Introduction

본 논문의 목적은 3D reconstruction과 segmentation을 동시에 할 수 있는 3D representation을 학습하는 것이다. 하지만 3D에서 바로 작동하는 모델을 만들기에는 대규모 3D annotation dataset을 구축하는 것에 비용적 한계가 있다.
기존에 NeRF rendering을 통해 CLIP, DINO 등 2D VLM feature를 distillation하여 위에 언급한 목적을 달성하려는 모델도 있었지만, NeRF 모델은 렌더링 속도가 느리고 수정이 어렵다는 한계가 있다.
이에 따라 본 논문에서는 기존의 3D Gaussian Splatting을 확장해서 object segmentation까지 수행할 수 있는 모델을 구축하였다. 2D VLM 모델로부터 distillation하기 위해 각 가우시안에 Identity Encoding이라는 low-dimensional embedding을 더해 각 가우시안이 속한 물체에 대한 정보를 학습하도록 했고, un-supervised 3D Regularization Loss를 새롭게 도입하여 공간상 가까이 위치하는 가우시안들이 유사한 identity encoding 값을 학습할 수 있도록 했다.
3D gaussian splatting의 explicit한 특성과 본 논문의 contribution 덕분에 Gaussian Grouping은 위 사진과 같이 object removal, inpainting 등 3D scene editing을 지원한다.
Method
본 논문의 목적은 scene reconstruction뿐만 아니라 panoptic segmentation까지 가능한 모델을 만드는 것이다. Gaussian Grouping 모델은 이 목적을 달성하면서 각 물체를 group으로 구분지어 scene editing을 가능하게 하며, 기존 3DGS의 품질을 유지하면서도 빠른 training과 rendering이 가능하다.
Preliminaries: 3D Gaussian Splatting
각 가우시안은 아래의 파라미터로 구성된다.
- 중심점: $\mathbf{p} = \{x, y, z\} \in \mathbb{R}^3$
- 표준편차 (크기): $\mathbf{s} \in \mathbb{R}^3$
- 회전: $\mathbf{q} \in \mathbb{R}^4$
- 불투명도: $\alpha \in \mathbb{R}$
- 색 (SH coefficients): $\mathbf{c}$
3D Gaussian Grouping
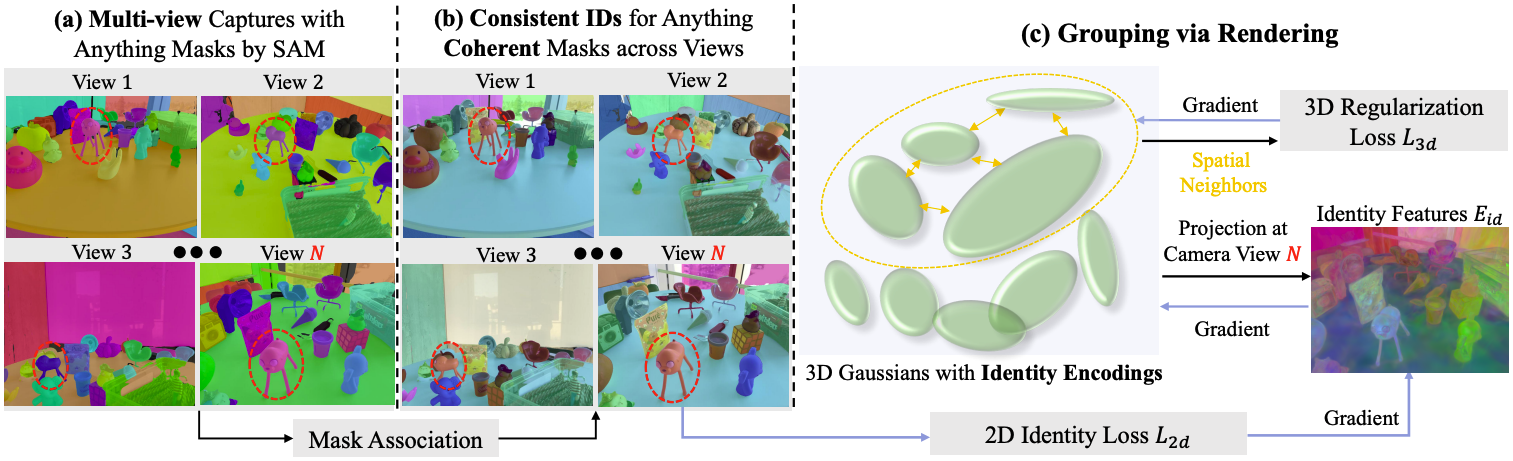
우선, Gaussian Grouping에서는 각 가우시안이 어떤 object에 속하는지를 표현하기 위해 크기 16의 벡터 identity encoding $\mathbf{e} \in \mathbb{R}^{16}$을 파라미터로 추가한다.
(a) 단계에서는 2D image와 SAM mask를 모델에 입력한다. (b) 단계에서는 multi-view consistency를 위해 같은 object를 보고 있는 mask들에 동일한 ID를 부여한다. 이때 zero-shot tracking 모델인 DEVA를 이용해서 frame간 object의 이동을 추적하고 mask를 associate할 수 있다. 이러한 방식은 각 mask를 별개로 보고 association을 진행하는 것보다 60배 이상 빠르면서 정확도도 더 높다고 한다.
(c) 단계에서는 렌더링을 통한 identity encoding의 학습을 진행한다. Identity encoding은 크기 16의 벡터로, 각 instance의 ID를 표현한다. 색깔과 같은 방식으로 identity encoding을 2D로 렌더링한 후, 각 mask와 비교하여 loss를 계산하고 backpropagate하는 방식으로 학습한다.
$E_{\text{id}} = \sum\limits_{i \in \mathcal{N}} e_i \alpha'_i \prod\limits_{j=1}^{i-1} (1 - \alpha'_j)$
Identity encoding을 렌더링하는 구체적인 수식은 위와 같다. $E_{\text{id}}$는 렌더링된 identity encoding, $\alpha'_i$는 각 픽셀에서의 Gaussian influence factor에 해당한다. Gaussian influence factor는 아래 수식을 통해 구한 projection된 covariance $\Sigma^{\text{2D}}$에 가우시안의 opacity $\alpha_i$를 곱하여 구한다.
$\Sigma^{\text{2D}} = J W \Sigma^{\text{3D}} W^T J^T$
Loss를 계산하는 과정을 구체적으로 살펴보자. 총 $K$개의 object가 있다고 가정하자. Grouping loss $\mathcal{L}_{\text{id}}$는 두 개의 세부 loss 항목 $\mathcal{L}_{\text{2d}}$와 $\mathcal{L}_{\text{3d}}$로 구성된다.
$\mathcal{L}_{\text{2d}}$는 2D identity loss로, 렌더링된 각 픽셀별 identity encoding이 K개의 mask ID 중 하나로 매핑되도록 한다. 우선 linear layer $f$를 통해 픽셀별 identity encoding을 크기 $K$의 벡터로 projection한다. 그 후 softmax를 취하여 standard classification을 진행한다. Loss 또한 standard cross-entropy loss이다.
$\mathcal{L}_{\text{3d}}$은 3D regularization loss로, 공간상 가까이 위치한 가우시안들의 identity encoding이 서로 유사해지도록 한다. 이 loss는 occlusion이 많은 상황이나 물체 내부의 가우시안이 더욱 잘 학습될 수 있도록 한다.
$\mathcal{L}_{3d} = \cfrac{1}{m} \sum\limits_{j=1}^{m} D_{\text{kl}}(P \| Q) = \cfrac{1}{mk} \sum\limits_{j=1}^{m} \sum\limits_{i=1}^{k} F(e_j) \log \left( \cfrac{F(e_j)}{F(e_i')} \right)$
위 수식에서 $P$는 현재 계산하고 있는 가우시안의 identity encoding, $Q = \{e'_1, e'_2, \cdots, e'_k\}$는 그 가우시안의 $k$ nearest neighbors의 identity encoding이다. $F$는 2D identity loss에서도 사용된 linear layer $f$와 softmax 연산을 합쳐서 표현한 것이다. $m$은 KL divergence에서의 sampling point 개수이다.
3D regularization loss로 인하여 각 가우시안의 identity encoding이 그 주변 $k$개의 가우시안과 유사해지게 된다.
최종 loss는 기존 가우시안의 reconstruction loss $\mathcal{L}_{rec}$과 Grouping loss $\mathcal{L}_{\text{id}}$를 합쳐 아래와 같이 표현된다.
$\mathcal{L}_{\text{render}} = \mathcal{L}_{\text{rec}} + \mathcal{L}_{\text{id}} = \mathcal{L}_{\text{rec}} + \lambda_{\text{2d}} \mathcal{L}_{\text{2d}} + \lambda_{\text{3d}} \mathcal{L}_{\text{3d}}$
Gaussian Grouping for Scene Editing
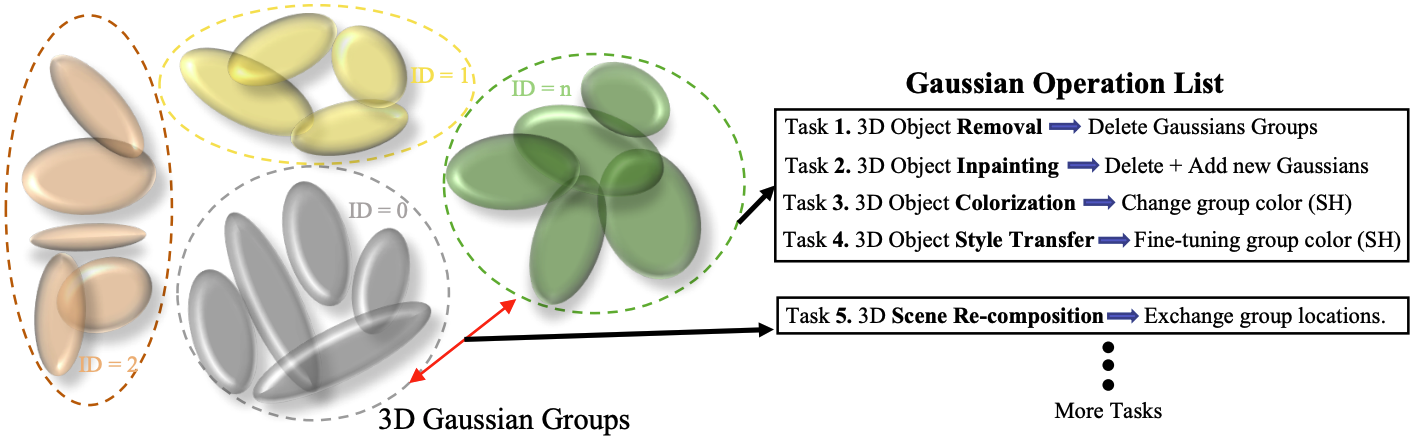
위의 과정을 거쳐 grouping이 끝난 후에는, 원하는 방식대로 scene editing을 할 수 있다. 먼저, 수정할 물체를 language prompt로 입력한다. 이때 SAM mask에는 language label이 없기 때문에 language prompt가 어떤 object를 뜻하는지 파악하기 위해 Grounding-DINO라는 open-vocabulary 모델을 추가적으로 사용한다.
먼저 2D image에서 Grounding-DINO로 language prompt에 맞는 부분을 찾아내고, 렌더링된 identity encoding image와 비교하여 3D 상에서의 물체를 찾아내는 방식이다. 이로 인해 Grounding-DINO가 2D image에서 정확한 부분을 찾지 못하면 3D에서도 정확한 물체를 찾을 수 없다는 한계가 있다.
Object removal이나 Scene recomposition (두 물체의 위치 교환)의 경우에는 추가적인 fine tuning 없이 단순히 하나의 group을 삭제하거나 두 group의 위치를 바꾼다. Object colorization의 경우에는 SH 파라미터만 fine-tuning을 진행한다.
Object inpainting의 경우에는 우선 해당하는 object로 분류된 가우시안과 함께, 위치가 object 내부에 있는 가우시안까지 삭제한다. 이후 Grounding-DINO에 'blurry hole'이라는 prompt를 넣어 fine-tuning을 진행할 영역을 선정한다. 이 영역을 DEVA 모델을 이용하여 다른 frame과 association한다. 이후 LaMa 모델의 2D inpainting 결과를 바탕으로 20만 개의 가우시안을 해당 영역에 새로 추가하고, 추가된 가우시안에 대해서만 학습을 진행한다. L1 loss와 LPIPS loss를 이용하여 학습한다.
Object style transfer의 경우에는 원하는 object로 분류된 가우시안과 object 내부에 있는 가우시안에 대해서만 학습을 진행한다. 중심점의 위치는 freeze하고 나머지 파라미터만 fine-tuning한다. Style transfer는 우선 2D image에 대해 InstructPix2Pix를 사용하여 진행한다. Rendering loss는 mask 내부 영역에 대해서만 계산된다. Inpainting과 마찬가지로 L1 loss와 LPIPS loss를 이용하여 학습한다.
Experiments
Dataset and Experiment Setup
Segmentation과 localization 정확도 측정을 위한 데이터셋으로는 LERF-Localization 데이터셋을 변형한 LERF-Mask 데이터셋을 사용하였다. LERF-Localization에서 3개 scene을 골라 직접 3D annotation을 진행하고 각 scene에 대해 평균 7.7개의 GT mask label text를 주었다. 그 외 Replica와 ScanNet 데이터셋도 사용하였다.
Reconstruction quality 측정을 위한 데이터셋으로는 Mip-NeRF 360, LLFF, Tanks & Temples, Instruct-NeRF2NeRF 데이터셋을 사용하였다.
3D Multi-View Segmentation
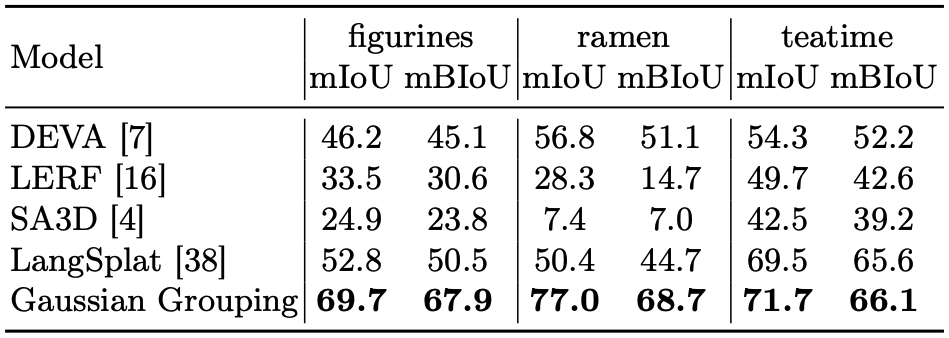
Open-vocabulary segmentation 결과는 위의 표와 같다. 특히 figurines와 ramen scene에서 다른 모델들보다 월등한 mIoU 값을 보이는 것을 알 수 있다.
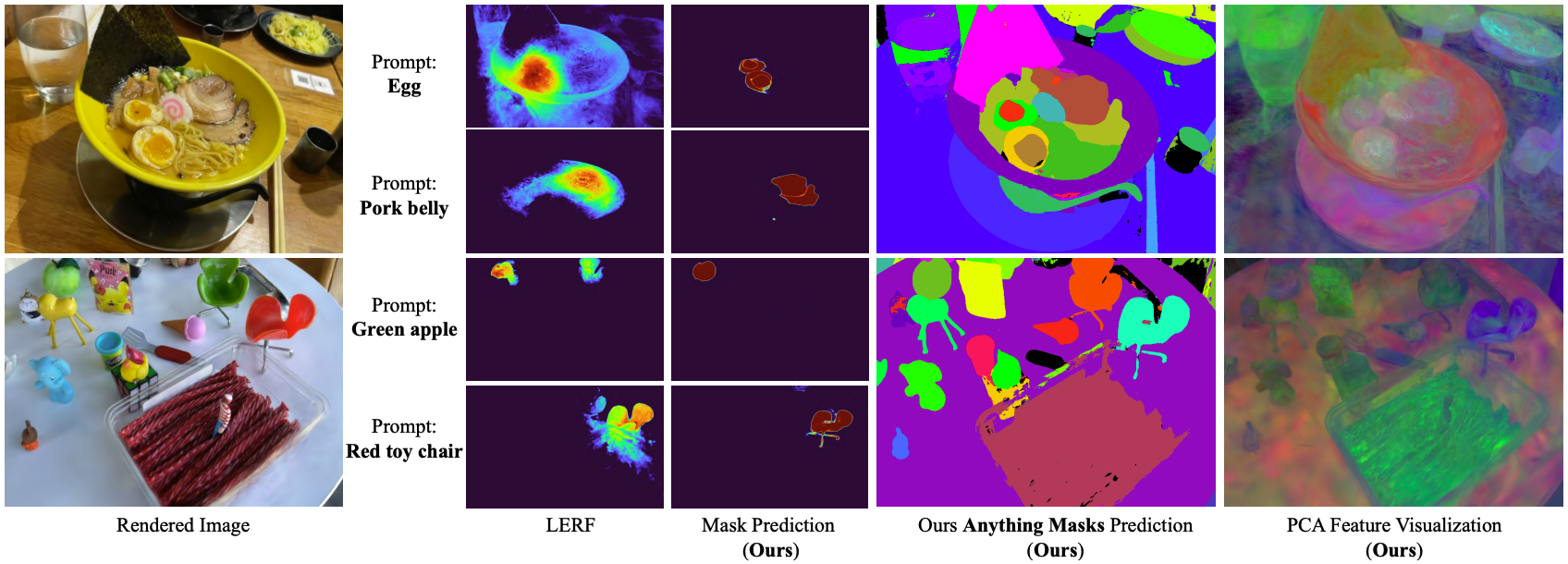
위와 같이 렌더링된 사진으로 비교해 보아도 Gaussian Grouping이 LERF보다 mask의 경계면이 깔끔하고, 'green apple'과 같이 복잡한 prompt에 대해서도 segmentation을 정확하게 수행하는 것을 확인할 수 있다.

3D panoptic segmentation 결과는 위의 표와 같다. Panoptic Lifting 모델과 비교하여 정확도와 속도 모두 우수한 것을 볼 수 있다.
3D Scene Editing

3D object removal task의 결과는 위와 같다. 여기서는 삭제 대상이 되는 물체가 얼마나 잘 삭제되었는지만을 확인하고, 물체가 있던 공간의 구멍이나 부자연스러움은 뒤의 3D object inpainting에서 확인한다. 먼저 truck scene을 보면, DFF 모델의 경우 트럭이 완전히 지워지지 않고 artifact가 남아 있는 것을 볼 수 있지만, Gaussian Grouping은 트럭만을 깔끔하게 제거했다. Train scene에서는, DFF는 기차를 구분하지 못하고 모든 가우시안을 삭제했지만, Gaussian Grouping은 기차를 잘 구분하여 삭제한 것을 확인할 수 있다.

Object inpainting task는 먼저 object removal을 하고 구멍 부분만을 다시 fine-tuning하는 과정을 거친다. 위 그림을 보면 Gaussian Grouping은 SPIn-NeRF에 비해 학습 시간이 짧으면서도 inpainting 결과가 더 좋은 것을 볼 수 있다.

Object style transfer task에서는 Gaussian Grouping과 Instruct-NeRF2NeRF를 비교한다. 둘 모두 'turn the bear into a panda'라는 prompt와 함께 InstructPix2Pix에서 나오는 image guidance를 동일하게 입력으로 받았다. Gaussian Grouping은 정확한 mask를 통해 곰 부분만을 판다로 바꾸는 것에 반해, Instruct-NeRF2NeRF의 경우 배경이 흐릿해지겨나 품질이 낮아지는 문제가 발생한다.

Multi-object editing task에서는 하나의 scene에서 위에 언급한 removal, inpainting, colorization 등을 여러 물체에 대해 한꺼번에 수행하는 것을 말한다. Gaussian Grouping이 주어진 prompt를 잘 이행하고 있는 것을 확인할 수 있다.
Ablation Experiments
먼저 Ablation on Mask Cross-view Association 항목에서는 DEVA 모델을 활용하여 mask association을 하는 것의 효과를 다룬다. Mask assignment를 딥러닝으로 해결하는 cost-based linear assignment를 사용했을 때는 training 시간이 매우 느려질 뿐만 아니라 mask 예측의 정확도도 떨어진다. 또한, 학습 초기에는 mask 예측이 거의 랜덤이어서 학습이 unstable해진다는 문제도 있다.
Influence of the Identity Encoding 항목에서는 identity encoding의 크기가 16일 때 좋은 segmentation separation을 보여주면서도 학습을 효율적으로 유지할 수 있다. 크기를 32로 설정하면 reconstruction의 성능은 좋아지지 않지만 학습 속도를 1.3배 늦춘다. Identity encoding은 기존 3DGS의 학습 속도와 렌더링 퀄리티에 큰 영향을 주지 않으면서 segmentation을 효율적으로 수행한다.

Ablation on 3D Regularization Loss 항목에서는 각 가우시안의 identity encoding을 주변 몇 개의 가우시안과 비교할지를 결정하는 파라미터 $k$값에 따른 scene reconstruction과 object removal 정확도를 비교한다. $k = 5$일 때 두 task의 정확도가 균형을 이루는 것을 볼 수 있다.

위 사진은 3D regularization loss를 사용하지 않았을 때의 object inpainting 결과를 나타낸 것이다. 2D identity loss만을 사용했을 때는 곰 동상 내부에 있는 반투명한 가우시안들이 곰으로 classification되지 않아 지워지지 않고 그대로 남아 있는 것을 볼 수 있다. 이는 training 시 물체 속 가우시안들이 물체 표면의 가우시안들에 가려져 렌더링되지 않아 supervision signal을 받지 못하기 때문이다. 3D loss가 이러한 현상을 해결해 준다.
Conclusion
Gaussian Grouping은 identity encoding을 이용하여 3D gaussian들을 segmentation하는 모델이다. SAM mask를 활용하여 mask의 정확도를 높였고, 이를 이용해 다양한 downstream task를 수행할 수 있다.
한계점으로는 off-the-shelf 모델들에 너무 의존한다는 점이 있다. 다양한 task를 수행하기 위해 SAM뿐만 아니라 DEVA, Grounding-DINO, LAMA, InstructPix2Pix 등을 사용하는데, 이러한 모델들의 결과가 좋지 않은 상황에서는 Gaussian Grouping의 정확도도 영향을 받을 수 있다.
개인적으로는 Gaussian Grouping이 목표로 하는 task가 많다 보니 task별로 데이터셋이나 baseline이 잘 정리되지 못한 느낌을 받았다. Mip-NeRF 360과 같은 간단한 데이터셋으로 hyperparameter를 어느 정도 정하고, 실제 테스트는 보다 복잡한 데이터셋에서 수행한 것 같다.