Introduction
대규모 데이터를 활용한 supervised learning이 LLM과 vision model에서 큰 성공을 거둔 반면, autonomous robot manipulation에는 아직 이 법칙이 적용되지 못하고 있다. 핵심 과제는 (1) 어떤 데이터를 수집해야 하는지, (2) 그 데이터를 어떻게 필요한 규모로 수집할 수 있는지이다.
현재 주된 데이터 수집 방식인 teleoperation은 물리적 로봇 하드웨어에 의존하여 scaling에 한계가 있다. 반면 in-the-wild Internet video는 대규모이지만 정밀한 annotation이 부재하여 dexterous manipulation 학습에 부적합하다. 본 논문은 이 둘의 중간 경로를 탐색한다. 3D hand pose annotation이 paired된 egocentric human video이다. 이 접근은 wearable headset과 smart glass가 보편화되면서 가능해졌다.
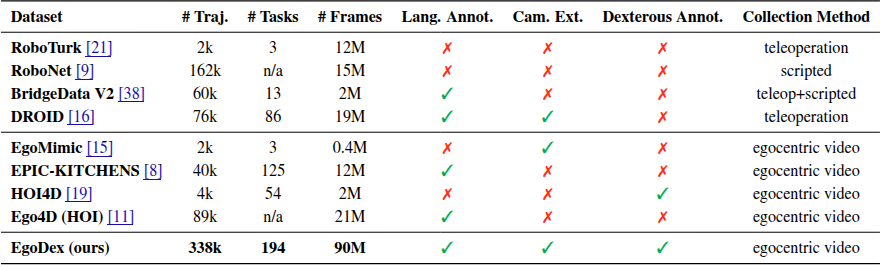
본 논문에서는 Apple Vision Pro로 수집한 대규모 egocentric dataset인 EgoDex를 소개한다. EgoDex는 829시간의 30 FPS egocentric video와 skeletal data로, 총 9천만 프레임, 338,000개 task demonstration, 194개 tabletop manipulation task로 이루어져 있다. 기존 dataset 대비 trajectory, task, frame 수가 가장 크며, language annotation, camera extrinsic, dexterous annotation을 모두 갖추고 있다. 또한 hand trajectory prediction을 위한 imitation learning policy를 체계적으로 평가하여 benchmark와 metric을 제안한다.
Related Work
Large-Scale Manipulation Datasets
기존 robot teleoperation dataset(RoboTurk, BridgeData, RT-X, DROID)은 수백 시간의 데이터를 포함하지만, teleoperation은 물리적 로봇과 operator가 필요하여 현재 규모 이상으로 scaling하기 어렵다. Ego4D, EPIC-KITCHENS 같은 대규모 egocentric video dataset은 더 scalable하지만 manipulation에 초점을 두지 않고 3D hand pose annotation이 없다. Hand-object interaction 연구는 3D hand pose를 제공하지만 manual annotation에 의존하여 EgoDex보다 규모가 작고, grasping 위주이다.
Scalable Methods for Robot Data Collection
Universal manipulation interface(handheld gripper), motion capture glove, augmented reality 기반 robot-free demonstration 등 scalable한 데이터 수집 방법이 제안되었다. 그러나 이들은 모두 active data collection을 요구하며, Internet 규모의 데이터처럼 인간 활동의 passive byproduct로 수집되지 않는다는 한계가 있다.
Learning from Human Video
Internet video에서 visual representation이나 grasp affordance를 학습하는 연구가 있지만, raw unstructured video는 dexterous manipulation task와의 image distribution gap이 크고 motor action label이 없다. HaMeR 같은 3D hand prediction network으로 후처리할 수 있으나, multiple viewpoint와 camera extrinsic 없이는 정확도가 떨어진다. EgoDex는 수집 시점에 Vision Pro의 multiple calibrated camera와 on-device SLAM, production-grade hand prediction network으로 3D head 및 hand tracking을 직접 포함하여 정밀한 annotation을 제공한다.
EgoDex Dataset
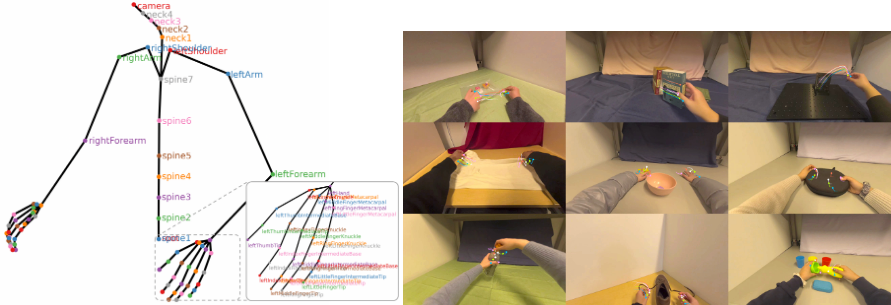
Modalities
데이터는 다음 5가지 modality로 구성된다:
- $1920 \times 1080$ 해상도, 30 Hz egocentric RGB video
- 30 Hz camera intrinsic 및 extrinsic
- 30 Hz 전체 upper body joint의 3D position 및 orientation (각 hand 25개 joint 포함)
- 30 Hz skeletal joint별 pose prediction confidence value
- Manipulation에 대한 natural language annotation
Language annotation은 data collector가 task name, task description, 환경, 조작 대상 object 등의 metadata를 기록하고, GPT-4가 이를 단일 detailed natural language description으로 통합한다.
Task Types
EgoDex는 3가지 유형의 task로 구성된다:
- Reversible: 서로 inverse인 task pair. 한 task의 final state 분포가 inverse task의 initial state 분포에 해당한다(예: 충전기 연결/분리).
- Reset-free: final state가 자체 initial state 분포 내에 있는 task. 환경 reset이 불필요하다(예: 공 던지고 받기).
- Reset: 각 demonstration 후 환경을 초기 상태로 reset해야 하는 task.
Reversible과 reset-free task는 costly한 환경 reset을 제거하여 data collection의 효율을 높인다.
Diversity
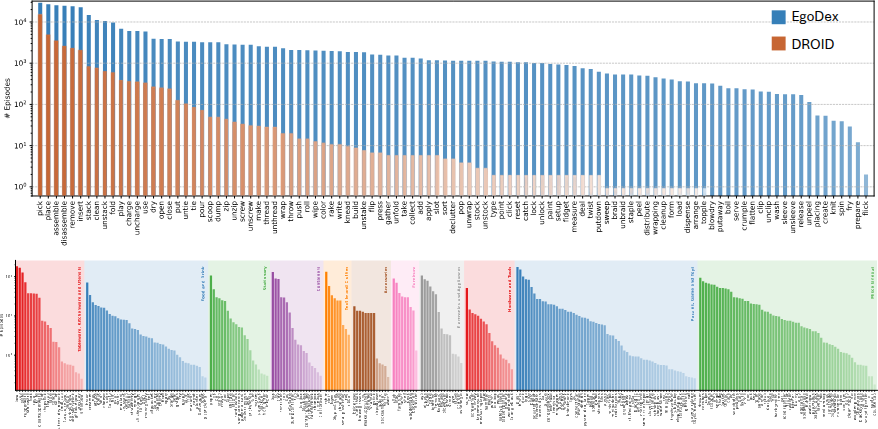
EgoDex는 dexterous manipulation behavior의 diversity에 중점을 둔다. 나사 조이기, 신발끈 묶기, 카드 나누기, 페이지 넘기기, 테니스공 잡기, 배터리 끼우기 등 단순 pick-and-place를 훨씬 넘어서는 194개 task를 포함한다. Verb 분포를 분석하면, verb당 1000개 이상의 demonstration으로 구성된다. Scene diversity는 tabletop 환경에 한정되지만, image-to-image augmentation 등으로 보완 가능하다.
EgoDex Benchmarks
Action Representation
Dexterous manipulation에 충분한 bimanual dexterity를 포착하는 action representation을 설계한다. 시간 $t$의 action $a_t$는 각 wrist의 3D position, 각 wrist의 6D orientation, 각 fingertip의 3D position으로 구성된다: 2 hands $\times$ (3 + 6 + (3 $\times$ 5 fingertips)) = 48 차원. Action은 fixed time horizon에 걸쳐 chunk로 예측되며, current camera frame 기준 relative trajectory로 표현한다.
Benchmarks
두 가지 benchmark task를 제안한다:
- Dexterous trajectory prediction: egocentric image observation, skeletal joint pose, natural language description으로부터 주어진 time horizon 동안의 hand trajectory를 예측한다: $f_\theta(o_{0..t}, s_{0..t}, l) = \hat{a}_{t:t+H}$
- Inverse dynamics: 현재까지의 observation에 더해 time horizon 끝의 goal image가 추가로 주어지며, 그 사이의 hand trajectory를 예측한다. Visually goal-conditioned policy로 해석할 수 있다: $f_\theta(o_{0..t}, s_{0..t}, o_{t+H}, l) = \hat{a}_{t:t+H}$
각 benchmark는 prediction horizon $H$로 parameterize된다(예: $H = 30$은 1초, $H = 90$은 3초). 1%의 데이터를 held-out test set으로 설정하여 fully reproducible한 평가를 보장한다.

Evaluation Metrics
자연스러운 human motion은 inherently multimodal하므로, 단일 predicted trajectory를 ground truth와 비교하는 것은 불충분하다. 따라서 "best of $K$"" metric을 사용한다. 각 test data point에 대해 모델을 $K$번 sampling하고, ground truth trajectory와 가장 가까운 trajectory와의 거리를 측정한다. 거리는 predicted 3D keypoint position과 ground truth 3D counterpart 간의 Euclidean distance로, predicted chunk의 각 timestep과 12개 keypoint(각 hand의 wrist + 5 fingertip)에 대해 평균한다. 이 값은 3D space에서의 average positional error(단위: meter)로 해석된다.
Experiments
X-IL framework의 state-of-the-art imitation learning policy를 학습하고 평가한다. 2가지 Transformer model architecture(encoder-decoder, decoder-only)와 3가지 policy representation(behavior cloning, denoising diffusion, flow matching)을 조합하여 총 14개 모델을 학습한다. 모든 모델은 A100 GPU 8개에서 batch size 2048로 50,000 step 학습한다.
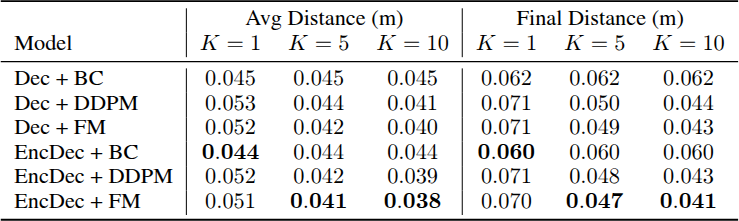
Key Findings
Encoder-Decoder Outperforms Decoder-Only
모든 encoder-decoder(EncDec) 모델이 decoder-only(Dec) 모델을 consistently 소폭 능가한다.
Different Policy Representations Excel in Different Settings
Encoder-decoder flow matching(EncDec + FM) 모델이 $K = 5$, $K = 10$에서 최고 성능을 달성한다. $K$가 증가할수록 denoising diffusion(DDPM)과 FM의 성능이 개선되는 반면, deterministic인 behavior cloning(BC)은 $K$와 무관하다. 다만 $K = 1$에서는 BC가 diffusion과 flow matching을 약 15% 능가하여, BC의 average prediction이 더 낫지만 DDPM/FM의 best prediction이 BC의 single prediction보다 우수함을 보여준다.
Performance Degrades as Prediction Horizon Increases

Prediction horizon을 2초에서 1초로 줄이면 average/final distance가 31%/21% 개선되고, 3초로 늘리면 18%/11% 악화된다. 48차원 dexterous action을 더 먼 미래까지 예측할수록 난이도가 증가한다.
Visual Goal-Conditioning Significantly Improves Performance
Visual goal-conditioning(goal image 제공)은 average distance를 22%, final distance를 53% 감소시킨다. Goal image가 predicted trajectory의 endpoint를 visual "anchor"로 제공하여 multimodality를 완화한다.
Medium-Size Model Capacity Is Sufficient
Default 200M parameter 모델과 500M parameter 모델이 동일한 성능(average distance 0.045, final distance 0.062)을 달성한다. 현재 dataset 규모에서는 medium-size 모델이 충분하며, commodity GPU에서도 실행 가능하다.
Performance Scales with Dataset Size
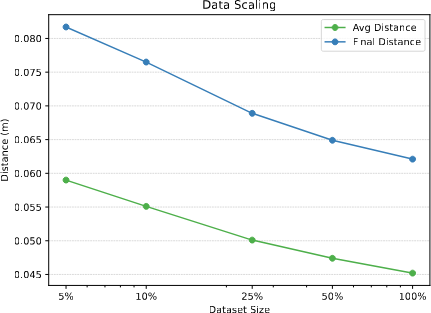
Dataset size가 증가할수록 average distance와 final distance가 모두 개선된다. Log-scale에서 dataset size에 대해 성능이 지속적으로 향상되어, 대규모 egocentric dataset 수집의 가치를 입증한다.
Research Use Cases
Robotics
인간의 외형, kinematics, dynamics를 모방하는 robot embodiment가 있다면, egocentric video를 3D arm 및 hand pose delta로 매핑하는 control policy를 zero-shot으로 배포할 수 있다. Embodiment gap bridging 방법으로는 (1) 소규모 robot data와 co-training, (2) 대규모 human data pretraining 후 소규모 robot data fine-tuning, (3) human data로 visual encoder 학습, (4) human-object interaction trajectory에서 manipulation prior 학습 후 RL/IL fine-tuning이 제안된다.
Perception
Action recognition, human-object interaction detection, active object detection, state change prediction, contact point/grasp/trajectory modeling, object affordance 학습 등 다양한 egocentric perception task에 활용 가능하다.
Video Generation and World Models
대규모 egocentric video data와 3D pose, language annotation을 제공하므로, egocentric viewpoint에서의 video generation과 world model 학습을 가능하게 한다. 다만 Egocentric 시점에서의 world model은 viewpoint 변동, temporal/spatial consistency, agent-centric interaction 반영 등 고유한 어려움이 있다.
Conclusion
본 논문은 다양한 dexterous manipulation task에 대한 3D pose annotation이 있는 대규모 egocentric video dataset인 EgoDex를 소개했다. Hand trajectory prediction을 위한 imitation learning policy를 학습하고 평가하여 benchmark와 metric을 제안했다. EgoDex는 task와 manipulation behavior에서 높은 diversity를 보이지만, background 및 scene diversity에는 한계가 있으며, heavy occlusion이나 고속 motion에서 dexterous annotation이 불완전할 수 있다. 향후 procedural background randomization과 더 다양한 환경에서의 데이터 수집이 계획되어 있다.