Introduction
Human-level contact-rich manipulation은 근본적으로 multi-modal 문제이다. Vision은 spatially rich하지만 temporally slow한(1~2 Hz) global context를 제공하고, force sensing은 빠르게 변화하는($\geq$ 10 Hz) local contact dynamics를 반영한다. 이 두 신호는 주파수와 정보 특성이 근본적으로 다르기 때문에 통합이 어렵다.
기존 접근인 Reactive Diffusion Policy(RDP)는 hierarchical "slow-fast" 구조를 사용한다: slow policy가 vision으로 latent action을 생성하고, fast policy가 force signal 기반으로 이를 실제 action으로 decode한다. 그러나 이 explicit separation은 세 가지 문제를 야기한다: (1) fast policy가 spatial geometry에 "blind"하여 information bottleneck이 발생하고, (2) slow policy의 semantic error를 fast policy가 보정할 context가 없어 modal conflict가 발생하며, (3) vision과 force 간의 "hand-over"가 rigidly hand-designed되어 scalability가 제한된다.
본 논문은 visual planning과 reactive force control을 unified Transformer architecture 내에 통합하는 end-to-end visual-force diffusion policy인 ImplicitRDP를 제안한다. Low-frequency visual token과 high-frequency force token을 하나의 sequence로 concatenate하고, causal cross-attention으로 action과 modality 간의 interaction을 구조화하는 Structural Slow-Fast Learning을 도입한다. 또한 modality collapse를 방지하기 위해, force feedback을 action space로 매핑하는 Virtual-Target-based Representation Regularization(VRR)을 제안한다.
Related Work
Imitation Learning with Force Input
최근 연구들은 force/torque 측정값을 imitation learning framework에 추가 modality로 통합하기 시작했다. 대부분은 TCP의 force/torque signal을 policy input에 직접 포함하지만, action chunking으로 인해 chunk 내부의 제어는 사실상 open-loop으로 남아 real-time force feedback에 반응하지 못한다. RDP는 hierarchical slow-fast architecture로 force 기반 closed-loop control을 달성했지만, two-stage 설계가 학습 복잡성과 hyperparameter tuning 부담을 증가시킨다. ImplicitRDP는 이러한 force-based closed-loop control을 통합된 framework 내에서 달성한다.
Mitigate Modality Collapse
RDP는 hierarchical architecture를 통해 서로 다른 modality에 대한 attention을 강제하지만, standard end-to-end network는 단일 modality에 과도하게 의존하는 modality collapse 문제를 겪는다. FACTR은 학습 초기에 visual input을 blur하는 curriculum learning 전략을 도입했으나, 학습 복잡성이 증가하고 task 간 일반화가 어렵다. 대안으로, future prediction을 representation regularization으로 사용하는 연구들이 policy robustness를 향상시킴을 보여왔다. TA-VLA는 future torque prediction을 auxiliary objective로 사용하여 physically grounded representation을 학습한다. ImplicitRDP는 future prediction paradigm을 활용하되, compliance control에서 영감을 받은 virtual target이라는 새로운 prediction objective를 제안한다.
Methodology
Preliminary: Diffusion Policy
Diffusion Policy(DP)는 로봇 제어를 conditional generative modeling 문제로 formulate한다. Action sequence $\mathbf{A}_t$의 conditional distribution $p(\mathbf{A}_t | \mathbf{O}_t)$를 학습하며, training 시 ground-truth action에 Gaussian noise를 추가한다:
$\mathbf{A}_t^k = \sqrt{\bar{\alpha}_k} \mathbf{A}_t^0 + \sqrt{1 - \bar{\alpha}_k} \epsilon^k$
Noise prediction network $\epsilon_\theta$가 noisy action과 observation으로부터 noise를 예측하며, DDPM loss로 학습한다:
$\mathcal{L}_\epsilon = \mathbb{E}_{k, \epsilon^k, (\mathbf{O}_t, \mathbf{A}_t^0)} [\| \epsilon^k - \epsilon_\theta(\mathbf{O}_t, \mathbf{A}_t^k, k) \|^2]$
Inference 시 Gaussian noise에서 시작하여 iterative denoising으로 action chunk를 생성하고, Receding Horizon Control(RHC)로 실행한다. 그러나 chunk 내부는 open-loop이므로 high-frequency observation이 있어도 reactivity가 제한된다.
Structural Slow-Fast Learning
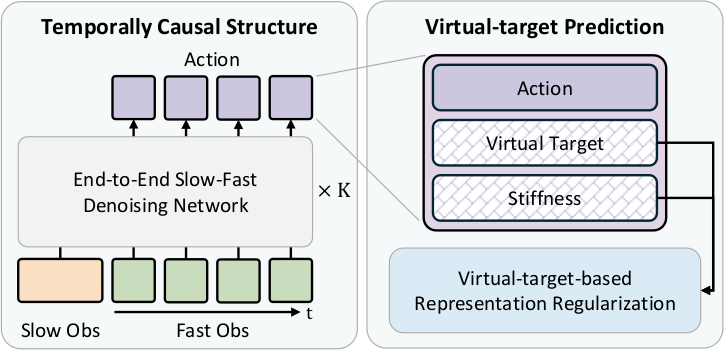
Temporally Causal Structure
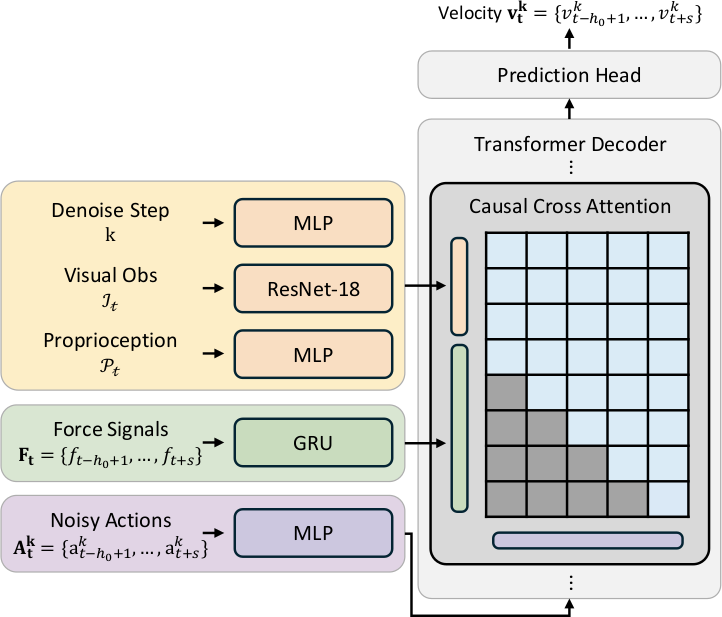
ImplicitRDP는 Standard Transformer-based DP를 기반으로 하지만, observation을 "slow" part(visual observation $\mathcal{I}_t$와 proprioception $\mathcal{P}_t$)와 "fast" part(force signal $\mathbf{F}_t$)로 분리한다. Force signal은 action chunk에 aligned된 temporal sequence로 처리한다. Future information leakage를 방지하기 위해 두 가지 구조적 제약을 적용한다: (1) GRU로 force를 encoding하여 temporal causality를 보장하고, (2) causal attention mask를 사용하여 action $a_{t-h_o+s}$의 예측이 force token $\{f_{t-h_o+1}, \ldots, f_{t-h_o+s}\}$에만 attend하고 미래 force에는 attend하지 않도록 한다. 이 구조적 제약은 standard DP와 동등한 병렬 학습 효율을 유지하면서, dense force signal의 temporally causal processing을 가능하게 한다.
Consistent Inference Mechanism
Temporally causal structure 덕분에 model이 variable-length action token input을 자연스럽게 지원한다. 이를 활용하여, noisy action sequence를 하나씩 확장하면서 연속적으로 sampling하여 force-based closed-loop control을 구현한다. Diffusion model의 inherent stochasticity로 인한 consecutive inference 간 inconsistency를 방지하기 위해, DDIM sampler에서 stochasticity parameter $\eta = 0$으로 설정하여 denoising trajectory를 strictly deterministic으로 만든다. Slow observation encoding과 noise sampling은 chunk 시작 시 한 번만 수행하고 cache하며, 매 control step마다 fast observation만 갱신하여 DDIM을 실행한다. 매 시퀀스마다 마지막 action element만 실제 로봇에서 실행한다. 이를 통해 force-based closed-loop control을 달성하면서 action chunking의 장점(smoother motion, non-Markovian behavior)을 유지한다.
Virtual-Target-based Representation Regularization
Virtual Target Formulation
End-to-end policy가 단일 modality에 과도하게 의존하는 것을 방지하기 위해, compliance control theory에서 영감을 받은 virtual target prediction을 사용한다. Standard compliance system을 spring-mass-damper로 모델링하면:
$f_{\text{ext}} = M\ddot{x}_{vt} + D\dot{x}_{vt} + K(x_{vt} - x_{\text{real}})$
Quasi-static manipulation에서 inertia와 damping term을 무시하면, virtual target은 현재 stiffness와 measured force로부터 도출된다:
$x_{vt} = x_{\text{real}} + K^{-1} f_{\text{ext}}$
Adaptive Stiffness Assignment
Manipulation task는 물체 접근, 접촉, 조작 등 여러 phase로 구성되므로, 모든 phase에 동일한 force-based regularization을 적용하는 것은 부적절하다. ACP의 heuristic 전략을 채택하여 adaptive stiffness matrix를 할당한다. Force 방향에 직교하는 방향에는 high stiffness $k_{\text{high}}$를, force 방향에는 force magnitude에 따라 변하는 adaptive stiffness $k_{\text{adp}}$를 적용한다:
$k_{\text{adp}} = \begin{cases} k_{\text{max}}, & \|f_{\text{ext}}\| < f_{\text{min}} \\ k_{\text{max}} - \frac{k_{\text{max}} - k_{\text{min}}}{f_{\text{max}} - f_{\text{min}}}(\|f_{\text{ext}}\| - f_{\text{min}}), & \text{otherwise} \\ k_{\text{min}}, & \|f_{\text{ext}}\| > f_{\text{max}} \end{cases}$
Unified Training Objective
Diffusion framework에 VRR을 통합하기 위해, original action $a_t$, virtual target $x_{vt}$, stiffness magnitude $k_{\text{adp}}$를 concatenate한 augmented action vector를 구성한다:
$a_{\text{aug},t} = \text{concat}([a_t, x_{vt}, k_{\text{adp}}])$
Diffusion policy는 이 augmented sequence를 denoise하도록 학습되며, inference 시 auxiliary component는 버리고 $\hat{a}_t$만 실행한다.
Advantages over Force Prediction
Virtual target은 force prediction 대비 두 가지 이점을 제공한다. 첫째, objective alignment: force sensor는 TCP frame에서 측정하는 반면 action은 robot base/world frame의 trajectory이다. Virtual target은 action space와 동일한 좌표계의 motion trajectory이므로, motion planning과 force understanding을 위한 consistent한 representation 학습이 가능하다. 둘째, adaptive importance weighting: adaptive stiffness가 dynamic weighting mechanism으로 작용한다. Free motion 시($\|f_{\text{ext}}\|$ 작음) $K$가 커져 $\Delta x \to 0$이고 $x_{vt} \approx x_{\text{real}}$이 되어 force noise를 무시한다. Contact 시($\|f_{\text{ext}}\|$ 큼) $K$가 작아져 $\Delta x$가 크게 증폭되어 high-force contact event에 높은 loss weight를 부여한다.
Implementation Details
Learning Stability
End-to-end network에서 force signal을 직접 활용하면 instability가 발생할 수 있다. 두 가지 수정을 적용한다. 첫째, standard $\epsilon$-prediction 대신 velocity-prediction을 사용한다:
$\mathbf{v}_t^k \triangleq \sqrt{\bar{\alpha}_k} \epsilon - \sqrt{1 - \bar{\alpha}_k} \mathbf{A}_t^0$
Velocity-prediction은 inference stability와 conditional information adherence 사이의 더 나은 균형을 제공한다.
둘째, 6D rotation이나 quaternion 대신 Euler angle을 rotation representation으로 사용한다. 세 차원이 독립적이어서 rotation의 coupling이 줄어들고 action stability가 높아지며, relative action을 예측하므로 Gimbal lock 문제 또한 자연스럽게 회피할 수 있다.
Hardware Design
Force-based learning에는 distinctive physical signal이 필요하다. End-effector와 object가 모두 rigid하면 force 변화가 미약하고 noise에 묻힌다. 이를 완화하기 위해 custom compliant fingertip을 설계하여, 어떤 stiffness의 물체와 접촉하더라도 항상 distinctive reactivity signal을 생성하도록 한다.

Experiments
Real-world contact-rich manipulation task에서 ImplicitRDP를 평가하여 4가지 질문에 답한다:
- Q1: End-to-end closed-loop network이 vision-only(DP) 및 hierarchical (RDP) baseline과 어떻게 비교되는가?
- Q2: Structural slow-fast learning(SSL)의 closed-loop force control이 contact-rich task 성능을 향상시키는가?
- Q3: Virtual-target-based representation regularization(VRR)이 다른 auxiliary task보다 효과적인가?
- Q4: Velocity-prediction과 Euler angle rotation representation이 learning stability를 향상시키는가?
Experimental Setup
Flexiv Rizon 4s robot arm에 joint torque sensor와 end-effector의 6-axis force/torque sensor를 장착한다. Joystick과 custom compliant fingertip을 robot end-effector에 장착하고, wrist webcam으로 visual observation을 기록한다. 모든 데이터는 10 Hz로 수집하며, 각 task마다 40개의 demonstration을 수집한다.
- Box Flipping: 얇은 상자를 fixture에 밀어 뒤집는 task. 의도적으로 작은 contact force(~8N)로 demonstration하며, 가해진 힘이 14N을 초과할 시 실패로 판정한다. 지속적 force application이 필요한 과일 껍질 벗기기, 화병 닦기 등의 task를 대표한다.
- Switch Toggling: Circuit breaker switch를 toggle하는 task. Switch 작동에 비교적 큰 force가 필요하며, vision-only policy로는 triggering threshold 도달 여부를 판단할 수 없다. 야채 자르기 등 short-duration force burst가 필요한 task를 대표한다.
Results and Analysis
Q1: Comparison with Baselines
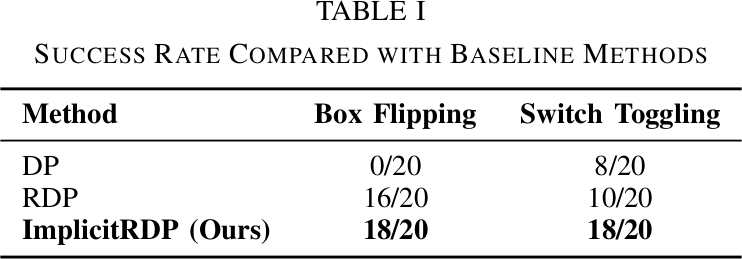
ImplicitRDP는 vision-only DP와 hierarchical RDP 모두를 consistently 능가한다. DP는 box flipping에서 과도한 force를 적용하여 0/20, switch toggling에서는 triggering force 도달 전에 toggling motion을 시작하여 8/20에 그친다. RDP는 box flipping에서 16/20의 성공률을 보이지만, switch toggling에서 10/20으로 어려움을 겪는다. RDP의 fast policy가 latent space에서 action을 decode하여 approach phase에서 precision loss가 발생하기 때문이다. ImplicitRDP는 두 task 모두에서 18/20을 달성한다.

Q2: Effectiveness of Closed-Loop Control

SSL과 VRR을 모두 제거하면(open-loop force) box flipping 6/20, switch toggling 5/20으로 크게 하락한다. VRR만 사용했을 때도 open-loop에서는 성능이 비교적 낮다. Box flipping에서의 성능 하락이 특히 두드러지는데, 지속적인 force application이 필요한 이 task에서 open-loop network은 chunk 내 action을 조정할 수 없기 때문이다. SSL이 실현하는 closed-loop force control이 contact-rich task, 특히 sustained force maintenance가 필요한 task에서 핵심적임을 보여준다.
Q3: Auxiliary Task Analysis
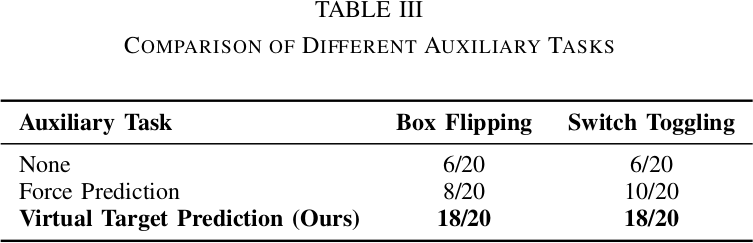
Virtual target을 prediction objective로 사용할 때 두 task 모두에서 최고 성능을 달성한다. Standard force prediction도 auxiliary task가 없는 모델과 비교하면 개선을 보이지만 VRR에는 미치지 못한다. Auxiliary task 없는 모델은 modality 간 importance relationship을 학습하지 못하여 modality collapse가 발생한다.
Q4: Ablation on Learning Stability
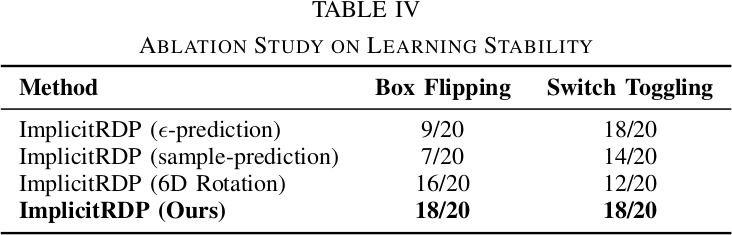
Velocity-prediction이 $\epsilon$-prediction(9/20, 18/20)과 sample-prediction(7/20, 14/20)을 능가하며, 특히 지속적 force application이 필요한 box flipping에서 현저한 차이를 보인다. Euler angle이 6D rotation(16/20, 12/20) 대비 우수하며, 6D rotation은 non-independent representation으로 인한 noise tolerance 저하로 switch toggling에서 불안정한 action을 유발한다. Velocity-prediction + Euler angle 조합이 두 task 모두에서 최고 stability와 성공률을 달성한다.
Conclusion
본 논문은 low-frequency visual planning과 high-frequency force control을 통합하는 end-to-end framework인 ImplicitRDP를 제안했다. Structural slow-fast learning을 통해 separate policy hierarchy의 필요성을 제거하고, 하나의 네트워크가 서로 다른 frequency의 modality에 동적으로 attend할 수 있도록 했다. Virtual-target auxiliary task는 representation space를 효과적으로 regularize하여 policy가 단일 modality에 과도하게 의존하지 않도록 한다. Contact-rich manipulation에서 기존 baseline을 능가하면서 더 간결한 training pipeline을 제공한다. Future work으로는 VLA 모델로의 확장과 tactile sensing 등 다른 high-frequency modality 통합이 있다.