TL;DR
- Flow, diffusion 같은 generative control policy(GCP)가 regression control policy(RCP)보다 좋은 이유로 흔히 거론되는 multi-modality 포착, 높은 expressivity, pixel 기반 제어 등은 실제로 핵심 요인이 아니다.
- GCP의 성공은 stochasticity injection(C2)과 supervised iterative computation(C3)의 조합에서 비롯되며, distribution fitting(C1)은 가장 덜 중요한 요소이다.
- C2+C3만 결합한 2-step 정책인 Minimal Iterative Policy(MIP)가 flow 모델과 동등한 성능을 달성하면서도 deterministic inference와 적은 연산량을 제공한다.
- GCP와 MIP의 성능을 설명하는 핵심 특성은 manifold adherence로, expert trajectory의 manifold에 가까운 action을 생성하는 inductive bias이다.
Thoughts
GCP가 왜 잘 되는지에 대해 그동안 "multi-modality를 포착하니까", "더 expressive하니까" 같은 설명이 널리 퍼져 있었는데, 이 논문은 28개 벤치마크에 걸친 체계적인 ablation으로 이런 통념을 하나씩 반박한다. 특히 아키텍처를 통제한 상태에서 RCP와 GCP를 비교한 것이 가장 큰 기여인데, 기존 연구들이 GCP에만 Transformer나 UNet 같은 강력한 아키텍처를 쓰고 RCP에는 단순한 MLP를 쓰면서 생긴 confounding을 깔끔하게 제거했다.
MIP라는 결과물도 실용적으로 매력적이다. 2-step만 쓰면서 flow와 동등한 성능을 내고, inference 시 stochasticity도 없어 재현성이 높다. 다만, MIP가 flow를 "대체"한다기보다는 flow의 어떤 요소가 실제로 작동하는지를 보여주는 진단 도구에 가깝다. Manifold adherence라는 설명도 흥미롭지만, 왜 stochastic supervision이 manifold adherence를 유도하는지에 대한 이론적 설명이 아직 부족하다는 점은 저자들도 인정하고 있다.
한 가지 아쉬운 점은 모든 실험이 behavior cloning 세팅에 한정되어 있다는 것이다. RL fine-tuning이나 large-scale pretraining 같은 실제 로봇 foundation model 파이프라인에서도 C2+C3의 이점이 유지되는지는 열린 질문으로 남아 있다. 또한 아키텍처의 중요성을 강조하면서도, 어떤 아키텍처가 어떤 task에 좋은지에 대한 체계적인 가이드라인은 제시하지 못했다.
Introduction
Furniture assembly, food preparation 같은 long-horizon dexterous manipulation은 로보틱스의 오랜 과제이다. 최근 behavior cloning(BC)의 성공과 함께, flow나 diffusion 같은 generative modeling 아키텍처를 policy parameterization에 사용하는 generative control policy(GCP)가 주목받고 있다. GCP가 기존의 regression control policy(RCP)보다 우수한 이유에 대해 여러 가설이 제시되어 왔다.
- H1. Pixel 기반 제어에서 더 뛰어난 성능
- H2. 학습 데이터의 multi-modality 포착
- H3. Iterative computation을 통한 높은 expressivity
- H4. Stochastic data augmentation을 통한 representation learning
- H5. 학습 안정성과 확장성 향상
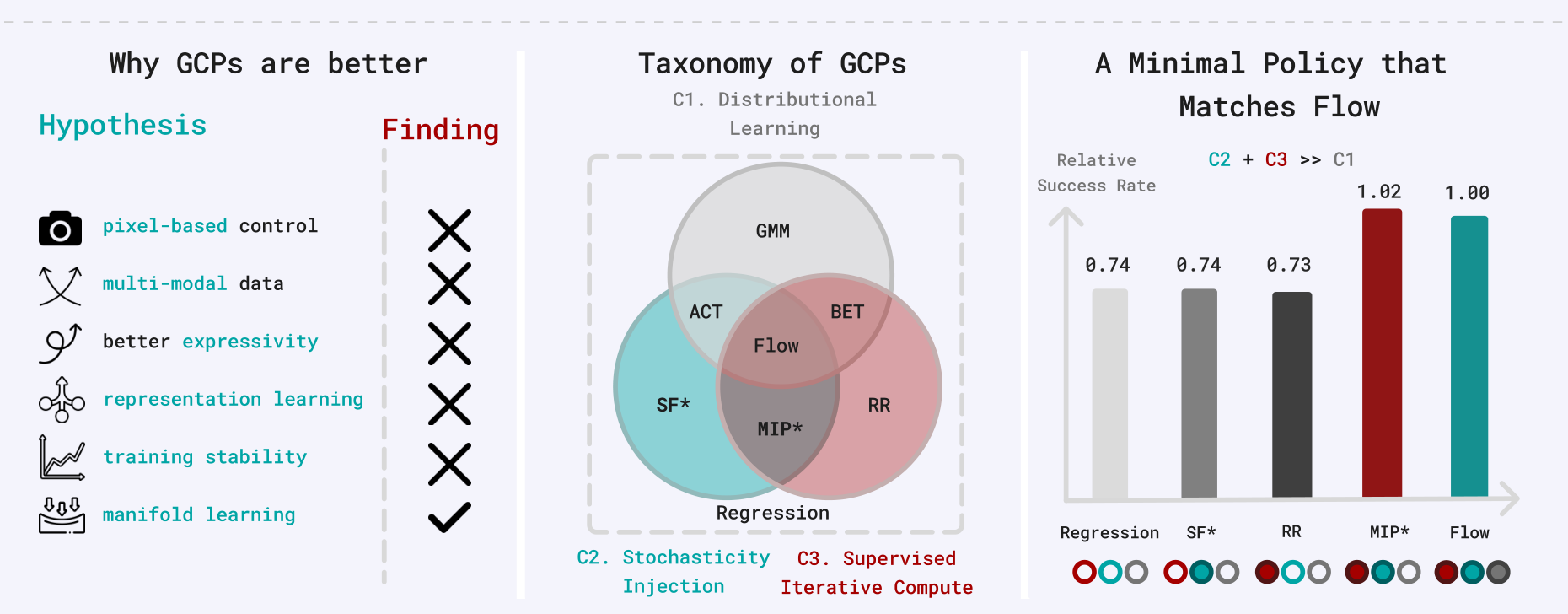
이 논문은 28개의 BC 벤치마크에서 GCP의 성공 요인을 체계적으로 분석한다. 핵심 발견은, 위의 가설들 중 대부분이 실제로는 GCP 성능의 핵심이 아니며, stochasticity injection과 supervised iterative computation의 조합이 가장 중요하다는 것이다.
Preliminaries
Observation $o \in O$와 action $a \in A$로 구성된 continuous control 세팅을 고려한다. Policy $\pi: O \to \Delta(A)$를 학습하여 주어진 task의 성공 확률 $J(\pi)$를 최대화한다. BC에서는 training distribution $p_{\text{train}}$에서 추출한 $(o, a)$ 쌍으로 policy를 학습한다.
RCP는 deterministic map $\pi: O \to A$로, neural network $\pi_\theta$가 $L_2$ loss를 최소화하도록 학습된다.
$\pi_\theta \approx \arg\min_\theta \mathbb{E} \|\pi_\theta(o) - a\|^2, \quad (o,a) \sim p_{\text{train}}$
GCP는 action의 분포 $a \sim \pi_\theta$를 parameterize한다. 이 논문은 flow 기반 GCP(flow-GCP)에 집중하며, conditional flow field $b: [0,1] \times A \times O \to A$를 학습한다.
$b_\theta \approx \arg\min_\theta \mathbb{E} \|b_t(I_t \mid o) - \dot{I}_t\|^2, \quad t \sim \text{Unif}([0,1]), \quad z \sim \mathcal{N}(0, \mathbf{I})$
여기서 $I_t = ta + (1-t)z$는 training action $a$와 noise $z$ 사이의 stochastic interpolant이다. Flow 모델은 noise $z$에서 시작하여 ODE를 적분해 action을 예측한다. 실제로는 9-step Euler integration을 사용한다.
Multi-modality and Expressivity Do Not Explain GCPs' Performance
When Controlled for Architecture, GCPs Only Outperform on Few Tasks
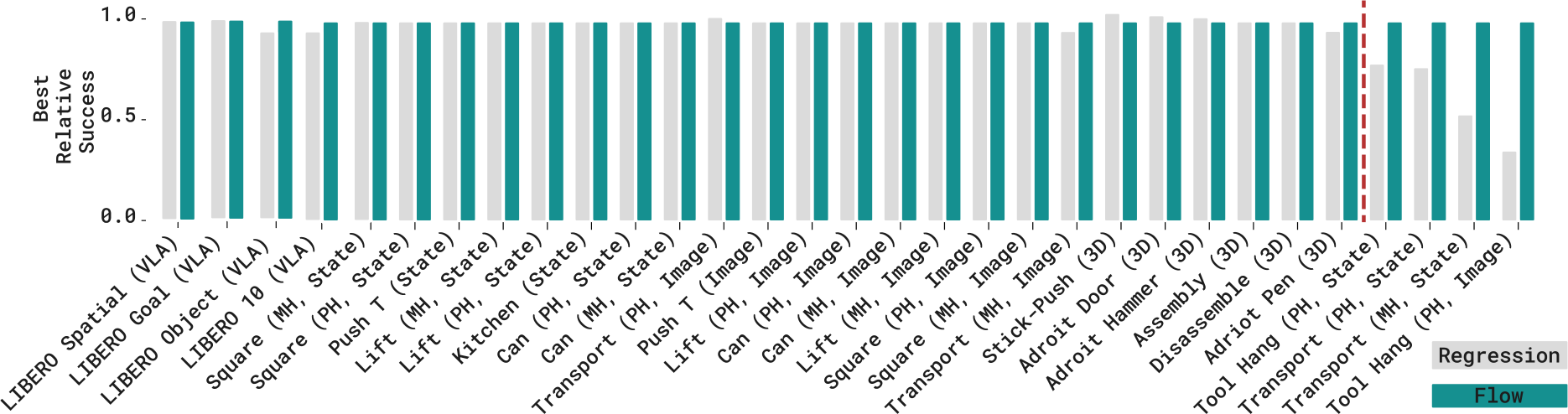
GCP와 RCP의 공정한 비교를 위해, Chi-Transformer, Sudeep-DiT, Chi-UNet 등 동일한 아키텍처를 공유하도록 설정했다. RCP는 noise level과 initial noise를 0으로 설정하면 같은 아키텍처로 구현할 수 있다. $\pi_0$ 같은 pre-trained VLA 모델도 backbone으로 사용했다.
결과적으로 state, image, VLA 기반 벤치마크 대부분에서 GCP와 RCP는 비슷한 성능을 보였다. GCP가 RCP를 5% 이상으로 능가하는 task는 소수에 불과했다. 핵심 통찰은 세 가지이다.
- GCP의 이점이 드문 경우에만 나타난다. 대부분의 task에서 성능 차이가 미미하다.
- Modality 독립적이다. Observation modality(state, image, point cloud)가 GCP의 이점과 상관관계를 보이지 않는다.
- 아키텍처가 지배적이다. Generative vs. regression 구분보다 아키텍처 선택이 성능에 훨씬 큰 영향을 미친다.
기존 연구에서 GCP가 우월하다고 보고된 이유는 아키텍처 비대칭성 때문이었다. GCP에만 Transformer나 UNet 같은 강력한 아키텍처를 사용하고 RCP에는 단순한 MLP를 사용하면서 생긴 혼동이었다.
GCPs' Performance Does Not Arise from Multi-modality
기존 문헌에서는 GCP가 training data의 multi-modality를 포착하기 때문에 성능이 좋다고 주장해왔다. 하지만 실험적 근거들은 이를 뒷받침하지 않는다.
Evidence A. 고정된 observation에서 다양한 initial latent로 action을 sampling해보면, 뚜렷한 action mode가 관찰되지 않는다. Push-T에서 T자 모양의 대칭축을 기준으로 좌우 경로가 동등한 상황에서도, 모든 trajectory가 한쪽으로만 가는 경향을 보인다.
Evidence B. Mean action(Monte Carlo 평균)으로 대체해도 성능 저하가 미미하다. 학습된 분포가 실제로 multi-modal이었다면 mean action은 mode 사이에 위치하여 성능이 크게 떨어져야 한다.
Evidence C. Deterministic expert로 수집한 완전 deterministic dataset에서도 GCP가 RCP를 능가한다. 데이터 자체에 multi-modality가 전혀 없어도 GCP의 이점이 유지된다.
Multi-modality 부재의 원인은 observation dimension에 비해 demonstration 수가 상대적으로 적기 때문이다. $d$차원 observation space를 grid로 나누려면 $2^d$개의 점이 필요한데, 실제 데이터에서는 같은 관측에 대해 "충돌하는" action을 거의 찾아볼 수 없다. 데이터가 multi-modal로 보이더라도 고차원 observation space에서 보면 사실상 unimodal인 경우가 대부분이다.
Limitations of the Expressivity of GCPs in the Absence of Multimodality
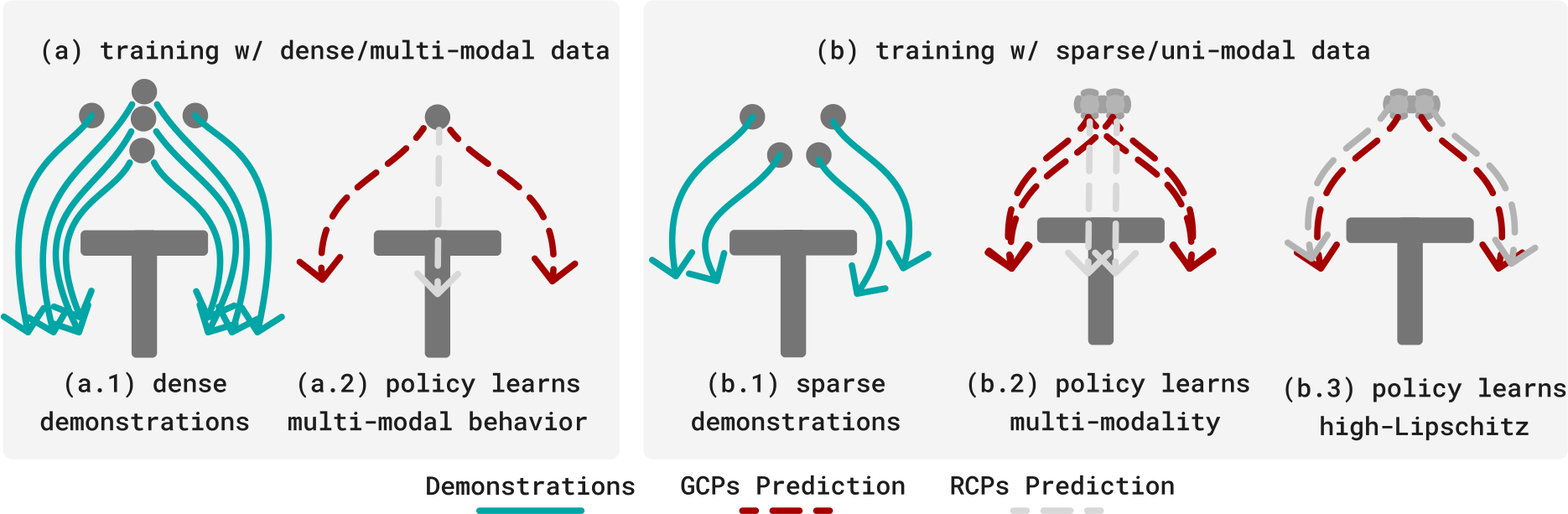

GCP가 iterative computation을 통해 더 복잡한 observation-to-action mapping을 표현할 수 있다는 주장도 있다. Deeper network이 higher Lipschitz function을 더 쉽게 표현할 수 있기 때문이다. 하지만 이 논문의 이론적, 실험적 분석은 이를 부정한다.
$\kappa$-log-concave 분포를 가정하면(다수의 classical unimodal 분포가 해당), flow의 Lipschitz constant는 ground-truth flow field의 Lipschitz constant에 의해 bound된다.
$\|\nabla_o \pi_\theta^*(z, o)\| \leq L \cdot \sqrt{1 + \kappa^{-1}}$
즉, integration step을 아무리 늘려도 observation-to-action mapping의 Lipschitz constant가 제한되어 있다. Multi-modality가 없는 unimodal 분포에서는 GCP가 RCP보다 본질적으로 더 expressive하지 않다.
실험적으로도 $y = \sin(1/x)$ 같은 high-Lipschitz function fitting에서 flow가 regression보다 나은 성능을 보이지 않았다. Initial noise를 고정하면($z=0$) flow policy는 regression과 완전히 동일한 mean-seeking behavior를 보인다.
Minimal Iterative Policy (MIP): Isolating the Source of GCPs' Success
A Taxonomy of GCPs
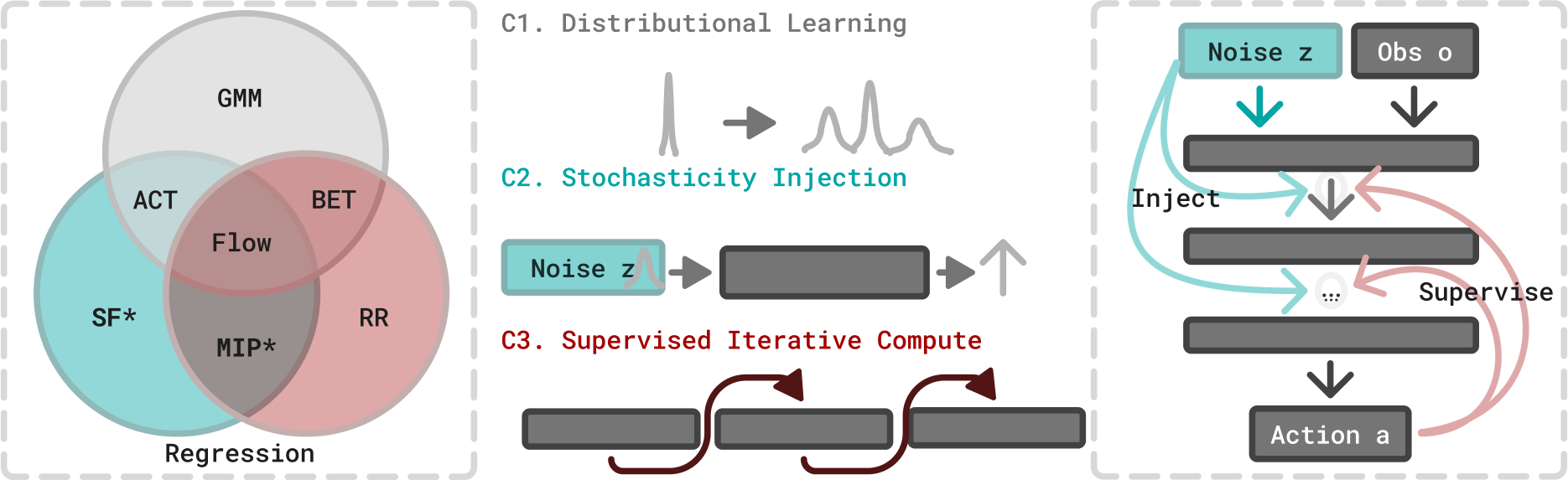
GCP의 design space를 세 가지 component로 분해한다.
- C1. Distributional Learning: action의 conditional distribution $a \sim \pi_\theta(o)$를 fitting하는 것. RCP와 같은 deterministic prediction($a = \pi_\theta(o)$)과 대비된다.
- C2. Stochasticity Injection: 학습 중 neural network 입력에 stochastic noise를 주입하는 것. Flow에서는 noise variable $z$가 이에 해당한다.
- C3. Supervised Iterative Computation (SIC): 이전 출력을 다시 네트워크에 넣어 반복적으로 정제하되, 각 step에서 독립적인 supervision signal을 제공하는 것. Flow에서는 각 interpolant time $t$에 대해 별도의 supervised flow field $b_t$를 학습한다.
이 taxonomy를 바탕으로, 각 component를 선택적으로 ablate하는 중간 단계 알고리즘들을 소개한다.
MIP: A Minimal Intermediate Between RCPs and GCPs
C2와 C3만 조합하여 Regression에서 Flow까지의 스펙트럼을 구성한다.
- Straight Flow (SF): C2만 포함. Flow field가 직선으로 constrained되어, single step으로 inference한다. RCP와의 유일한 차이는 학습 중 stochastic input $z$를 주입한다는 것이다.
- Residual Regression (RR): C3만 포함. Stochasticity 없이 iterative refinement만 수행한다.
- Minimal Iterative Policy (MIP): C2+C3를 결합. 단 2-step의 denoising만 수행하며, 학습 중에만 noise를 주입하고 inference는 deterministic이다.
MIP의 학습 objective는 다음과 같다.
$\pi_\theta^{\text{MIP}} \approx \arg\min_\theta \mathbb{E} \left[ \|\pi_\theta(o, I_0=0, t=0) - a\|^2 + \|\pi_\theta(o, I_{t_*}, t_*) - a\|^2 \right]$
여기서 $t_* = 0.9$이고, $z \sim \mathcal{N}(0, \mathbf{I})$이다. Inference 시에는 두 번의 forward pass만 수행한다.
$\hat{a}_0^{\text{MIP}} \leftarrow \pi_\theta^{\text{MIP}}(o, 0, t=0), \quad \hat{a}^{\text{MIP}} \leftarrow \pi_\theta^{\text{MIP}}(o, t_* \hat{a}_0^{\text{MIP}}, t_*)$
Components 2 and 3 Drive Performance: MIP Matches Flow
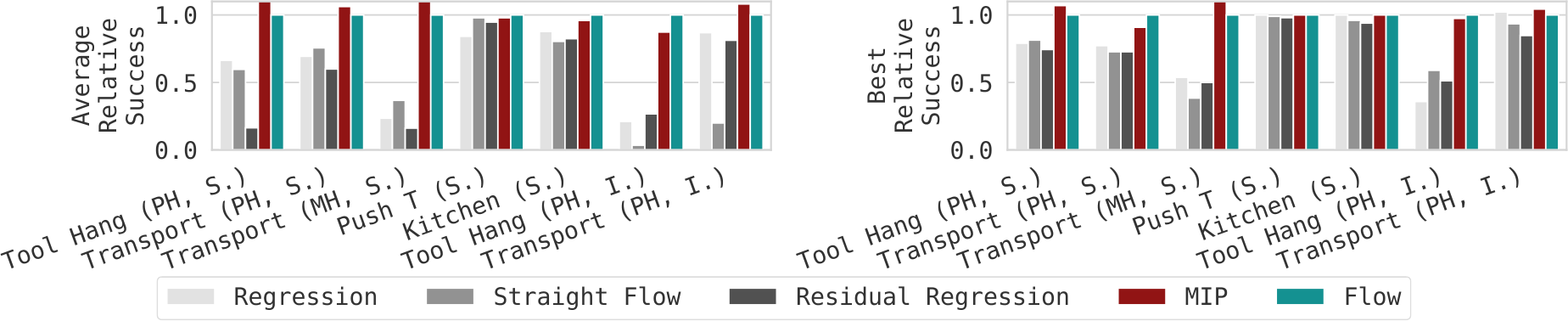

각 component의 기여를 체계적으로 ablation한 결과, SF(C2만)나 RR(C3만)은 단독으로 flow의 성능에 미치지 못한다. 반면 MIP(C2+C3)는 flow와 거의 동일한 성능을 달성한다. LIBERO multi-task 벤치마크에서도 MIP는 flow와 유사한 성능을 보이며, distributional learning(C1)이 가장 덜 중요한 요소임을 확인할 수 있다.
MIP Compares Favorably to Shortcut Policies
MIP는 shortcut model과 표면적으로 유사하다. 둘 다 few-step inference를 수행하기 때문이다. 하지만 핵심적인 차이가 있다. Shortcut model은 target distribution을 올바르게 학습하여 C1을 만족시키지만, MIP는 interpolant의 conditional mean을 예측하도록 학습되므로 C1을 만족시키지 않는다. MIP의 성능은 로봇 제어에서 full conditional distribution을 faithfully capture하는 것이 불필요함을 다시 한번 확인시켜 준다.
Consistency Trajectory Model(CTM)과의 비교에서, MIP는 대부분의 challenging task에서 best 또는 near-best 성능을 달성하면서도 CTM보다 학습 시간이 절반이다. CTM은 teacher flow model 대비 일정 수준의 성능 저하를 보이는 반면, MIP는 이러한 degradation이 없다.
Inductive Bias, Not Expressivity, Explains MIP's Performance
Manifold Adherence, Not Reconstruction, Drives Performance
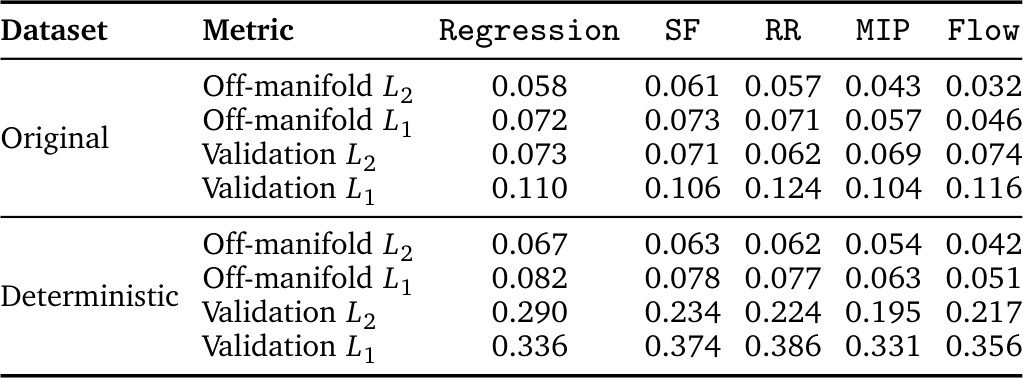
MIP와 flow가 expert data를 더 정확하게 근사하기 때문에 좋은 성능을 보이는 것일까? 실제로는 아니다. MIP, Flow, RCP 모두 validation set에서 비슷한 $L_2$ reconstruction error를 보인다. 즉 validation loss로는 성능 차이를 예측할 수 없다.
대신 이 논문은 manifold adherence라는 새로운 metric을 제안한다. Expert trajectory의 manifold에서 벗어난 정도를 측정하는 off-manifold norm으로, out-of-distribution state에서 action의 품질을 평가한다. MIP와 flow만이 낮은 off-manifold $L_2$ norm을 달성하며, SF는 이 이점을 보이지 않는다. 이는 supervised iterative computation(C3)이 expert action manifold에 대한 projection을 촉진하되, stochasticity(C2)가 있어야 compounding error를 완화할 수 있다는 것을 보여준다.
Stochasticity Stabilizes Iterative Computation
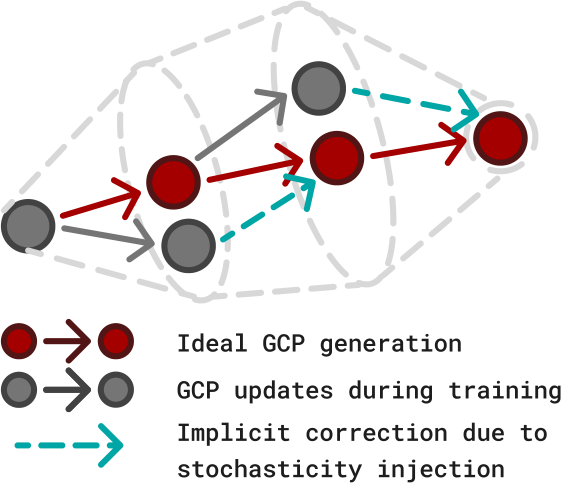
SF는 regression과 비슷한 성능을 보이는 반면, RR은 regression보다도 낮은 성능을 보인다. 이는 stochasticity 없는 sequential action generation이 매우 불안정하다는 것을 시사한다. Stochasticity injection은 generative process의 "coverage"를 제공한다. MIP의 첫 번째 step에서 action을 예측할 때, noise 주입이 초기 action $\hat{a}_0$의 coverage를 넓혀주어 더 많은 NFE에서 iterative improvement가 가능해진다. 이는 image augmentation이나 exploratory data collection과는 다른, iterative generative process 내부의 augmentation이다.
Architecture Remains Essential for Scaling
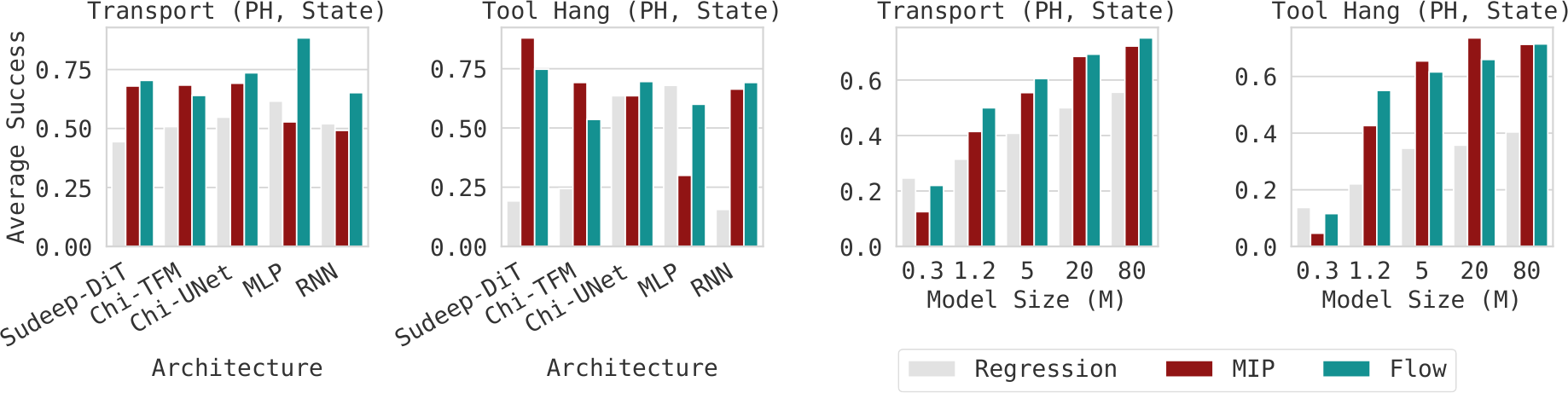
모든 방법이 model size 증가에 따라 scaling하지만, regression은 가장 작은 모델에서 상대적으로 좋은 성능을 보이다가 큰 모델에서는 flow와 MIP보다 poorly scale한다. 이는 supervised iterative computation이 더 많은 supervision step과 parameter를 통해 larger model을 더 효과적으로 활용하기 때문일 것이다. 또한 아키텍처 선택과 학습 방법 사이의 coupling이 강하여, 방법 간 비교 시 아키텍처를 통제하는 것이 매우 중요하다.
Conclusion
이 논문의 종합적인 평가는 generative modeling과 robotic control 사이의 근본적인 차이를 드러낸다. 제어에서는 exact data distribution을 fitting하는 것(C1)이 부차적이며, stochastic iterative computation(C2+C3)이 촉진하는 manifold adherence의 inductive bias가 핵심이다. 이 통찰은 GCP의 성공을 설명할 뿐 아니라, MIP 같은 간소화된 아키텍처의 설계를 가능하게 한다.
Theoretical Gaps
Manifold adherence가 closed-loop 성능의 유용한 proxy임을 경험적으로 확인했지만, MSE loss를 사용한 stochastic supervision이 왜 이런 behavior를 유도하는지에 대한 이론적 framework은 아직 없다. 이 이론적 기반을 마련하는 것이 향후 principled policy design의 핵심 과제이다.
Broader Applications
이 논문의 분석은 behavior cloning에 한정되어 있다. C2+C3의 이점이 RL fine-tuning, large-scale pretraining, long-horizon planning 같은 다른 세팅에서도 유지되는지는 열린 질문이다.