Introduction
자연어를 3D scene understanding에 사용함으로써 VR, 자율주행 등 3D 공간상의 task를 훨씬 직관적으로 수행할 수 있다. 기존의 모델들은 NeRF 또는 3DGS와 CLIP을 함께 사용하여 open-vocabulary segmentation을 수행한다.
그러나 기존 방법들은 CLIP feature를 마스킹된 물체별 이미지들에서만 추출하기 때문에 feature가 물체 경계 내부의 local 정보만 담고 있고 global context에 대한 이해가 부족하다. 또한 LERF와 LangSplat 등은 2D로 렌더링했을 때의 semantic consistency만 보기 때문에 실제 3D 상에서 물체의 표면과 semantic이 잘 align되지 않는다. 이로 인해 texture가 부족하거나 너무 복잡한 scene에서 잘 동작하지 못한다는 문제가 있다.
LangSurf는 semantic feature와 물체의 실제 표면과의 alignment를 우선시한다. 또한 물체별 feature가 조금 더 이미지 전체적인 global context를 갖게 하기 위해 Hierarchical-Context Awareness Module을 도입했다. 또한 geometry와 semantic을 joint training하고 semantic grouping strategy를 사용하는 등 정확도를 개선하였다.
Preliminaries
LangSplat에서는 각 가우시안에 크기가 3인 language feature vector $\mathbf{f}^{lang} \in \mathbb{R}^3$ 를 할당하여 semantic을 학습한다. RGB color와 semantic은 아래의 수식을 통해 각각 2D로 렌더링될 수 있다.
$\begin{align*} \mathbf{C}(v) & = \sum\limits_{i \in \mathcal{N}} c_i \alpha_i \prod\limits_{j=1}^{i-1} (1 - \alpha_j) \\ \mathbf{F}(v) & = \sum\limits_{i \in \mathcal{N}} f_i \alpha_i \prod\limits_{j=1}^{i-1} (1 - \alpha_j) \end{align*}$
Methodology
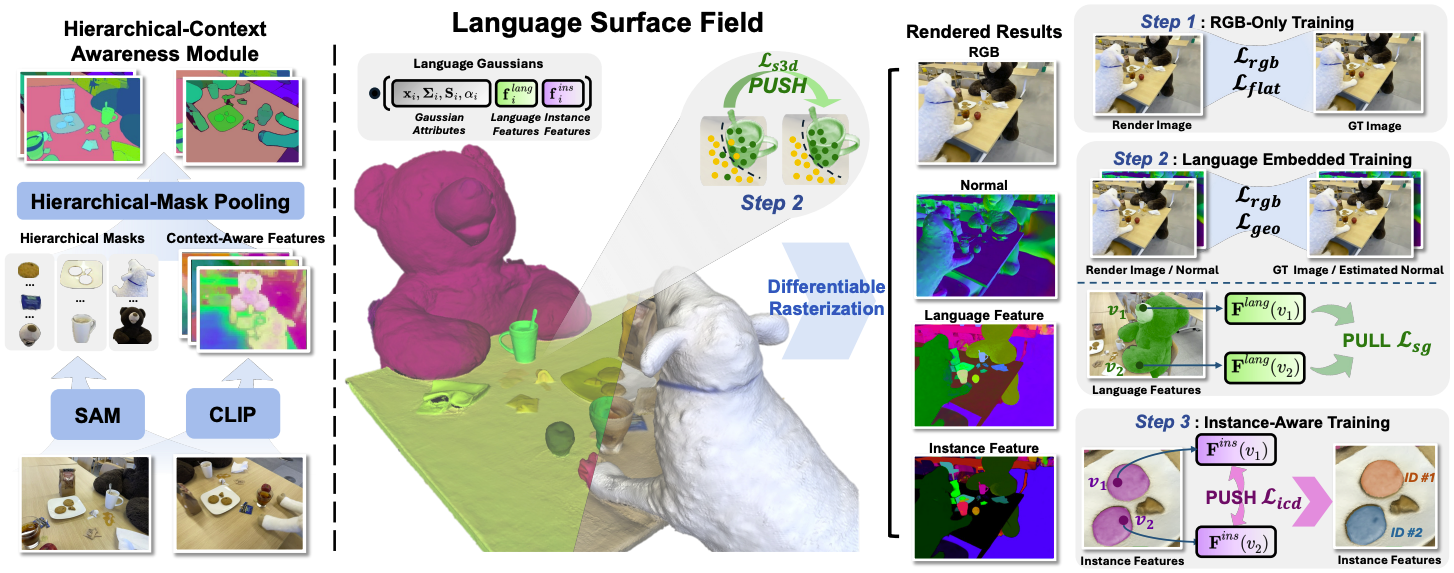
Input 2D image를 $\{ \mathbf{I}_i \in \mathbb{R}^{3 \times H \times W} \}$라 할 때, LangSurf의 주된 목표는 3D scene을 language-embedded gaussian들로 표현하는 것이다. 이때 각 가우시안은 $\{ (\mathbf{x}_i, \boldsymbol{\Sigma}_i, \mathbf{S}_i, \alpha_i, \mathbf{f}_i^{lang}, \mathbf{f}_i^{ins}) \}$로 표현된다. $\mathbf{f}^{ins} \in \mathbb{R}^3$는 instance feature이다.
Hierarchical-Context Awareness Module
이전 모델들이 물체별 SAM mask만으로 feature를 얻은 것과 달리, LangSurf는 우선 input image $\mathbf{I}_i$ 전체를 encoder에 넣어 feature map $\{ \mathbf{L}_i^{lang, h} \mid h = (s, m, l) \} \in \mathbb{R}^{D \times H \times W}$ 을 생성한다. 이는 pixel별 feature로, 전체적인 context를 담당한다.
또한, bear nose와 bear의 예시처럼 하나의 물체가 여러 scale에서 서로 다른 semantic에 해당하는 문제를 해결하기 위해 Hierarchical-Mask Pooling을 도입한다. 우선 각 이미지에 대한 SAM mask를 $\mathbf{M}_i^{h, j}, \ j = 1, \cdots, M$라 하자. 이때 $i$는 각 이미지의 index, $h = \{s, m, l\}$은 SAM mask의 hierarchy (small, medium, large), $j$는 각 hierarchy에서의 각각의 mask에 대한 index이다.
$\mathbf{L}^{lang, h}(v) = \cfrac{\sum \mathbf{L}^{lang}(v) \cdot \mathbf{M}^h(v)} {\sum \mathbf{M}^h(v)}, \quad h = \{s, m, l\}$
Masked average pooling은 위 식과 같다. Mask 경계 내부의 픽셀에 대한 feature들을 모두 평균내는 방식이다. $v$는 hierarchy $h$에서의 각 mask 내부의 픽셀들에 해당한다. 이 과정을 통해 mask 내부 픽셀들끼리 semantic consistency를 유지할 수 있도록 한다.
이때, 가우시안 내에서는 고차원 벡터인 $\mathbf{L}^{lang, h}(v)$을 직접 학습하지 않고 LangSplat과 같은 방식으로 autoencoder를 써서 차원을 낮춘 $\mathbf{H}^{lang, h}(v)$를 학습한다.
Language-Embedded Surface Field Training
LangSurf의 학습은 아래의 3단계로 이루어진다.
- RGB만으로 초기 학습을 진행한다.
- Geometry와 semantic을 모두 사용하여 joint training을 진행한다.
- Language feature를 통해 instance feature $\mathbf{f}^{ins}$를 초기화하고 이를 학습한다.
첫 단계에서는 우선 RGB만을 이용하여 기초적인 가우시안의 형태를 잡는다.
$\begin{align*} \mathcal{L}_{rgb} & = \|\mathbf{C}_i - \mathbf{I}_i\|_1, \\ \mathcal{L}_{flat} & = \|\min (s_1, s_2, s_3)\|_1 \end{align*}$
$\mathcal{L}_{rgb}$는 기존 3DGS의 loss이고 $\mathcal{L}_{flat}$는 가우시안이 납작해지도록 하는 loss이다.
두 번째로는 geometry와 semantic을 모두 사용하여 joint training을 진행한다. Geometry regularization constraint로는 $\mathcal{L}_{geo}$를 사용한다. Semantic loss로는 $\mathbf{F}^{lang}$과 $\mathbf{H}^{lang}$ 사이의 L2 loss와 함께 Semantic Grouping loss $\mathcal{L}_{sg}$를 사용한다.
$\mathcal{L}_{sg} = \cfrac{1}{M} \sum\limits_{j=1}^{M} \sum\limits_{v_1, v_2 \in \mathcal{M}_j} \| \mathbf{F}^{lang}(v_1) - \mathbf{F}^{lang}(v_2) \|_2$
$\mathcal{L}_{sg}$는 렌더링 시 한 mask 안에 있는 픽셀들은 서로 같은 semantic feature $\mathbf{F}^{lang}$를 갖도록 유도하는 loss이다.
이때 렌더링된 feature에 대해서만 loss를 적용하면 실제 3D 상에서 가우시안의 위치가 부정확하더라도 알 수 없기 때문에 Spatial-Aware Semantic Supervision $\mathcal{L_{s3d}}$를 함께 사용한다.
$\mathcal{L}_{s3d} = \sum\limits_{j=1}^{N} \sum\limits_{k=1}^{N_k} \mathbf{f}_j^{lang} \cdot ( \log \cfrac{\mathbf{f}_j^{lang}}{\mathbf{f}_k^{lang}} )$
위 식과 같이 KL-divergence를 이용하여 각 가우시안과 그 근처 k개의 가장 가까운 가우시안들의 feature vector를 align한다. 이는 Gaussian Grouping과 유사한 방법이다.
마지막으로 instance-aware training을 진행한다. 이는 같은 카테고리에 여러 물체가 속하는 경우를 처리하기 위해서이다. 이를 위해 instance feature $\mathbf{f}^{ins}$를 각 가우시안에 추가한다. 초기값은 $\mathbf{f}^{lang}$과 동일하다.
$\mathbf{z}_i^{ins} = \cfrac{1}{|\mathbf{M}_i|} \sum\limits_{v \in \mathbf{M}_i} \mathbf{F}_i^{ins}(v)$
우선 위 식을 이용해 각 mask에 속한 픽셀의 렌더링된 instance feature를 평균낸다.
$\mathcal{L}_{icd} = \sum\limits_{j=1}^{M} \sum\limits_{k \neq j}^{M} \text{ReLU} ( D_{\min} - \|\mathbf{z}_j^{ins} - \mathbf{z}_k^{ins}\|_2 )$
이후 위 식과 같이 Instance Contrastive Decomposition supervision $\mathcal{L}_{icd}$를 도입하여 서로 다른 instance feature들이 충분히 떨어져 있도록 유도한다. 이때 $D_{\min}$은 instance간 최소 거리이다. 이 단계에서는 다른 파라미터들은 freeze하고 instance feature만 training한다.
Experiments
Implementation Details
각 image에서 feature를 추출하기 위해 OpenSeg의 backbone을 사용하였고, text encoder로는 CLIP을 사용하였다. 또한 2D mask를 얻기 위해 SAM을 사용하였다. 단계별 training 횟수로는, 1단계에서 7000 iterations, 2단계에서 23000 iterations, 3단계에서 10000 iterations 학습하였다.
데이터셋으로는 LERF와 ScanNet을 사용하였다. Metric으로는 2D에서는 mIoU와 mAcc, 3D에서는 F-score를 사용하였다.
Results of Open-Vocabulary Query Tasks
2D와 3D에서 각각 language query를 통해 open-vocabulary segmentation을 진행하였다.

LERF 데이터셋에서의 2D segmentation 결과를 보면 LangSurf의 수치가 가장 좋은 것을 알 수 있다.

Qualitative result를 보아도 LangSurf의 결과가 GT에 가장 가까운 것을 볼 수 있다.
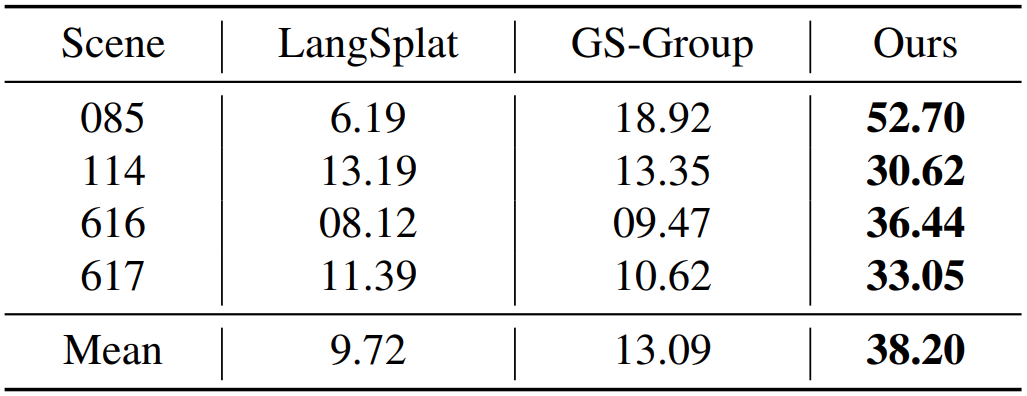
ScanNet 데이터셋에서 3D segmentation 결과를 보면 LangSurf가 LangSplat이나 Gaussian Grouping에 비해 25% 이상 F-score 값이 좋은 것을 볼 수 있다.
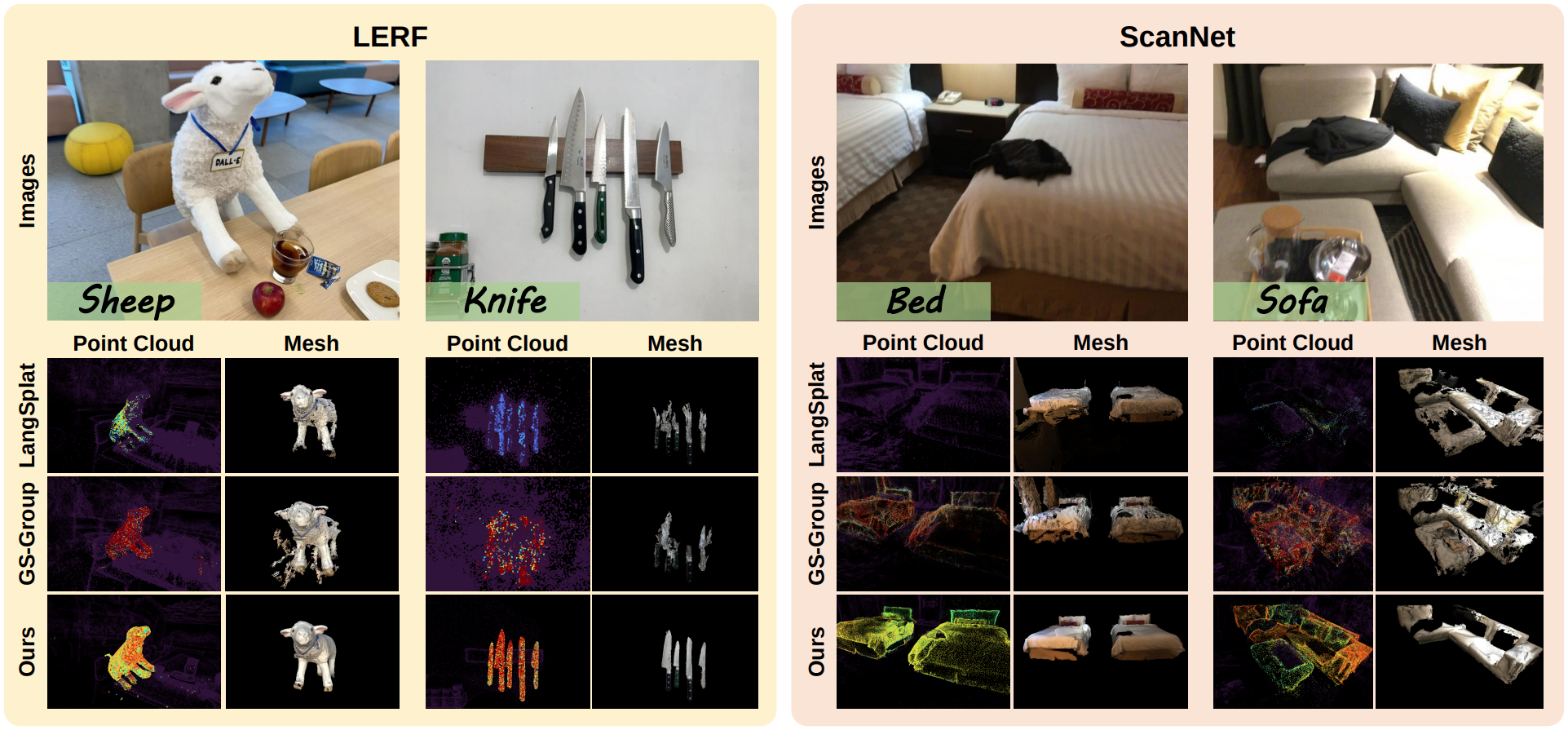
Point cloud와 mesh로 3D segmentation 결과를 비교해 보아도 LangSurf가 LangSplat이나 Gaussian Grouping에 비해 더욱 깔끔한 표면을 보이는 것을 알 수 있다.
Ablation Study
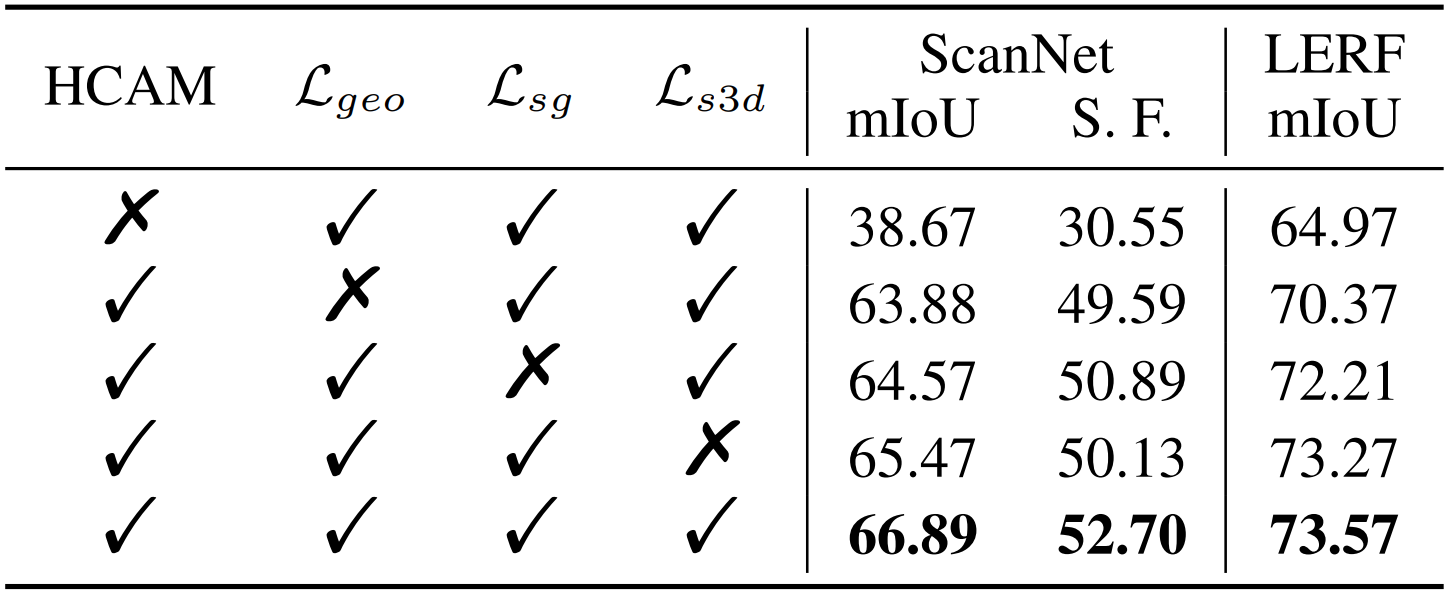
위 ablation study 결과를 보면 Hierarchical-Context Awareness Module의 영향이 가장 큰 것을 볼 수 있는데, contextual information을 추출하는 것이 정확한 segmentation을 하는 데 큰 영향을 줬다고 해석할 수 있다.
Conclusion
기존의 3D segmentation 모델이 2D rendered view에서의 결과에만 집중한 것과는 달리, LangSurf는 geometry와 semantic 정보를 모두 사용하여 language field가 실제 물체의 표면에 잘 align되도록 하였다. 또한 Hierarchical-Context Awareness Module은 가우시안 학습을 위해 context-aware feature를 추출할 수 있다.
이러한 contribution 덕분에 LangSurf는 2D와 3D segmentation 모두에서 SOTA를 달성하였고, object removal, editing 등 downstream task 성능도 크게 개선하였다.