Introduction

문제제기: Open-vocabulary 3D scene understanding을 위한 대규모 데이터셋이 없다.
이러한 데이터셋의 조건:
- 정확한 3D segmentation
- Comprehensive text label
- 충분한 데이터셋 크기
기존 방법들은 2D VLM을 이용해 데이터 생성을 자동화하려고 시도했지만, bounding box를 사용하는 등 boundary가 정확하지 않거나, label이 너무 단순하거나, 데이터셋의 크기가 너무 작았다.
본 논문에서는 더 나은 data generation pipeline을 제안한다.
- SOTA open-vocabulary 2D segmentation model을 사용하여 boundary의 정확도를 향상시켰다.
- Region-aware VLM을 사용하여 구체적인 캡션을 생성하였다.
- 데이터셋의 크기가 충분히 크다.
Related Work
Open-Vocabulary 3D Instance Segmentation
기존의 3D instance segmentation 모델은 두 종류로 나눌 수 있다.
- Closed-vocabulary로 3D에서 직접 segment한다.
- CLIP과 같은 2D VLM을 이용하기 위해 2D로 scene을 렌더링하여 학습한다.
반면 본 논문에서 제안하는 encoder는 3D point로부터 embedding을 직접 구하는 것이 가능하다.
Mosaic3D-5.6M Data Engine
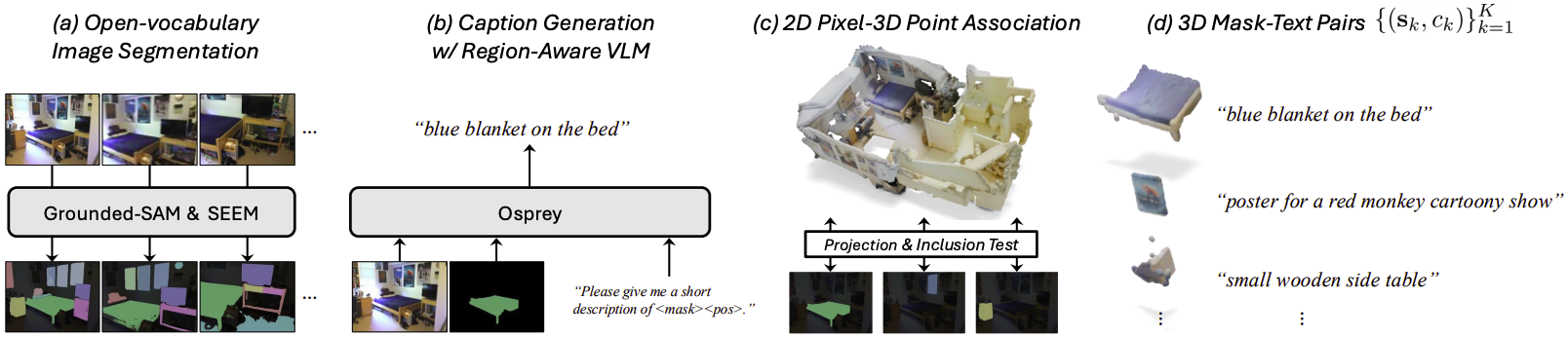
Segmentation을 위해 Grounded-SAM과 SEEM을 사용한다. Grounded-SAM을 이용해 주로 foreground object를 정확하게 segment하고 SEEM을 이용해 주로 background를 segment한다.
Region-aware VLM으로는 Osprey를 사용한다. Osprey는 전체 이미지, segmentation mask, 텍스트 프롬프트를 입력받아 다른 VLM 모델들보다 구체적인 캡션을 생성할 수 있다. 특히, 마스킹된 영역의 공간적인 정보를 설명할 수 있다.
각 2D mask를 이용해 3D mask를 생성하기 위해 먼저 3D point cloud를 각 viewpoint로 project한다. 각 mask 영역 안에 들어가면서 depth가 GT depth와 유사한 점들을 그 마스크에 해당하는 3D 점으로 본다. 각 mask에 해당하는 3D 점들을 모아 그 마스크에 해당하는 캡션을 association하면 3D mask-text pairs $\{(\mathbf{s}_k, c_k)\}_{k=1}^K$를 얻는다.
ScanNet, ARKitScenes, Matterport3D, ScanNet++, Structured3D 데이터셋을 이용하여 3D segmentation 데이터를 생성한 결과 총 30K개의 scene에서 30M개의 text token, 5.6M개의 mask-text pair를 얻었다.
Model Training
Mosaic3D: Language-Aligned 3D Encoder
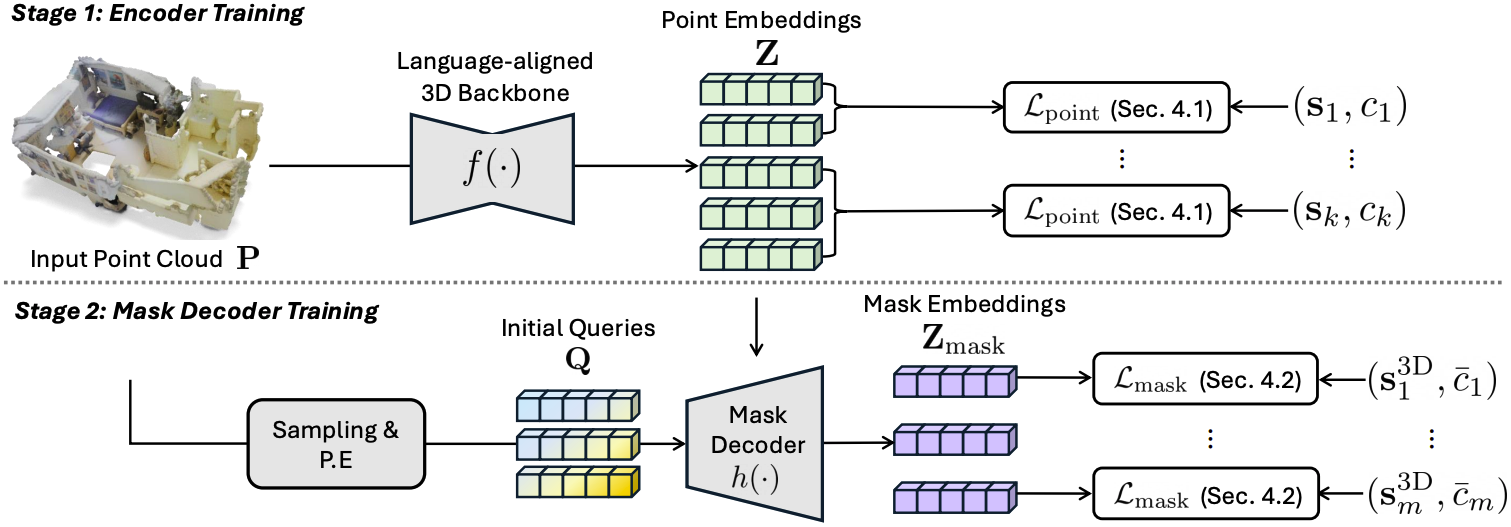
Mosaic3D-5.6M 데이터셋을 이용하여 실제로 3D point에서 embedding을 구하는 encoder와 그 반대 연산을 하는 decoder를 학습하였다.
먼저 3D encoder $f(\cdot)$는 U-shaped sparse convnet을 backbone으로 사용했다. Point cloud $\mathbf{P} \in \mathbb{R}^{N \times 3}$가 주어졌을 때 backbone은 per-point feature $\mathbf{Z} = f(\mathbf{P}) \in \mathbb{R}^{N \times D}$를 출력한다.
학습을 위해 contrastive learning을 사용한다. 3D mask-text pairs $\{(\mathbf{s}_k, c_k)\}_{k=1}^K$가 주어졌을 때, 먼저 pre-trained text encoder $g(\cdot)$를 이용해 text embedding $\mathbf{w}_k = g(c_k) \in \mathbb{R}^{D}$를 계산한다. 이때 Recap-CLIP을 사용하였다.
이후 각 점의 point embedding과 text embedding의 similarity score를 계산한다. 이때 각 마스크 영역 내에서 pooling을 진행하고, 최종적으로 모든 마스크에 대한 평균 loss를 구한다.
$\mathcal{L}_{\text{point}} = - \cfrac{1}{K} \sum\limits_{k=1}^{K} \text{Pool} \left( \mathbf{s}_k, \sigma \left( \mathbf{Z}, \mathbf{w}_k \right) \right)$
$\sigma (\mathbf{Z}, \mathbf{w}_k) = \log \cfrac{\exp \left( \mathbf{Z} \cdot \mathbf{w}_k^{\top} / \tau \right)} {\sum\limits_{j=1}^{K} \exp \left( \mathbf{Z} \cdot \mathbf{w}_j^{\top} / \tau \right)}$
Mosaic3D with Mask Decoder
Point embedding을 이용해 open-vocabulary 3D instance segmantation을 할 수 있도록 mask decoder를 추가로 학습하였다. Mask3D 모델을 사용하였다.

이 decoder를 학습하기 위해 3D mask-text pairs 데이터에 대한 추가적인 처리가 필요하다. $\{(\mathbf{s}_k, c_k)\}$는 특정 뷰에서의 마스크를 단순히 3D로 투영한 것이기 때문에 실제 object instance 단위로 마스크를 다시 묶어줄 필요가 있다. 위 알고리즘과 같이 Segment3D mask를 활용한다.
Decoder $h(\cdot)$는 encoder의 출력 $\mathbf{Z} = f(\mathbf{P})$와 위 알고리즘으로 구한 3D mask-text pairs $\{ ( \mathbf{s}_{m}^{\text{3D}}, \{ c_{j \in \mathcal{M}_m} \} ) \}_{m=1}^{M}$ 를 입력으로 받아 language feature와 align된 mask embedding $\mathbf{Z}_{\text{mask}}$를 출력한다.
$\mathbf{Z}_{\text{mask}} = h(\mathbf{Z}; \mathbf{Q})$
$\mathbf{o} = \text{Linear}(\mathbf{Z}_{\text{mask}}), \quad \mathbf{S}_{\text{pred}} = \sigma (\mathbf{Z}_{\text{mask}} \cdot \mathbf{Z}^{\top})$
이후 위 식과 같이 $\mathbf{Z}_{\text{mask}}$를 MLP에 통과시켜 그 마스크의 objectness를 구하고, 각 점의 embedding $\mathbf{Z}$와의 cosine similarity를 통해 binary mask를 예측한다. 이 두 값을 통해 objectness prediction loss $\mathcal{L}_\text{obj}$, Dice loss $\mathcal{L}_\text{dice}$, binary cross entropy loss $\mathcal{L}_\text{bce}$를 계산한다. 이 세 loss term으로 decoder를 일차적으로 학습한다.
이후 open-vocabulary segmentation을 위해 mask caption loss $\mathcal{L}_\text{cap}$도 계산한다.
$\bar{\mathbf{w}}_m = g(\bar{c}_m)$
위 식과 같이 text embedding도 계산한다. 이때 $\bar{c}_m$은 $\mathbf{s}_{m}^{\text{3D}}$에 속한 캡션을 모두 concat한 것이다. 이후 아래 식과 같이 mask embedding과 caption embedding을 align한다.
$\mathcal{L}_{\text{cap}} = -\cfrac{1}{M} \sum\limits_{m=1}^{M} \sigma (\mathbf{Z}_{\text{mask}}, \bar{\mathbf{w}}_m)$
$\sigma (\mathbf{Z}_{\text{mask}}, \bar{\mathbf{w}}_m) = \log \cfrac{\exp \left(\mathbf{Z}_{\text{mask}} \cdot \bar{\mathbf{w}}_m^\top / \tau \right)} {\sum\limits_{j=1}^{M} \exp \left(\mathbf{Z}_{\text{mask}} \cdot \bar{\mathbf{w}}_j^\top / \tau \right)}$
최종 loss term은 아래와 같다.
$\mathcal{L}_{\text{mask}} = \lambda_{\text{obj}} \mathcal{L}_{\text{obj}} + \lambda_{\text{dice}} \mathcal{L}_{\text{dice}} + \lambda_{\text{bce}} \mathcal{L}_{\text{bce}} + \lambda_{\text{cap}} \mathcal{L}_{\text{cap}}$
이러한 decoder를 통해, 여러 뷰에서 CLIP feature를 계산할 필요 없이 바로 open-vocabulary 3D segmentation을 수행할 수 있다.
Experiments
Open-Vocabulary 3D Semantic Segmentation
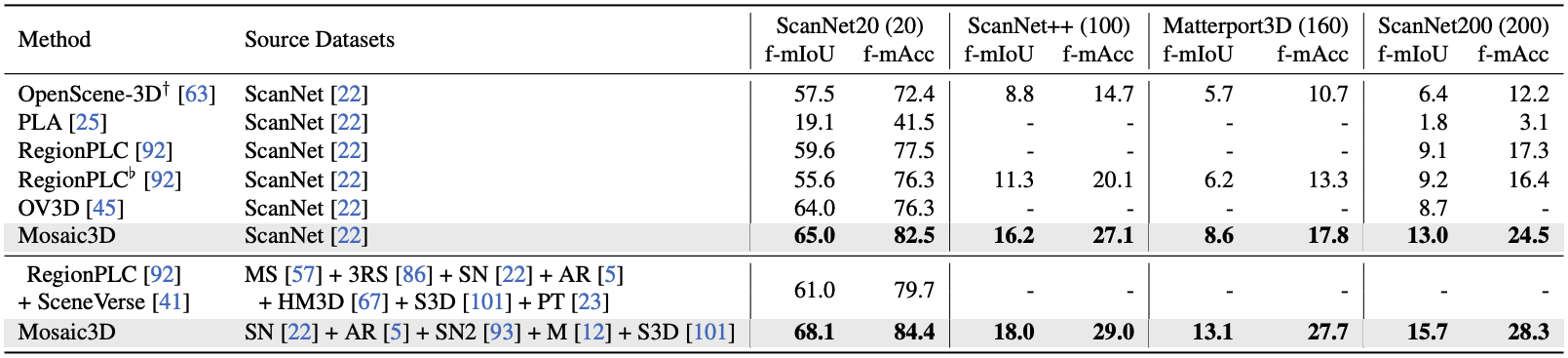
Mosaic3D 모델이 다른 모델들보다 semantic segmentation 정확도가 높은 것을 볼 수 있다.
Open-Vocabulary 3D Instance Segmentation
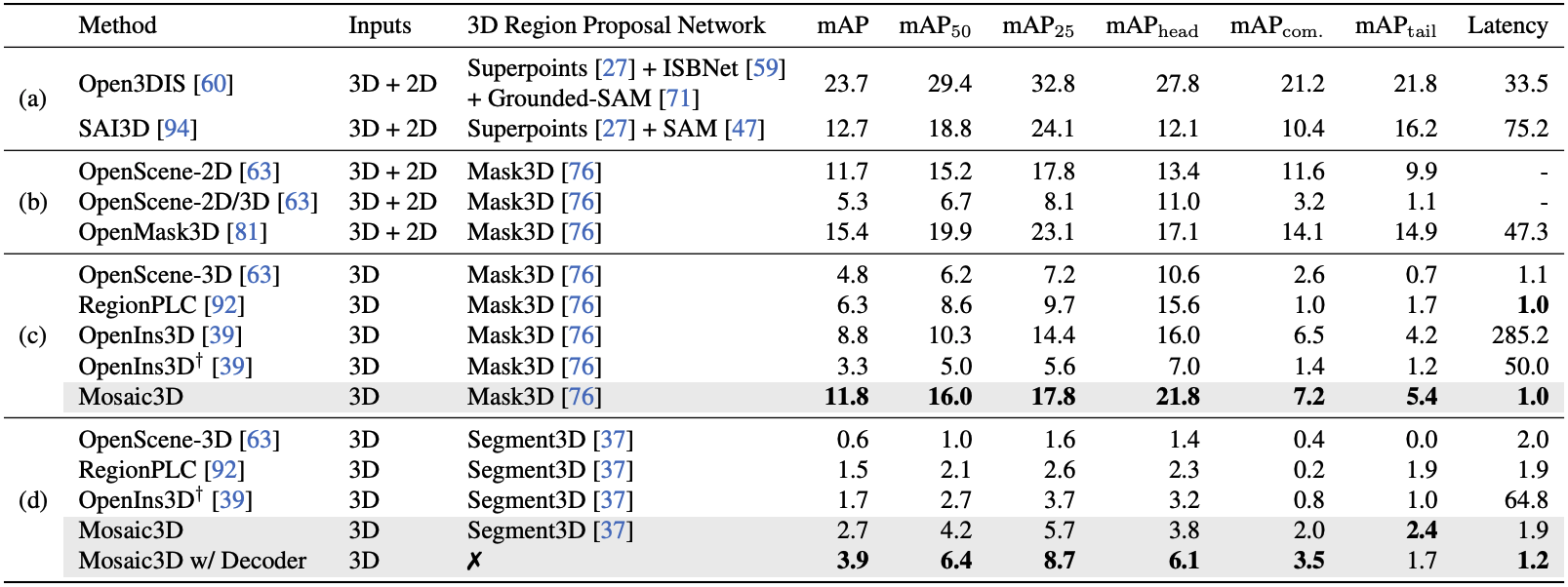
Instance segmentation도 마찬가지로 Mosaic3D 모델이 다른 모델들보다 정확도가 높은 것을 볼 수 있다. 또한 Mosaic3D 모델의 처리 속도도 빠른 것을 볼 수 있다.
Conclusion
본 논문의 key contribution은 2D VLM을 이용하여 높은 퀄리티의 3D mask-text pairs를 생성하는 pipeline을 구축했다는 것이다. 또한 이 데이터셋을 기반으로 3D encoder와 decoder를 학습하여 open-vocabulary 3D segmentation task에서 SOTA를 달성하였다.
하지만 Matterport3D나 Structured3D와 같이 view가 너무 sparse한 scene에 대해서는 성능이 크게 차이가 나지 않는다는 한계점이 있다.