Introduction
Vision foundation model은 대규모 시각 데이터로 학습되어 open-world에서 뛰어난 reasoning 및 planning 능력을 보여주지만, 이를 로봇에 적용할 때 핵심 과제는 visual data와 action data 사이의 modality gap이다.
Dr. Robot (Differentiable Rendering of Robots)은 로봇의 시각적 외형에서 제어 파라미터까지 완전히 미분 가능한 로봇 self-model이다. 아래 세 가지 핵심 구성요소를 통해 고품질 gradient를 얻는다.
- Gaussians Splatting: canonical pose에서의 로봇 외형을 3D Gaussian으로 모델링하여 differentiable rasterizer를 통해 렌더링
- Implicit Linear Blend Skinning (LBS): 기존 LBS를 Gaussian splitting에 호환되도록 확장, differentiable forward kinematics와 결합하여 3D Gaussian을 목표 pose로 변형
- Pose-Conditioned Appearance Deformation: pose에 따라 3D Gaussian의 spherical harmonics, scale, opacity, covariance를 변화시키는 외형 변형 모델
Dr. Robot 방식의 효과를 검증하기 위해 in-the-wild 비디오에서의 robot pose reconstruction 등 다양한 태스크에서 성능을 평가한다.
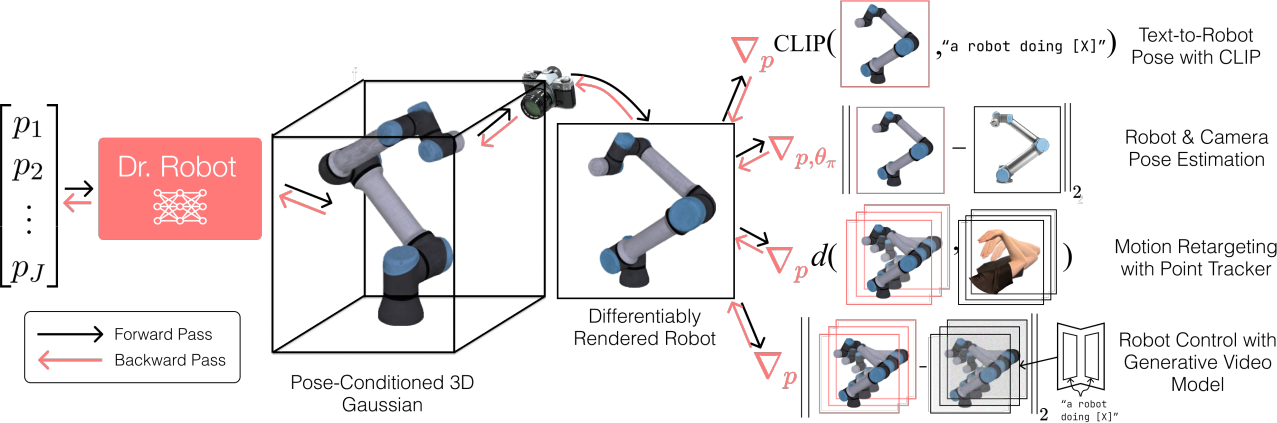
Approach
Overview and Formulation

로봇 pose $\mathbf{p}$가 주어졌을 때, 임의의 카메라 시점에서의 로봇의 appearance $\mathbf{I}$를 differentiable function $f$로 모델링한다:
$\mathbf{I} = \pi(f(\mathbf{p}))$
여기서 $\pi$는 pinhole camera model 하의 image formation process이다. $f$를 differentiable function으로 구성하기 위해 세 가지 성질이 필요하다: full-body differentiability, deformability, rendering efficiency. 이를 각각 forward kinematics (FK), linear blend skinning (LBS), Gaussians Splatting (GS)으로 구현한다.
Forward Kinematics
Pose $\mathbf{p}$가 주어지면, joint $j$의 위치와 방향을 base joint 0에 대한 homogeneous matrix $T_j(\mathbf{p})$로 표현한다. 이는 kinematic chain을 따라 parent joint들의 rigid transformation을 곱한 것이다:
$T_j(\mathbf{p}) = \prod\limits_{i=0}^{j-1} A_i(\mathbf{p}_i) \quad \text{for} \quad A_i(\mathbf{p}_i) = \begin{bmatrix} R_i^{i-1} & o_i^{i-1} \\ \mathbf{0} & 1 \end{bmatrix}$
Canonical Gaussians Splatting
Canonical pose의 로봇을 static 3D scene으로 취급하여 3D Gaussian $\mathcal{G}$로 표현한다. 각 Gaussian은 다음과 같이 표현된다:
$g_k = \mathcal{N}(\mu_k, RSS^TR^T)$
여기서 $\mu_k$는 평균, $R$은 rotation matrix, $S$는 scaling matrix이다. 추가로 27차원 spherical harmonics 계수 $\mathbf{c}_{shs}$와 opacity $o$가 렌더링 시 외형을 표현한다. 최적화 과정에서 매 $N$ step마다 Gaussian을 split하여 밀도를 높이고, 낮은 opacity의 Gaussian은 truncate한다.
Implicit Linear Blend Skinning (LBS)
Canonical 3D Gaussian splatting은 static pose만 모델링할 수 있으므로, 임의의 pose에서 렌더링하려면 Gaussian을 3D 공간에서 재배치하는 geometric deformation function이 필요하다. SMPL을 따라 linear blend skinning (LBS)을 사용하되, 3D Gaussian의 splitting과 truncation으로 인해 고정된 vertex set을 가정하는 기존 LBS와 호환되지 않는 문제를 해결하기 위해 implicit LBS를 제안한다.
Implicit LBS function $W(\mu): \mathbb{R}^3 \to \mathbb{R}^J$는 임의의 3D 좌표를 입력받아 $J$개 joint transform의 영향을 나타내는 weight를 출력한다. Gaussian의 position $\mu$에 대한 geometric deformation function $D$는 다음과 같다:
$D(\mu, \mathbf{p}) = \sum_{j=1}^{J} W(\mu)_j T_j(\mathbf{p}) \mu$
Appearance Deformation
Geometric deformation만으로는 3D Gaussian의 위치만 변경되므로, pose에 따른 외형 변화(rotation matrix $R_k$, scaling matrix $S_k$, spherical harmonics 계수 $\mathbf{c}_{shs,k}$, opacity $o_k$)도 모델링해야 한다. Appearance deformation function $X$는 canonical 및 projected position과 pose를 조건으로 이러한 파라미터 변화를 예측한다:
$(\Delta R_k, \Delta S_k, \Delta o_k, \mathbf{c}_{shs,k}) = X(\mu_k, \mathbf{p})$
Implicit LBS와 동일한 MLP 아키텍처를 공유하며, 입출력 차원만 다르다.
Optimization
Canonical GS $\mathcal{G}$와 로봇 pose $\mathbf{p}$가 주어지면, 최종 posed GS $\mathcal{G}^p$는 다음과 같다:
$f(\mathbf{p}) = \mathcal{G}^p = X(D(\mathcal{G}, \mathbf{p}), \mathbf{p})$
카메라 viewpoint $\pi$와 visual observation $I$가 주어지면, prediction과 observation 사이의 MSE를 최소화하여 전체 로봇 모델을 학습한다:
$\min\limits_{\theta_X, \theta_W, \theta_\mathcal{G}} L = ||I - \pi(X(D(\mathcal{G}, \mathbf{p}), \mathbf{p}))||_2$
학습 데이터는 로봇의 URDF 파일을 기반으로 MuJoCo에서 10K pose, 각 12개 viewpoint로 촬영한 이미지를 사용한다.
Test-Time Optimization
테스트 시에는 image gradient를 통해 다양한 objective에 대해 로봇 action을 최적화할 수 있다. Visual foundation model에서 계산된 visual reward 등을 목적함수로 사용할 수 있다.
Experiments
Self Model Quality
로봇 3DGS 자체의 렌더링 품질과 geometry 정확도를 평가한다. 렌더링 품질은 PSNR, geometry는 target pose Gaussian과 ground truth pointcloud 사이의 Chamfer distance로 측정한다. Deformable Gaussians, nearest neighbor, random, no deform (appearance deformation 제거 ablation) 등과 비교한다.
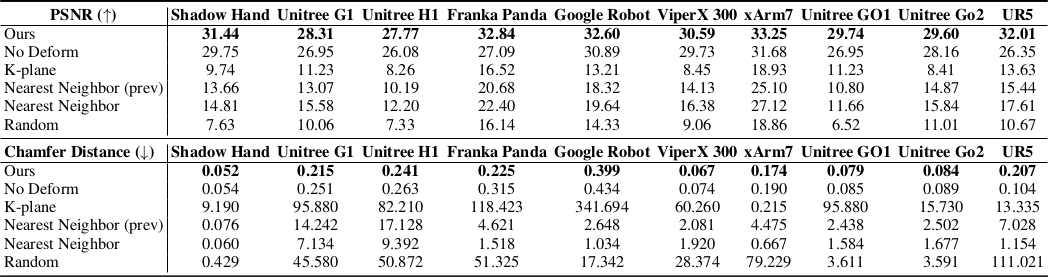
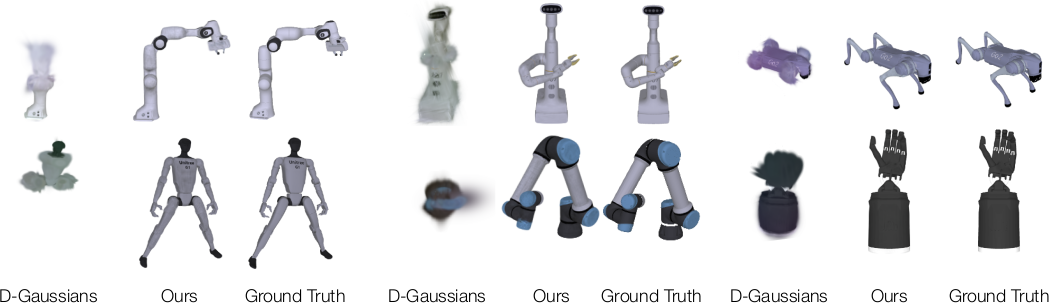
LBS를 geometric deformation의 prior로 사용하는 것이 fidelity에 큰 영향을 미치며, K-plane 기반의 Deformable Gaussians와 비교하여 특히 많은 chained joint를 가진 Panda Arm 같은 로봇에서 격차가 크다. 다양한 로봇 하드웨어에서 일관되게 우수한 성능을 보인다.
Robot Pose Reconstruction
Dr. Robot의 gradient 품질을 평가하기 위해 단일 in-the-wild 이미지로부터 robot joint angle을 추정한다. 단일 RGB 이미지 $I$가 주어지면, robot pose $\mathbf{p}$와 camera pose $\theta_\pi$를 공동으로 최적화한다:
$\min\limits_{\mathbf{p}, \theta_\pi} \mathcal{L}_{Rec}(\mathbf{p}, I) = ||I - \pi(f(\mathbf{p}))||_2$

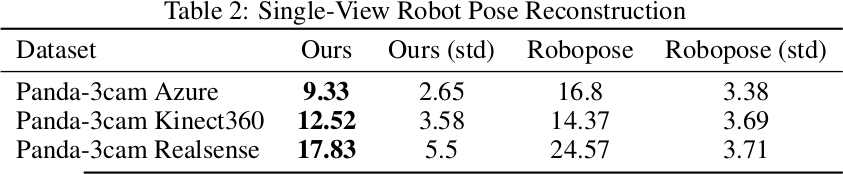
Panda-3CAM 데이터셋(약 10K 이미지)에서 기존 SOTA인 Robopose 대비 32.9% 향상된 성능을 달성한다. Azure, Kinect360, Realsense 세 가지 카메라 플랫폼에서 일관되게 우수하며, gripper pose까지 정확하게 복원할 수 있다.
Applications
Text to Robot Pose with CLIP
CLIP의 image-language similarity를 활용하여, 렌더링된 로봇 이미지와 text prompt 사이의 유사도를 최대화하도록 joint angle을 최적화한다:
$\min\limits_{p} \mathcal{L}_{CLIP}(\mathbf{p}; \text{text prompt}) = \mathcal{C}(\text{text prompt}, \pi(f(\mathbf{p})))$
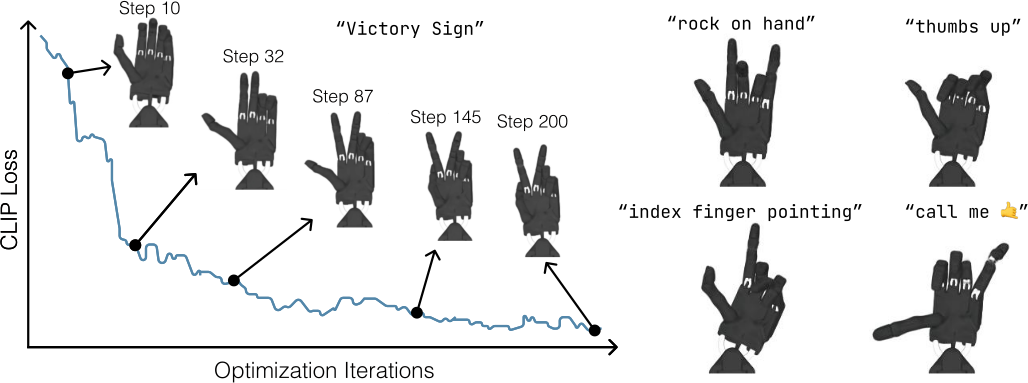
Shadow Hand의 24차원 action space에서 CLIP gradient만으로 "victory sign", "thumbs up", "rock on hand" 등 text prompt에 대응하는 의미적으로 유의미한 hand pose를 생성할 수 있다.
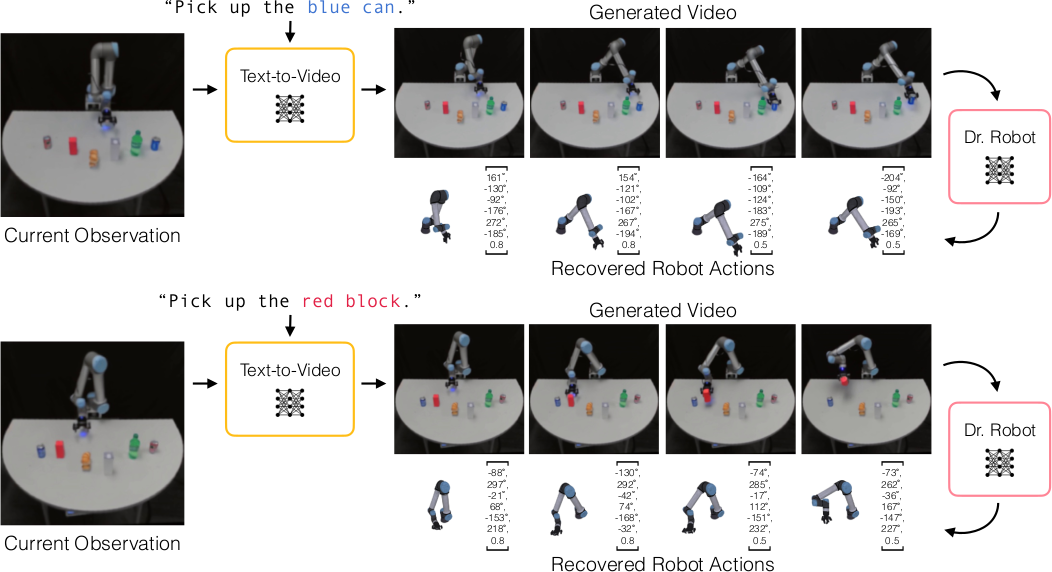
Text to Action Sequences with Video Model
Generative video model을 활용하여 text-conditioned robot control을 수행한다. Stable Video Diffusion을 ASU Table Top 데이터셋 100 에피소드로 fine-tuning하고, 테스트 시 novel language prompt로 비디오를 생성한 뒤, Dr. Robot으로 각 프레임에서 robot pose를 reconstruction하여 action sequence를 추출한다.
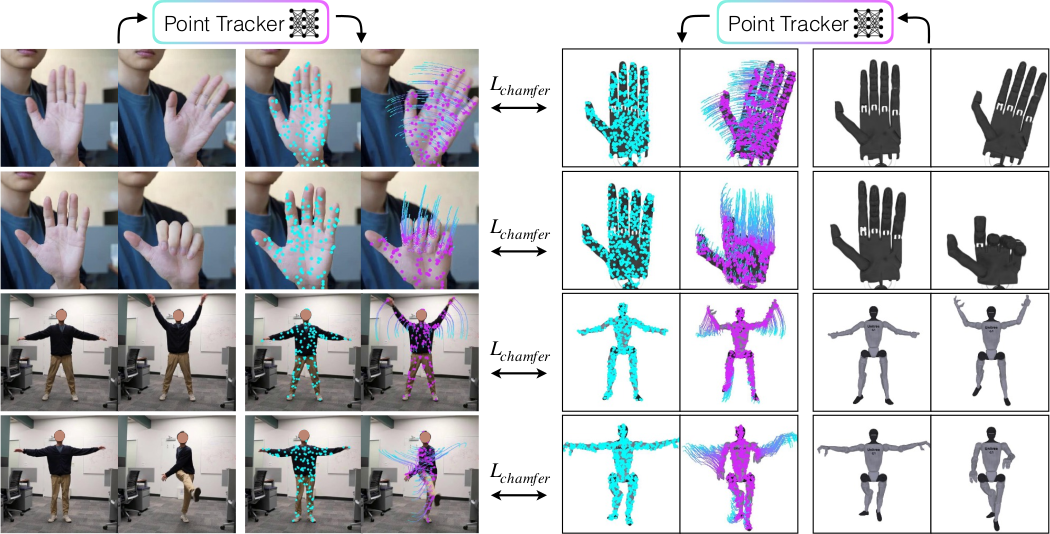
Visual Motion Retargeting with Point Tracking
Point tracking model $\mathcal{P}$와 differentiable renderer $\pi$를 결합하여 motion retargeting을 수행한다. 로봇 위의 초기 point $c_0^r$을 시간에 따라 추적하여 $c_{1:T}^r = \mathcal{P}(c_0^r, \pi(\mathbf{p}_{1:T}))$을 얻고, 목표 point $c_{1:T}$과의 Chamfer distance를 최소화한다:
$\mathcal{L}_{Track}(\mathbf{p}_{1:T}; c_0^r, c_{1:T}) = \sum\limits_{1=t}^{T} d(c_t, \mathcal{P}(c_0^r, \pi(\mathbf{p}_{1:T}))_t)$
Related Works
Differentiable Rendering
Differentiable rendering은 3D 표현을 2D 이미지로 변환하면서 gradient 계산을 가능하게 한다. Mesh, voxel, point cloud 등 기존 explicit 표현에서 NeRF, DeepSDF, Occupancy Networks 등 neural 3D 표현으로 발전했으며, 최근 3D Gaussian Splatting이 효율적인 differentiable rasterization을 제공한다.
Visual Foundation Models for Robotics
Video prediction과 contrastive learning을 통한 visual representation 학습, masked autoencoding, visual pretraining에서의 reward function 도출 등이 연구되고 있다. Text-to-video generative model을 world simulator로 활용하거나 planning에 사용하는 연구도 활발하다. Dr. Robot은 이러한 visual foundation model과 로봇의 action parameter를 image gradient를 통해 연결하는 interface를 제안한다.
Conclusion
본 논문에서는 kinematics-aware deformable model과 Gaussian Splatting을 통합하여 visual data와 robotic action data 사이의 modality gap을 연결하는 differentiable robot rendering 방법을 제안하였다. 다양한 로봇 형태와 DoF에 호환 가능하며, 효율적이고 효과적인 gradient를 제공하므로 픽셀로부터 직접 로봇을 제어할 수 있다. Vision foundation model과 robotics의 미래 응용을 위한 기반이 될 것이다.
Limitations and Future Work
- Lighting Effects: 환경 조명 변화(저조도 등)에 적응하도록 설계되지 않았기 때문에 이러한 경우 노이즈가 발생할 수 있다. Test-time fine-tuning을 통해 이를 해결할 수 있을 것이다.
- Differentiable Physics: Gaussian Splatting 기반 differentiable physics simulation과 결합하여 로봇과 환경 간 물리적 상호작용을 differentiable하게 모델링할 수 있을 것이다.