Introduction
문제제기
- 기존 모델들은 픽셀 단위로 한번에 feature를 추출하는 모델을 사용하지 않는다.
- Feature pyramid 후 patch별로 CLIP 피쳐를 뽑으면 blurry해진다.
- SAM 모델로 마스킹한 후 CLIP 피쳐를 뽑는 방식은 모델을 많이 써야 해서 복잡해진다.
- Open-vocabulary query를 처리할 때 similarity score의 threshold를 empirical하게 정한다.
GOI는 APE 모델을 약간 변형하여 픽셀별로 피쳐를 바로 뽑을 수 있고, Optimizable Semantic-space Hyperplane (OSH)을 이용하여 threshold를 logistic regression을 통해 최적화한다.
Methods
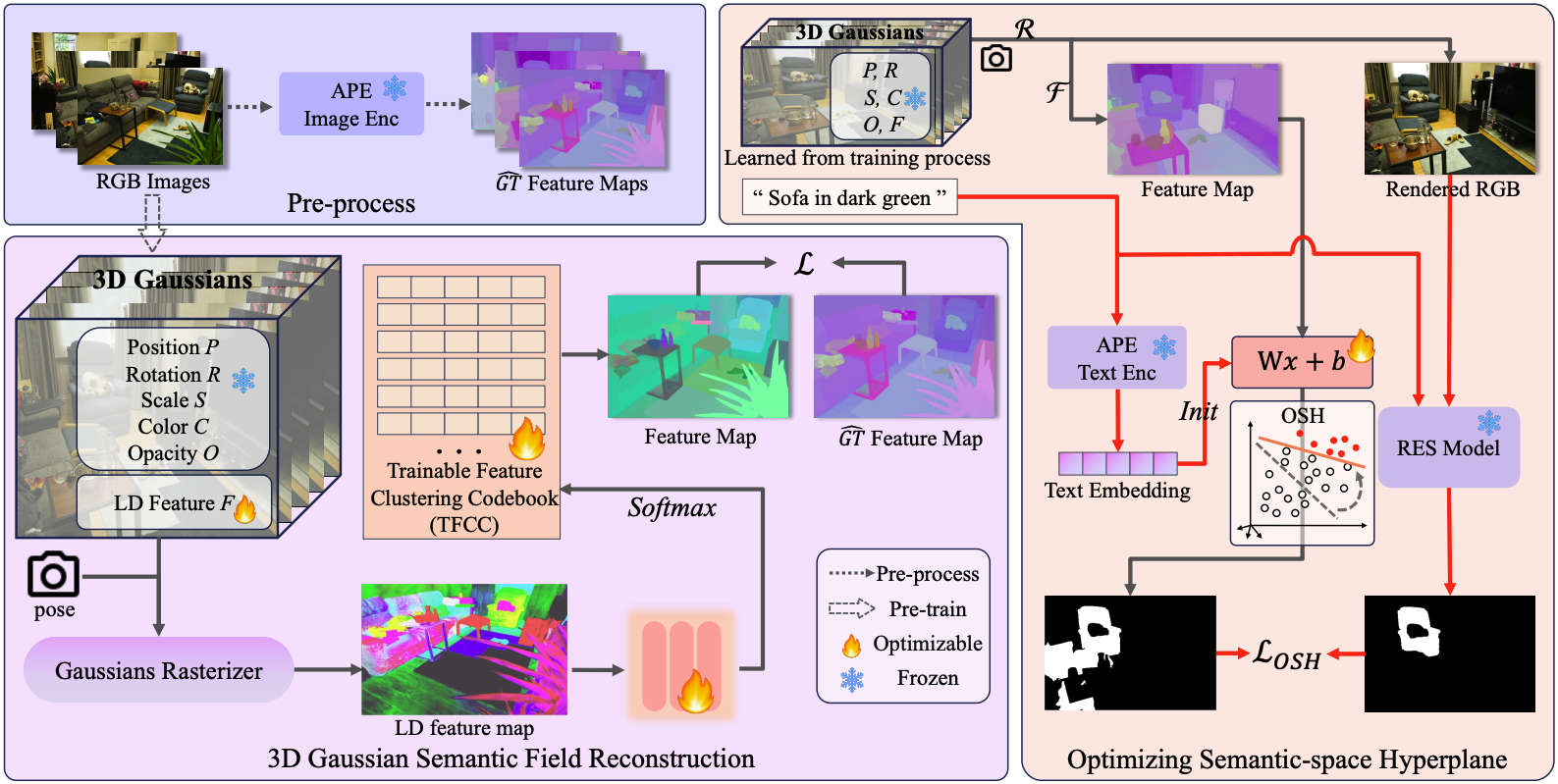
Preprocessing
카메라 pose를 알고 있는 이미지 $I = \{I_1, I_2, \dots, I_K\}$가 있을 때, APE image encoder를 이용하여 2D semantic feature map $V = \{V_1, V_2, \dots, V_K\}$를 구한다. 이 feature map을 pseudo GT features $\hat{GT}$로 정한다. $\hat{GT}$의 각 픽셀별 피쳐를 $v_{gt}$라 하자.
3D Gaussian Semantic Field Reconstruction
APE embedding을 모든 가우시안에 직접 할당하는 것은 비효율적이기 때문에 Trainable Feature Clustering Codebook (TFCC)을 사용한다. TFCC는 $n = 300$개의 entry를 가지고 있고, 각 entry는 APE space의 피쳐 벡터를 가지고 있다. 대신 각 가우시안에는 저차원 피쳐 벡터를 할당한다.
가우시안의 저차원 피쳐 벡터는 RGB 렌더링과 동일한 방식으로 렌더링된다. 이 렌더링된 픽셀별 벡터를 APE space의 피쳐 벡터로 다시 복원하기 위해서는 TFCC를 이용하는데, 저차원 피쳐 벡터를 MLP에 통과시켜 TFCC entry의 index로 classification한다.
TFCC Trainig
TFCC의 각 entry feature부터 학습을 진행한다. 우선 k-means clustering을 이용해 $\hat{GT}$를 클러스터링하여 TFCC를 initialize한다. TFCC 학습에는 아래의 self-entropy loss를 사용하는데, 이는 $\hat{GT}$의 각 픽셀별 피쳐인 $v_{gt}$가 하나의 entry에만 가깝고 나머지와는 전부 멀어지도록 하는 것이다. Entropy가 작을수록 확률분포가 한 점으로 몰리는 원리이다.
$\mathcal{L}_{ent} = - \sum\limits_{i=1}^{N} p_i \log (p_i)$
이때 $p_i = \text{Softmax} \left( \cos \left\langle v_{gt}, \mathcal{T}[i] \right\rangle \cdot \tau \right)$이다. 여기서 contrastive learning을 직접 사용할 수 없는 이유는 $v_{gt}$가 어느 entry에 매칭될지 사전에 알 수 없기 때문이다.
학습을 돕기 위해 아래의 loss term을 추가로 사용한다.
$\mathcal{L}_{max} = 1 - \cos \left\langle v_{gt}, \mathcal{T}[d] \right\rangle$
이때 $d = \arg\max\limits_i \left( \cos \left\langle v_{gt}, \mathcal{T}[i] \right\rangle \right)$이다. 이는 $v_{gt}$와 가장 가까운 TFCC entry와 $v_{gt}$ 사이의 cosine similarity를 최대화하는 것이다. TFCC 학습의 최종 loss는 아래와 같다.
$\mathcal{L}_T = \lambda_{ent} \mathcal{L}_{ent} + \lambda_{max} \mathcal{L}_{max}$
Feature and Decoder Training
이후 TFCC와 함께 가우시안별 피쳐와 MLP decoder를 joint training한다. 어떤 픽셀에 대해 렌더링된 피쳐 벡터를 decode하여 APE embedding을 구하면 이론적으로 $v_{gt}$와 유사해야 한다. 따라서 MLP를 통해 구한 TFCC의 index와 $v_{gt}$에 해당하는 TFCC index $d$가 유사해지도록 학습한다. 이때 L2 loss를 사용한다.
$\mathcal{L}_{joint} = \left\| e - \text{onehot}(d) \right\|_2^2$
마지막으로, 렌더링된 픽셀별 피쳐를 통해 구한 TFCC entry 벡터 $v$와 $v_{gt}$를 직접 end-to-end로 비교하는 cosine similarity loss를 추가한다.
$\mathcal{L}_{e2e} = 1 - \cos \left\langle v_{gt}, v \right\rangle$
따라서 joint training 단계에서의 최종 loss는 아래와 같다.
$\mathcal{L} = \mathcal{L}_T + \lambda_{joint} \mathcal{L}_{joint} + \lambda_{e2e} \mathcal{L}_{e2e}$
Optimizable Semantic-space Hyperplane
각 가우시안별 저차원 피쳐 또는 렌더링된 저차원 피쳐를 decode하여 APE embedding으로 변환하고 나면, text embedding과 비교하여 cosine similarity를 구할 수 있다.
$\cos(\theta) = \cfrac{\phi_{img} \cdot \phi_{text}}{\|\phi_{img}\| \|\phi_{text}\|}$
기존에는 미리 정해진 threshold를 이용해 이 similarity 값을 판별하지만, 이는 모든 scene, 모든 query들에 완벽히 들어맞지 않을 수 있다. GOI는 이 thresholding 과정을 아래와 같이 hyperplane seperating 관점에서 본다.
$\tilde{W} x + \bar{b} = 0$
$\tilde{W}$는 text query embedding, $x$는 semantic feature, $\bar{b}$는 threshold에 해당한다.
GOI는 RES model인 Grounded-SAM을 이용해 threshold를 학습하고 text query embedding 또한 업데이트한다.
먼저 APE를 통해 얻은 text query embedding과 threshold 기본값을 이용해 특정 view에서 thresholding을 진행하여 binary mask $m$을 얻는다. 그 후, 같은 view에서 렌더링된 RGB 이미지를 이용해 Grounded-SAM mask $\hat{m}$도 얻는다. 이후 아래의 loss를 이용해 $\tilde{W}$와 $\bar{b}$를 logistic regression 방식으로 1회 업데이트한다.
$\mathcal{L}_{OSH} = -\cfrac{1}{P} \sum\limits_{i=1}^{P} \left[ w \cdot \hat{m}_i \log (\sigma (m_i)) + (1 - \hat{m}_i) \log (1 - \sigma (m_i)) \right]$
이렇게 업데이트한 text query embedding과 threshold를 다른 뷰에서도 사용한다.
Experiments
Evaluation Setup
- 데이터셋: Mip-NeRF360, Replica
- Metric: mean Intersection over Union (mIoU), mean Pixel Accuracy (mPA), mean Precision (mP)
Quantitative Results
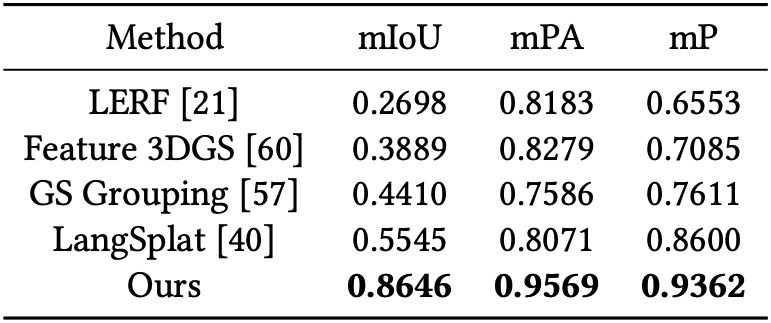
Mip-NeRF360에서의 결과는 위의 표와 같다.
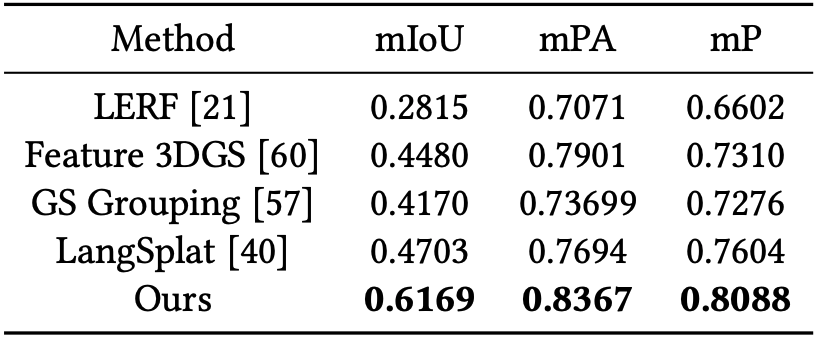
Replica에서의 결과는 위의 표와 같다.
Qualitative Results

다른 모델들과 segmentation 결과를 비교하면 위 사진과 같다.
Ablation Study
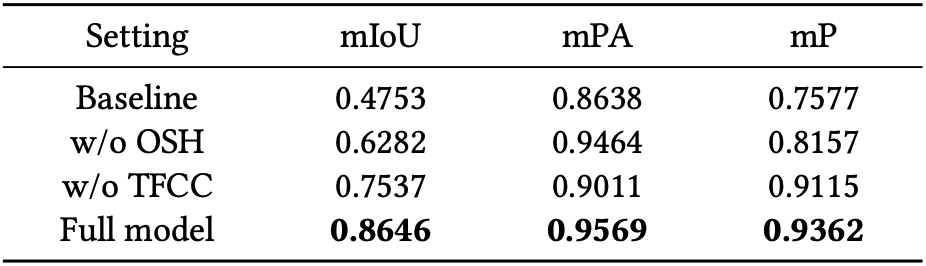

Ablation study 결과는 위와 같다. TFCC와 OSH 모듈 모두 결과에 긍정적인 영향을 주는 것을 확인할 수 있다.
Conclusion
GOI는 TFCC 모듈을 이용하여 고차원 피쳐 벡터를 저차원으로 효율적으로 압축하며, OSH 모듈을 이용하여 querying의 정확도를 향상시켰다.