Introduction
로봇의 안전한 planning을 위해 map의 각 지점의 uncertainty를 구하는 것은 중요하다. 3DGS를 이용하여 로봇을 위한 지도를 만드는 연구는 많이 진행되었지만, uncertainty를 정량적으로 구하는 것은 여전히 challenge로 남아 있다.
본 논문에서는 Continuous Semantic Splatting (CSS) 모델을 소개한다. 3DGS의 각 가우시안이 kernel 함수가 될 수 있다는 점에서 착안하여, CSS는 2D segmentation 모델과 Bayesian framework를 융합하여 각 3D 가우시안의 semantic uncertainty를 정량적으로 구한다.
또한, 기존 3DGS segmentation 모델들은 아래와 같이 uncertainty가 높은 환경에서 렌더링된 이미지가 부정확할 수 있다.
- 2D에서 segmentation 정보를 넣어 주는 네트워크 자체에 노이즈가 많을 때.
- Novel view에서 보았을 때 필요한 곳에 가우시안이 존재하지 않을 때.
- Novel view에서 여러 객체의 경계가 흐려지면서 서로 다른 semantic category가 혼합될 때.
CSS에서는 uncertainty를 이용해 확률적으로 rasterization하는 새로운 방법을 통해 기존 3DGS segmentation 모델의 한계점을 해결한다.
Related Work
Probabilistic 3D Semantic Mapping
기존 로보틱스 환경에서는 voxel로 된 3D map을 많이 사용하였다. Sparse한 Voxel map에서 dense하게 semantic mapping을 하기 위해 Bayesian Kernel Inference (BKI)라는 방법이 기존에 주로 사용되었다. BKI는 uncertainty 값을 이용하여 3D 점과 점 사이의 공간에 대한 semantic label을 확률적으로 추정한다.
BKI의 단점으로 커널 함수를 직접 정해야 하는데, ConvBKI 논문에서는 이 커널 함수를 뉴럴 네트워크로 학습하는 방법을 제시했고 그 결과 커널 함수가 3D 가우시안의 형태가 된다는 것을 확인하였다. 그러나 discrete한 voxel map 상에서는 3D 가우시안들의 분포나 형태에 제한이 있었다.
Method
Preliminaries: Gaussian Splatting
3DGS의 각 가우시안은 중심점 $\mu$, 공분산 $\Sigma$, opacity $\alpha$ 등으로 정의된다. 중심점과 공분산은 splatting 과정을 통해 2D image plane 상의 점 $\mu'$와 $\Sigma'$으로 변환된다. 2D 픽셀 $x_i'$와 splatting된 가우시안 $x_n'$가 주어졌을 때, 점 $x_i'$에서의 가우시안 함숫값은 아래와 같다.
$g(x'_i, x'_n) = \exp \left( -\cfrac{1}{2} (x'_i - \mu'_n)^T \Sigma_n^{-1} (x'_i - \mu'_n) \right)$
논문에서는 $k(x'_i, x'_n)$라고 표기했지만 뒤에 나올 $\kappa$와 구분하기 위해 $g$로 표기하였다.
이후 아래의 식과 같이 이 함숫값을 opacity와 곱해 그 가우시안의 influence를 구한다.
$\alpha'_n = \alpha_n \cdot g(x'_i, x'_n)$
아래와 같이 alpha compositing을 하여 occlusion을 반영한다.
$\kappa(x'_i, x'_n) = \alpha'_n \prod\limits_{j=1}^{n-1} (1 - \alpha'_j)$
최종적으로 2D 픽셀 $x_i'$에서 쏜 ray 상에 있는 $N$개의 가우시안에 대해 앞에서 뒤 순서로 아래와 같이 합을 구하면 그 픽셀의 색깔을 렌더링할 수 있다.
$C_i = \sum\limits_{n=1}^{N} c_n \kappa(x'_i, x'_n)$
위의 유도 과정을 살펴보면, $\kappa(x'_i, x'_n)$가 $n$번째 가우시안이 $i$번째 픽셀 $x'_i$에 미치는 영향을 0부터 1 사이의 값으로 나타내고 있는 것을 볼 수 있다.
Probabilistic Semantic Update
여기서는 이미 학습이 완료된 각 가우시안에 semantic segmentation feature를 확률적으로 할당하는 방법을 소개한다.
공간상 $n$번째 가우시안을 $x_n$으로 표기하고 그 가우시안의 class vector를 $\theta_n$이라 하자. $\theta_n$은 크기가 클래스의 총 개수이고 0부터 1 사이의 값으로 그 클래스에 속할 확률을 나타낸다. 우리가 구하고자 하는 것은 가우시안 $x_n$과 모든 픽셀들의 집합 $\mathcal{D}$가 주어졌을 때의 $\theta_n$의 확률분포 $p(\theta_n \mid x_n, \mathcal{D})$이다.
그런데 이 확률분포를 직접 구하기 어렵기 때문에 Bayes' rule을 써서 아래와 같이 표현한다.
$p(\theta_n \mid x_n, \mathcal{D}) = p(y_i \mid \theta_n, x_n, \mathcal{D}) \cdot p(\theta_n)$
이 과정을 Bayesian Update라고도 한다.
먼저 첫 번째 항을 구하는 방법을 살펴보면, 우선 off-the-shelf pixel-wise 2D segmentation 모델을 이용해 pixel-wise class를 얻고, 이를 one-hot vector로 표현한다. 픽셀 $x_i$에 대한 one-hot vector를 $y_i$라 하자.
수식 유도를 위한 중간 변수로 2D 픽셀 $x_i$에 대해 렌더링된 class vector를 $\theta_i$라 하자. $\theta_i$ 또한 크기가 클래스의 총 개수이고 0부터 1 사이의 값으로 $x_i$가 그 클래스에 속할 확률을 나타낸다.
그렇다면 $\theta_i$가 실제 클래스 $y_i$를 맞출 확률은 아래와 같다.
$p(y_i \mid \theta_i) = \prod\limits_{c=1}^{C} (\theta_i^c)^{y_i^c}$
$y_i$가 one-hot vector이므로 우변의 곱은 결국 정답 클래스에 해당하는 $\theta_i$의 element가 된다. 예를 들어 $y_i = [0, 1, 0]^T$이고 $\theta_i = [0.1, 0.7, 0.2]^T$라면 $p(y_i \mid \theta_i) = 0.7$이 된다.
그렇다면 이를 확장해서 $n$번째 가우시안의 class vector $\theta_n$이 실제 클래스 $y_i$를 맞출 확률을 $p(y_i \mid \theta_n, x_i, x_n)$으로 표시할 수 있다. $p(y_i \mid \theta_n, x_i, x_n)$와 $p(y_i \mid \theta_i)$ 사이의 관계는 아래의 수식으로 표현할 수 있다.
$p(y_i \mid \theta_n, x_i, x_n) \propto p(y_i \mid \theta_i)^{\kappa(x_i, x_n)}$
즉, $n$번째 가우시안이 $i$번째 픽셀 $x'_i$에 미치는 영향 $\kappa(x'_i, x'_n)$을 연결고리로 이용하는 것이다. 그런데 $\kappa(x'_i, x'_n)$가 줄어들수록 $p(y_i \mid \theta_i)^{\kappa(x_i, x_n)}$가 증가한다는 점에서 수식에 오류가 있어 보인다. 논문에서는 이 과정이 커널 함수 $\kappa(x'_i, x'_n)$를 이용해 가우시안 class vector의 확률분포를 조정한다는 점에서 Bayesian Kernel Inference (BKI)에 해당한다고 한다.
이제 $\theta_n$에 대한 prior distribution $p(\theta_n)$을 설정해 보자. 논문에서는 아래와 같이 categorical distribution의 conjugate prior인 Dirichlet distribution을 이용한다. Dirichlet distribution은 categorical distribution의 각 클래스에 속할 확률값 자체를 랜덤변수 $\alpha$로 모델링하여 기존 분포의 신뢰도를 조절하는 분포이다.
$p(\theta_n) \propto \prod\limits_{i=1}^{C} \theta_{n,c}^{\alpha_n^c - 1}$
이제 Bayesian Update를 적용할 수 있다. 우리가 최종적으로 구하고자 하는 값 $p(\theta_n \mid x_n, \mathcal{D})$는 아래와 같이 쓸 수 있다.
$p(\theta_n \mid x_n, \mathcal{D}) \propto \left[ \prod\limits_{i=1}^{N} \left[ \prod\limits_{c=1}^{C} (\theta_n^c)^{y_i^c} \right]^{\kappa(x_n, x_i)} \right] \prod\limits_{c=1}^{C} \theta_{n,c}^{\alpha_n^c - 1}$
이때 $p(y_i \mid \theta_n, x_n, \mathcal{D})$ 부분을 구하기 위해 $\mathcal{D}$를 각 픽셀로 분해하여 $\prod\limits_{i=1}^{N}$로 계산하고 있는 것을 볼 수 있다.
이를 조금 더 간단히 하면 아래와 같이 단순히 Dirichlet distribution의 concentration parameter $\alpha$를 업데이트 하는 것으로도 볼 수 있다.
$\alpha_n^c \leftarrow \alpha_n^c + \sum\limits_{i=1}^{N} \kappa(x_i, x_n) y_i^c$
따라서, 결론적으로 코드 상에서 수행하는 것은 위의 식이다. 직관적으로 요약하면 먼저 각 픽셀에 대한 특정 가우시안 $x_n$의 influence $\kappa(x'_i, x'_n)$를 one-hot vector $y_i$와 곱한다. 이를 $x_n$이 영향을 주는 모든 픽셀에 대해 수행하여 합한 뒤 그 가우시안의 concentration parameter $\alpha$에 더하면 된다.
이러한 방식으로 뉴럴 네트워크를 추가로 사용하지 않고 확률적으로 각 가우시안에 semantic 정보를 할당할 수 있다.
$\theta_{n}$의 평균과 분산은 아래의 수식을 통해 구할 수 있다.
$\mathbb{E}[\theta_n^c] = \cfrac{\alpha_n^c}{\sum\limits_{j=1}^{C} \alpha_n^j}, \quad \text{Var}[\theta_n^c] = \cfrac{\mathbb{E}[\theta_n^c] (1 - \mathbb{E}[\theta_n^c])}{1 + \sum\limits_{j=1}^{C} \alpha_n^j}$
Probabilistic Semantic Rasterization
각 가우시안의 class vector $\theta_n$를 각 픽셀의 class vector $\theta_i$로 렌더링할 때는 색깔을 렌더링할 때와 같은 수식을 사용한다.
$\theta_i = \sum\limits_{n=1}^{N} \kappa(x_i, x_n) \theta_n$
또한 $\theta_n$을 이용하여 $\theta_i$의 expectation과 variance를 계산할 수 있는데, 이는 이후 semantic uncertainty를 계산하는 데 사용된다.
$\mathbb{E}(\theta_i) = \sum\limits_{n=1}^{N} \kappa(x_i, x_n) \mathbb{E}(\theta_n)$
Variance는 각 가우시안들 간의 독립을 가정하고 아래와 같이 모델링한다.
$Var(\theta_i) = \sum\limits_{n=1}^{N} \kappa(x_i, x_n)^2 Var(\theta_n)$
3DGS를 렌더링할 때는 배경의 색깔까지 고려하게 되는데, ray가 모든 가우시안을 통과했을 때 누적된 opacity가 최종적으로 1이 되어야 하기 때문이다. CSS에서도 마찬가지로 배경의 class를 고려해야 한다. 배경 클래스가 현재 픽셀 $x_i$에 미치는 영향은 아래의 식과 같다.
$\kappa(x_i, x_b) = 1 - \sum\limits_{n=1}^{N} \kappa(x_i, x_n)$
배경의 class vector $\theta_b$ 또한 Dirichlet distribution을 따르며, 각 카테고리의 확률값은 모두 동일하게 설정한다.
Uncertainty at Image Level
픽셀 단위로 uncertainty를 구할 수도 있지만, 이미지 전체의 uncertainty를 정량적으로 구하는 방법도 소개한다. 각 픽셀의 variance 또는 expectation 값을 이용하여 아래와 같이 구할 수 있다.
$U(\mathcal{I}_{Var}) = \left| \sum \mathcal{I} \right|^{\cfrac{1}{n}} = \exp \left( \cfrac{1}{n} \sum\limits_{i=1}^{n} \log \left( \text{Var}(\hat{\theta}_i) \right) \right)$
분산을 이용하여 uncertainty $U(\mathcal{I}_{Var})$를 구하는 식은 위와 같다. $\text{Var}(\hat{\theta}_i)$는 $\text{Var}({\theta}_i)$의 element 중 정답 카테고리에 해당하는 분산 값을 의미한다.
$U(\mathcal{I}_\mathbb{E}) = 1 - \cfrac{\sum\limits_{i=1}^{n} \mathbb{E}(\hat{\theta}_i)}{n}$
기댓값을 이용하여 uncertainty $U(\mathcal{I}_\mathbb{E})$를 구하는 식은 위와 같다. 마찬가지로 $\mathbb{E}(\hat{\theta}_i)$는 $\mathbb{E}({\theta}_i)$의 element 중 정답 카테고리에 해당하는 기댓값을 의미한다. 즉, 정답 카테고리에 할당된 확률이 높을수록 이미지의 uncertainty가 낮아지도록 정의된다.
Results
Comparison to Voxel-Based Method
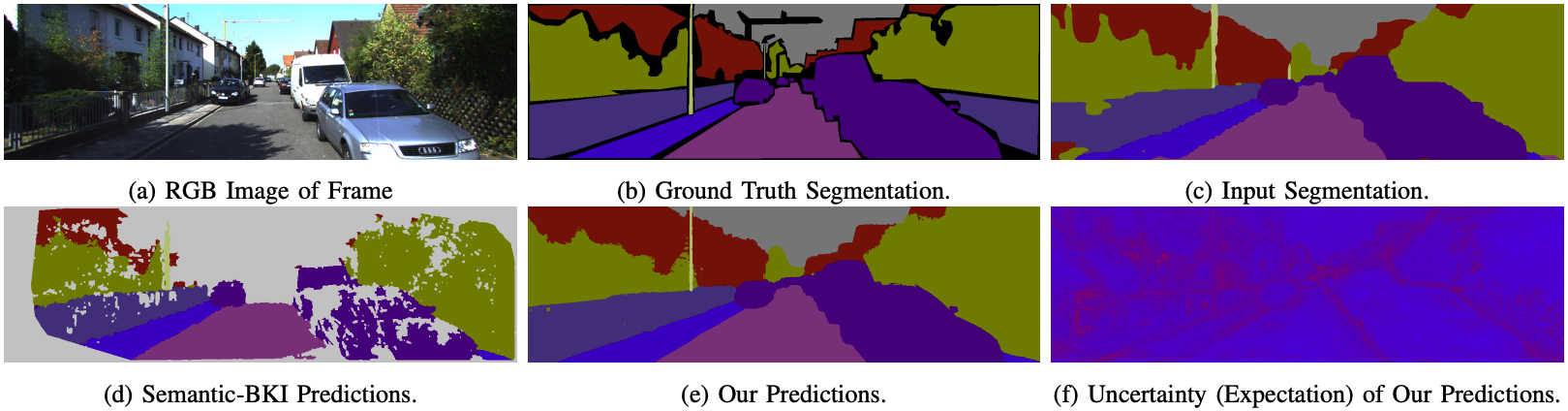
CSS 모델과 다른 voxel 기반 semantic segmentation 모델의 성능을 비교한다. 데이터셋으로는 KITTI driving dataset을 사용하였고, metric으로는 mIoU를 사용하였다.
위 (d)번 그림을 보면, voxel 기반 모델의 출력이 군데군데 비어 있는 것을 볼 수 있는데, voxel이 본질적으로 sparse하기 때문이다. 반면 (e)번 그림을 보면 CSS는 모든 픽셀에 대해 label을 예측하는 것을 볼 수 있다.
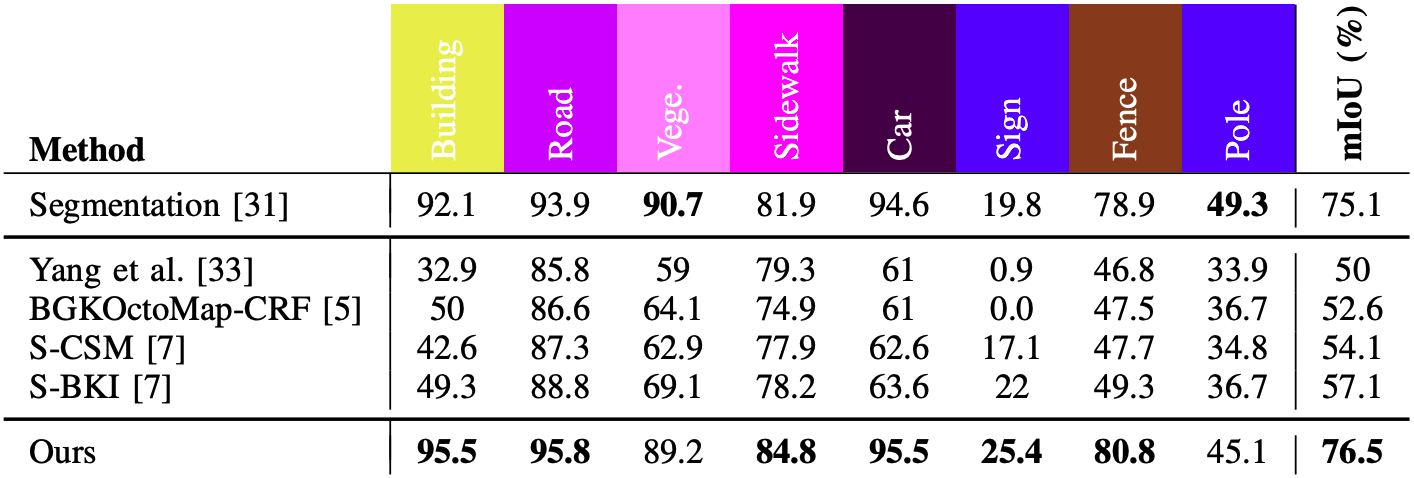
위 표는 렌더링된 뷰에서 전체 픽셀에 대해 segmentation 결과를 정량적으로 평가한 것이다. voxel 기반 모델에 비해 CSS의 mIoU가 높은 것을 볼 수 있다. 다만 이 결과는 voxel 기반 모델들의 출력에 빈 공간이 있다는 것을 고려하지 않았기 때문에 label의 정확도보다는 모든 픽셀을 labeling하는 것의 효과를 보여 준다고 해석할 수 있다.
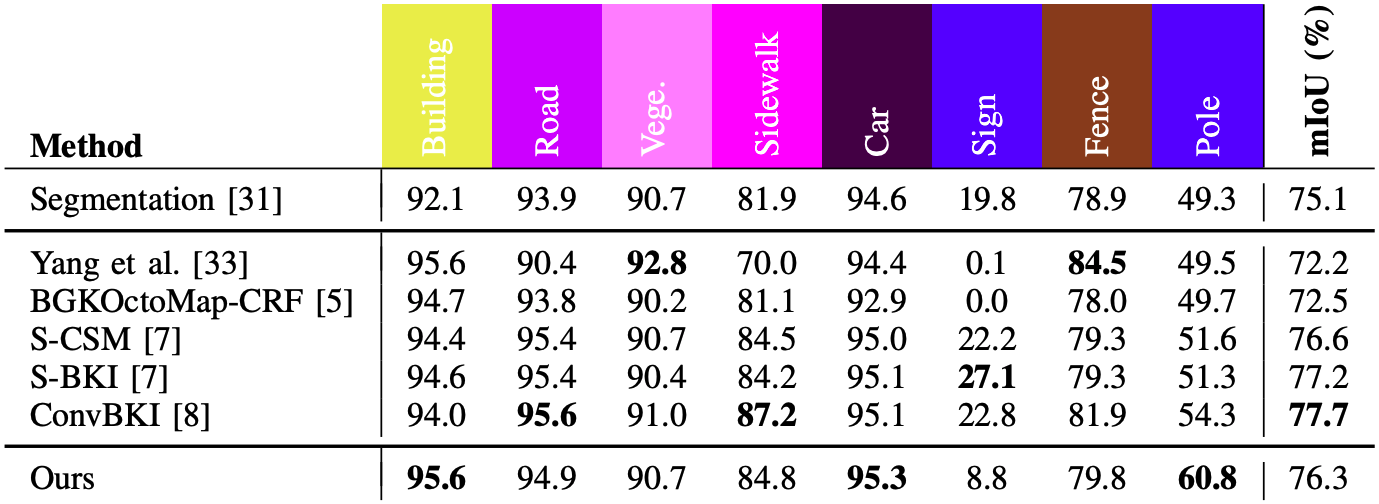
위 표는 voxel 기반 모델들이 출력한 픽셀들에 대해서만 mIoU를 비교한 것이다. 카테고리에 따라 순위에 차이는 있지만 정확도 자체는 비슷한 것으로 보인다. 맨 윗줄의 2D segmentation model보다 3D 모델의 성능이 좋은 것은 multi view image의 정보를 3D로 모으는 것이 효과가 있다는 것으로 해석할 수 있다.
Uncertainty Quantification
Uncertainty 추정 성능을 분석하기 위해, 본 논문에서는 sparsification이라는 방법을 사용한다. 우선 예측된 결과들을 uncertainty가 큰 픽셀 또는 이미지부터 하나씩 제거해 가면서 segmentation accuracy가 어떻게 증가하는지를 확인한다. Uncertainty가 잘 추정되었다면 정확도가 점점 증가할 것이다.
여기서는 Replica 데이터셋을 사용하였다.
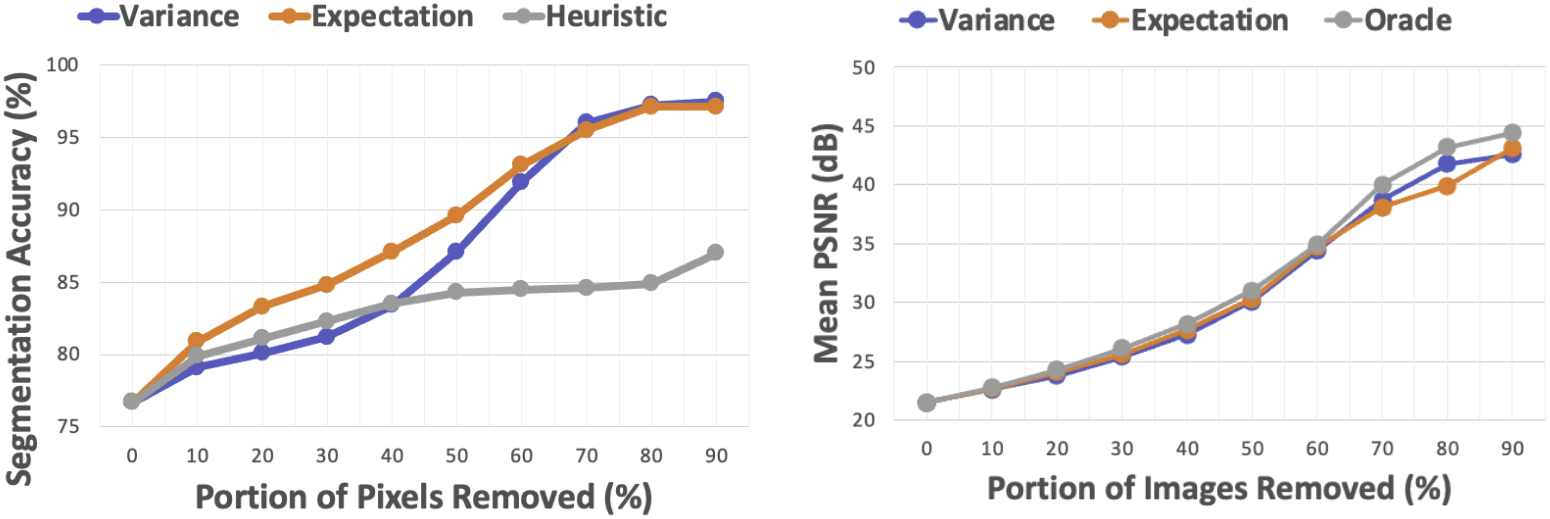
위의 왼쪽 그래프에서 볼 수 있듯, uncertainty가 큰 픽셀부터 차례로 제거했을 때 정확도가 점점 증가하는 것을 볼 수 있다. 또한 오른쪽 그래프는 이미지 단위로 uncertainty를 예측하고 그 순서대로 이미지를 하나씩 제거한 것인데, 제거된 이미지가 많을수록 평균 PSNR이 증가하는 것을 볼 수 있다.
이러한 결과를 통해 CSS에서 uncertainty가 잘 모델링되었다고 볼 수 있다. 또한 기댓값과 분산 모두 uncertainty를 측정할 수 있는 지표라고 해석할 수 있다.
Conclusion
본 논문에서는 기존 robotic mapping 방식에서 사용되던 uncertainty 추정을 3DGS와 결합하여 3DGS에서 확률적으로 semantic segmentation을 수행하는 방법을 제시하였다. 또한 픽셀과 이미지 레벨에서 uncertainty 추정 성능을 평가하는 방법을 새로 도입하였다.
Future work으로는, 첫 번째로 실시간 3DGS 모델과 본 모델을 결합하는 것을 언급하고 있다. 두 번째로는 Dirichlet distribution 대신 continuous conjugate prior를 이용하여 open-vocabulary segmentation을 구현하는 것을 언급하고 있다.