Introduction
인간의 행동 데이터는 physical intelligence를 학습하기 위한 가장 scalable한 데이터 소스 중 하나이다. 인간은 다양한 물체, 환경, task variation에서 dexterous manipulation을 일상적으로 수행하며, 이는 robot teleoperation으로 수집 가능한 데이터 규모를 훨씬 초월한다. 그러나 기존 human-to-robot transfer 연구는 두 가지 한계가 있다: (1) 대부분 수십~수백 시간 규모의 작은 human dataset에 의존하고, (2) gripper나 low-DoF hand에 초점을 맞추어 fine-grained finger articulation이 부재하다.
본 논문은 human-to-robot transfer for dexterous manipulation이 근본적으로 scaling phenomenon임을 보이고, 대규모 egocentric human data 기반의 human-to-dexterous-manipulation transfer framework인 EgoScale을 제안한다. 20,854시간의 action-labeled egocentric human video로 VLA(Vision-Language-Action) 모델을 학습하며, 이는 기존 연구 대비 20배 이상 큰 규모이다. Human data scale과 validation loss 사이의 log-linear scaling law를 발견하고, 이 validation loss가 downstream real-robot 성능과 강하게 상관됨을 보인다.
Scale 외에도, 효과적인 two-stage transfer recipe를 제안한다: (1) 대규모 human pretraining, (2) 소량의 aligned human-robot data로 lightweight mid-training. 이를 통해 long-horizon dexterous manipulation과 one-shot task adaptation이 가능해진다. 최종 policy는 pretraining 없는 baseline 대비 평균 성공률 54% 향상을 달성하며, 22-DoF dexterous hand뿐 아니라 lower-DoF robot에도 효과적으로 transfer된다.

Method
Human Action Representation
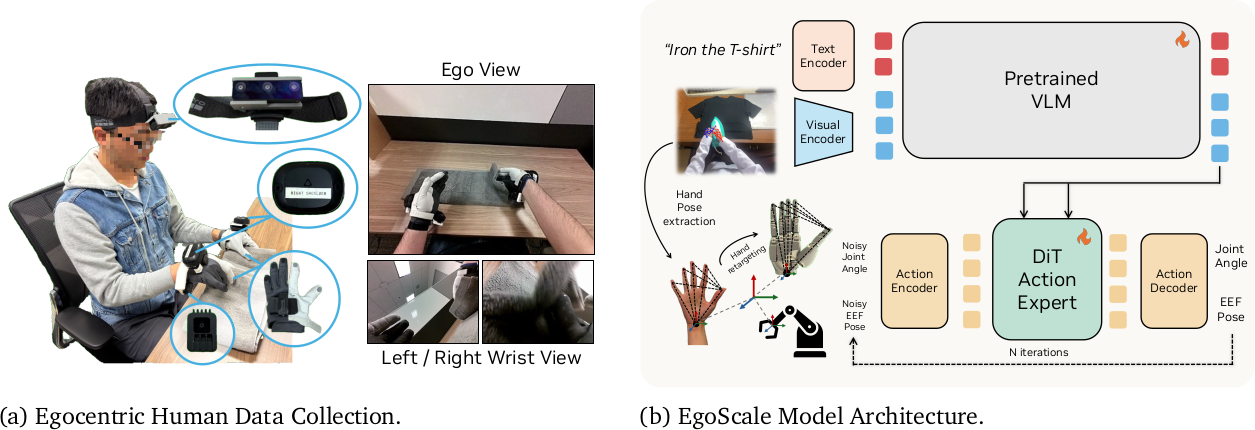
각 human demonstration은 head-mounted 카메라의 egocentric RGB observation과, off-the-shelf perception pipeline으로 추정한 camera motion 및 human hand pose로 구성된다. 이를 통일된 action representation으로 변환한다.
Wrist-level Arm Motion
Global camera pose에 불변인 motion command를 얻기 위해, 연속 timestep 간의 relative wrist motion을 사용한다. Timestep $t$의 action chunk에서 relative end-effector formulation은 $\Delta \mathbf{W}^t = (\mathbf{W}_w^0)^{-1} \mathbf{W}_w^t$로, absolute camera pose에 대한 의존성을 제거하고 물리적으로 의미 있는 arm motion을 포착한다. 이 표현은 human demonstration과 robot execution에서 공유된다.
Hand Articulation
Finger-level 제어를 위해, 21개 human hand keypoint를 optimization 기반 절차로 dexterous robot hand joint space에 retargeting한다. Joint limit과 kinematic constraint를 적용하며, 기본적으로 22-DoF Sharpa hand의 action space를 사용한다. High-DoF hand로 정의되지만, 학습된 모델은 lower-DoF hand에도 효과적으로 transfer된다.
Human Data Sources and Processing
Stage I: Large-Scale Egocentric Human Pretraining Data
총 20,854시간의 대규모 egocentric human activity dataset으로 pretraining한다. 대부분은 in-the-wild egocentric recording으로, 9,869개 scene, 6,015개 task, 43,237개 object를 포함하며 long-tailed manipulation behavior를 폭넓게 커버한다. 모든 녹화는 egocentric RGB 카메라(30 FPS)로 수행되며, off-the-shelf SLAM과 hand-pose estimation pipeline으로 camera motion과 hand trajectory를 복원한다. 추정이 noisy하지만, 데이터의 scale과 diversity가 효과적인 supervision을 제공한다. 이에 더해 Apple Vision Pro로 수집된 829시간의 EgoDex 데이터를 포함하여 higher-precision kinematic signal로 pretraining을 보강한다.
Stage II: Aligned Human-Robot Mid-Training Data
Human demonstration과 robot execution 사이의 embodiment gap을 추가적으로 bridging하기 위해, 소규모의 aligned human-robot dataset을 도입한다. 344개 tabletop manipulation task로 구성되며, 각 task당 약 30개 human trajectory와 5개 robot trajectory를 포함한다(총 약 50시간 human + 4시간 robot). Human demonstration은 로봇과 동일한 카메라 configuration으로 수집하여 visual observation이 직접 비교 가능하다. Stage I이 diversity와 semantic grounding을 제공하고, Stage II가 정밀한 human-robot correspondence를 제공하여, scale과 alignment를 decouple한다.
Model Architecture
GR00T N1과 유사한 flow-based VLA architecture를 사용한다. 매 timestep $t$에서, observation $o_t = (I_t, l_t)$ (이미지 + language instruction)을 vision-language embedding $\phi_t$로 인코딩하고, flow-matching objective로 future action chunk를 예측한다. Robot data의 경우 proprioceptive state $q_t$도 conditioning하며, human demonstration에서는 learnable placeholder token으로 대체하여 architectural 변경 없이 통일된 formulation을 유지한다.
다양한 robot embodiment를 수용하기 위해, lightweight embodiment-conditioned MLP adapter를 input/output interface에 사용한다. Embodiment-specific adapter가 proprioceptive state를 encode하고 hand action을 decode하며, relative wrist motion prediction, vision-language backbone, DiT action expert는 완전히 공유된다.
Training Recipe
Three-stage training pipeline을 사용한다.
- Stage I(human pretraining): 20K시간 egocentric human data로 100K step 학습. 256 GB200 GPU, global batch size 8,192, learning rate $5 \times 10^{-5}$. 이때 VLA 모델의 모든 parameter를 freezing 없이 학습한다.
- Stage II(mid-training): aligned human-robot play dataset으로 50K step 학습. Batch size 2,048, learning rate $3 \times 10^{-5}$. Vision-language backbone은 freeze하고 vision encoder와 DiT action expert만 업데이트한다.
- Stage III(post-training): task-specific robot demonstration으로 10K step fine-tune. Batch size 512, learning rate $3 \times 10^{-5}$.
Robot Systems and Control
Galaxea R1Pro humanoid robot에 22-DoF Sharpa Wave dexterous hand를 장착하여 실험한다. Base와 torso를 고정하고 양팔 각 7-DoF를 relative end-effector space에서 제어한다. Perception system으로 head-mounted egocentric 카메라 1대와 각 wrist 안쪽에 장착된 카메라 2대(총 3대 RGB 카메라)를 사용한다.
Experiment
Experiment Setup

Tasks
5가지 highly dexterous manipulation task를 설계한다. 각 task는 100개 teleoperated robot demonstration을 제공한다(Shirt Rolling은 20개).
- Shirt Rolling: 양손으로 T-shirt를 교대로 접고 말아 원통 형태로 만든 뒤 바구니에 넣는 task.
- Card Sorting: 손가락으로 빽빽한 카드 더미에서 한 장을 분리하여 색상에 맞는 홀더에 삽입하는 task.
- Tongs for Fruit Transfer: 도구함에서 집게를 잡고 과일을 집어 목표 위치에 놓는 dexterous tool use task.
- Unscrewing a Bottle Cap: 병뚜껑을 잡고 연속적으로 회전시켜 제거하는 task. 4종류 병에 각 25개 trajectory.
- Syringe Liquid Transfer: 주사기를 집어 tube A에서 액체를 추출, tube B에 주입, 주사기를 쓰레기통에 버리는 long-horizon multi-step task.
Evaluation Metric
각 method를 2개 random seed로 학습하고, 각 checkpoint당 10회 trial(Bottle은 4종 x 4회 = 16회)로 평가한다. Image-overlay 기반 initialization으로 초기 조건의 variability를 줄인다. Absolute task success rate과 fine-grained task completion score를 기록한다.
Large-Scale Human Pretraining Is Key to Strong Performance
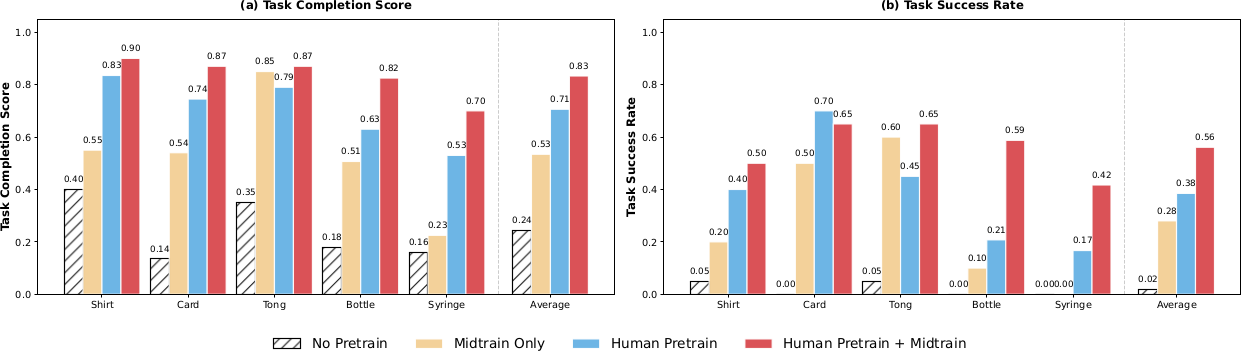
4가지 checkpoint를 비교한다: (1) from scratch, (2) mid-training only, (3) human pretraining only, (4) human pretraining + mid-training. 모든 task에서 human pretraining이 from scratch 대비 평균 task completion 55% 향상을 가져온다. 주목할 점은, noisy하고 unconstrained하며 task-aligned되지 않은 대규모 human data만으로도 mid-training-only baseline을 대부분의 task에서 능가한다는 것이다. 이는 human demonstration의 scale과 diversity가 정밀한 embodiment alignment 없이도 dexterous manipulation에 강한 inductive bias를 제공함을 보여준다.
Human pretraining과 소량의 aligned mid-training을 결합하면 최고 성능을 달성한다. 대규모 human data가 general manipulation structure를 제공하고, mid-training이 이 표현을 executable robot control에 anchoring하는 상호 보완적 효과를 보인다.
Policy Performance Scales with Pretraining Data Size
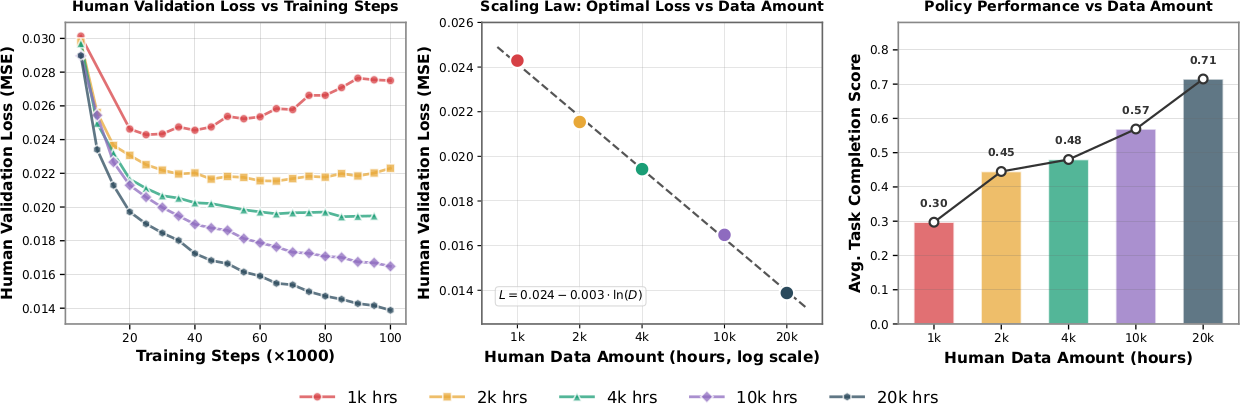
1k, 2k, 4k, 10k, 20k 시간의 human data로 pretraining한 모델을 비교한다. Human data 양이 증가할수록 downstream robot performance가 consistent하게 향상되며, average task completion이 1k시간의 0.30에서 20k시간의 0.71로 단조 증가한다. Saturation 징후는 관찰되지 않는다.
Held-out human-video validation set에서의 action prediction loss를 분석하면, 작은 dataset(1k-2k시간)은 초기에 loss가 감소하다 plateau되거나 overfitting이 발생하는 반면, 큰 dataset(10k-20k시간)은 안정적이고 단조적인 improvement를 보인다. Data scale에 대한 수렴 시 optimal validation loss를 plot하면, 거의 완벽한 log-linear scaling law가 관찰된다:
$\mathbf{L} = 0.024 - 0.003 \cdot \ln(\mathbf{D})$
여기서 $D$는 human pretraining data의 시간 수이며, fitted curve의 $R^2 = 0.9983$이다. 이 offline scaling behavior가 real-robot performance와 강하게 상관되어, human validation loss가 embodied control capability의 의미 있는 indicator임을 확인한다.
Aligned Mid-Training Enables One-Shot Transfer

Aligned human-robot mid-training이 극도로 제한된 robot supervision으로도 unseen skill 학습을 가능하게 하는지 검증한다. Mid-training data에 포함되지 않은 두 가지 task, Fold Shirt와 Unscrewing Water Bottles에서, 단일 robot demonstration과 100개의 aligned human demonstration만으로 post-training한다.
대규모 human pretraining 또는 aligned mid-training 중 하나라도 빠지면 one-shot setting에서 실패한다. 반면 Pretrain + Midtrain 모델은 Fold Shirt에서 0.88, Unscrewing Water Bottles에서 0.55의 성공률을 달성하여 강한 few-shot generalization을 보인다. 이는 mid-training data에서의 shared motion structure(common motion primitive)가 단일 robot demonstration만으로도 transfer를 가능하게 함을 시사한다.
Human Pretraining Enables Cross-embodiment Transfer
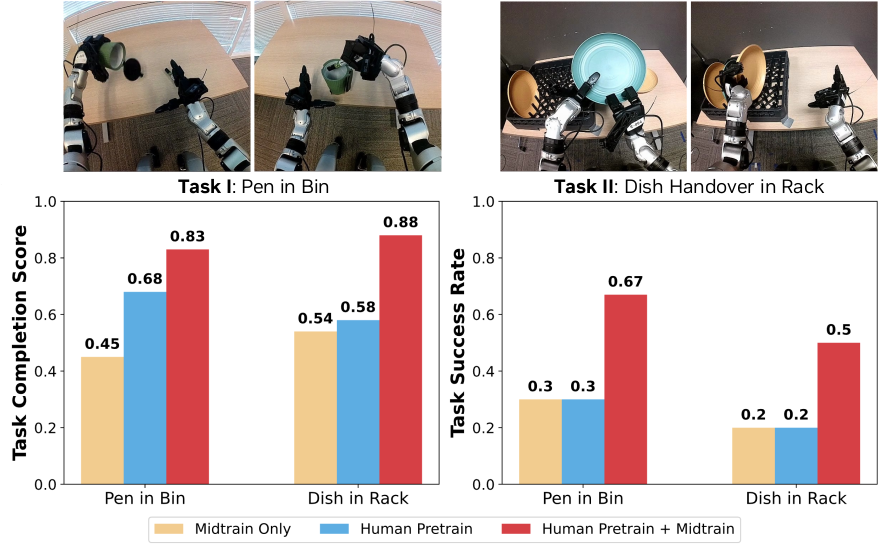
Human pretraining이 substantially different robot embodiment에도 transfer 가능한지 검증한다. Unitree G1 로봇(shorter arm, reduced workspace, 7-DoF tri-finger hand)에서 두 가지 task(Pen in Bin, Dish in Rack)를 평가한다. G1 embodiment play data를 mid-training mixture에 포함하면, G1 embodiment-specific data만으로 학습한 것 대비 큰 성능 향상을 달성한다. 이는 human pretraining이 reusable manipulation structure를 학습하고, mid-training이 이를 새로운 embodiment의 sensing/control interface에 adapt시킴을 보여준다.
Hand Action Space Design for Human Pretraining
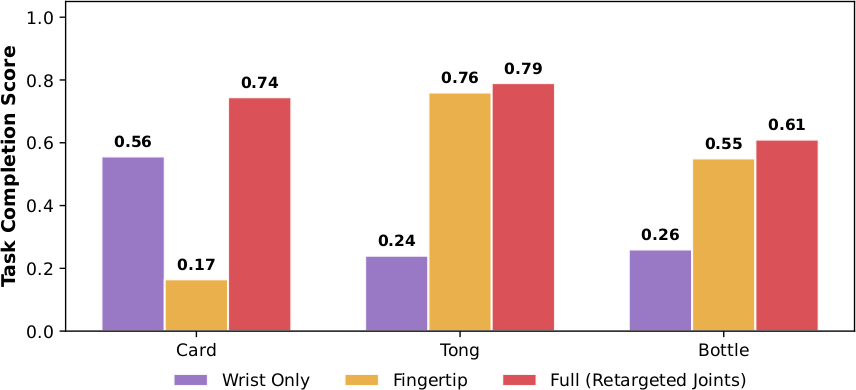
Human hand action representation의 선택이 downstream performance에 미치는 영향을 비교한다. (1) Wrist-only: finger-level supervision을 제거. 모든 task에서 가장 낮은 성능. 특히 정밀한 finger articulation이 필요한 Cards, Tongs에서 취약하다. (2) Fingertip-based: wrist와 fingertip의 $\mathbb{SE}(3)$ trajectory를 예측. 일부 task에서 개선되지만 inconsistent. Fingertip pose의 small error가 retargeting 후 implausible joint configuration을 유발한다. (3) Full retargeted joints(default): 22-DoF joint-space hand action. 모든 task에서 가장 consistent한 성능을 보여, large-scale human pretraining에 가장 practical하고 effective한 선택이다.
Related Work
Robot Learning from Human Data
Human demonstration을 활용한 robot learning 연구는 초기에 human video를 representation learning이나 intent inference에 활용했으며, 이후 planning이나 high-level control에 사용하되 low-level execution은 robot demonstration에 의존했다. 최근 EgoMimic, DexWild 등은 human과 robot demonstration을 co-train하는 unified imitation policy를 제안하고, EgoVLA는 human hand motion에 대해 VLA를 pretraining한다. 본 논문은 이들과 달리 pure large-scale human pretraining에 초점을 맞추어, wrist motion과 dexterous hand articulation 모두를 diverse egocentric human video에서 직접 학습하며, 기존 방법 대비 훨씬 큰 규모의 human data에서 systematic한 scaling 효과를 보인다.
Scaling Properties in Robot Learning
Language와 vision에서 관찰된 scaling law가 robot learning에도 적용되는지 연구가 진행되고 있다. 대규모 robot dataset과 foundation-style policy에서 data diversity가 증가하면 robustness와 generalization이 향상됨이 보고되고 있다. 기존 연구가 주로 robot-collected data의 scaling에 초점을 맞추는 반면, 본 논문은 diverse in-the-wild human egocentric data의 scaling이 dexterous manipulation에 systematic한 gain을 가져옴을 보인다.
Learning Dexterous Manipulation
Dexterous manipulation은 analytic/control 기반 grasping에서 learning 기반 접근으로 발전해왔다. Grasp affordance, contact map, hand-object interaction field 등의 structured representation이 도입되었으며, 최근에는 unified perception and control로 generalizable multi-fingered manipulation policy를 학습하려는 시도가 있다. 그러나 high-dimensional action space와 dexterous hand hardware의 한계로 scaling이 어렵다. 본 논문은 egocentric human video와 dense hand tracking을 alternative supervision source로 활용하여 이 문제를 해결한다.
Conclusion
본 논문은 dexterous manipulation을 위한 human-to-robot transfer가 근본적으로 scaling phenomenon임을 보였다. 20K시간 이상의 egocentric human manipulation data로 VLA policy를 pretraining한 EgoScale은, human action prediction loss와 data scale 사이의 log-linear scaling law를 발견하고, 이 loss가 real-robot performance와 강하게 상관됨을 확인했다. Large-scale human pretraining과 소량의 aligned human-robot mid-training을 결합하는 simple yet effective transfer recipe를 통해, long-horizon dexterous manipulation, emergent one-shot adaptation, 다른 robot embodiment로의 cross-embodiment transfer를 달성했다.
향후 방향으로는 (1) 탐색된 범위 내에서 saturation이 관찰되지 않으므로, human data와 model capacity를 함께 scaling하면 추가적인 gain이 가능할 수 있다. (2) Weaker/unlabeled video를 self-supervised objective로 활용하면 이점이 더 증폭될 수 있다. (3) Robotic hardware가 human-like kinematics에 가까워질수록 embodiment gap이 줄어들어, 더 강한 transfer와 잠재적으로 zero-shot execution이 가능해질 수 있다.