Introduction
기존 VLM 중 InstructBLIP나 MiniGPT-4와 같은 shallow alignment 기법은, 이미지 인코더로부터 얻은 특징을 단순히 선형 변환이나 Q-Former를 통해 언어 모델 입력 공간에 맞추는 방식이었다. 이 방식은 빠르게 수렴하지만, LLaVA 1.5와 같이 언어 모델의 파라미터를 훈련하는 방법에 비해 성능이 떨어지는 문제가 있었다. 특히, shallow alignment는 언어 모델의 깊은 레이어들과 이미지 특징 사이에 충분한 융합을 이루지 못하여, 이미지 특징이 언어 모델의 기대 입력 분포와 맞지 않는다는 심각한 문제를 드러냈다. 그 결과, 이미지 캡셔닝처럼 섬세한 조정이 필요한 과제에서는 표현이 얕고 부정확해지는 문제가 발생했다.
한편 PaLI, Qwen-VL 등은 아예 언어 모델 자체를 이미지-텍스트 쌍 데이터로 추가 학습시켜 시각적 이해를 강화하는 전략을 택했다. 그러나 이러한 접근은 LLM이 본래 가지고 있던 자연어 처리 능력을 심각하게 손상시키는 부작용을 초래했다. 이는, 원래 LLM들이 방대한 텍스트 전용 데이터셋에서 학습된 반면, 이미지-텍스트 데이터는 분포가 매우 다르기 때문이며, 이로 인해 catastrophic forgetting이 발생하는 것이었다. 실제로 LAION 데이터셋으로 추가 훈련할수록 MMLU 점수가 급격히 하락하는 현상이 관찰되었으며, 이는 PaLM-E나 Flamingo에서도 비슷하게 보고되었다.
이러한 문제의식 하에 CogVLM은 기존 방식들과는 다른 접근을 취했다. CogVLM은 언어 모델의 기존 파라미터를 완전히 고정(freeze)한 채, 각 레이어에 이미지 특징 전용의 새로운 QKV 매트릭스와 MLP 층을 추가하는 trainable visual expert module을 도입했다. 이를 통해 이미지와 텍스트 간 깊은 융합(deep fusion)을 달성하면서도, 입력에 이미지가 없으면 기존 언어 모델과 동일하게 작동할 수 있게 했다. 따라서 CogVLM은 원래 언어 모델이 가진 자연어 처리 성능을 전혀 희생하지 않으면서, 최고 수준의 시각적 이해 능력까지 획득하는 데 성공했다.
이 설계는 효율적인 미세조정 방법인 P-Tuning과 LoRA의 차이를 참고하여 고안되었다. P-Tuning은 입력에 접두어 임베딩만 추가하는 반면, LoRA는 각 레이어의 가중치를 직접 조정하여 더 나은 성능과 안정성을 보여주는 것을 보고, CogVLM도 shallow alignment 방식(P-Tuning 유사) 대신 레이어별 조정(LoRA 유사) 방식을 택한 것이다.
Method
Architecture
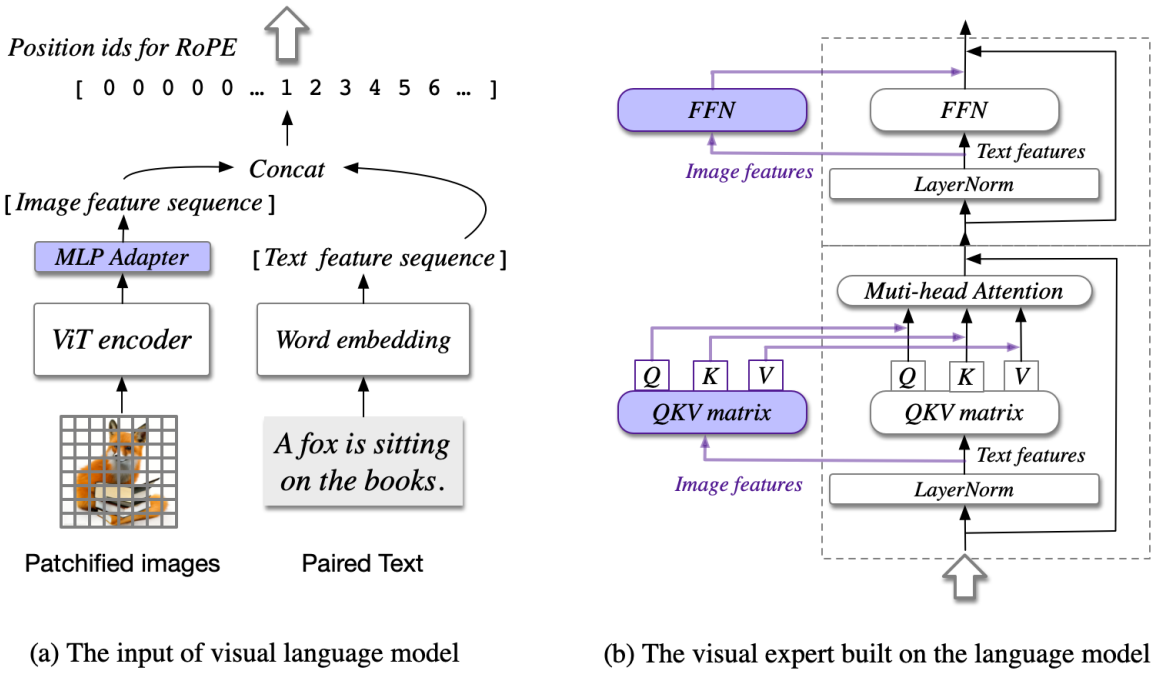
CogVLM의 방법론(Method) 파트에서는 모델 아키텍처와 구체적인 설계 요소들을 자세히 설명하고 있다.
CogVLM은 총 네 가지 핵심 컴포넌트로 구성된다: Vision Transformer(ViT) 인코더, MLP 어댑터, 사전학습된 대규모 언어 모델(GPT), 그리고 Visual Expert 모듈이다.
우선 ViT 인코더로는 EVA2-CLIP-E를 사용하며, 여기서는 contrastive learning을 위해 사용되는 마지막 [CLS] 특징 집계 레이어를 제거하였다. 이는 이미지의 글로벌 특징 벡터가 아닌, 패치별 특징 벡터를 그대로 활용하기 위함이다.
MLP 어댑터는 ViT 인코더의 출력을 언어 모델의 텍스트 임베딩 공간과 일치시키기 위해 사용된다.
CogVLM은 사전학습된 Vicuna1.5-7B를 언어 모델로 채택했으며, 모든 어텐션 연산(이미지와 텍스트 간 어텐션 포함)에 causal mask를 적용하여 autoregressive 성질을 유지한다. Causal mask란 현재 토큰이 과거 토큰만을 참고할 수 있도록 제약하는 마스크를 의미한다.
Visual Expert Module
CogVLM의 핵심은 Visual Expert 모듈이다. 각 레이어에 새롭게 추가된 이 모듈은 이미지 특징을 언어 모델의 attention head별로 align시키기 위한 trainable QKV 매트릭스와 MLP를 포함한다. 이 모듈은 사전학습된 언어 모델의 QKV 매트릭스 및 MLP와 동일한 형태를 가지며, 초기화도 동일하게 수행된다. 이 설계의 핵심 아이디어는 언어 모델의 각 attention head가 특정 의미적 정보를 포착하기 때문에, 이미지 특징도 이에 맞춰 깊은 융합(deep fusion)이 가능하도록 변환해줘야 한다는 것이다.
Attention 레이어의 입력 hidden state $X$는 다음과 같은 차원을 가진다:
$X \in \mathbb{R}^{B \times H \times (L_I + L_T) \times D}$
여기서 $B$는 배치 크기, $H$는 어텐션 헤드 수, $L_I$는 이미지 토큰 수, $L_T$는 텍스트 토큰 수, $D$는 히든 차원 크기이다.
Attention with visual expert는 다음과 같이 계산된다:
$Attention(X, W_I, W_T) = \text{softmax}\left( \cfrac{\text{Tril}(QK^T)}{\sqrt{D}} \right)V$
여기서 $Q$, $K$, $V$는 각각 쿼리, 키, 밸류를 의미하고, $\text{Tril}(\cdot)$은 causal mask를 적용하기 위해 하삼각 행렬 형태로 만드는 연산이다.
Q, K, V는 각각 다음처럼 시각 정보와 텍스트 정보를 concat하여 구성된다:
$Q = \text{concat}(X_I W^Q_I, X_T W^Q_T)$
$K = \text{concat}(X_I W^K_I, X_T W^K_T)$
$V = \text{concat}(X_I W^V_I, X_T W^V_T)$
여기서 $W_I$는 Visual Expert 모듈의 가중치, $W_T$는 원래 언어 모델의 가중치를 의미한다.
Feed Forward Network(FFN) 층에서도 유사하게, 이미지를 위한 FFN과 텍스트를 위한 FFN 결과를 결합하여 출력한다:
$FFN(X) = \text{concat}(FFN_I(X_I), FFN_T(X_T))$
즉, CogVLM은 각 레이어별로 이미지와 텍스트 특징을 별도로 처리한 뒤 합쳐서 깊은 융합을 달성한다는 점이 특징이다.
Positional Embedding
포지션 임베딩(Position Embedding) 측면에서도 중요한 최적화가 적용되었다. 일반적인 Transformer는 입력 토큰 각각에 고유한 위치 정보를 부여하지만, 이미지 토큰 수가 수백~수천 개에 달할 수 있는 CogVLM에서는 모든 이미지 토큰에 동일한 position id를 부여했다. 이는 ViT 인코더 단계에서 이미 패치 간 상대적 위치 정보가 반영되었기 때문에 가능하며, 시퀀스가 지나치게 길어지는 문제와 LLM 내부에서 하단 이미지 부분에만 주목하는 편향 문제를 방지할 수 있었다.
전체적으로 CogVLM은 기존 shallow alignment의 한계를 극복하기 위해 레이어 단위 깊은 융합과, 원래 언어 모델의 능력 보존을 동시에 달성하는 세심한 아키텍처 설계를 보여준다.
Pretraining
Data
CogVLM의 pretraining 데이터는 모두 공개된 15억 개의 이미지-텍스트 쌍 데이터셋에서 수집되었다.
추가적으로, CogVLM은 자체적으로 4천만 장 규모의 Visual Grounding 데이터셋도 구축하였다. 이 데이터는 캡션 내 명사 단어들과 해당 단어를 나타내는 bbox를 매칭시키는 방식으로 생성되었다. 구체적으로는 spaCy를 통해 명사를 추출하고, GLIPv2를 이용하여 bbox를 예측했다.
Training
사전학습은 두 단계로 이루어진다. 첫 번째 단계에서는 이미지 캡셔닝 태스크에 해당하는 텍스트 부분의 다음 토큰 예측(next token prediction) 손실을 최소화하는 방식이다.
두 번째 단계에서는 이미지 캡셔닝과 REC 태스크를 혼합하여 학습하였다. REC는 텍스트 설명을 기반으로 이미지 내 객체의 bbox를 예측하는 과제로, VQA 포맷(질문: "Where is the object?", 답변: "[[x0, y0, x1, y1]]")으로 구성되었다. REC 태스크에서 loss는 "Answer" 부분의 다음 토큰 예측에만 적용된다.
Alignment
CogVLM의 instruction alignment 단계에서는 두 가지 범용(generalist) 모델, 즉 CogVLM-Chat과 CogVLM-Grounding을 학습시켰다. CogVLM-Chat은 자연어 입력과 출력을 다루고, CogVLM-Grounding은 입력과 출력 모두에 바운딩 박스 정보를 포함하는 형식으로 작동한다.
CogVLM-Chat
CogVLM-Chat을 학습시키기 위해 다양한 오픈소스 비주얼 질문응답(VQA) 데이터셋을 활용했다. 이러한 다양한 데이터셋을 하나로 통합하여 instruction-supervised fine-tuning(SFT)을 진행했다.
VQA 데이터셋은 짧고 간결한 답변(1-2 단어)이 많은 반면, 대화형 데이터셋은 길고 논리적인 답변을 요구한다는 차이가 있다. 이를 고려하여 SFT 과정에서는 프롬프트를 다음과 같이 다르게 구성하였다.
- 간단한 답변의 경우: "Question: Short answer:"
- 긴 답변이 필요한 경우: "Question: Answer:"
이와 같은 프롬프트 디자인을 통해 다양한 응답 스타일을 효과적으로 학습할 수 있도록 했다.
CogVLM-Chat은 학습 시 ViT 인코더의 파라미터도 업데이트 가능하게 하되, 나머지 파라미터 대비 10배 낮은 학습률로 조정하여 학습 안정성을 높였다. 이를 통해 전체 모델 학습을 무너뜨리지 않으면서 비전 모듈의 적응을 촉진할 수 있었다.
CogVLM-Grounding
CogVLM-Grounding은 모델에 일관된 visual grounding 능력을 부여하기 위해 학습되었다. 여기서는 4가지 유형의 visual grounding 데이터를 사용하였다.
- Grounded Captioning (GC) - 캡션 안의 명사구(noun phrase) 각각에 대해 참조 바운딩 박스 추가
- Referring Expression Generation (REG) - 이미지 내 특정 박스를 설명하는 텍스트 생성
- Referring Expression Comprehension (REC) - 텍스트 설명에 대해 관련 박스를 찾는 과제
- Grounded Visual Question Answering (GroundedVQA) - 지역 참조(region reference)를 포함하는 질문에 대한 VQA 스타일 과제
이 데이터들에서 사용되는 바운딩 박스 표현은 다음과 같다:
$\text{Bounding Box} = [[x_0, y_0, x_1, y_1]]$
수집된 데이터셋은 다양한 변환과 재활용이 가능하여 모델의 다재다능성을 키우는 데 큰 도움이 되었다. 예를 들어, grounded captioning 데이터는 REG나 REC 태스크로 쉽게 변환할 수 있다. 예시로 "A man [box1] and a woman [box2] are walking together."라는 문장은 다음과 같이 변환될 수 있다.
- REG 스타일 질문: "Describe this region [box2]." → 답변: "A woman."
- REC 스타일 질문: "Where is the man?" → 답변: "[box1]"
이처럼 동일한 데이터도 다양한 태스크로 전환 가능하다.
Experiments
CogVLM의 성능 평가를 위해, 아래의 다양한 태스크에서 정량적 평가를 수행했다.
- 이미지 캡셔닝: 주어진 이미지의 주요 내용을 요약하는 텍스트 캡션을 생성.
- Visual Question Answering: 주어진 이미지의 다양한 시각적 요소에 초점을 맞춘 질문에 답변하는 능력을 평가.
- 대형 비전-언어 모델 (LVLM) 벤치마크: 객체 인식 및 위치 지정, OCR, 시각적 설명 생성, 시각적 지식 추론 등 대형 멀티모달 모델의 고급 기능을 평가.
- Visual Grounding: 문장 내 텍스트 언급과 이미지 내 특정 영역 간 참조 관계를 정확히 연결하는 능력을 측정.
Image Captioning
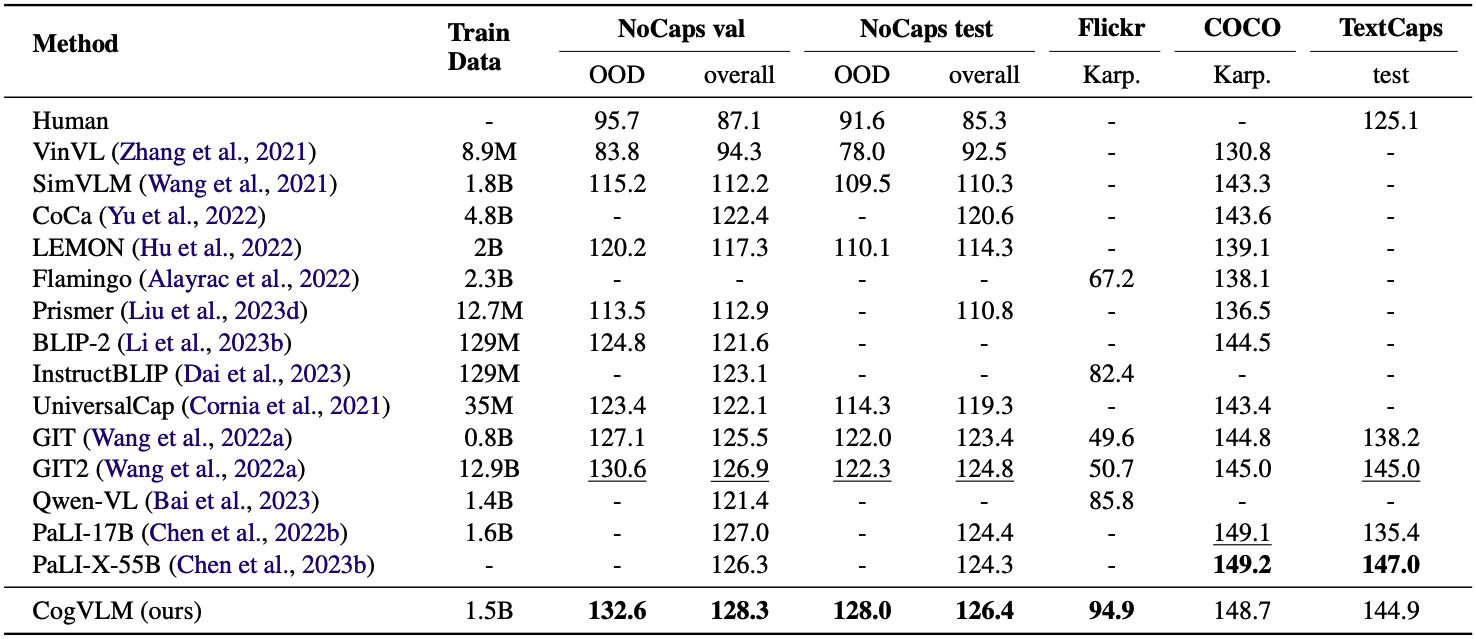
CogVLM의 기본 pretrained 모델은 위의 네 가지 벤치마크에서 성능을 평가받았다. NoCaps와 Flickr 데이터셋에서는 zero-shot 설정 하에 모델이 long-tail 시각 개념을 얼마나 정확히 기술할 수 있는지를 평가했다. COCO와 TextCaps 데이터셋에서는 fine-tuning 후 성능을 측정했다.
위 표를 보면 다양한 벤치마크에서 CogVLM은 SOTA를 달성했다. 특히 out-domain 세트에서는 최대 5.7포인트의 차이로 앞섰다. 이는 12.9B 샘플을 사용한 GIT2에 비해, 불과 1.5B 샘플만 사용하고도 달성한 성과였다.
Visual Question Answering
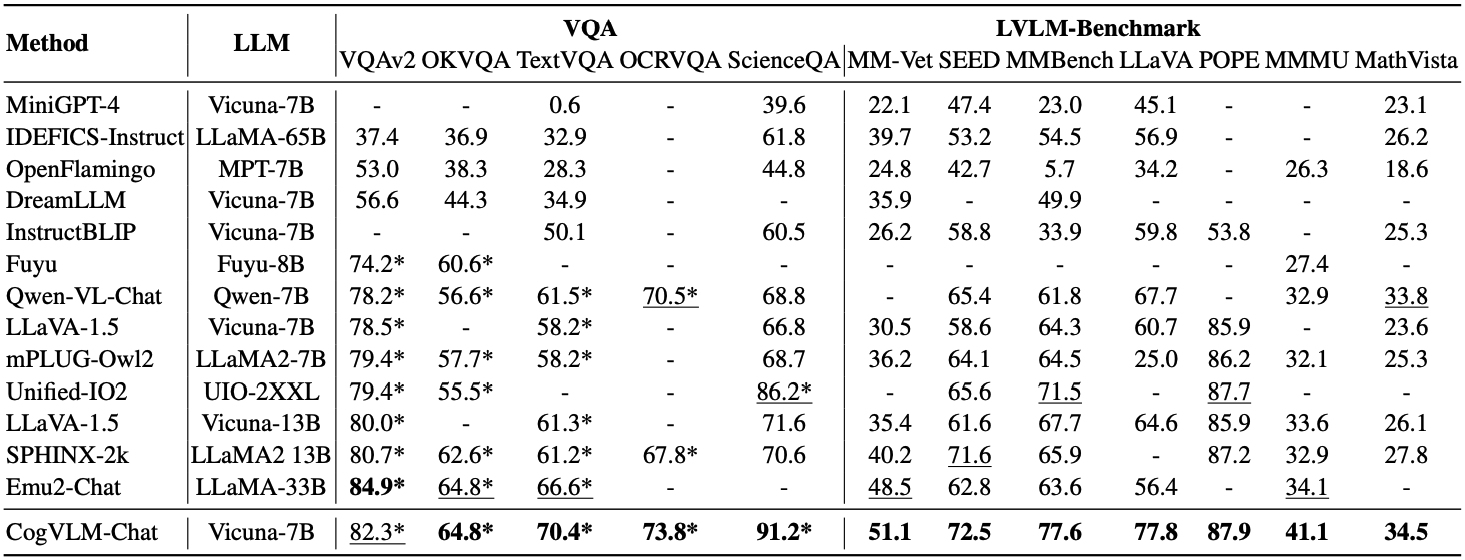
위 표에 따르면, CogVLM은 다양한 VQA 태스크에서 유사한 파라미터 크기를 가진 모델들을 압도하는 성능을 보였다. 구체적으로, 일상생활 이미지를 기반으로 한 질문응답 데이터셋(VQAv2)뿐만 아니라, 텍스트 중심의 질문응답 데이터셋(TextVQA, OCRVQA), 그리고 외부 지식을 요구하는 데이터셋(OKVQA, ScienceQA)에서도 뛰어난 결과를 달성했다.
LVLM Benchmarks
CogVLM은 총 7개의 LVLM 벤치마크에서 모두 SOTA를 달성했다. 특히, 더 큰 언어 모델을 사용한 멀티모달 모델들과 비교했을 때도 CogVLM은 확연한 우위를 보였다. 이는 CogVLM 아키텍처 설계의 효율성과 deep fusion 전략의 우수성을 뒷받침한다.
추가적으로, MMMU, POPE, MathVista에서의 결과들은 CogVLM이 강력한 추론 능력과 다양한 작업에 대한 일반화 능력을 가지고 있음을 보여준다.
반면 InstructBLIP과 MiniGPT-4처럼 shallow fusion 기반의 모델들은 대부분 벤치마크에서 CogVLM에 비해 저조한 성능을 보였는데, 이는 shallow alignment 방식으로는 높은 수준의 이해와 추론을 달성할 수 없음을 보여준다.
Visual Grounding
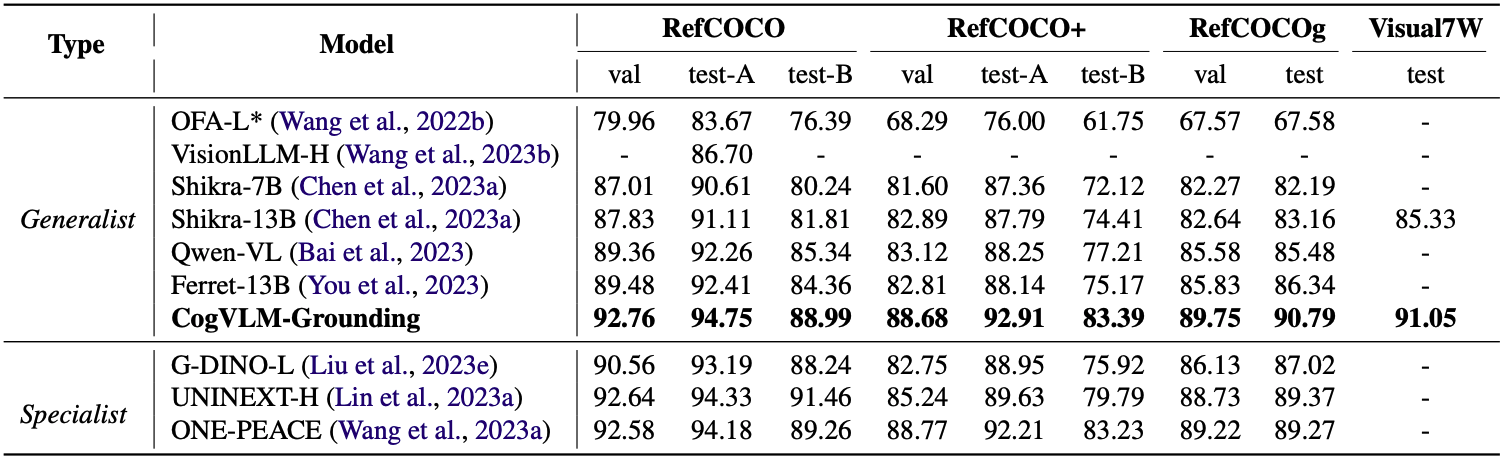
위 표에 따르면, CogVLM은 이 영역에서도 전반적으로 SOTA를 달성했다. 이러한 결과는 CogVLM이 뛰어난 공간적 이해 능력을 갖추었음을 시사한다.
Ablation Study
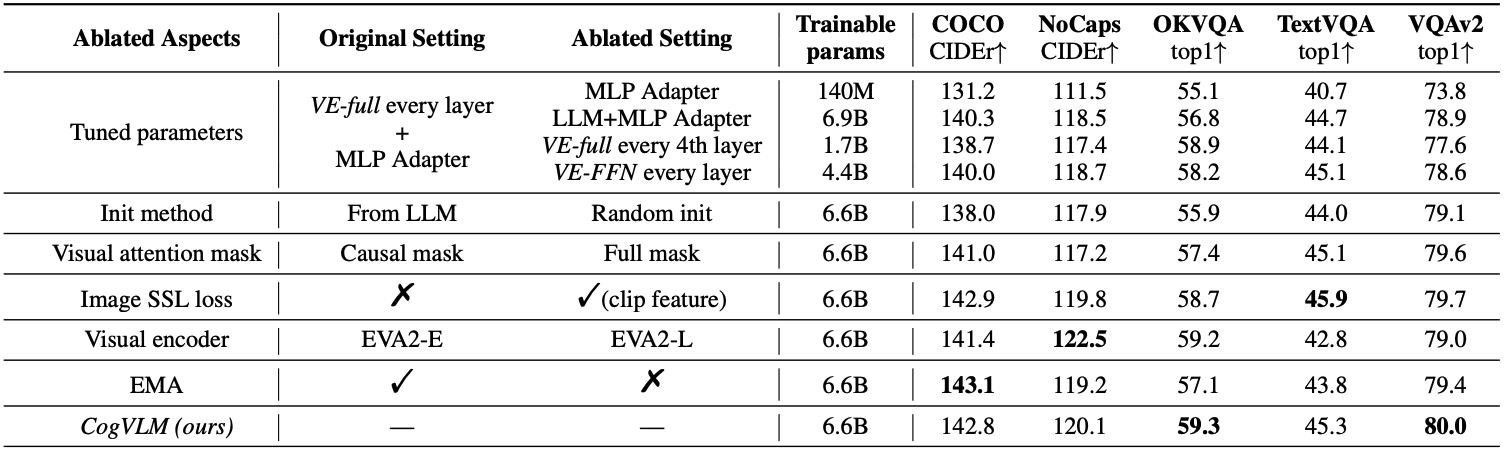
Model Structure and Tuned Parameters
먼저 Model structure and tuned parameters 측면에서는, 여러 구조적 변형과 튜닝 전략에 대해 비교 실험을 진행했다. 실험 항목은 다음과 같다.
- MLP Adapter만 튜닝하는 경우
- Visual Expert 없이 LLM 파라미터와 어댑터를 모두 튜닝하는 경우
- Visual Expert를 4개 레이어마다 추가하는 경우
- Visual Expert를 FFN 부분에만 추가하는 경우
결과적으로, MLP Adapter만 튜닝하는 shallow alignment 방식은 성능이 매우 열악했다. 또한, Visual Expert를 추가하는 방식은 LLM 자체를 튜닝하는 것보다 외부 지식이 필요한 데이터셋에서 특히 더 높은 성능을 보였다. Visual Expert를 4개 레이어마다 삽입하거나, Attention 부분을 제거하는 경우에도 다소 성능 저하는 있었지만 허용 가능한 수준이었으며, 계산 비용과 모델 성능 간 균형을 잡는 데 사용할 수 있다.
Initialization Method
초기화 방법 측면에서는, Visual Expert를 LLM weight를 사용하여 초기화할 때 항상 더 높은 성능을 얻을 수 있었다. 이는 언어 데이터로 사전학습된 트랜스포머 구조가 시각 토큰을 처리하는 데에도 기본적인 능력을 지니고 있다는 것을 시사하며, 멀티모달 사전학습을 위한 더 나은 출발점이 될 수 있음을 보여준다.
Visual Attention Mask
시각 토큰에 causal mask를 적용하는 것이 전체 mask를 사용하는 것보다 성능이 더 우수함을 실험적으로 발견했다. 이는 직관적으로는 양방향 어텐션이 더 많은 정보를 활용할 수 있을 것 같지만, 실제로는 causal mask가 LLM의 구조적 특성과 더 잘 맞아떨어지기 때문으로 보인다.
Visual Encoder
Visual Encoder를 더 작은 모델로 교체했을 때는 전반적으로 대부분의 벤치마크에서는 성능이 약간 감소했고, 텍스트 기반 데이터셋인 TextVQA에서는 2.5포인트 하락이 관찰되었다. 이는 비주얼 인코더 규모가 텍스트 이해 능력에 일정 부분 영향을 미칠 수 있음을 시사한다.
Conclusion
CogVLM은 기존의 shallow alignment 방식 대신, deep fusion 방식을 채택하여 훈련 패러다임을 전환했다. 그 결과, 총 17개의 대표적인 멀티모달 벤치마크에서 SOTA 성능을 달성하는 데 성공했다.
현재 VLM 훈련은 아직 초기 단계에 있으며, 향후 탐색할 수 있는 여러 연구 방향이 존재한다. 예를 들면, 더 나은 SFT (Supervised Fine-Tuning) 정렬 방법, RLHF (Reinforcement Learning with Human Feedback) 기반 훈련, 그리고 환각 (hallucination) 문제를 방지하는 기술 등이 있다.