Introduction
Action-conditioned video prediction model(world model)은 로봇 조작 분야에서 큰 가능성을 보여왔지만, 기존 접근법들은 연산 비용이 높고 장기간 rollout에서 물리적으로 일관된 상호작용을 유지하지 못하는 한계가 있다. Multi-step diffusion process에 의존하는 모델은 실시간 상호작용이 불가능할 정도로 느리고, 누적된 prediction error로 인해 장기간 rollout이 불안정하다.
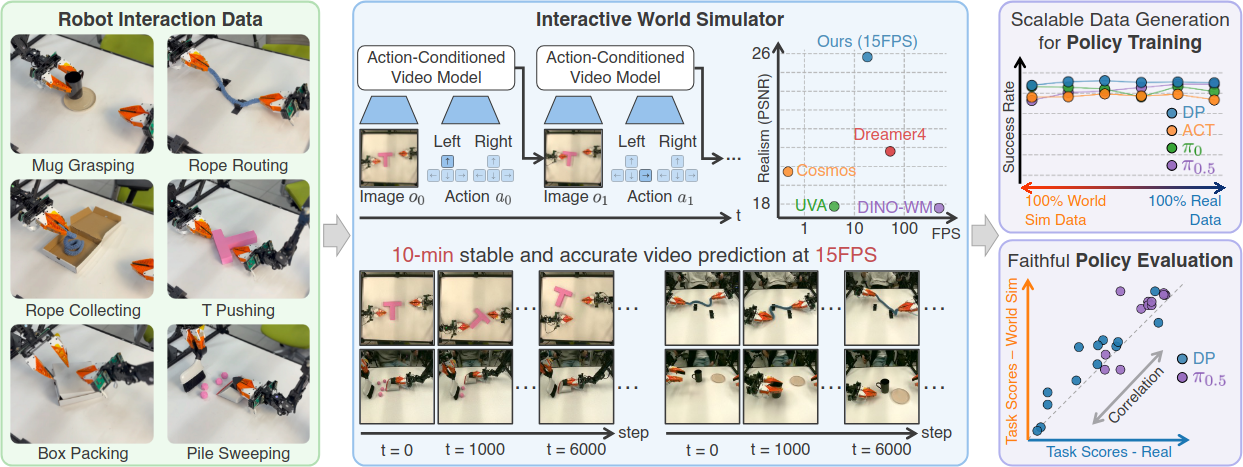
본 논문에서는 Interactive World Simulator를 제안한다. 고차원 이미지를 저차원 latent representation으로 인코딩하고, latent space에서 prediction하여 빠르고 안정적인 시뮬레이션을 가능하게 한다.
제안된 world simulator는 단일 RTX 4090 GPU에서 15 FPS로 10분 이상 안정적으로 동작하며, rigid object, deformable object, object pile 등 다양한 물체와의 복잡한 물리적 상호작용을 포함하는 작업에서 기존 방법들을 능가한다. 주요 기여는 다음과 같다:
- 10분 이상의 안정적인 장기간 rollout을 지원하는 interactive action-conditioned video prediction model 제안
- 물리적 로봇 없이도 imitation learning을 위한 고품질 합성 데이터 생성 가능
- World simulator 내 policy 성능이 실제 환경 성능과 강한 상관관계를 보여 재현 가능하고 확장 가능한 policy evaluation이 가능
Related Works
Video Prediction Model for Robotic Manipulation
Video prediction model은 zero-shot planning, policy steering, evaluation, direct control 등 다양한 역할을 수행한다. NovaFlow와 RIGVid는 large-scale video generation을 활용하여 3D object flow와 trajectory를 추출하고, Large Video Planner는 video를 robot foundation model의 주요 modality로 활용한다. FOREWARN은 action-conditioned world model과 VLM을 결합하여 최적 계획을 선택하며, Ctrl-World와 VEO, VEO2는 large-capacity video model을 evaluation에 활용한다.
그러나 기존 video prediction model들은 실질적인 한계가 있다. Sora, Diffusion Forcing, DFoT 등 많은 아키텍처가 로봇 action에 명시적으로 conditioned되지 않으며, 고용량 diffusion 기반 모델들은 enterprise급 GPU 클러스터가 필요하다. 또한 일부 모델은 안정적인 장기간 prediction에 필요한 robustness가 부족하다.
Imitation Policy Training
Diffusion Policy (DP), Action Chunking Transformer (ACT), $\pi_0$, $\pi_{0.5}$ 등의 imitation learning 방법들은 고품질 real-robot expert data에 의존하며, 이는 수집 비용이 높고 확장이 어렵다. 본 프레임워크는 play-data interaction dataset으로 interactive world model을 구축하여, 물리적 로봇 없이도 simulator 내에서 demonstration data를 수집할 수 있게 한다.
Imitation Policy Evaluation
실세계 policy evaluation은 시간 소요가 크고 비용이 높아 알고리즘 반복과 공정한 비교가 어렵다. 3D 기반 방법(PEGASUS, Real-to-Sim Eval)은 digital twin이나 structured representation을 사용하고, 2D 기반 방법(VEO)은 유연하지만 closed-source인 경우가 많다. 본 프레임워크는 2D RGB 이미지와 action만 필요로 하며, simulator 내 성능과 실세계 성능 간 강한 상관관계를 보장한다.
Method
Problem Formulation
로봇 상호작용 데이터셋 $\mathcal{D}$는 여러 에피소드로 구성되며, 각 에피소드는 $\mathcal{E} = \{(o_0, a_0), (o_1, a_1), ..., (o_T, a_T)\}$ 형태이다. 여기서 $o_t \in \mathbb{R}^{3 \times H \times W}$는 RGB 이미지이고 $a_t$는 시점 $t$의 action이다. 목표는 $N$개의 과거 관측과 action을 입력받아 다음 RGB 프레임을 예측하는 action-conditioned video prediction model $\hat{o}_t = f(o_{t-N:t-1}, a_{t-N:t-1})$을 학습하는 것이다.
Interactive World Simulator
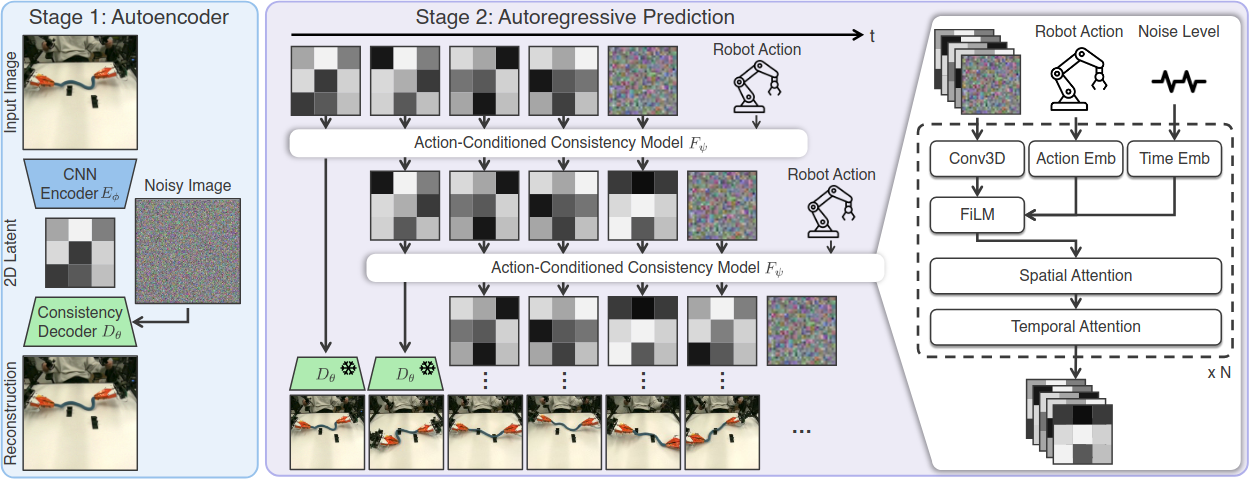
모델 학습은 두 단계로 진행된다.
Stage 1: Autoencoder Training
첫 번째 단계에서는 이미지 $o$를 compact한 2D latent representation $z$로 인코딩하고 다시 복원할 수 있는 autoencoder를 학습한다. CNN encoder $E_\phi$는 이미지를 latent representation $z = E_\phi(o) \in \mathbb{R}^{C \times H' \times W'}$로 변환하고, consistency model decoder $D_\theta$는 이를 다시 고품질 이미지로 복원한다.
학습 시 원본 이미지 $o$에 두 가지 다른 noise scale $\sigma_t > \sigma_s \geq 0$을 적용한다:
$x_{\sigma_t} = \mathcal{N}(o; \sigma_t), \quad x_{\sigma_s} = \mathcal{N}(o; \sigma_s)$
Decoder는 higher-noise input을 lower-noise target으로 매핑하도록 학습된다:
$\hat{x}_{\sigma_s} = D_\theta(x_{\sigma_t}; \sigma_t, \sigma_s, z)$
Weighted regression loss로 최적화한다:
$\mathcal{L}_{AE} = \mathbb{E}_{o, \sigma_t > \sigma_s} \left[ w(\sigma_t) \| \hat{x}_{\sigma_s} - x_{\sigma_s} \|_2^2 \right]$
여기서 $w(\sigma)$는 noise-dependent weight이다. Consistency Trajectory Model (CTM) 방식을 사용하여 안정적인 consistency model 학습을 수행한다. 결과적으로 적은 수의 denoising step만으로 고품질 이미지를 복원할 수 있는 encoder $E_\phi(o)$와 conditional generative decoder $D_\theta(\cdot; z)$를 얻는다.
Stage 2: Dynamics Training
두 번째 단계에서는 autoencoder 파라미터 $(\phi, \theta)$를 고정하고, 각 프레임 $o_t$를 latent $z_t$로 인코딩한 뒤, latent space에서 next-frame supervision으로 action-conditioned dynamics model $F_\psi$를 학습한다. $F_\psi$는 과거 latent context $z_{t-N:t-1}$과 action $a_{t-N:t-1}$이 주어졌을 때 미래 latent frame을 예측한다.
$F_\psi$도 consistency model로 구현한다. Consistency model은 multimodal distribution을 자연스럽게 모델링할 수 있어, 로봇 상호작용에서 발생하는 다양한 가능한 미래를 효율적으로 표현할 수 있다. Latent sequence를 spatiotemporal tensor $Z \in \mathbb{R}^{C \times T \times H' \times W'}$로 취급하고, Stage 1과 유사하게 두 가지 noise scale을 적용한다. 다만 Stage 1과의 차이점은 마지막 프레임에만 full noise를 적용한다는 것이다. Dynamics model은 action sequence와 history context가 주어졌을 때 lower-noise last frame의 latent를 예측하도록 학습된다:
$\hat{Z}_{\sigma_s} = F_\psi(Z_{\sigma_t}; \sigma_t, \sigma_s, a_{t-N:t-1})$
Latent space에서의 weighted regression loss로 학습한다:
$\mathcal{L}_{dyn}(\psi) = \mathbb{E}_{Z, \sigma_t > \sigma_s} \left[ w(\sigma_t) \| \hat{Z}_{\sigma_s} - Z_{\sigma_s} \|_2^2 \right]$
$F_\psi$는 3D convolutional block에 FiLM modulation과 spatiotemporal attention을 결합한 구조이다. 장기간 action-conditioned prediction을 가능하게 하는 핵심 기법은 observation context에 소량의 noise를 주입하는 것이다. 온라인 추론 시 모델의 prediction이 이후 context로 사용되므로 필연적으로 noisy한데, 학습 시에도 noise를 주입함으로써 dynamics model $F_\psi$가 noisy context에 대해 robust해지며, 이는 안정적인 장기간 prediction에 필수적이다.
Inference
추론 시 초기 이미지 $o_0$가 주어지면 먼저 2D latent $z_0 = E_\phi(o_0)$를 얻는다. 이후 noisy latent를 history latent에 추가하고, action 정보와 함께 마지막 noisy latent를 clean latent로 denoising한다 (즉, $z_1$을 예측). 예측된 latent를 기존 context에 추가하여 새로운 history context를 구성하고, 이 과정을 반복하여 autoregressive하게 미래 latent를 예측한다. Context 길이가 threshold를 넘으면 오래된 context를 버려 computation cost가 horizon 증가에 따라 커지지 않도록 한다. 최종적으로 decoder $D_\theta$가 예측된 latent $z$를 이미지 $\hat{o}$로 렌더링한다.
Data Generation for Policy Training
Interactive World Simulator는 expert demonstration data 수집을 위한 확장 가능한 대안을 제공한다. 초기 관측 $o_0$로 simulator를 초기화한 뒤, 사용자가 teleoperation 인터페이스를 통해 제어 명령을 입력하면, simulator가 autoregressive하게 대응하는 관측 시퀀스를 생성하여 demonstration trajectory를 만든다. 생성된 trajectory는 DP, ACT, $\pi$-series 등 표준 imitation learning pipeline과 직접 호환되며, 실세계 demonstration과 자유롭게 혼합하여 사용할 수 있다.
Policy Evaluation
Interactive World Simulator는 확장 가능한 policy evaluation도 가능하게 한다. Policy가 world model의 예측 프레임을 소비하여 다음 action을 생성하고, world model이 그 action을 받아 미래 프레임을 예측하는 방식으로, 실세계 상호작용을 모방한다. 물리적 실험 대비 controllable한 초기 설정, 빠른 실험 리셋, 안전한 대규모 실험이 가능하다.
Experiment
실험에서는 세 가지 질문을 다룬다: (1) 기존 world model 대비 realism, speed, robustness는? (2) Simulator 생성 데이터의 품질은 real data와 유사한가? (3) Simulator 내 policy evaluation이 실세계 성능을 잘 반영하는가?
World Model Instantiation
MuJoCo의 T pushing simulation task 1개와 실세계 task 6개(Mug Grasping, Rope Routing, Rope Collecting, T Pushing, Box Packing, Pile Sweeping)로 실험한다. Rigid object, deformable object, object pile, articulated object 등 다양한 물체와 상호작용을 포함하며, ALOHA Bimanual Robot을 사용한다. 실세계에서는 task당 약 600 에피소드(에피소드당 200 step)의 play data를 수집하며, 수집에 약 6시간이 소요된다.
기본 이미지 해상도는 $128 \times 128$이고, 모델은 경량(예: mug grasping task 모델 크기 176.02 MB)이다. Stage 1 학습은 H200 GPU 1대에서 약 6시간, Stage 2 학습은 약 12시간이 소요된다.
Video Baseline Comparisons
6개 real task와 1개 simulation task에서 Cosmos, UVA, Dreamer4, DINO-WM과 비교한다. 동일한 초기 조건과 rollout horizon(192 step, 19.2초)에서 MSE, LPIPS, FID, PSNR, SSIM, UIQI, FVD 등 표준 metric으로 평가한다.
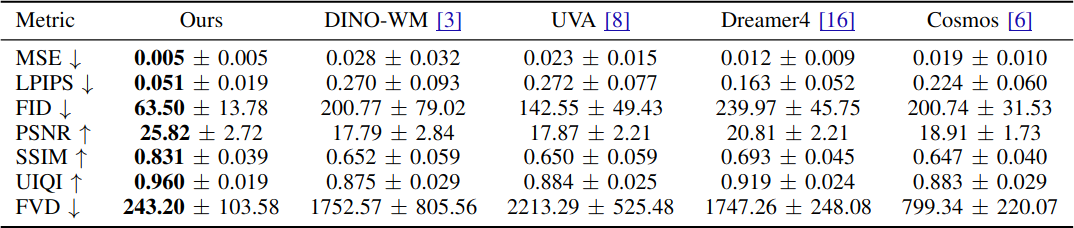
Interactive World Simulator가 모든 metric에서 기존 방법을 일관되게 능가하며, 단일 GPU에서 15 FPS의 interactive performance를 유지한다. 10분 이상의 안정적인 추론도 가능하다.

정성적 비교에서도 기존 방법들이 robot pose drift, 부정확한 object dynamics, missing detail, severe artifact 등의 문제를 보이는 반면, Interactive World Simulator는 물리적으로 타당한 상호작용과 안정적인 prediction을 유지한다.
Data Generation for Policy Training
Simulator가 real data와 유사한 품질의 합성 데이터를 생성할 수 있는지 검증한다. MuJoCo T pushing, 실세계 T pushing, pile sweeping, mug grasping, rope routing의 5개 task에서 DP, ACT, $\pi_0$, $\pi_{0.5}$ 4가지 imitation learning policy를 각 100개 demonstration 에피소드로 학습한다.

사용자는 키보드 또는 kinematic device로 simulator와 상호작용하여 expert demonstration data를 수집할 수 있다. Simulator 내 teleoperation 경험은 실세계 렌더링과 매우 유사하다.
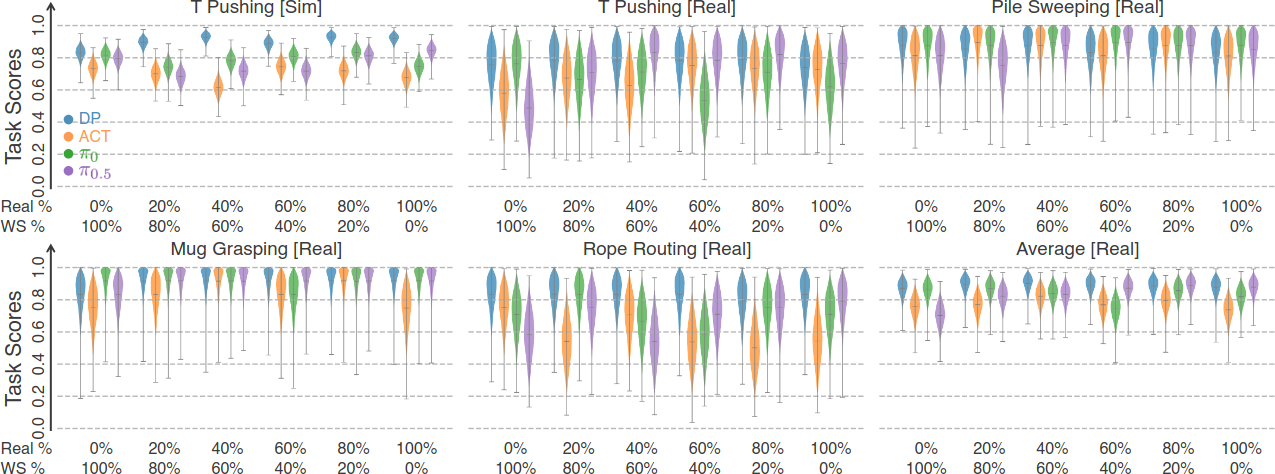
100% world simulator data부터 100% real-world data까지 다양한 혼합 비율로 학습한 결과, 모든 혼합 비율에서 일관되게 높은 성능을 보인다. DP의 경우 100% simulator data로 87.9%, 100% real data로 90.3%의 평균 task score를 달성하여, simulator 생성 데이터가 실세계 demonstration과 유사한 품질임을 확인한다. ACT도 76.2% vs 73.6%로 유사한 성능을 보인다.
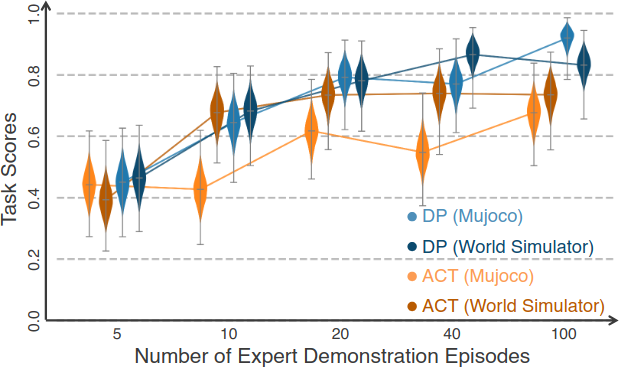
데이터 규모에 따른 성능 변화도 검증한다. 5~100개 에피소드 범위에서 ACT와 DP를 MuJoCo data와 world simulator data로 각각 학습한 결과, 양쪽 모두 데이터 증가에 따라 성능이 일관되게 향상되며, world simulator data의 scaling behavior가 MuJoCo와 유사하다.
Sim-to-Real Correlation for Faithful Policy Evaluation
World simulator 내 policy evaluation이 실세계 성능을 충실히 반영하는지 검증한다. DP, ACT, $\pi_0$, $\pi_{0.5}$ 4가지 policy를 real-world data로 학습하고, T pushing, rope routing, mug grasping, pile sweeping 4개 task에서 최종 및 중간 checkpoint를 평가한다. 각 task당 20개의 초기 설정을 world simulator와 실세계 모두에서 동일하게 적용한다.
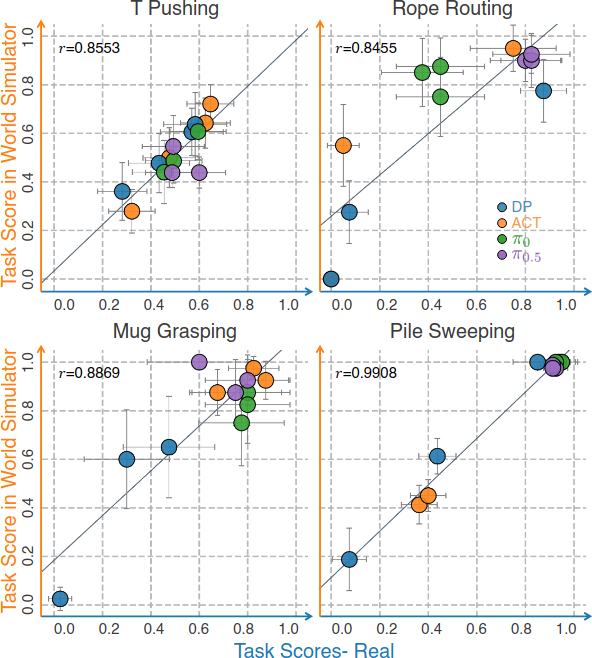
4개 task 모두에서 강한 양의 상관관계가 관찰된다(r = 0.8553, 0.8455, 0.8869, 0.9908). T pushing을 제외한 나머지 task에서는 simulator 점수가 실세계보다 약간 높은 경향이 있지만, 이는 simulator의 유용성을 감소시키지 않는다. 한 policy가 simulator에서 다른 policy를 크게 능가하면 실세계에서도 그럴 가능성이 높아, 실세계 실험 없이도 고품질 후보 policy를 선별할 수 있다.
Conclusion
본 논문에서는 Interactive World Simulator를 제안하였다. Consistency model을 image decoding과 latent-space dynamics prediction에 활용하여, 단일 RTX 4090 GPU에서 15 FPS로 10분 이상의 안정적이고 물리적으로 일관된 video prediction을 달성한다. Simulator 생성 데이터로 학습한 imitation policy가 real-world data로 학습한 policy와 유사한 성능을 보이며, simulator 내 policy 성능과 실세계 성능 간에 강한 상관관계가 확인되어, scalable한 policy training과 evaluation을 위한 reliable한 surrogate 역할을 한다.