Introduction
3D visual grounding은 텍스트로 된 description을 그에 해당하는 3D object와 매칭하는 task이다. 3D visual grounding을 위해 풀어야 하는 문제는 아래와 같다.
- Object Recognition
- 물체간 위치관계 표현
MiKASA는 object recognition을 위해 scene-aware object encoder를 도입하였고, 물체간 위치관계를 표현하기 위해 multi-key-anchor 개념을 도입하였다.
또한 late fusion을 사용하여 모델의 decision proecss를 어느 정도 파악할 수 있도록 하였다.
Method
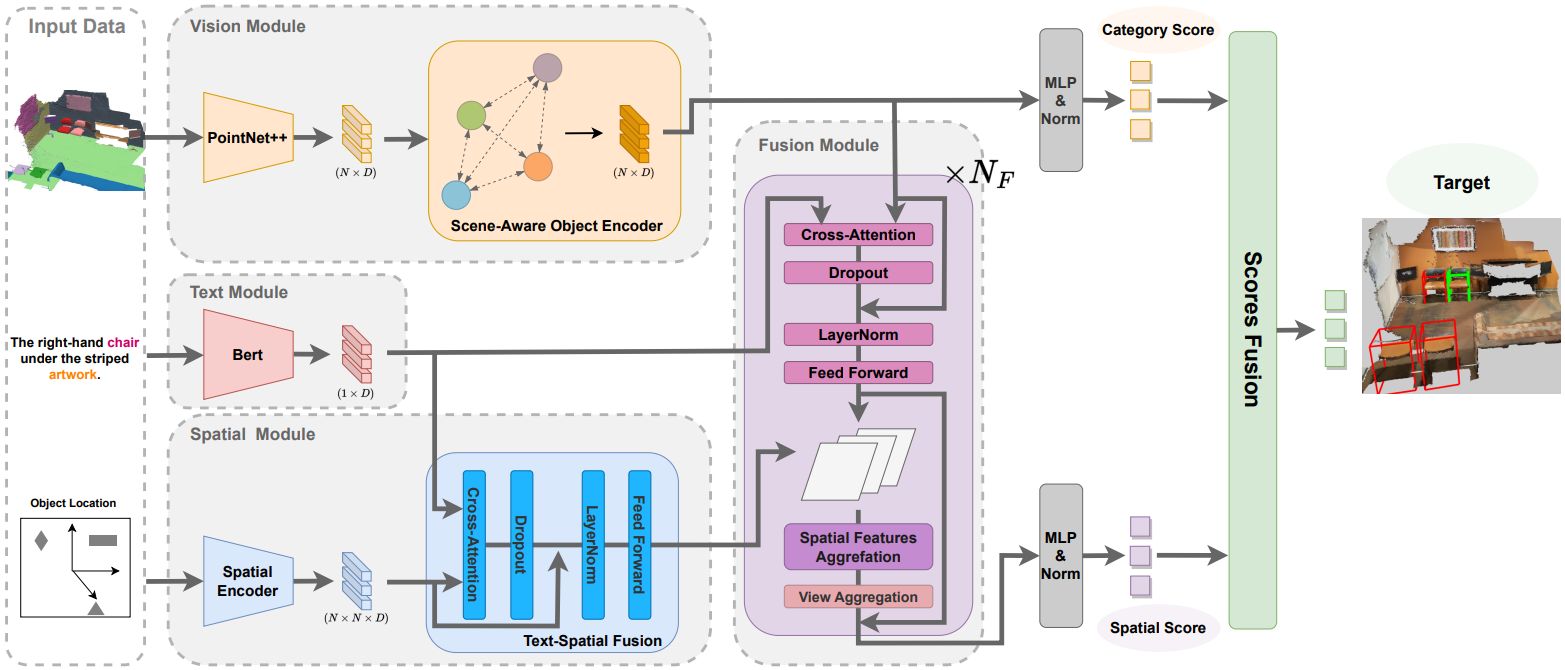
MiKASA는 위와 같이 vision module, text module, spatial module, fusion module로 구성된다.
- Vision module은 주변의 맥락을 포함하여 각 물체의 feature를 추출한다.
- Text module은 BERT를 이용하여 텍스트 query에 대한 feature를 추출한다.
- Spatial module은 각 물체간 위치관계를 feature로 변환한다.
- Fusion module은 세 모듈에서 나온 feature를 통합하여 최종 score를 계산한다.
Scene-Aware Object Encoder
먼저 point cloud에서 각 object별 feature를 얻는다. 이 과정은 설명이 나와 있지 않다. Object의 개수가 $N$이라면 각 object의 feature는 $O = \{ O_1, O_2, \dots, O_N \}$로 표현할 수 있다. 각 feature vector $O_i$는 크기가 $D$이다.
이후 self-attention을 이용하여 scene-aware object feature $O_i^{sa}$를 계산한다. 이 또한 $N \times D$의 dimension을 가진다.
Spatial Features Encoding
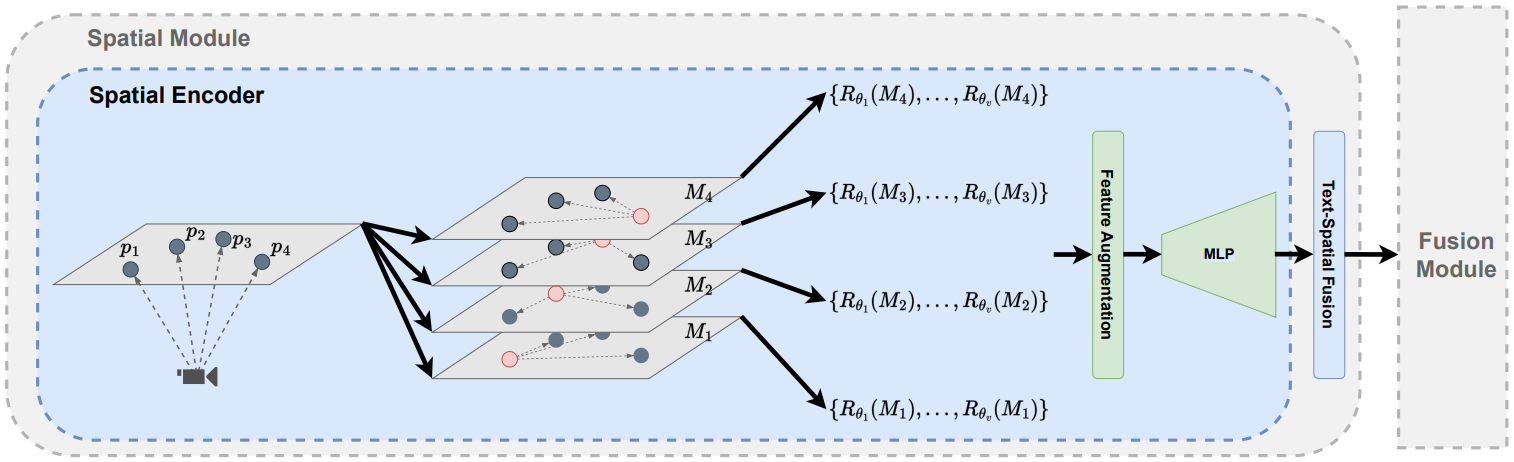
Spatial module에서는 물체간 위치관계를 명시적으로 feature로 변환한다.
우선 각 물체의 3차원 위치를 $P = \{ p_1, p_2, \dots,p_N \}$라 하자. 이후 $i$번째 물체와 나머지 물체들간의 좌표값의 차이를 계산하여 $M_i$라 하자. 즉, $M_i$는 3차원 좌표값의 차이에 해당하는 벡터를 $N-1$개 가지고 있다.
Data augmentation을 위해 여러 view에 대해 이 작업을 수행하여 $\{ R_{\theta_1}(M_i), \dots, R_{\theta_v}(M_i) \}$를 구한다. 이때 $R_{\theta}$는 특정 view에 대한 좌표계로의 변환을 의미한다.
이후 이렇게 계산한 각 view에서의 벡터를 통합하는 feature aggregation 과정을 거친다. 이 과정에 대해서는 설명이 나와 있지 않다.
이렇게 통합한 벡터를 MLP에 통과시켜 dimension을 $D$로 맞춰 준다. 총 dimension은 $N \times N \times D$가 된다.
Text-spatial fusion은 spatial module 안에서 진행된다. BERT를 통해 얻은 $1 \times D$ 크기의 feature와 이 단계에서 얻은 spatial feature를 cross-attention한다. 이후 layer normalization과 linear layer까지 통과시킨다. 이를 통해 텍스트 정보와 연관성이 있도록 spatial feature를 조정한다.
Multi-Modal Feature Fusion
Fusion model은 test-object fusion, object-spatial fusion, spatial feature aggregation, view aggregation의 4개 stage가 총 $N_F$번 반복되는 구조이다.
Text-object fusion은 앞서 설명한 text-spatial fusion과 유사하게 cross-attention을 사용한다. 이렇게 생성한 text-object feature는 앞서 설명한 각 object별 spatial map $M_i$에 더한다. 이렇게 얻은 feature는 각 object에 대한 특성과 물체간 상관관계에 대한 정보를 모두 담고 있다.
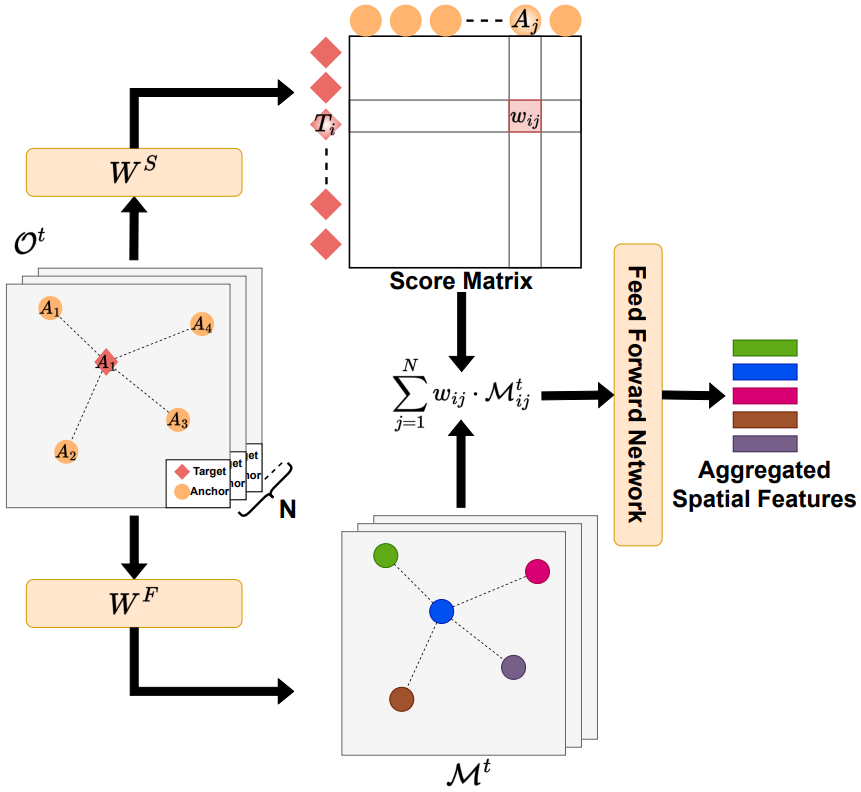
이후 spatial feature aggregation을 진행한다. 각 물체별 feature map에 대해 attention을 적용하여 특정 물체와 주변 물체간의 상관관계를 score matrix의 element $w_{ij}$로 표현한다. 이 과정을 각 view에 대해 진행하고 그 결과를 통합한다.
$O_i^{t+1} = O_i^t + \sum\limits_{j=1}^{N} w_{ij} \cdot \mathcal{M}_{ij}^t, \quad \forall i \in \{1, 2, \dots, N\}$
마지막으로 위 식을 이용하여 최종 object-spatial feature $\mathcal{O}$를 업데이트한다.
Multi-Modal Predictions Fusion
MiKASA는 category score와 spatial score를 별도로 계산하여 모델의 작동 방식을 이해하기 쉽도록 했다. Category score는 어떤 물체가 텍스트가 찾는 물체인지를 판별하고, spatial score는 어떤 물체가 텍스트가 설명하는 위치에 있는지를 판별한다.
$\mathcal{P} = \lambda \cdot g(f_1(X; \theta_1)) + \mu \cdot g(f_2(X; \theta_2))$
각 score는 위 식과 같이 MLP $f_1, f_2$를 이용해 계산되는데, 평균과 분산을 맞추기 위해 normalization $g$를 거친다. 이후 hyperparameter $\lambda, \mu$를 이용해 두 score를 weighted sum한다. 최종적으로 점수가 가장 높은 object를 선택한다.
Loss Function
$\mathcal{L} = L_{\text{ref}} + \alpha L_{\text{text}} + \beta L_{\text{obj}} + \gamma L_{\text{obj.scene}}$
MiKASA에 사용된 loss function은 위와 같다. $L_{\text{ref}}$는 최종 결과에 대한 loss, $L_{\text{text}}$는 문장에서 target object를 찾는 과정에 대한 loss, $L_{\text{obj}}$는 전체 object에 대한 categorization에 대한 loss, $L_{\text{obj_scene}}$은 scene-aware object encoder를 거친 이후의 object categorization에 대한 loss이다.
Experiment
Experimental Setup
데이터셋은 NR3D와 SR3D를 사용하였다. Text encoder는 BERT, object encoder는 PointNet++를 사용하였다. Metric으로는 정답 bounding box를 고른 scene의 비율을 사용하였다.
Baseline Comparison
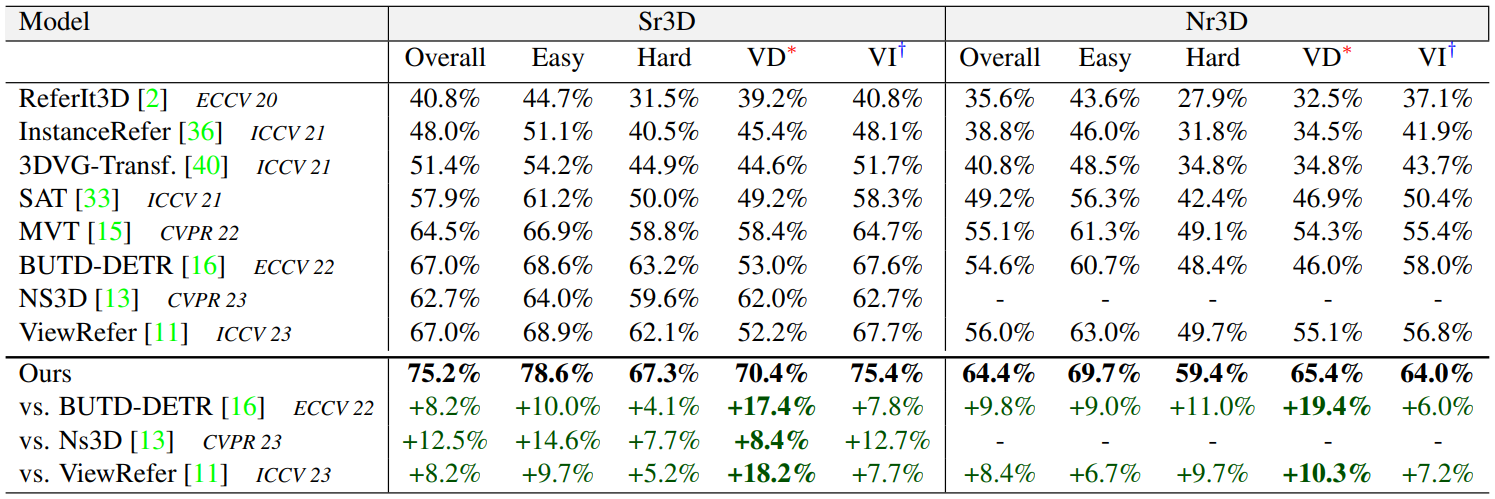
Baseline 모델들과 성능을 비교한 결과는 위와 같다.

Qualitative result는 위와 같다. Category score 또는 spatial score만 사용했을 때와 최종 모델의 inference 결과를 비교해 볼 수 있다.
Conclusion
MiKASA는 scene-aware object encoder와 multi-key-anchor를 이용하여 3D 환경에서의 object recognition과 spatial understanding을 수행한 모델이다. Scene-aware object encoder는 category score, multi-key-anchor는 spatial score를 계산하는 역할을 하고, 두 score를 합쳐 최종적으로 SOTA 성능의 3D visual grounding 성능을 보여 주었다.