Introduction

3D language field를 모델링하는 것은 robot navigation, manipulation, autonomous driving 등 다양한 task에 중요하게 쓰일 수 있다. 하지만 지금까지의 모델들은 속도와 정확도에 상당한 한계가 있었는데, 이를 3D modeling 방식과 rendering target, 이 두 가지의 측면에서 살펴보자.
먼저 기존의 NeRF 기반 방식은 강력한 3D modeling 방식이지만 속도 측면에서 한계가 있다. 또한 rendering target으로는 CLIP embedding을 사용하는 방식이 있다. 즉 2D RGB image를 렌더링하는 것처럼 각 픽셀이 CLIP embedding인 image를 렌더링하는 것이다. 그런데 CLIP 자체는 object를 구분하는 능력이 없기 때문에 추가적인 과정을 거쳐 물체를 구분해야 했는데, 이로 인해 속도와 정확도 모두 떨어지는 한계가 있다.
LangSplat에서는 NeRF 대신 3D Gaussian Splatting을 사용하여 속도를 향상시켰다. 이때 CLIP embedding을 각각의 가우시안에 직접 저장하는 것이 아니라, encoder를 거쳐 저차원으로 projection된 vector를 저장하여 memory cost를 줄였다.
또한 object를 빠르고 정확하게 구분하기 위해, LangSplat은 SAM을 이용한다. SAM이 제공하는 object segmentation mask를 이용하여 각 object별로 명확히 구분된 CLIP embedding을 얻을 수 있다. 이를 통해 전체적인 모델의 정확도를 향상시켰다.
Related Work
SemanticNeRF는 NeRF 프레임워크 안에 semantic 정보를 추가한 모델이다. LERF는 처음으로 CLIP embedding을 NeRF 프레임워크에 사용하여 open-vocabulary 3D query를 가능하게 하였다. LERF에는 DINO feature도 사용되어 성능을 향상시켰다.
Proposed Approach
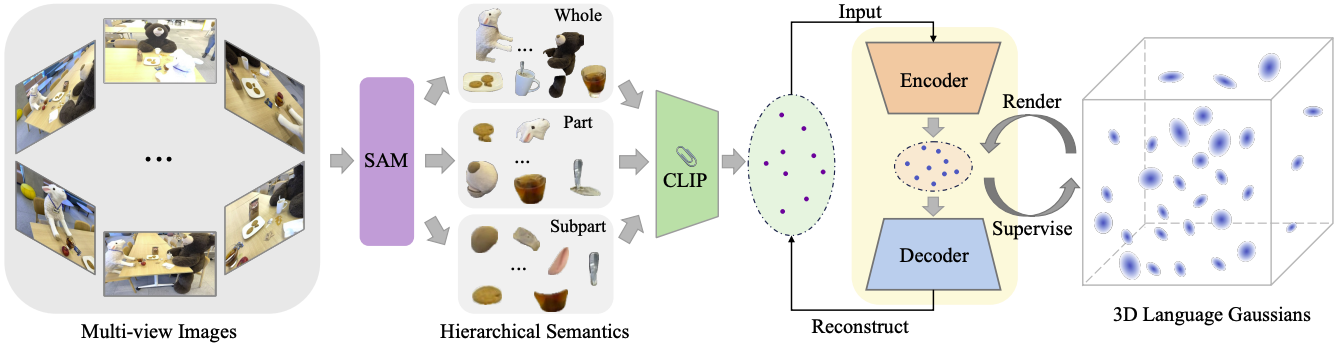
Revisiting the Challenges of Language Fields
앞서 Introduction에서 언급한 것처럼, CLIP 자체는 전체 이미지를 입력으로 받는 모델로, object를 구분하는 능력이 없다. 이를 해결하기 위해 기존 모델들은 이미지를 patch로 잘라 각 patch를 CLIP embedding으로 변환하였다. 그런데 object의 위치를 알고 patch를 자르는 것이 아닌, patch안에 물체가 우연히 속하기를 바라는 느낌이 더 강하다.
또한 공간 상의 한 점은 속한 물체를 어디까지로 보느냐에 따라 다른 semantic을 가질 수 있다. 예를 들어, 고양이 귀 위의 점은 귀, 머리, 고양이의 세 가지 semantic에 속할 수 있고, 이 세 가지 language query에 모두 activate되어야 한다. 이를 해결하기 위해 기존에는 다양한 크기의 patch를 이용하는 방식을 사용했다.
이러한 multi-scale patch 방식은 두 가지 문제점을 가지고 있다. 첫째, 한 patch 안에 여러 물체가 있을 수 있다는 것인데, 이 경우 CLIP embedding은 여러 물체의 semantic을 동시에 포함하게 되어 물체의 구분이 불명확해진다. DINO feature를 함께 사용하는 모델도 있지만, 이 방법 또한 만족스러운 결과를 내지는 못했다. 둘째, 이러한 방식은 inference 시 한 번에 모든 scale에 대해 한번에 렌더링을 진행하고 그 중 최적의 scale을 선택해야 했기 때문에 속도가 매우 느리다는 문제도 있었다.
Learning Hierarchical Semantics with SAM
SAM은 이미지 내의 물체를 구분하는 segmentation mask를 높은 정확도로 제공하는 모델로, whole, part, subpart의 세 가지 hierarchical level에 대한 mask를 각각 제공한다. LangSplat은 이 SAM을 이용하여 각 픽셀이 어떤 object에 속하는지 명확히 구분한다.
SAM을 통해 얻은 whole, part, subpart mask를 각각 $M^w_0, M^p_0, M^s_0$라 하자. 이때 각 계층별로 중복된 mask나 stability score가 낮은 mask를 제거하여 $M^w, M^p, M^s$를 얻는다. 이렇게 얻은 mask를 이용하여 각 object별로 CLIP embedding을 얻고, 해당 object에 속하는 pixel들에 이를 할당해줄 수 있다.
$L_t^l(v) = V(I_t \odot M^l(v)), \quad l \in \{s, p, w\}$
이 과정을 수식으로 표현하면 위와 같은데, $L_t^l(v)$는 픽셀 $v$에 대한 $l$ 계층의 CLIP embedding, $I_t$는 $t$ 번째 frame 이미지, $M^l(v)$는 $v$ 픽셀이 속한 $l$ 계층의 mask, $V$는 CLIP encoder를 의미한다. $\odot$ 연산은 element-wise multiplication로, mask를 이용하여 해당 object에 속하는 pixel만을 추출하는 과정을 의미한다.
이러한 과정을 통해 이미지의 각 픽셀은 속한 object에 해당하는 CLIP embedding을 가지게 된다.
3D Gaussian Splatting for Language Fields
$G(x) = \exp\left(-\cfrac{1}{2}(x - \mu)^\top \Sigma^{-1} (x - \mu)\right)$
3D Gaussian Splatting에서는 각 가우시안을 위와 같이 평균 $\mu$와 공분산 $\Sigma$로 정의한다. 이 가우시안들을 학습하기 위해 아래와 같이 tile-based rasterizer를 사용한다.
$C(v) = \sum\limits_{i \in \mathcal{N}} c_i \alpha_i \prod\limits_{j=1}^{i-1} (1 - \alpha_j)$
이때 alpha는 투명도가 적용된 2D에서의 가우시안 값이다.
LangSplat에서는 각각의 가우시안에 3개의 계층별 language embedding $\{f^s, f^p, f^w\}$를 추가한다. 이 language embedding의 렌더링은 컬러 렌더링과 동일한 식을 사용한다.
$F^l(v) = \sum\limits_{i \in \mathcal{N}} f^l_i \alpha_i \prod\limits_{j=1}^{i-1} (1 - \alpha_j), \quad l \in \{s, p, w\}$
위 식의 결과 $F^l(v)$는 픽셀 $v$에 대해 렌더링된 $l$ 계층의 language embedding을 의미한다.
Scene-Specific Language Autoencoder
고차원의 CLIP embedding을 각각의 가우시안에 모두 할당하는 것은 메모리나 연산량 측면에서 매우 비효율적이다. 따라서 LangSplat은 고차원의 CLIP embedding을 저차원으로 projection한 후 각각의 가우시안에 할당한다.
이러한 projection은 scene-wise language autoencoder를 이용해 이루어진다. 이 autoencoder는 가우시안 학습 전에 먼저 학습되는데, SAM을 통해 얻은 mask를 이용해 학습된다. CLIP은 scene에 관계없이 작동하기 때문에 dimension이 큰 반면 각 scene별로 등장하는 object는 그 수가 제한적이기 때문에 이러한 compression이 가능하다.
$\mathcal{L}_{ae} = \sum\limits_{l \in \{s, p, w\}} \sum\limits_{t=1}^T d_{ae}(\Psi(E(L^l_t(v))), L^l_t(v))$
위 식에서 $L^l_t(v)$ 각 segmentation mask에 대한 CLIP embedding이다. Encoder $E$는 CLIP embedding $L_t^l(v) \in \mathbb{R}^D$를 scene-specific latent feature $H_t^l(v) \in \mathbb{R}^d \ (d \ll D)$로 변환하는 네트워크이고, decoder $\Psi$는 CLIP embedding을 복원하는 네트워크이다. $d_{ae}$는 encoder와 decoder를 거쳐 복원된 embedding과 원래 embedding 사이의 거리를 의미하고, L1 loss와 cosine distance를 함께 사용한다. $d$는 실험적으로 3으로 설정되었다.
Autoencoder가 학습되면, 모든 CLIP embedding은 scene-specific latent feature로 projection된 후 가우시안 학습에 사용된다. $d$는 실험적으로 3으로 설정되었다.
$\mathcal{L}_{lang} = \sum\limits_{l \in \{s, p, w\}} \sum\limits_{t=1}^T d_{lang}\left(F^l_t(v), H^l_t(v)\right)$
가우시안 학습에 사용되는 loss는 위와 같다. 앞선 수식에서 렌더링된 language embedding $F^l_t(v)$과 CLIP embedding에서 직접 projection한 embedding $H^l_t(v)$을 비교한다. $d_{lang}$는 두 embedding 사이의 distance function이다.
Inference 시에는 렌더링된 language embedding $F^l_t(v)$을 decoder $\Psi$에 통과시켜 CLIP embedding으로 복원한다. 이를 통해 open-vocabulary query가 가능하다.
Open-Vocabulary Querying
CLIP 모델은 image-to-text alignment가 잘 되어 있기 떄문에 LangSplat은 open-vocabulary query를 사용할 수 있다. Text query가 들어오면, 이를 CLIP embedding $\phi_{qry}$로 변환한 후 각각의 렌더링된 language embedding $\phi_{img}$와 비교하여 relevancy score를 계산한다.
$\min\limits_i \cfrac{\exp(\phi_{\text{img}} \cdot \phi_{\text{qry}})}{\exp(\phi_{\text{img}} \cdot \phi_{\text{qry}}) + \exp(\phi_{\text{img}} \cdot \phi_{\text{canon}}^i)}$
Relevancy score는 위와 같이 정의되는데, 이때 $\phi_{\text{canon}}^i$은 predefined canonical phrase인 {"object", "things", "stuff", "texture"} 중 $i$번째 단어를 CLIP embedding으로 변환한 것이다.
이때 language feature의 계층이 3가지가 있기 때문에 relevancy score도 총 3개가 나오게 되는데, 그 중에서 가장 relevancy score가 높은 계층을 고른다.
3D object localization task를 수행할 때는 단순히 relevancy score가 가장 높은 점을 고르면 되고, 3D semantic segmentation task를 수행할 때는 특정 threshold보다 높은 점들만을 골라 object mask를 예측한다.
Experiments
Settings
데이터셋으로는 LERF dataset과 3D-OVS dataset을 사용했고, 평가 지표로는 mIoU를 사용했다.
CLIP 모델로는 OpenCLIP ViT-B/16, SAM 모델로는 ViT-H를 사용했다. 3DGS 학습 시에는, 먼저 기본 가우시안을 30,000 iteration 동안 학습시킨 후, 다른 파라미터를 전부 고정시킨 뒤 language feature만 30,000 iteration 추가로 학습시켰다. Autoencoder는 MLP 구조로 구현되었다.
Results on the LERF dataset

왼쪽 표는 localization result, 오른쪽 표는 semantic segmentation result를 나타낸다. 둘 모두에서 baseline을 뛰어넘는 결과가 나온 것을 알 수 있다.

렌더링된 이미지를 보아도 LangSplat이 훨씬 깔끔한 경계선으로 정확한 segmentation을 하는 것을 확인할 수 있다.
Results on the 3D-OVS dataset
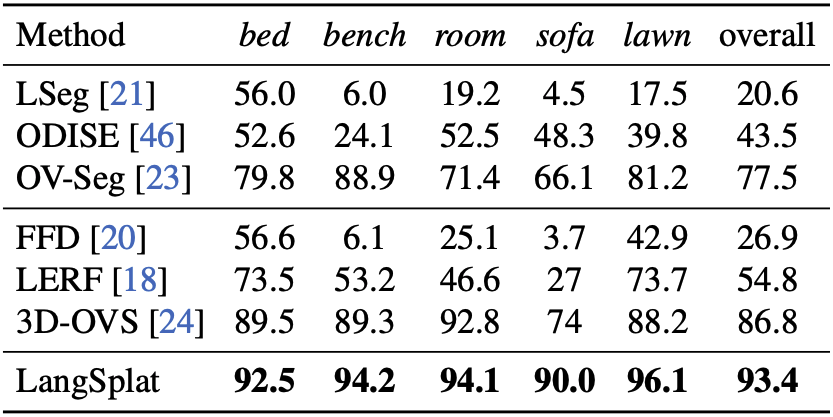
LangSplat은 평균 IoU 93.4%로 다른 모든 모델보다 높은 성능을 내는 것을 확인할 수 있다.
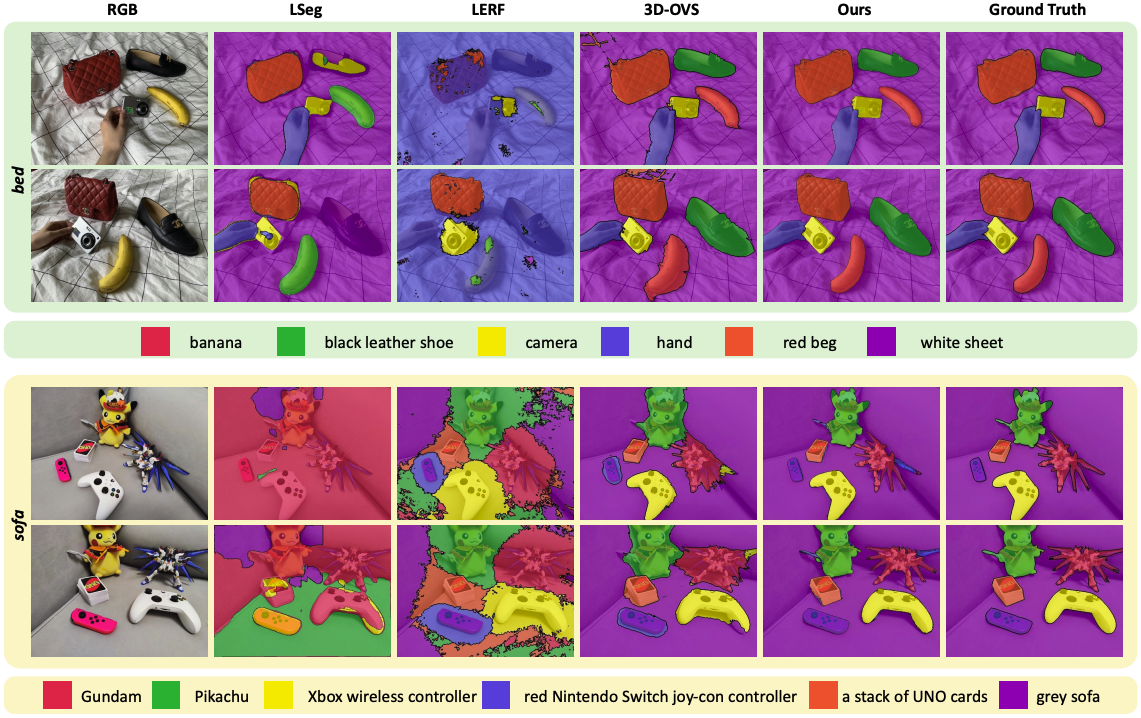
LangSplat이 다른 모델들보다 더욱 정확하게 segmentation map을 예측하는 것을 볼 수 있다.
Conclusion
LangSplat은 3DGS의 빠른 렌더링 속도와 SAM의 정확한 2D segmentation mask를 이용하여 open-vocabulary 3D localization 및 segmentation task에서 속도와 정확도를 크게 개선시킨 모델이다.