Convolutional Layers
지금까지 다루었던 Fully-Connected Layer의 경우, 인풋 데이터 $\mathbf{x}$ 전체에 가중치 $\mathbf{W}$를 곱하는 방식이다. 즉, $f(\mathbf{x}) = \mathbf{W} \cdot \mathbf{x}$로 표현된다. 이는 아래 이미지와 같이 인풋과 같은 크기와 채널 수를 가지는 Weight Matrix를 만들고, 이를 인풋 데이터와 element-wise multiplication한 후 모두 더하는 것으로 해석할 수 있다. 학습 결과 이 Weight Matrix는 각 클래스 자체를 대변하는 Template이 된다.
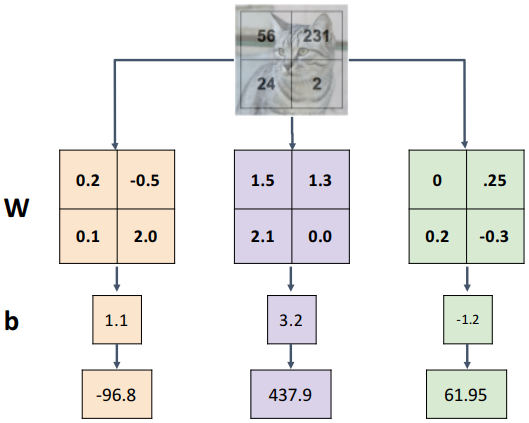

이러한 방식의 단점으로, 각 템플릿은 '융통성'이 없다. 즉, 템플릿에 나타난 바로 그 위치에 물체가 있을 때만 높은 점수를 주고, 물체의 위치가 조금이라도 다르면 낮은 점수를 준다. 그렇다면 이미지 전체를 대상으로 하나의 큰 템플릿 매칭을 하는 것이 아니라, 물체의 작은 특징들에 대한 템플릿을 구하고 이러한 템플릿을 모아 물체를 판별하면 어떨까?
Convolutional Layer가 바로 그 역할을 한다. 이미지보다 작은 크기의 템플릿인 '필터'를 만들고, 이미지의 '일부분'과 element-wise multiplication한 후 모두 더하는 방식을 사용한다.
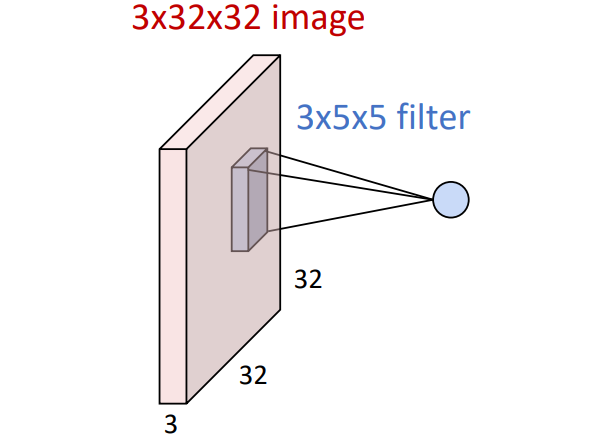
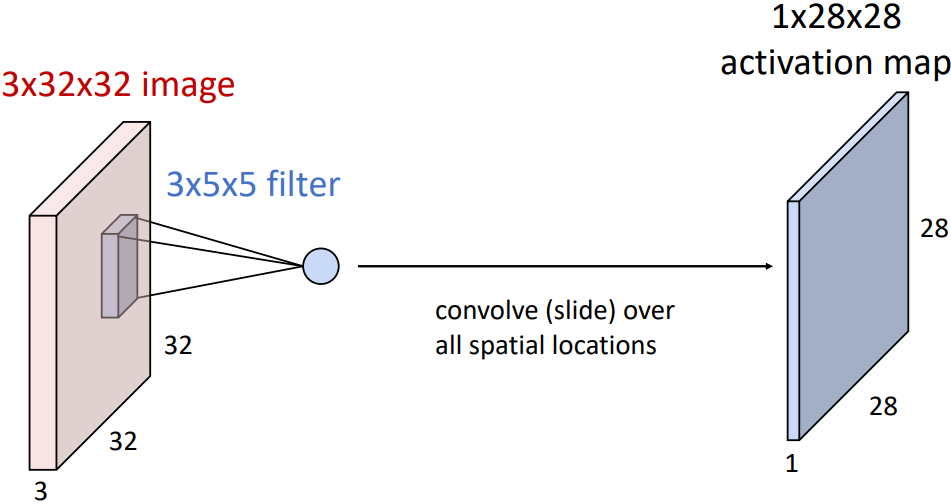
위 그림이 이에 해당되는데, 3x5x5 크기의 영역만을 활용하여 element-wise multiplication을 수행하고 모두 더하여 숫자 하나를 만들어낸다. 그 숫자가 바로 이미지의 해당 영역에서의 그 템플릿에 대한 점수이다.
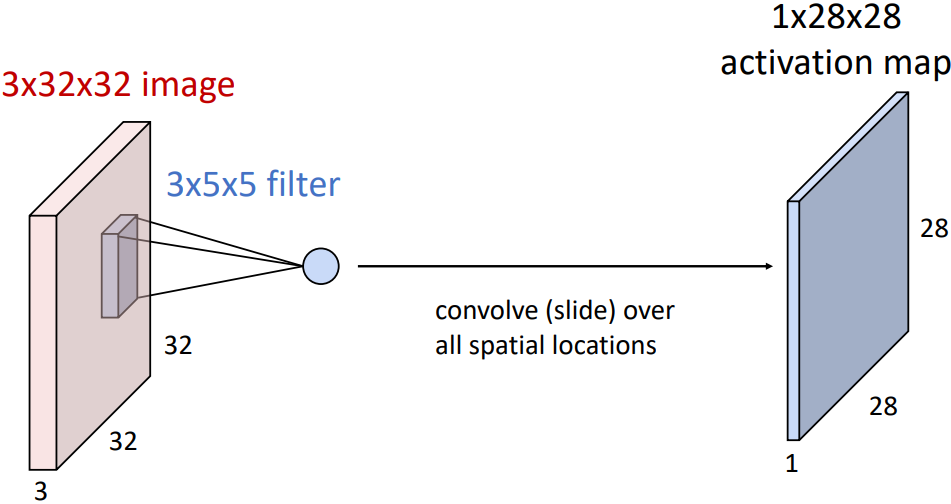
템플릿을 이미지의 좌상단부터 우하단까지 이동시키면서 각 위치에 대한 점수를 계산할 수 있고, 이 숫자를 모아 2D Matrix로 표현할 수 있다. 이를 Activation map이라고 한다. 따라서 Activation map에는 그 필터가 찾고자 하는 특징이 있는 영역에 높은 값이 들어가고, 그렇지 않은 영역에는 낮은 값이 들어간다.
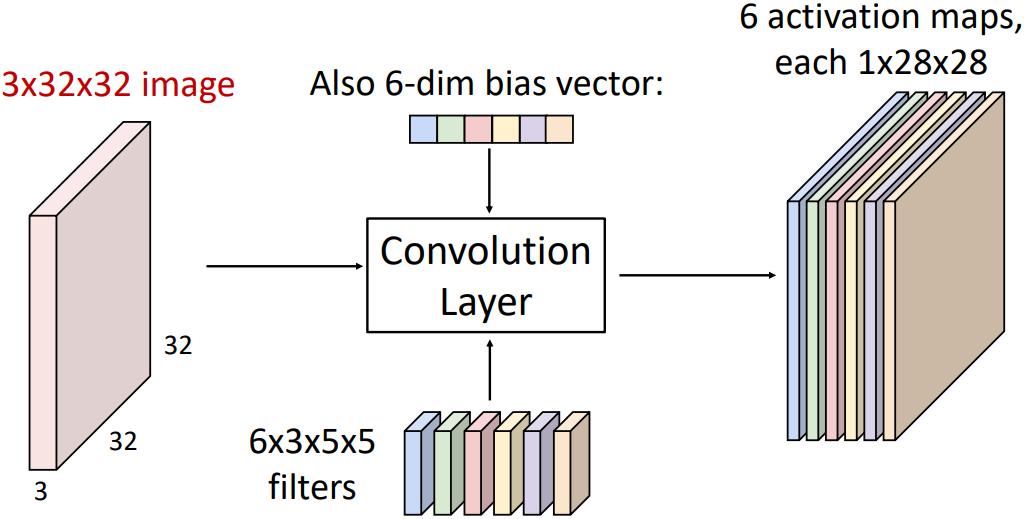
이때 여러가지 특징에 대해 각각의 템플릿(필터)를 적용하면 아래 그림과 같이 필터 개수만큼의 Activation map이 나오게 된다.
마지막으로, training 과정에서는 하나의 이미지가 아닌 mini-batch로 여러 이미지를 한 번에 처리한다. 따라서 하나의 batch가 들어왔을 때의 activation map은 아래 그림과 같다.
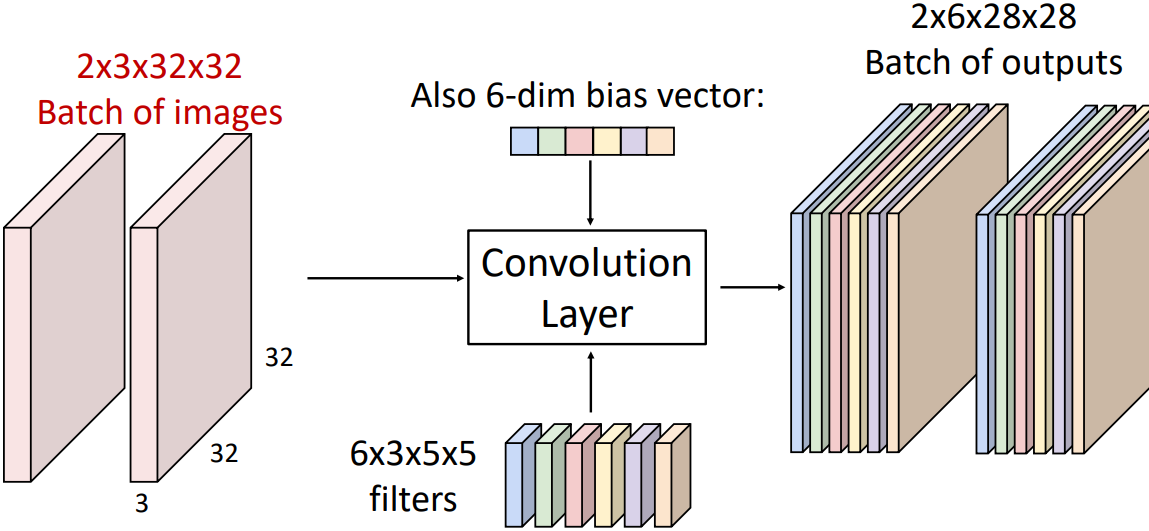
즉, input shape는 $N \times C_{in} \times H \times W$, filter shape는 $C_{out} \times C_{in} \times K_h \times K_w$일 때, output shape는 $N \times C_{out} \times H_{out} \times W_{out}$이다. 각 파라미터의 의미는 다음과 같다.
- $N$: batch size
- $C_{in}$: input channel
- $C_{out}$: output channel
- $H$: input height
- $W$: input width
- $H_{out}$: output height
- $W_{out}$: output width
- $K_h$: filter height
- $K_w$: filter width
그 결과, 아래와 같이 filter들을 visualize할 수 있다. 전체적인 물체의 형태 대신 모서리나 원 등 작은 기하학적 특징을 찾는 것을 확인할 수 있다.

Stacking Convolutions
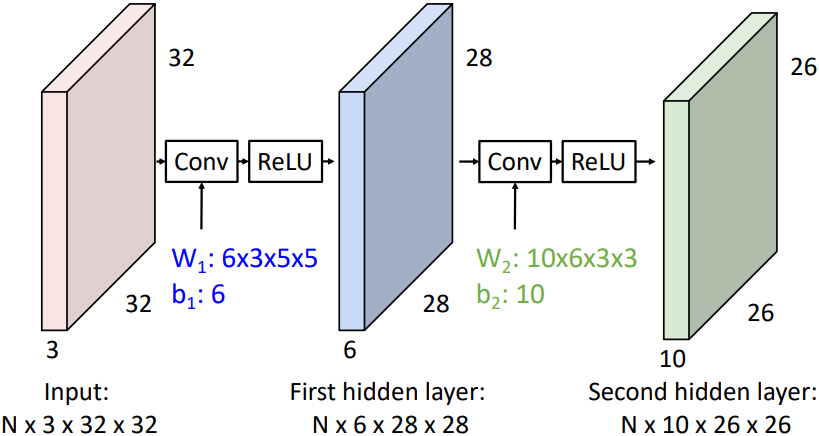
Convolutional Layer를 여러 층으로 쌓으면 더 복잡한 특징을 찾을 수 있다. 첫 번째 Convolutional Layer가 이미지에서 직접 특징을 찾는다면, 그 다음 Convolutional Layer부터는 Activation map에서 특징을 찾는다. 그 말은, 앞에서 찾은 작은 특징을 조합하여 더 고차원적인 특징을 찾는다는 것이다. 이미지의 한 부분에서 특징 A가 높게 나오고 그 바로 옆에서는 특징 B가 높게 나온다면, 다음 layer에서는 이 둘을 조합하여 고차원적인 특징 C를 찾을 수 있는 것이다.
이때 두 Convolutional Layer 사이에 Activation Function을 추가하여 두 Layer가 하나로 합쳐지는 것을 방지한다. 주로 ReLU 함수를 사용한다.
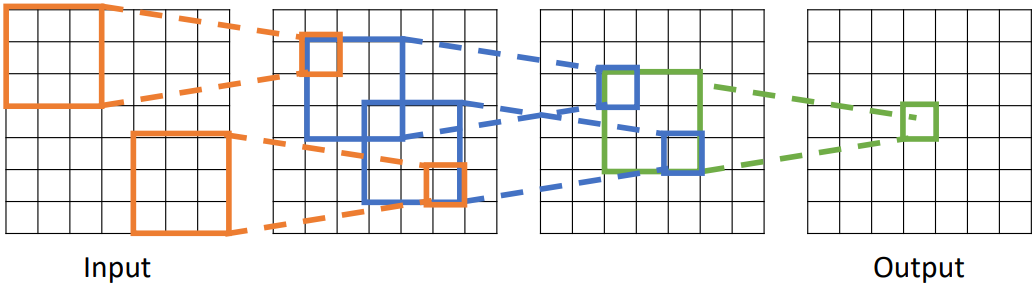
위 그림은 여러 Convolutional Layer가 쌓였을 때, output의 한 element에 영향을 미치는 이전 layer의 영역을 표시한다. 이를 Receptive Field라고 한다. Layer가 많아질수록 Receptive Field가 커지며, 이는 작은 필터로도 더 넓은 영역에 걸친 특징까지 찾아낼 수 있다는 것을 의미한다. Receptive Field의 한 변의 길이는 아래의 수식으로 계산할 수 있다. $L$을 Layer의 개수라고 할 때,
$RF = 1 + L \times (K - 1)$
가 된다. 위 그림에서 input layer의 Receptive Field를 구해 보면, 총 3개의 Layer를 거쳤으므로 $1 + 3 \times (3 - 1) = 7$이 된다.
Padding
위 이미지를 보면, Convolutional Layer를 거치면서 이미지의 크기가 줄어드는 것을 확인할 수 있다. 인풋 이미지가 한 변의 길이가 $W$인 정사각형이고 필터의 크기가 $K$라면, Convolutional Layer를 거치면 이미지의 한 변의 길이는 $W - K + 1$이 된다.
이를 방지하기 위해 이미지의 모서리에 0으로 채워진 여분의 픽셀을 덧대는 방식을 사용하는데, 이를 Padding이라고 한다.
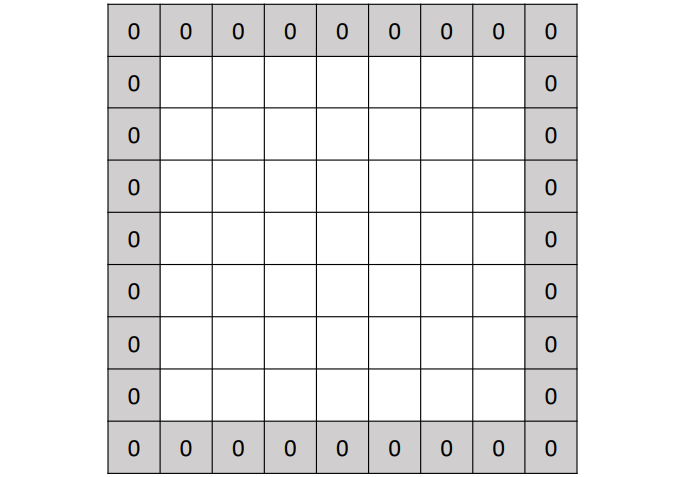
위 예시의 경우, 원래는 7x7 이미지에 3x3 필터를 적용하면 5x5 Activation map이 나오게 된다. 이때 이미지의 모서리에 1픽셀 크기의 Padding을 적용하면 총 9x9 이미지가 되고, 여기에 3x3 필터를 적용하면 기존과 동일한 크기인 7x7 Activation map이 나오게 된다.
Padding까지 고려한 Activation map의 크기는 아래와 같이 계산할 수 있다. $P$를 Padding의 크기라고 하자.
$W_{out} = W - K + 1 + 2P$
또한 $W_{out} = W$를 맞추기 위해, 보편적으로 $P = \frac{K - 1}{2}$로 설정한다.
Stride
Filter를 sliding할 간격을 직접 설정할 수 있는데, 이를 Stride라 한다. Stride가 1이면 한 픽셀씩 이동하고, 2이면 두 픽셀씩 이동한다. Stride에 따라서도 Activation map의 크기가 달라진다.
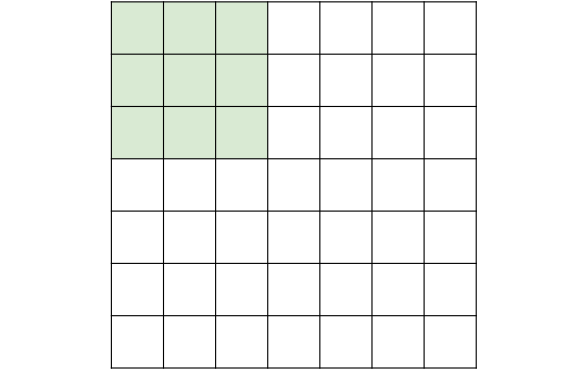
위 그림처럼 이미지의 크기가 7이고 필터의 크기가 3일 때, Stride가 2인 경우 Activation map의 크기는 3이 된다. 이를 일반화하면 아래와 같다. $S$를 Stride의 크기라 하자.
$W_{out} = \frac{W - K + 2P}{S} + 1$
보편적인 파라미터들의 조합은 다음과 같다.
- $K = 3, P = 1, S = 1$: 3x3 conv
- $K = 5, P = 2, S = 1$: 5x5 conv
- $K = 1, P = 0, S = 1$: 1x1 conv
- $K = 3, P = 1, S = 2$: 3x3 conv, stride 2
Stride를 통해 Activation map의 크기를 줄일 수 있으며, 이는 아래에 살펴볼 Pooling Layer와 유사하게 downsampling을 하는 효과가 있다.
Pooling Layers
Pooling Layer는 downsampling을 통해 이미지의 크기를 줄이는 Layer이다. 크게 세 가지 이유로 downsampling을 하게 되는데, 첫째, 적은 수의 Layer로 Receptive Field를 늘릴 수 있으며 둘째, 연산량을 줄일 수 있다. 마지막으로, 특히 Max Pooling의 경우 작은 변화에 대해 불변성을 부여할 수 있다. 예를 들어, 이미지가 한두 픽셀 이동하거나 회전하더라도 Max Pooling을 거치면 Activation map이 크게 변하지 않게 된다.
Pooling Layer에는 세 가지 Hyperparameter가 존재한다.
- Pooling Function: Max Pooling, Average Pooling 등
- Kernel Size: Pooling을 적용할 영역의 크기
- Stride: Pooling을 적용할 간격
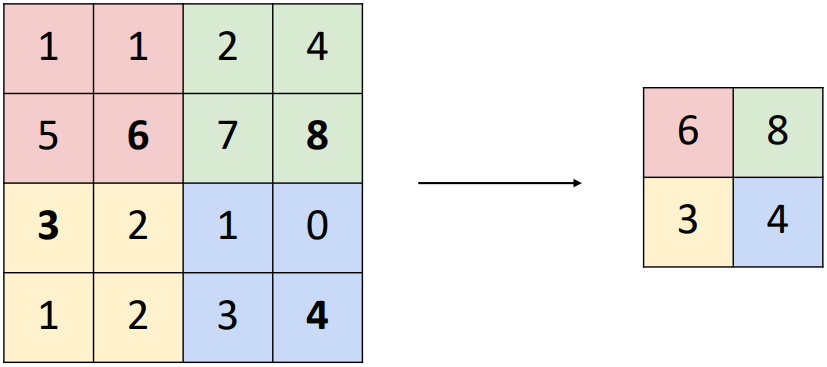
위 예시는 4x4 이미지에 2x2 Kernel Size로 Max Pooling을 적용한 결과이다. 각 영역별로 가장 큰 값을 선택하여 Activation map을 만들게 된다. Average Pooling의 경우 최댓값 대신 평균값을 이용한다는 것 외에는 모두 동일하다. Pooling Layer에는 학습 가능한 파라미터가 없으며, Max Pooling이나 Average Pooling 등 미리 정해진 함수를 사용한다. Pooling Layer에서는 Padding을 사용하지 않는다.
Max Pooling이 가장 보편적으로 사용되는 Pooling Function인데, 그 이유는 Convolution Layer의 목적 자체가 이미지의 각 영역에 우리가 원하는 특징이 있는지를 찾는 것이기 때문이다. 따라서 score 값이 큰 픽셀이 있다면, 그곳에는 우리가 찾고자 하는 특징이 있다는 뜻이기 때문에 그 정보를 유지하여 다음 Layer로 넘기는 것이 유리하다.
Pooling Layer의 output shape는 다음과 같이 계산할 수 있다. $K$를 필터의 크기, $S$를 Stride의 크기라 하자.
$W_{out} = \frac{W - K}{S} + 1$
보편적인 파라미터들의 조합은 다음과 같다.
- Max Pooling, $K = 2, S = 2$
- Max Pooling, $K = 3, S = 2$ (AlexNet)
Batch Normalization
Batch Normalization은 인풋 데이터의 분포를 일정하게 하여 training 수렴 속도를 높이는 유용한 방법이다. Network가 깊어도 빠르게 잘 수렴하도록 해 준다.
Train Time
Training 시 Mini-Batch 단위로 학습을 진행하게 되는데, 한 레이어의 파라미터가 업데이트됨으로 인하여 다음 레이어의 입력 데이터의 분포가 변하게 된다. 즉, 다음 레이어로 들어오는 mini-batch의 평균이나 분산이 데이터 자체가 다르기 때문뿐만 아니라 이전 레이어로 인해 바뀌는 것이다. 이를 Internal Covariate Shift라고 한다.
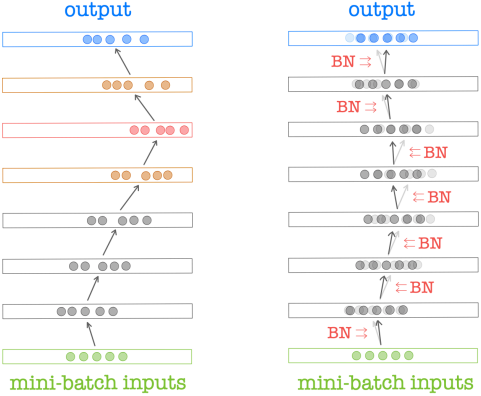
위 그림과 같이, layer를 많이 거칠수록 초기 layer의 작은 파라미터 변화가 batch 전체 평균이나 분산의 큰 변화를 가져오는 문제가 발생한다. 따라서 뒤쪽 layer의 경우 이전 batch로 파라미터를 업데이트했는데 이전과 유사한 데이터가 들어오지 않으니 weight update가 step마다 불규칙적으로 진행되거나 weight의 각 element 간에도 update되는 속도가 달라지는 문제가 발생한다. 이는 결과적으로 optimization의 속도를 늦추게 된다.
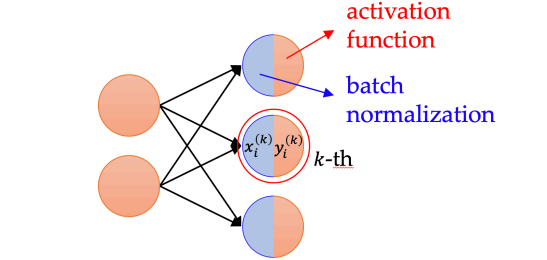
이러한 문제를 해결하기 위해, 위 그림과 같이 각 conv layer에서 output이 출력될 때마다 그 batch 내 이미지들의 평균과 분산을 $\beta$, $\gamma$로 변환시켜 준다. 이때 $\beta$, $\gamma$는 node마다 하나씩 할당되는데, 지금까지 지나간 batch들을 통해 최적화된 "공통 평균", "공통 분산"에 해당한다. 이를 Batch Normalization이라 한다. 주로 conv layer 또는 FC layer와 Activation function 사이에 적용된다.
Batch 내 이미지들의 평균과 분산을 원하는 값으로 변환시키기 위해서는, 우선 그 batch 내에서 평균과 분산을 각각 0과 1로 표준화시켜야 한다. 이때 Batch Normalization은 채널별로 수행되므로, 한 batch에 RGB 이미지 100장이 있다면 R채널 100장, G채널 100장, B채널 100장으로 분리한 뒤 각 채널별로 100장의 모든 픽셀값을 이용해 연산을 수행한다. 따라서 $\beta$, $\gamma$는 그 크기가 채널의 개수인 벡터가 된다.
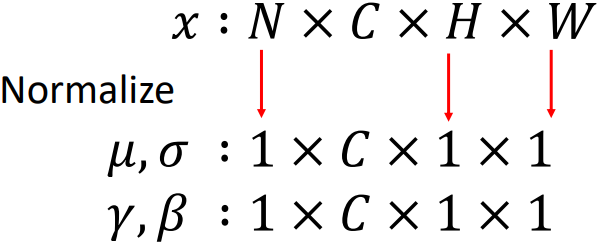
Batch Normalization 관련 변수의 shape는 위 그림과 같다.
$\begin{align*} \mu_j & = \cfrac{1}{N} \sum_{i=1}^{N} x_{i, j} \\ \sigma_j^2 & = \cfrac{1}{N} \sum_{i=1}^{N} (x_{i, j} - \mu_j)^2 \\ \hat{x}_{i, j} & = \cfrac{x_{i, j} - \mu_j}{\sqrt{\sigma_j^2 + \epsilon}} \\ y_{i, j} & = \gamma_j \hat{x}_{i, j} + \beta_j\end{align*}$
위 수식은 한 batch 내 이미지를 평균이 0, 분산이 1인 분포로 변환시킨 후 $\beta$, $\gamma$를 이용해 원하는 분포로 만드는 과정이다. $x_{i, j}$는 $i$번째 이미지의 $j$번째 채널, $y_{i, j}$는 $i$번째 이미지의 $j$번째 채널의 Normalize된 값이다. $\epsilon$ 은 분모가 0이 되는 것을 방지하기 위한 작은 상수이다.
이때, $\beta$와 $\gamma$는 학습 가능한 파라미터이다. 즉, 사람이 직접 설정한 값이 아니라 batch가 지날 때마다 업데이트된다. 이는 batch 내의 평균과 분산 또한 데이터의 특성이 될 수 있기 때문인데, 평균과 분산을 완전히 없애는 대신 학습 가능한 파라미터로 두어 네트워크가 스스로 최적화할 수 있도록 한다.
Batch Normalization을 통해 각 채널의 평균과 분산을 통일해 줌으로써 앞 레이어의 파라미터들이 업데이트되더라도 이미지들이 일정한 분포를 가지게 해 준다. 그 결과, learning rate를 크게 하거나 sigmoid 등 saturate되는 activation function을 사용할 수 있고, weight initialization에도 덜 영향을 받게 된다.
Test Time
Training을 할 때에는 batch별로 $\mu$와 $\sigma$를 구할 수 있지만, test 시에는 mini-batch가 없다. 따라서, test 시에는 training 때 구해놓은 $\mu$와 $\sigma$를 사용해야 한다. 각 mini-batch가 지나갈 때마다 moving average를 통해 값을 가중치 평균하여 전체 데이터에 대한 $\mu^{test}_j$와 $\sigma^{test}_j$를 구하게 된다.
$\begin{align*} \mu^{test}_j & = 0.99 \mu^{test}_j + 0.01 \mu_j \\ \sigma^{test}_j & = 0.99 \sigma^{test}_j + 0.01 \sigma_j \end{align*}$
이 과정을 통해 test 시에도 Batch Normalization을 적용할 수 있게 된다. 이때는 $\mu^{test}_j$와 $\sigma^{test}_j$가 고정된 값이므로, Convolutional layer의 weight와 bias에 포함되어 함께 계산될 수 있다. 이를 통해 test 시에는 Batch Normalization의 연산량이 사실상 0이 된다.
Batch Normalization Results
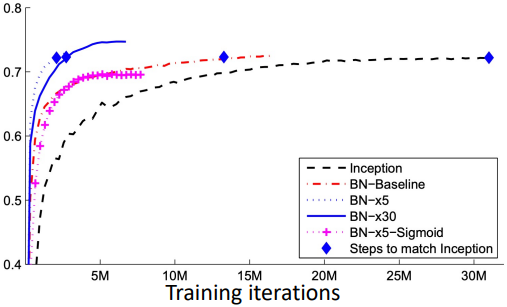
Batch Normalization 여부에 따른 학습 속도를 그래프로 비교하면 위 그림과 같다. Batch Normalization을 적용한 경우(파란색 실선) 그렇지 않은 경우(검은색 점선)보다 학습이 훨씬 빠르게 진행되는 것을 확인할 수 있다.
- Learning rate를 크게 해도 학습이 잘 진행된다.
- Weight initialization에 덜 민감하다.
- Regularizaion의 역할을 한다.
- Test 시 추가적인 연산이 필요하지 않다.
Batch Normalization은 위와 같은 장점들이 있지만, 이론적으로 완전히 검증되지 않았고 training과 testing에서의 동작이 달라 버그의 요인이 될 가능성이 높다는 단점이 있다. 그럼에도 Batch Normalization은 현재 수많은 Deep network에 필수적으로 사용되고 있다.
Variants of Batch Normalization
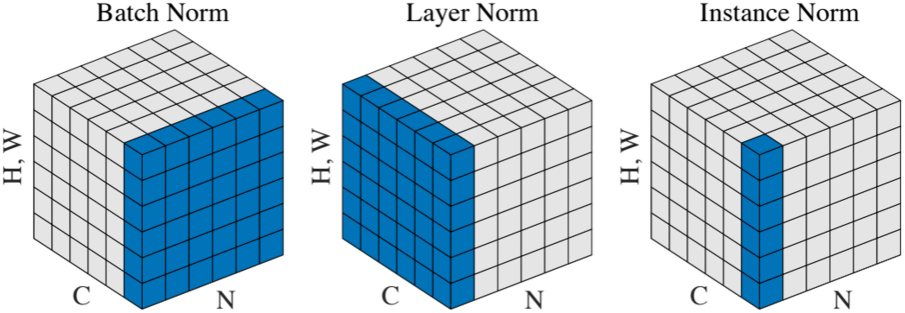
Layer Normalization
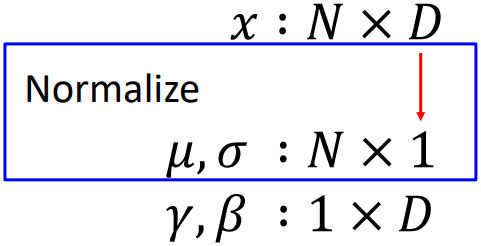
Layer Normalization은 FC layer나 RNN, Transformer 등에서 사용되는 방법이다. Batch Normalization이 채널 단위로 평균과 분산을 구하는 것과 달리, Layer Normalization에서는 각 batch에 대해 평균과 분산을 구한다. FC layer에서는 각 인풋이 벡터이기 때문에 이러한 연산이 가능하다. 다만 이 방식은 앞선 레이어에 포함되어 함께 연산할 수 없기 때문에 따로 forward pass와 backpropagation을 수행해야 한다.
Instance Normalization
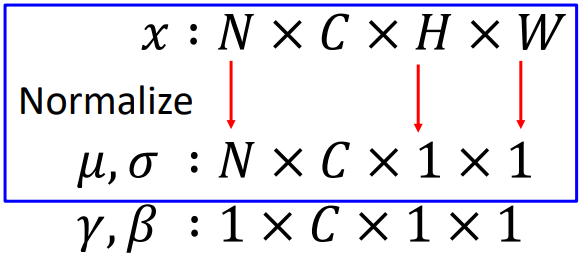
Instance Normalization은 CNN에서 사용되는데, 각 이미지를 독립적으로 생각하여 한 이미지에 대해서만 채널별 픽셀값들의 평균과 분산을 구하는 방식이다. 각 이미지가 독립적으로 처리되기 때문에 Batch Normalization과 달리 training과 test 시의 동작이 같다.