TL;DR
- 3D vision-language(3D-VL) task를 위한 단순하고 통합된 Transformer 모델로, self-attention만으로 single-modal encoding과 multi-modal fusion을 모두 처리한다.
- ScanScribe라는 최초의 대규모 3D scene-text pair 데이터셋(278K pair, 2,995 RGB-D scan)을 구축하여 3D-VL pre-training을 가능하게 했다.
- Masked language/object modeling과 scene-text matching으로 self-supervised pre-training한 후, visual grounding, dense captioning, question answering, situated reasoning 등 다양한 downstream task에서 SOTA를 달성한다.
- Auxiliary loss나 task-specific 모듈 없이도 적은 annotation으로 fine-tuning하여 강한 성능을 보여, 3D-VL의 general-purpose foundation model 가능성을 제시한다.
Thoughts
3D-VL 분야에서 "단순한 아키텍처 + 대규모 pre-training"이라는 NLP/2D-VL에서 검증된 패러다임을 처음으로 본격 적용한 논문이다. 기존 3D-VL 모델들이 task마다 auxiliary loss, knowledge distillation, task-specific head 등을 복잡하게 쌓았던 것과 비교하면, self-attention만으로 통합 모델을 만들고 pre-training으로 성능을 끌어올린 접근이 깔끔하다. ScanScribe 데이터셋 구축도 의미 있는 기여인데, GPT-3와 template을 활용해 기존 3D-VL annotation에서 278K scene-text pair를 생성한 것은 실용적이고 재현 가능한 방식이다.
저자들도 ScanScribe의 규모가 NLP나 2D-VL 데이터셋에 비하면 여전히 작다는 점, 그리고 offline 3D object detection에 의존하는 점이 병목이 될 수 있다는 한계를 인정하고 있다.
여기에 더해, scene encoding에서 object-level token만 사용하는 구조적 한계도 고려할 필요가 있다. Object proposal이 놓친 물체는 모델이 아예 인식할 수 없으므로, fine-grained spatial reasoning이나 novel object에 대한 일반화가 제한될 수 있다. Spatial Transformer의 pairwise spatial feature도 효과적이지만, object 수가 많아지면 $O(N^2)$ 비용이 문제가 되어 large-scale scene 확장성에 영향을 줄 수 있다. Pre-training objective도 MLM, MOM, STM이라는 비교적 표준적인 구성인데, 3D 특유의 spatial structure를 더 적극적으로 활용하는 pre-training task(예: spatial relation prediction, region-level contrastive learning)가 있었다면 성능이 더 올라갔을 가능성도 있다.
Introduction
3D vision-language grounding(3D-VL)은 3D 물리 세계와 자연어를 연결하는 분야로, embodied intelligence 구현에 핵심적이다. 3D visual grounding, dense captioning, question answering, situated reasoning 등의 task가 있다.
기존 3D-VL 모델들은 한두 가지 task에만 초점을 맞추고, task-specific한 모듈과 auxiliary loss를 복잡하게 설계하는 경향이 있었다. 예를 들어 3D-SPS와 BUTD-DETR는 각 layer에서 VL feature를 attend하고 object를 detect하며, 3DVG는 spatial relation 정보를 model design에 명시적으로 주입하고, 3DJCG는 두 개의 task-specific head로 dense captioning과 visual grounding을 jointly 학습한다. 이 과정에서 3D object detection, classification, text classification 같은 auxiliary loss나 knowledge distillation 같은 optimization trick이 필요한 경우가 많았다.
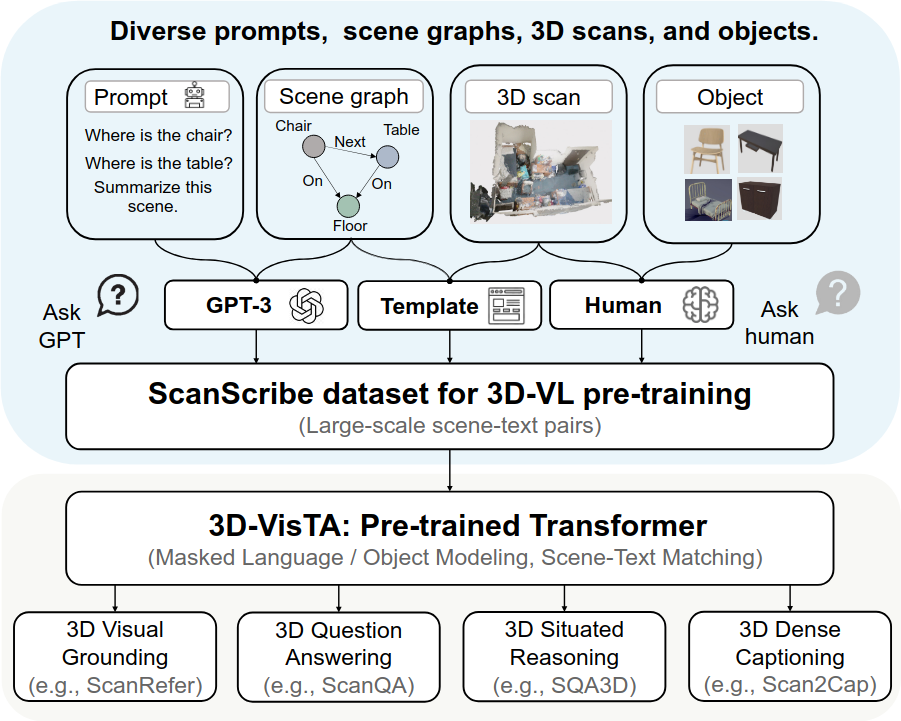
3D-VisTA는 이러한 복잡성을 걷어내고, self-attention layer만으로 single-modal modeling과 multi-modal fusion을 모두 처리하는 단순하고 통합된 Transformer이다. 또한 3D-VL pre-training을 위해 ScanScribe라는 최초의 대규모 3D scene-text pair 데이터셋을 구축했다. Self-supervised pre-training을 거친 3D-VisTA는 다양한 downstream task에서 lightweight task head만 추가하면 되므로, auxiliary loss나 optimization trick 없이도 SOTA 성능을 달성한다.
Related Work
3D Vision-Language Learning
기존 3D-VL 모델들은 task-specific하게 설계되어 있다. ScanRefer, ReferIt3D, ScanQA 등이 각 task에 특화된 모듈을 사용하며, ViL3DRel은 spatial relation 정보를, 3DJCG는 shared 3D object proposal module을 활용한다. 학습 시에도 auxiliary loss나 knowledge distillation 같은 trick이 필요한 경우가 많다. 3D-VisTA는 이러한 복잡한 설계 없이 하나의 통합된 모델로 다양한 task를 처리한다.
Large-Scale Pre-Training
NLP(BERT, GPT), 2D vision(ViT, Swin Transformer), 2D-VL(CLIP, ALIGN, Flamingo) 분야에서는 대규모 pre-training이 큰 성과를 거두었지만, 3D-VL 분야에서는 대규모 pre-training 데이터셋이 부족하여 거의 탐구되지 않았다. 3D-VisTA는 ScanScribe를 구축하여 이 gap을 메운다.
3D-VisTA
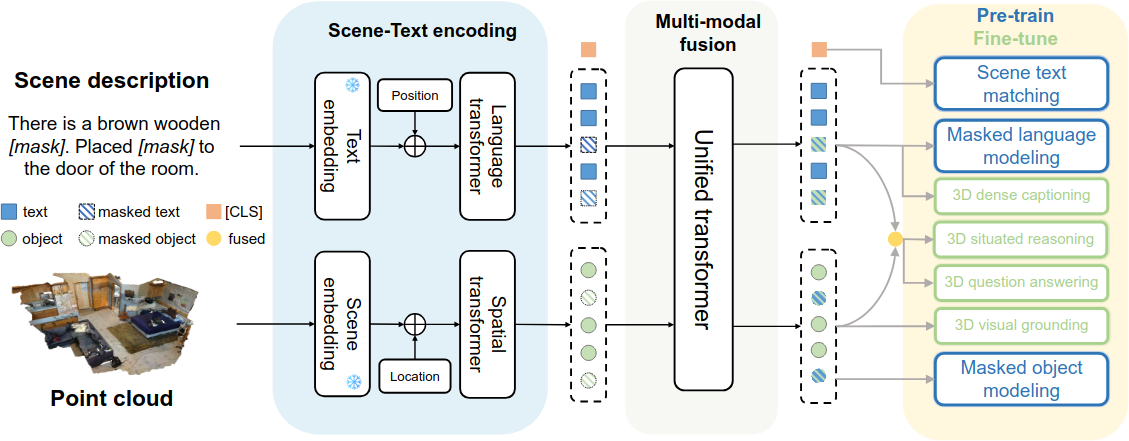
3D-VisTA는 scene point cloud와 sentence를 입력으로 받아, text encoding module, scene encoding module, multi-modal fusion module을 통해 처리한다.
Text Encoding
4-layer Transformer를 사용하여 문장 $S$를 text token sequence $\{w_{cls}, w_1, w_2, \ldots, w_M\}$으로 인코딩한다. $w_{cls}$는 special classification token이며, $M$은 문장 길이이다. Pre-trained BERT의 처음 4개 layer로 초기화한다.
Scene Encoding
3D scene의 point cloud가 주어지면, segmentation mask를 사용해 scene을 object bag으로 분해한다. 각 object에 대해 1024개의 point를 sampling하고 좌표를 unit ball로 정규화한 뒤, PointNet++로 point feature $f_i$와 semantic class $c_i$를 추출한다. 여기에 location 정보 $l_i$(3D position, length, width, height)를 추가하여 object token $o_i$를 구성한다.
$o_i = f_i + W_c c_i + W_l l_i, \quad i = 1, 2, \ldots, N$
Object 간의 spatial relation을 포착하기 위해, Spatial Transformer를 도입한다. Object pair $(i, j)$에 대한 pairwise spatial feature $s_{ij}$를 정의한다.
$s_{ij} = [d_{ij}, \sin(\theta_h), \cos(\theta_h), \sin(\theta_v), \cos(\theta_v)]$
$d_{ij}$는 Euclidean distance, $\theta_h$와 $\theta_v$는 두 object 중심을 잇는 선의 수평/수직 각도이다. 이 pairwise spatial feature $S = [s_{ij}] \in \mathbb{R}^{N \times N \times 5}$를 self-attention의 attention weight에 반영한다.
$\text{Attn}(Q, K, V, S) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + \log \sigma(Sw)\right) V$
$w \in \mathbb{R}^5$는 spatial feature를 attention score로 매핑하는 학습 가능한 parameter이고, $\sigma$는 sigmoid function이다.
Multi-modal Fusion
Text token과 3D object token을 단순히 concatenate하여 $L$-layer Unified Transformer에 넣는다. Learnable type embedding을 추가하여 text와 3D object를 구분한다. Multi-modal fusion module의 출력은 $\{w_{cls}, w_{1:M}, o_{1:N}\}$으로, [CLS] token, text token, 3D object token이다.
Self-supervised Pre-training
세 가지 self-supervised proxy task로 3D-VisTA를 pre-train한다.
Masked Language Modeling (MLM)
BERT의 MLM을 따른다. Text token의 15%를 randomly 선택하여, 80%는 [MASK]로, 10%는 random token으로, 10%는 그대로 둔다. 나머지 text와 3D object token이 주어졌을 때 masked token을 예측한다.
$\mathcal{L}_{\text{MLM}} = -\mathbb{E}_{(w,o) \sim D} \log P_\theta(w_m \mid w_{\setminus m}, o)$
Masked Object Modeling (MOM)
MLM과 유사하게, 3D object token의 10%를 masking한다. 단, point feature와 semantic embedding($f_i + W_c c_i$)만 learnable mask embedding으로 대체하고, positional information($W_l l_i$)은 유지한다. Masked object의 semantic class $c$를 나머지 3D object와 text로부터 예측한다.
$\mathcal{L}_{\text{MOM}} = -\mathbb{E}_{(w,o) \sim D} \log P_\theta(c(o_m) \mid o_{\setminus m}, w)$
Scene-Text Matching (STM)
Scene과 text의 global alignment를 학습한다. [CLS] token의 output을 2-layer MLP에 넣어 scene과 text가 match하는지 예측한다. 30%의 sample은 random하게 선택된 다른 scene 또는 text로 대체하여 negative pair를 생성한다.
$\mathcal{L}_{\text{STM}} = -\mathbb{E}_{(w,o) \sim D} \log P_\theta(y \mid w, o)$
최종 pre-training loss는 세 objective의 합이다.
$\mathcal{L}_{\text{pre-train}} = \mathcal{L}_{\text{MLM}} + \mathcal{L}_{\text{MOM}} + \mathcal{L}_{\text{STM}}$
ScanScribe
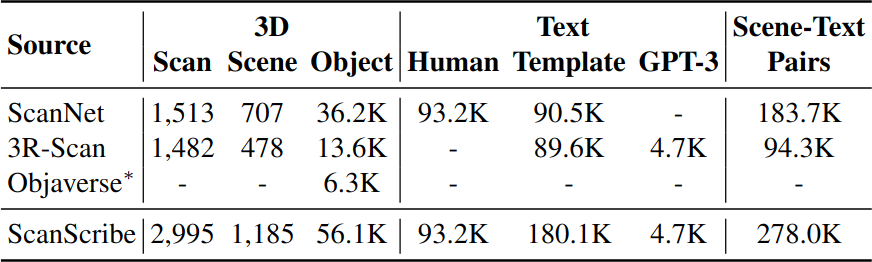
3D-VL pre-training을 위한 최초의 대규모 3D scene-text pair 데이터셋이다. ScanNet과 3R-Scan에서 수집한 2,995 RGB-D scan(1,185개 unique indoor scene)으로 구성되며, 총 278K scene-text pair를 포함한다.
데이터 구축은 두 단계로 진행된다. 먼저 3D scene을 수집하고, 각 scene의 object instance 10%를 Objaverse 3D object database의 동일 카테고리 object로 random하게 교체하여 다양성을 높인다. 다음으로 text를 생성하는데, 기존 3D-VL 데이터셋(ScanRefer, ScanQA 등)의 annotation을 변환하거나, scene graph에 기반한 template으로 scene description을 만들거나, GPT-3를 활용하여 다양한 description을 생성한다.
Downstream Task Finetuning
Pre-trained 3D-VisTA에 lightweight task head를 추가하여 fine-tuning한다.
- 3D Visual Grounding: 2-layer MLP를 object token에 적용하여 target object의 확률을 구하고, cross-entropy loss로 학습한다.
- 3D Dense Captioning: [CLS] token $w_{cls}$로부터 text token을 autoregressive하게 생성하고, cross-entropy loss로 학습한다.
- 3D Question Answering: Object token과 text token을 modular co-attention network(MCAN)에 넣어 answer를 예측하고, QA loss로 학습한다.
- 3D Situated Reasoning: 3D QA와 유사한 설정에서 situation description과 question을 단일 input sentence로 처리한다.
Experiments
Implementation Details
Pre-training은 batch size 128로 수행하며, AdamW optimizer에 learning rate $4 \times 10^{-4}$를 사용한다. Unified Transformer의 layer 수는 4로 설정하고, pre-training과 fine-tuning 모두 NVIDIA A100 GPU 1대에서 수행한다.
Downstream Task Results
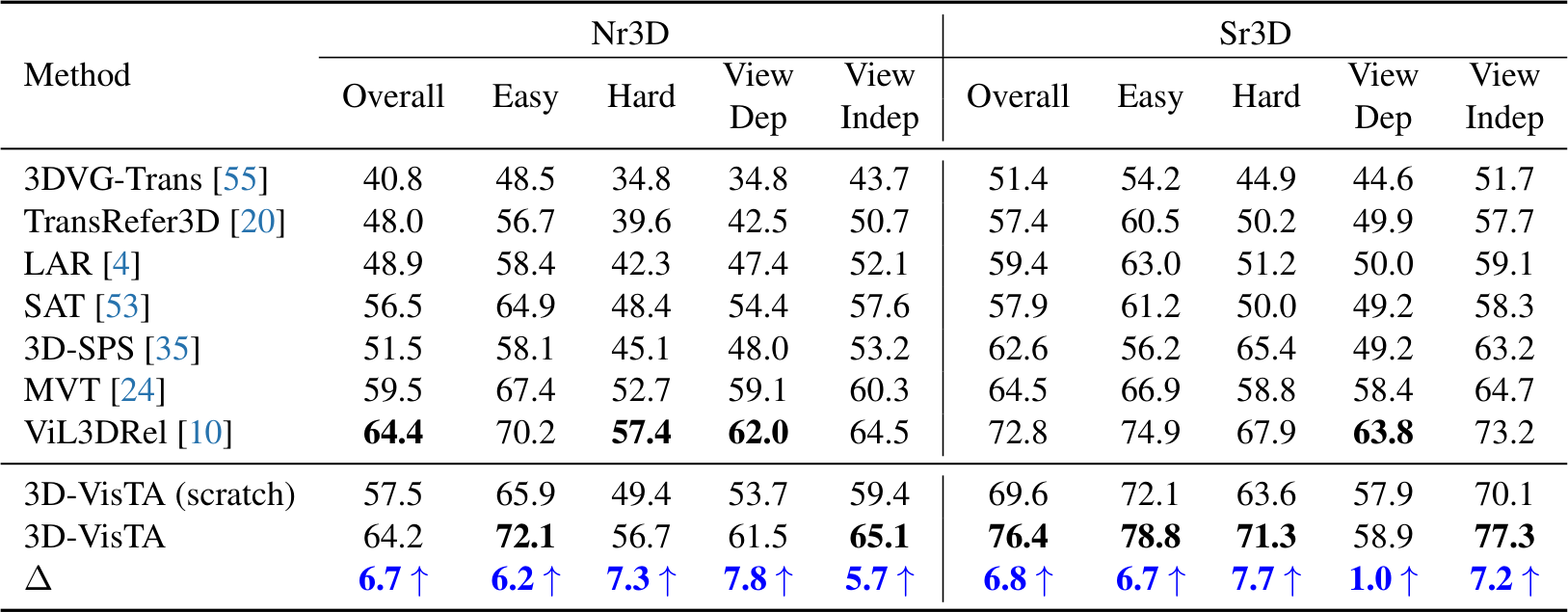
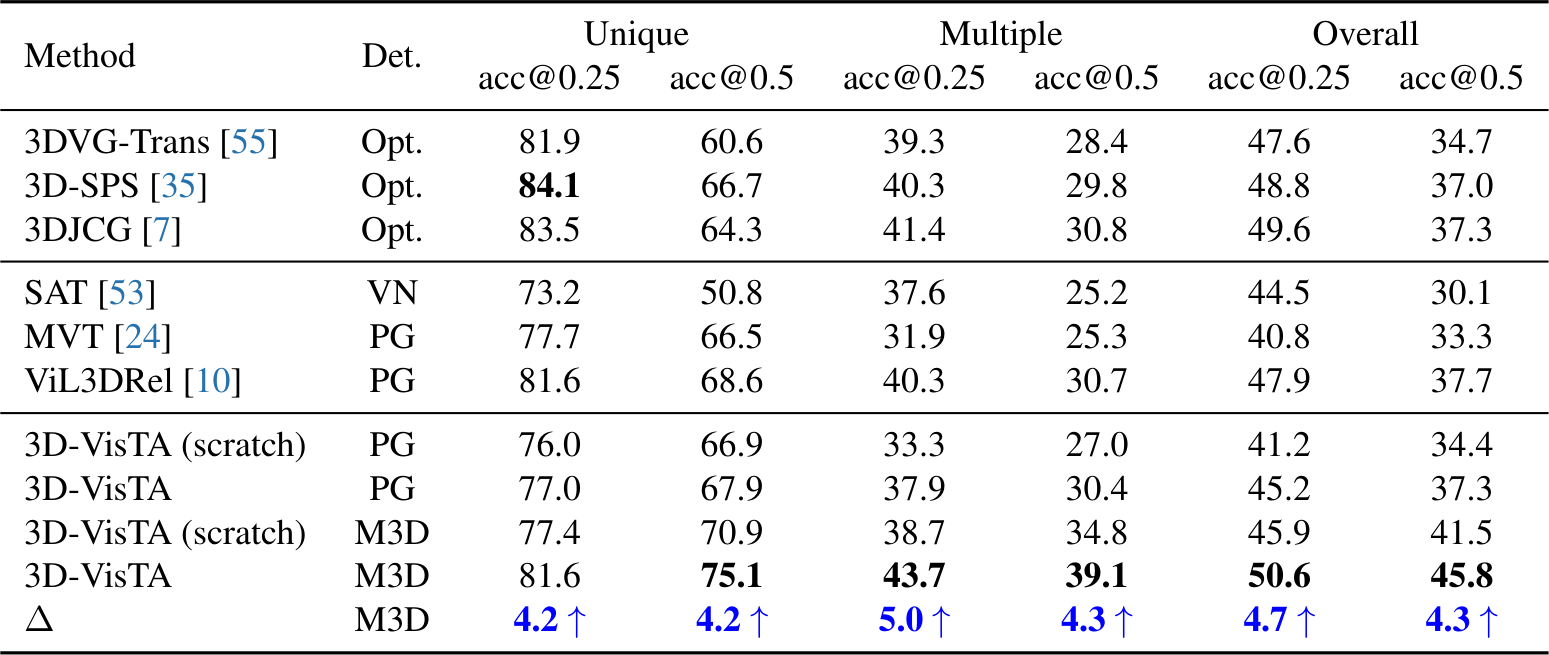
3D Visual Grounding
Nr3D와 Sr3D에서, 3D-VisTA(scratch)는 이미 기존 SOTA와 경쟁력 있는 성능을 보인다(Sr3D Overall 69.6%). Pre-training 후에는 Nr3D에서 64.2%, Sr3D에서 76.4%로 향상되어, 기존 best인 ViL3DRel(73.2%)을 큰 폭으로 능가하며 SOTA를 달성한다.
ScanRefer에서도 Mask3D object proposal을 사용했을 때 Unique subset 기준 acc@0.25에서 75.1%, acc@0.5에서 43.7%를 달성하여 SOTA를 능가한다.
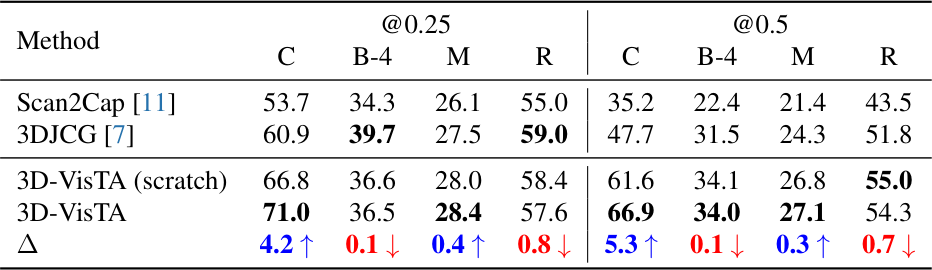
3D Dense Captioning
Scan2Cap에서 C@0.5 기준 66.9%, B-4@0.5 기준 34.0%를 달성한다. 3D-VisTA는 BLEU-4, METEOR, ROUGE, CIDEr 전 metric에서 이전 방법들을 능가한다.
3D Question Answering
ScanQA에서 EM@1 27.0/23.0을 달성하며, BLEU-4(16.0/11.9), CIDEr(76.6/62.6) 모두 기존 방법을 크게 능가한다.
3D Situated Reasoning
SQA3D에서 평균 정확도 48.5%를 달성한다.
전체적으로 다음과 같은 관찰이 가능하다.
- 3D-VisTA는 scratch부터 학습해도 경쟁력 있는 성능을 보여, 단순한 아키텍처의 효과를 입증한다.
- ScanScribe로 pre-training하면 모든 task에서 일관된 성능 향상이 나타난다. Nr3D/Sr3D에서 6.7%/6.8%, ScanRefer에서 4.7%/4.3% 향상된다.
- Pre-trained 3D-VisTA는 ViL3DRel을 Sr3D에서 큰 폭으로 능가하며, Scan2Cap, ScanQA, SQA3D에서도 새로운 SOTA를 달성한다.
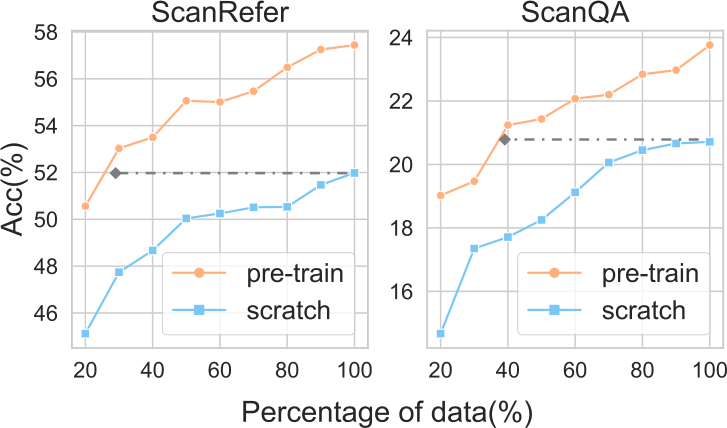
- 30~40%의 annotation만으로 fine-tuning해도 full data로 scratch 학습한 것보다 좋은 성능을 달성하여, pre-training의 data efficiency를 보여준다.
Ablation Studies
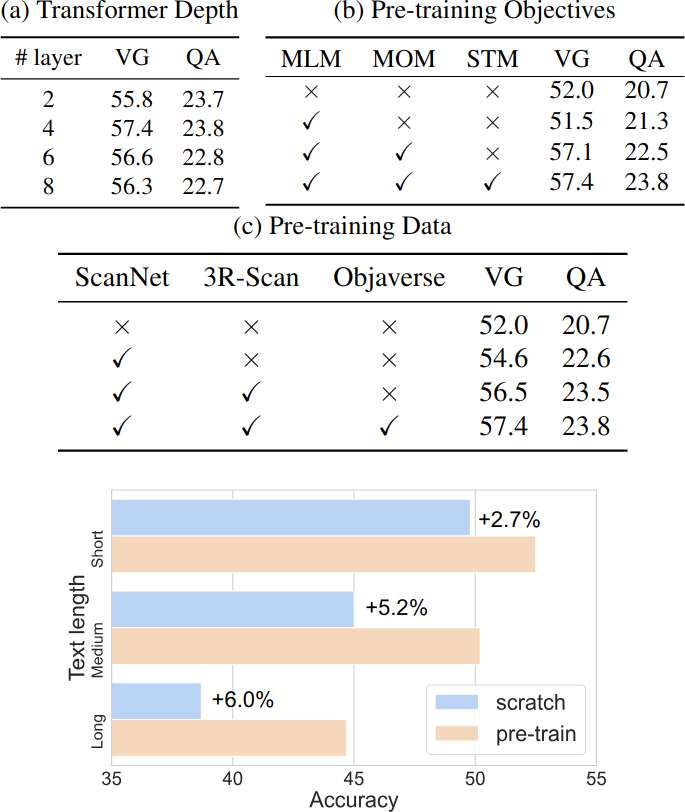
Transformer Depth. Unified Transformer의 layer 수를 2~8로 변화시키며 테스트한 결과, 4-layer가 최적이며 더 깊게 쌓아도 성능이 향상되지 않는다. 이는 ScanScribe의 규모가 아직 deep model을 충분히 활용하기에는 부족함을 시사한다.
Pre-training Objectives. MLM만 사용하면 QA에 약간 도움이 되지만 VG에는 오히려 부정적이다. MOM과 STM을 추가하면 QA와 VG 모두 향상되며, 세 objective를 모두 사용할 때 최고 성능을 달성한다. STM과 MOM이 3D vision-text alignment에 가장 크게 기여한다.
Pre-training Data. ScanNet만 사용해도 성능 향상이 나타나며, 3R-Scan과 Objaverse를 추가할수록 데이터 양과 다양성이 증가하여 VG와 QA 모두 꾸준히 향상된다. 세 데이터 소스를 모두 사용할 때 최고 성능을 달성한다.
Qualitative Studies

Pre-training이 3D-VisTA의 spatial understanding을 향상시킨다. Visual grounding에서 human prior viewpoint와 spatial relation에 대한 추론이 개선되어, 같은 class의 여러 instance 중 target object를 정확히 구분할 수 있다. Dense captioning에서는 color, shape 같은 visual concept에 대한 이해가 개선되며, QA와 situated reasoning에서도 비슷한 향상이 관찰된다. 긴 text query에서 pre-training의 효과가 더 크게 나타난다.
Conclusion
3D-VisTA는 self-attention layer만으로 3D scene과 text를 align하는 단순하면서도 효과적인 아키텍처이다. ScanScribe라는 최초의 대규모 3D scene-text pair 데이터셋을 구축하여 3D-VL pre-training을 가능하게 했고, 다양한 3D-VL task에서 SOTA를 달성하면서 뛰어난 data efficiency를 보여준다.
Future Work
현재 offline 3D object detection module을 사용하는 점이 병목이므로, detection module을 pre-training 단계에서 jointly optimize하는 것이 향후 방향이다. 또한 ScanScribe의 데이터 규모를 더 늘리고, model size도 scaling하는 것이 3D-VL 학습을 한 단계 발전시킬 수 있다.