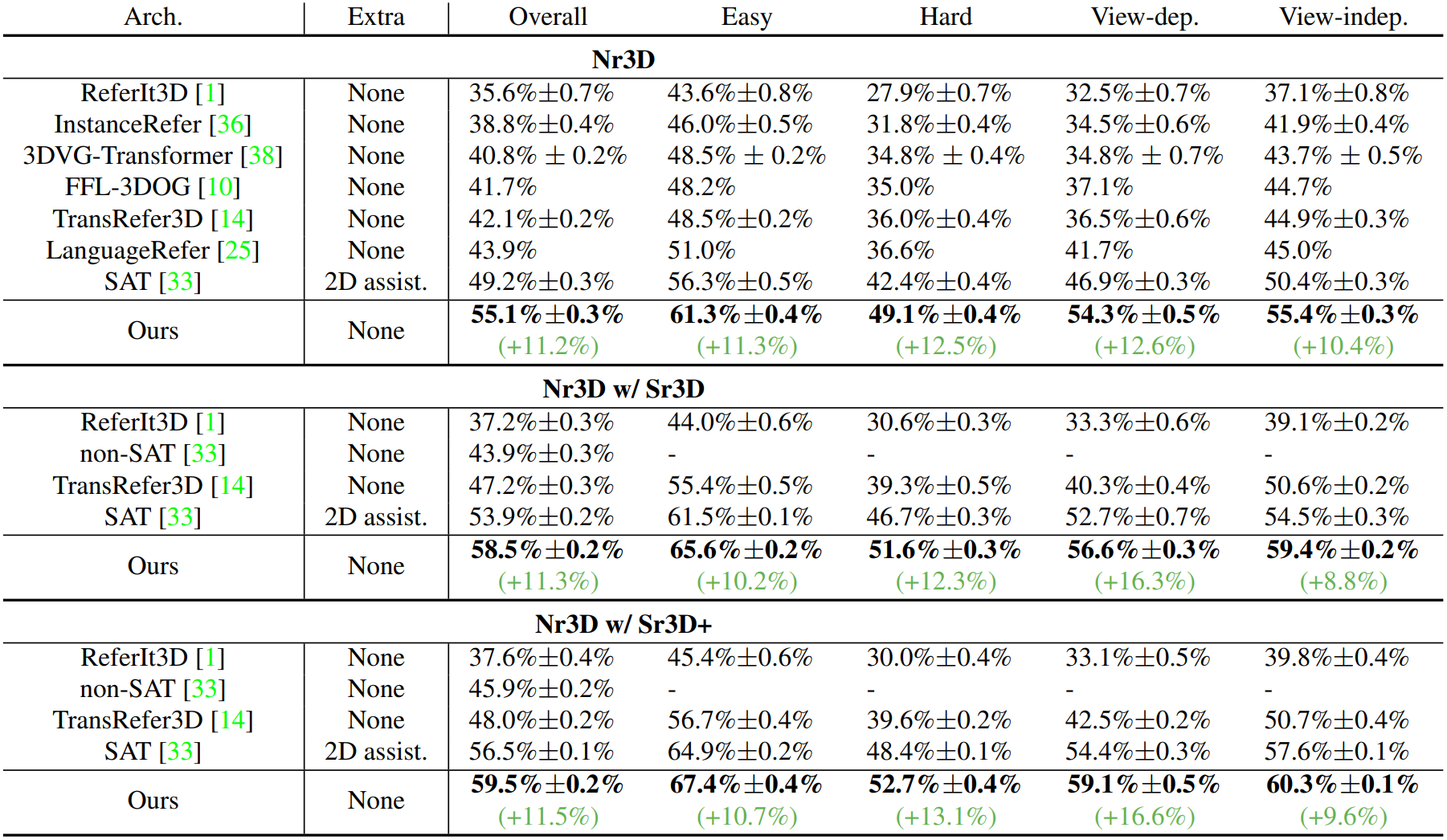
NR3D 데이터셋에서의 결과는 위와 같다.
SR3D 데이터셋에서의 결과는 위와 같다.
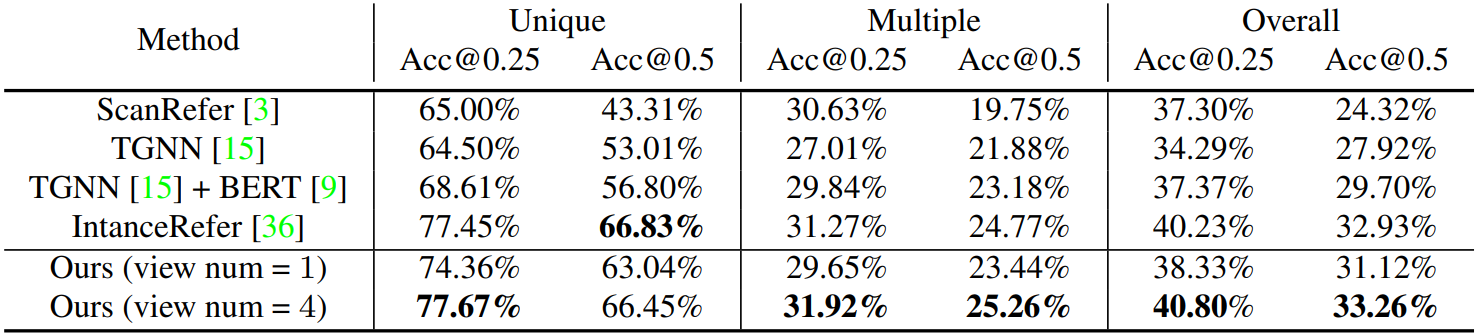
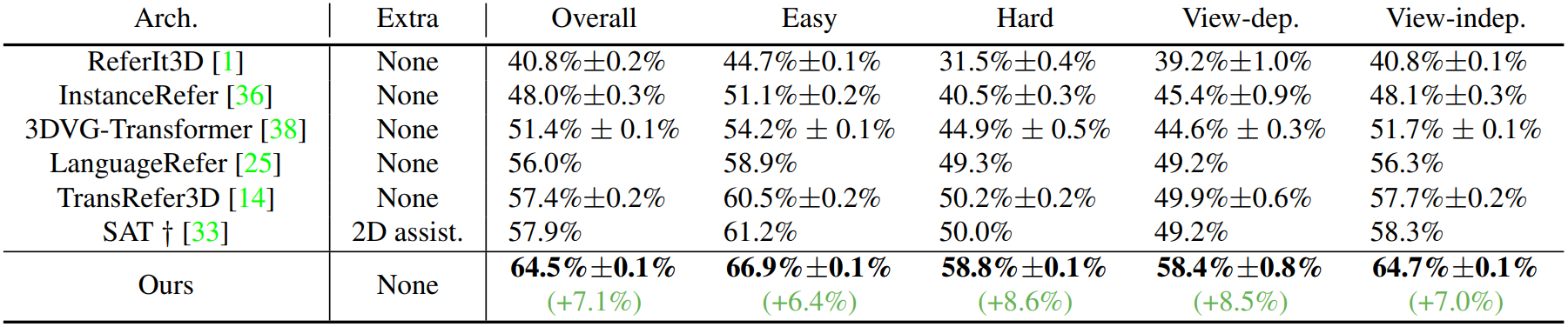
ScanRefer 데이터셋에서의 결과는 위와 같다.
Qualitative Results
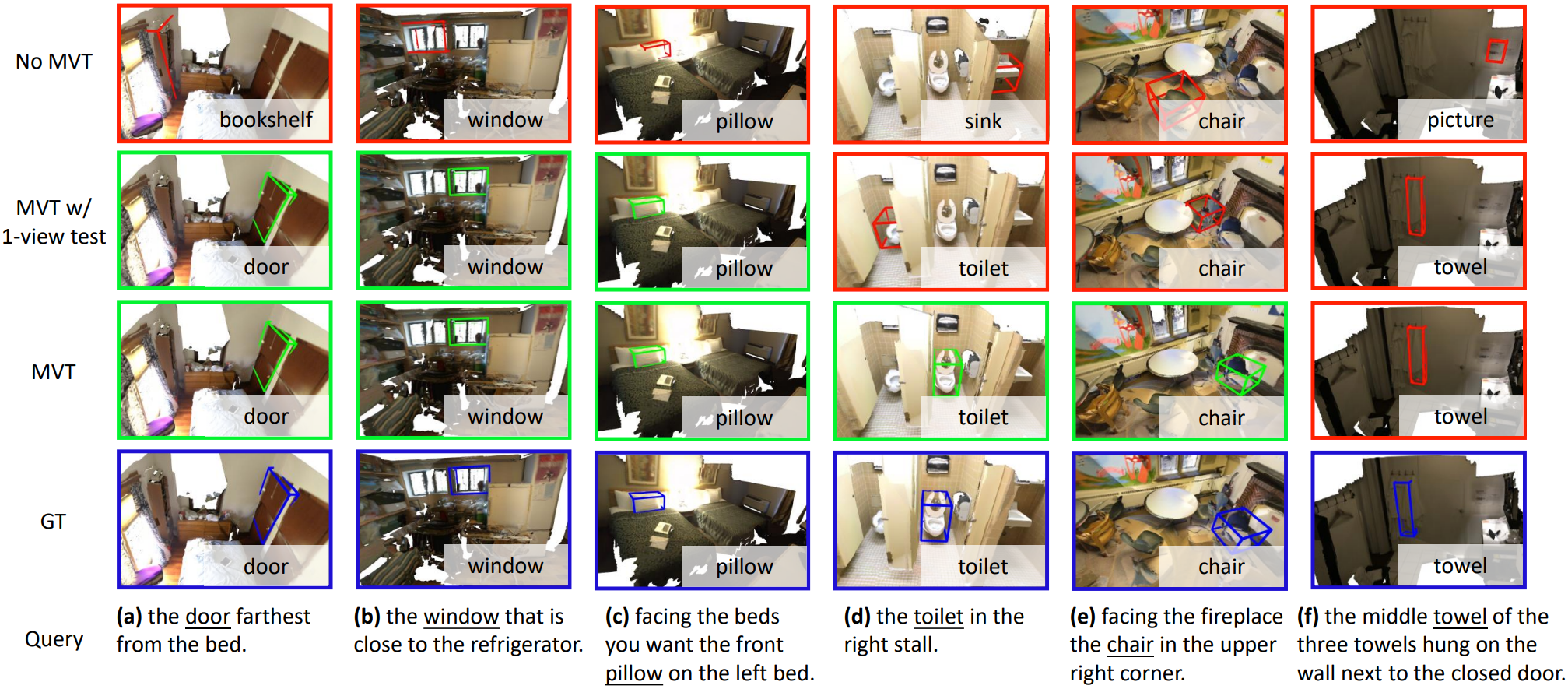
MVT 실행 결과를 시각화하면 위와 같다.
Ablation Study
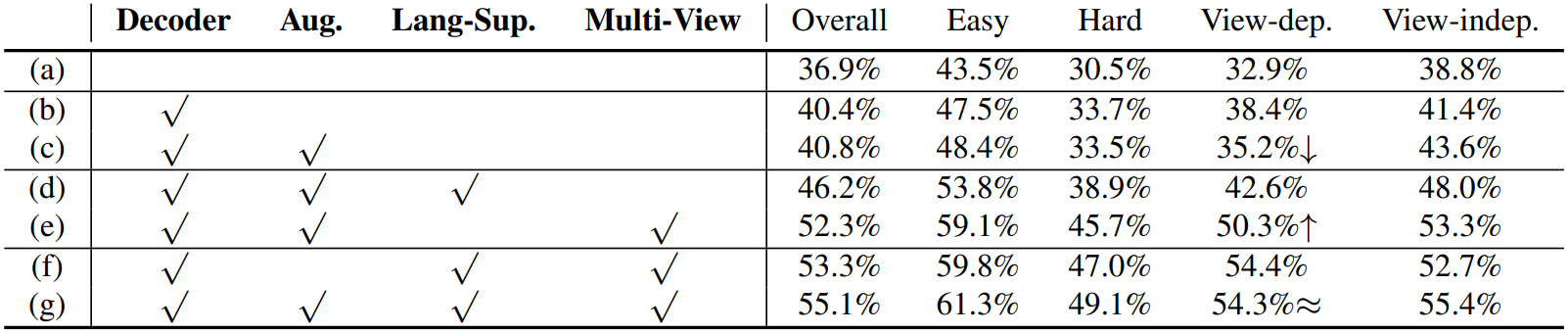
Ablation study 결과는 위와 같다. (c)와 (e)를 비교했을 때 multi-view modeling이 효과적임을 알 수 있다. 그 외에도 각 요소들이 MVT의 정확도 향상에 기여하고 있는 것을 확인할 수 있다.
Conclusion
MVT는 multi-view에서의 3D 정보를 이용하여 특정 view에 의존하지 않는 3D visual grounding 모델이다.