Computational Graph
Neural Network를 구성하기 위한 마지막 개념으로, 어떻게 각 parameter에 대한 gradient를 계산할 수 있는지 살펴보자. Loss 값을 이용해 gradient를 계산할 수 있다면 Lecture 5에서 다룬 SGD, Adam 등을 활용해 parameter를 업데이트할 수 있다.
즉, 우리의 목표는 gradient $\frac{\partial L}{\partial w}$를 계산하는 것인데, 수식을 통해 도함수를 구하는 방식은 모델이 커질수록 불가능하게 된다. 이를 해결하기 위해 backpropagation이라는 방법을 사용하는데, Computational Graph라는 개념을 먼저 이해해야 한다.
$L(\mathbf{W}) = \cfrac{1}{N} \sum_{j \neq y_i} \max(0, s_j - s_{y_i} + 1) + \lambda R(\mathbf{W})$
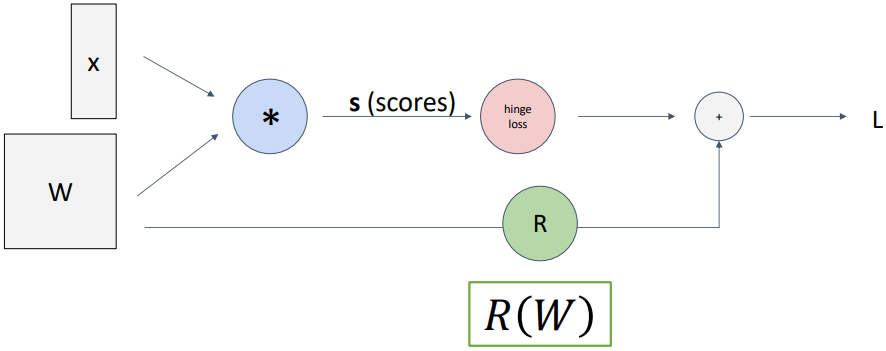
Computational Graph는 수학 연산을 노드로, 변수를 엣지로 표현한 방향이 있는 그래프이다. 예를 들어, 위 그림은 Multiclass SVM Loss function을 computational graph로 나타낸 것이다. 먼저 $\mathbf{W}$와 $\mathbf{x}$를 곱해 score를 구하고, 이를 이용해 hinge loss를 구한 뒤 regularization term을 더한다. 이러한 방식으로 어떤 복잡한 함수라도 기초적인 연산 단위로 분해할 수 있다.
Backpropagation: Simple Example
아래와 같이 단순한 함수를 Computational graph로 표현한다고 가정하자.
$f(x, y, z) = (x + y) \cdot z$
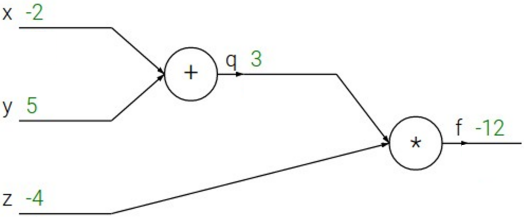
$x = -2, \ y = 5, \ z = -4$를 대입했다고 가정하면 중간 변수는
$q = x + y = 3$
이 되고, 최종 결과는
$f = q \cdot z = -12$
가 된다. 이처럼 입력 변수로부터 출력 변수를 순차적으로 계산하는 과정을 Forward pass라고 한다. 이제 backpropagation을 통해 각 변수에 대한 gradient $\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}, \frac{\partial f}{\partial z}$를 계산해 보자.
우선, $f = q \cdot z$이므로
$\cfrac{\partial f}{\partial z} = q = 3$
이 된다.
다음으로 $\frac{\partial f}{\partial x}$와 $\frac{\partial f}{\partial y}$를 구해야 하는데, $f$로부터 한번에 구하는 것이 아닌, 중간 변수 $q$를 이용해 Chain rule을 적용하여 구할 수 있다.
$\cfrac{\partial f}{\partial q} = z = -4, \quad \cfrac{\partial q}{\partial x} = 1$
$\cfrac{\partial f}{\partial x} = \cfrac{\partial f}{\partial q} \cdot \cfrac{\partial q}{\partial x} = -4$
같은 방식으로 $\frac{\partial f}{\partial y}$를 구하면
$\cfrac{\partial f}{\partial y} = -4$
가 된다.
각 변수에 대한 Gradient를 Computational Graph에 함께 표시하면 아래 그림과 같다.
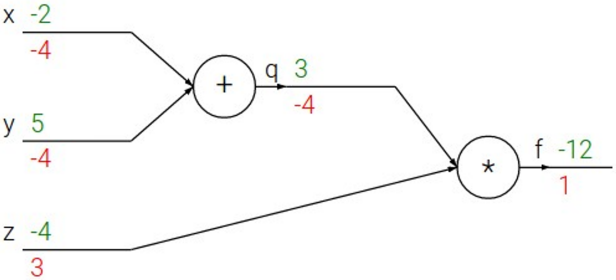
이때 가장 오른쪽 output의 경우 $\frac{\partial f}{\partial f} = 1$이 된다.
덧셈 node만을 자세히 살펴보면, 출력 변수인 $q$에 대한 gradient에 자신의 local gradient $\frac{\partial q}{\partial x}$를 곱하여 입력 변수에 대한 gradient를 계산해 내는 것을 볼 수 있다. 즉, 그래프 전체에 대한 방정식을 알지 못하더라도 각 노드의 local gradient를 계산할 수 있다면 output gradient $\frac{\partial f}{\partial f} = 1$에서부터 순차적으로 거슬러 올라가면서 최종적으로 입력 변수에 대한 gradient를 구할 수 있다. 이것이 Backpropagation 알고리즘이다.
이때 중요한 것은, Backpropagation은 Forward pass를 거친 후에야 작동할 수 있는 알고리즘이라는 것이다. 즉, 임의의 입력값에 대해 도함수 '수식'을 계산하는 알고리즘이 아니라, 특정한 입력값이 있고 forward pass를 통해 중간 변수들의 값을 모두 계산한 상태에서 그 specific한 입력값에 대해서만 gradient를 계산하는 알고리즘인 것이다.
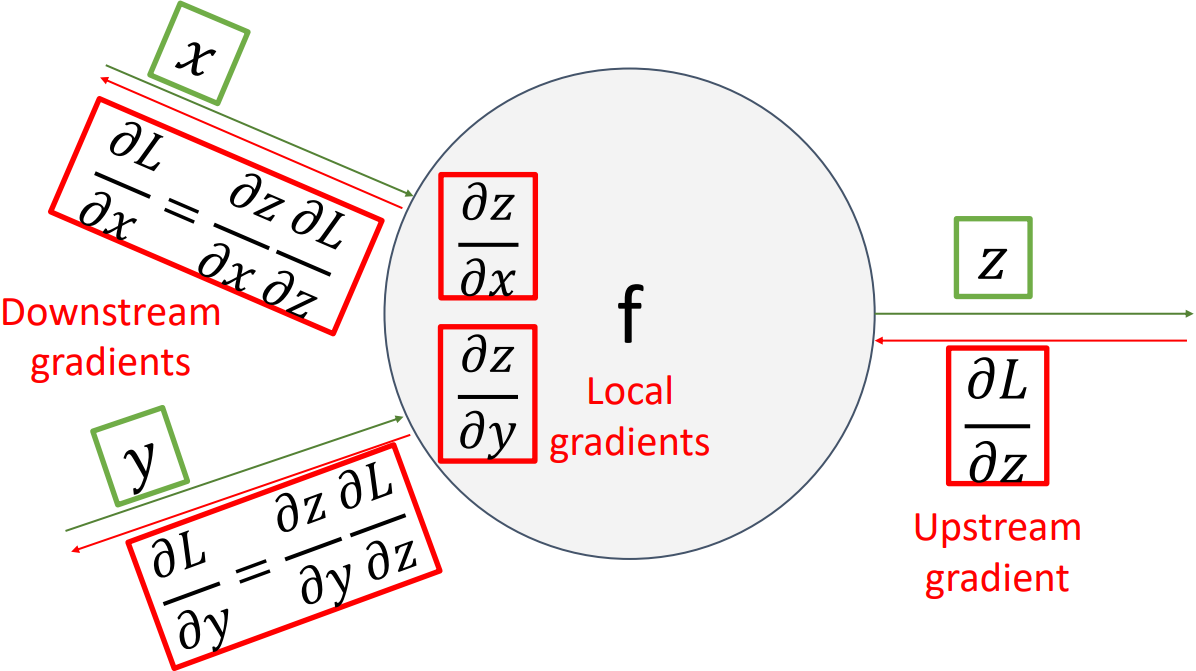
추가적으로, 위 그림과 같이 각 node의 output 변수에 대한 gradient를 Upstream Gradient, node 안에서의 output의 input에 대한 gradient를 local gradient, input 변수에 대한 gradient를 Downstream Gradient라고 부른다.
Patterns in Gradient Flow
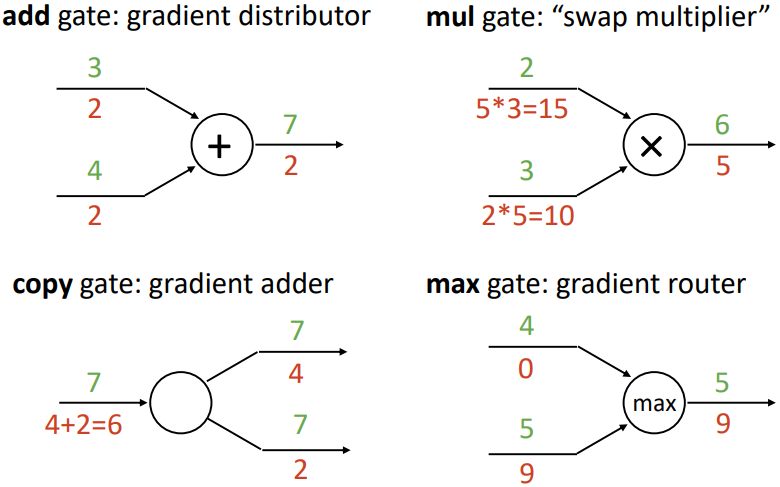
이때, 위 그림과 같이 연산자에 따라 gradient의 흐름에 특정한 패턴이 있다는 것을 알 수 있다.
덧셈의 경우, upstream gradient를 input 노드들로 그대로 전달한다.
Copy node는 한 node의 출력이 여러 node의 입력으로 들어가는 경우인데, 이는 덧셈 node의 dual에 해당한다. 덧셈 node는 변수값들은 더하고 gradient를 그대로 전달하는 것이었다면, copy node는 변수값들은 그대로 복사하고 gradient를 더해서 전달한다.
곱셈의 경우, 한쪽 input의 downstream gradient를 구하기 위해 upstream gradient와 상대쪽 변수의 값을 곱한다.
ReLU에 사용되는 max node의 경우, 입력 변수들 중 가장 큰 쪽으로 gradient를 그대로 전달하고 나머지에는 0을 전달한다.
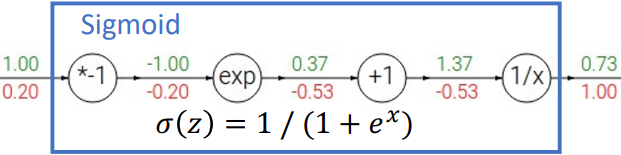
또한, 위 그림과 같이 node를 여러 개 묶어 더 큰 단위로도 graph를 구성할 수 있다. 위 그림은 sigmoid 함수의 예시이다.
$\sigma(x) = \cfrac{1}{1 + e^{-x}} \quad \Rightarrow \quad \cfrac{d\sigma}{dx} = \sigma(x)(1 - \sigma(x))$
위처럼 sigmoid 함수는 여러 연산자를 포함하고 있어 backpropagation이 여러 단계를 거치게 되고, 지수함수와 같이 연산량이 많은 node가 포함되어 있다. 하지만 도함수 자체는 단순 뺄셈과 곱셈으로 훨씬 간단하다. 이처럼 도함수가 간단한 함수의 경우에는 하나로 묶어 표현하는 것이 효율적이다.
Backprop with Vectors
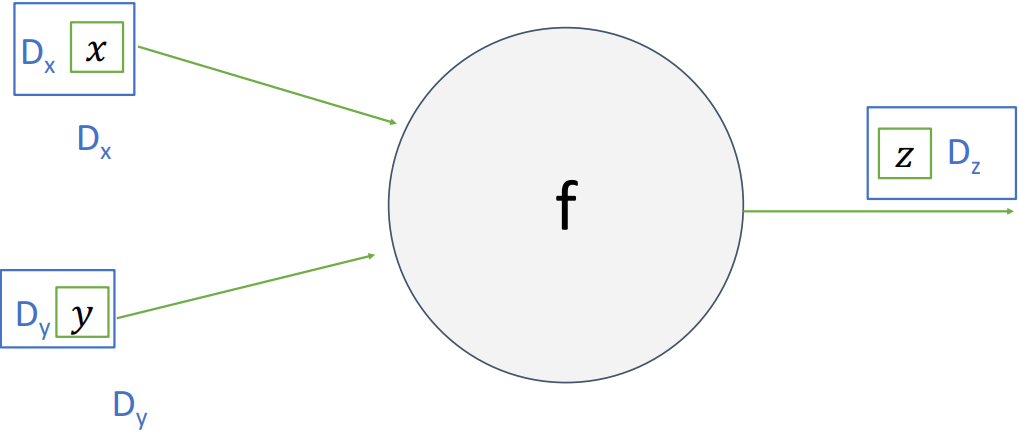
Node의 입출력이 scalar가 아닌 vector인 경우를 살펴보자. 입력 $\mathbf{x}$와 $\mathbf{y}$의 크기는 각각 $D_x$, $D_y$이고, 출력 $\mathbf{z}$의 크기는 $D_z$이다.
이때 Upstream Gradient $\frac{\partial L}{\partial \mathbf{z}}$가 주어진다고 가정해 보자. Loss $L$은 입력과 관계없이 scalar일 것이므로 $\frac{\partial L}{\partial \mathbf{z}}$는 $\mathbf{z}$와 같은 크기의 vector가 될 것이다.
Node 내부에서는 local gradient를 대신하여, input의 각 element $x_i$, $y_i$가 output의 각 element $z_i$에 어떻게 영향을 주는지 각각 계산해야 하는데, 이를 Jacobian matrix $\mathbf{J}$로 표현할 수 있다. 따라서 $\mathbf{x}$와 $\mathbf{z}$에 대한 Jacobian matrix는 $(D_x, D_z)$, $\mathbf{y}$와 $\mathbf{z}$에 대한 Jacobian matrix는 $(D_y, D_z)$의 크기를 갖는다. 이후 아래 수식과 같이 scalar의 경우와 동일하게 Chain rule을 적용하여 downstream gradient를 계산할 수 있다. 계산 순서에 유의하자.
$\cfrac{\partial L}{\partial \mathbf{x}} = \cfrac{\partial \mathbf{z}}{\partial \mathbf{x}} \cdot \cfrac{\partial L}{\partial \mathbf{z}}$
Jacobian Matrix is Expensive
Jacobian Matrix는 입력 변수의 개수가 많을수록 그 제곱으로 커지기 때문에 메모리 측면에서 효율적이지 않다. Neural Network에서, 대부분의 연산은 element-wise로 이루어진다. 따라서 Jacobian matrix에서 대각 성분을 제외한 나머지는 전부 0이 되며 대각 성분의 경우에도 위의 Patterns in Gradient Flow 파트와 같은 규칙이 있다. 아래의 ReLU 함수를 예로 들어보자.
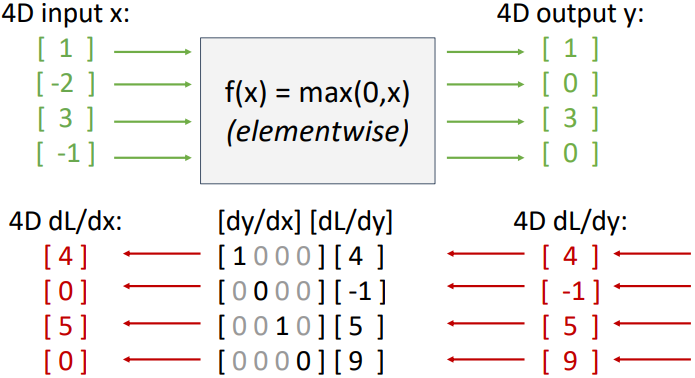
위 그림에서 ReLU 함수의 Jacobian matrix는 대각 성분이 0 또는 1이고, 나머지는 0이 된다. 대각 성분의 경우 해당하는 입력 변수가 0보다 크면 1, 작으면 0이 되는 것을 알 수 있다. 이처럼 Jacobian matrix를 계산하는 대신 각 element에 대해서 local gradient를 계산하는 것이 효율적이다.
$\left( \cfrac{\partial L}{\partial x} \right)_i = \begin{cases} \left( \cfrac{\partial L}{\partial y} \right)_i & , \text{if} \ x > 0 \\ 0 & , \ \text{otherwise} \end{cases}$
위처럼 직접 행렬 계산을 하는 것이 아닌 implicit한 방식을 이용하여 효율적으로 gradient를 계산할 수 있다.
Backprop with Matrices
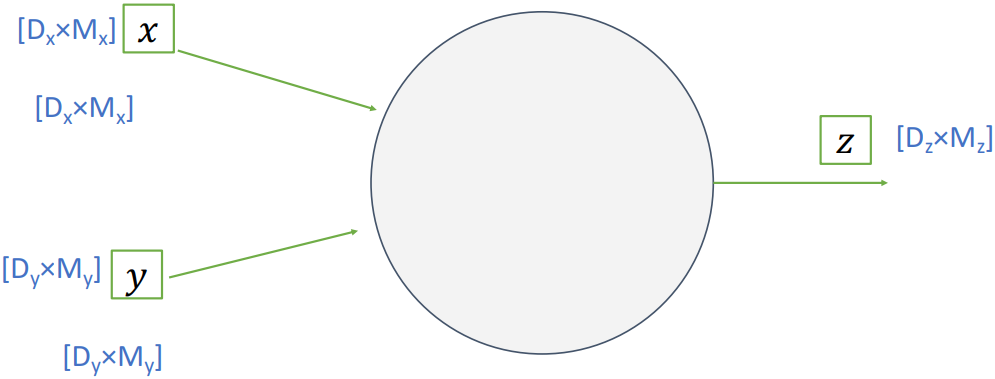
Node의 입출력이 matrix인 경우를 살펴보자. 입력 $\mathbf{x}$와 $\mathbf{y}$의 크기는 각각 $(D_x, M_x)$, $(D_y, M_y)$이고, 출력 $\mathbf{z}$의 크기는 $(D_z, M_z)$이다.
이때 Upstream Gradient $\frac{\partial L}{\partial \mathbf{z}}$가 주어지면 $\frac{\partial L}{\partial \mathbf{z}}$는 $\mathbf{z}$와 같은 크기의 행렬이 될 것이다.
행렬의 경우 2차원 형태 그대로 Jacobian을 구하려고 하면 4차원 텐서가 되기 때문에, 우선 입출력 행렬을 vector 형태로 flatten한 후에 Jacobian을 구하고 다시 reshape하는 방식을 사용한다. 즉, $\mathbf{x}$, $\mathbf{y}$, $\mathbf{z}$의 크기는 각각 $D_xM_x$, $D_yM_y$, $D_zM_z$이고, Jacobian matrix는 $(D_x M_x, D_zM_z)$, $(D_yM_y, D_zM_z)$의 크기를 갖는다.
이후 Backprop with Vectors 파트와 마찬가지 개념으로 Chain rule을 적용하여 downstream gradient를 계산할 수 있다.
Example: Matrix Multiplication
이때, vector 연산과 마찬가지로 matrix 연산에서도 Jacobian matrix 대신 local gradient를 효율적으로 계산할 수 있는 방법이 존재한다.
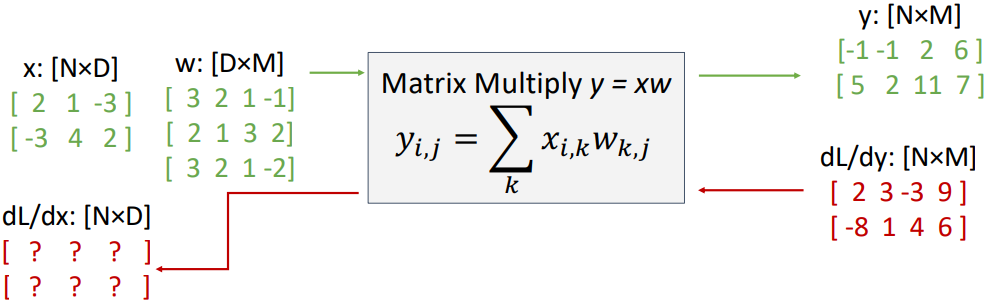
예를 들어, 위 그림의 경우처럼 2x3 행렬 $\mathbf{x}$와 3x4 행렬 $\mathbf{w}$의 곱을 계산하여 2x4 행렬 $\mathbf{y}$를 얻는 경우를 생각해 보자. 이때 $\frac{\partial L}{\partial \mathbf{y}}$도 주어져 있다.
가장 단순하게 위에서 설명한 것처럼 Jacobian matrix를 구할 수도 있지만, 먼저 $\frac{\partial L}{\partial \mathbf{x}}$의 각 element에 대한 local gradient를 계산해 보자.

위 그림에서 파란색으로 네모 표시된 부분인 $\frac{\partial L}{\partial \mathbf{x}_{1,1}}$을 계산해 보자. Chain rule을 이용하면
$\cfrac{\partial L}{\partial \mathbf{x}_{1,1}} = \cfrac{\partial \mathbf{y}}{\partial \mathbf{x}_{1,1}} \cdot \cfrac{\partial L}{\partial \mathbf{y}}$
가 된다. 즉 위 그림에서 Local Gradient Slice $\frac{\partial \mathbf{y}}{\partial \mathbf{x}_{1,1}}$를 구해야 한다.
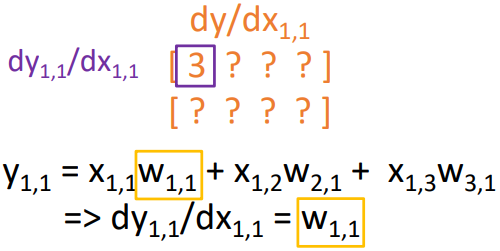
이 행렬도 각 element별로 계산해 보자. 우선 $\mathbf{y}_{1,1}$이 계산되는 과정을 보면
$\mathbf{y}_{1,1} = \mathbf{x}_{1,1} \cdot \mathbf{w}_{1,1} + \mathbf{x}_{1,2} \cdot \mathbf{w}_{2,1} + \mathbf{x}_{1,3} \cdot \mathbf{w}_{3,1}$
이므로
$\cfrac{\partial \mathbf{y}_{1,1}}{\partial \mathbf{x}_{1,1}} = \mathbf{w}_{1,1}$
가 된다. 나머지 element에 대해서도 계산을 수행해 보면 아래와 같다.

이처럼 첫 번째 row의 경우 $\mathbf{w}$의 첫 번째 row와 동일하고, 나머지 row의 경우 0이 된다는 것을 알 수 있다.
이제 앞에서 구한 Chain rule
$\cfrac{\partial L}{\partial \mathbf{x}_{1,1}} = \cfrac{\partial \mathbf{y}}{\partial \mathbf{x}_{1,1}} \cdot \cfrac{\partial L}{\partial \mathbf{y}}$
을 적용해 보자.
이때 $\frac{\partial \mathbf{y}}{\partial \mathbf{x}_{1,1}}$과 $\frac{\partial L}{\partial \mathbf{y}}$ 사이에서는 element-wise multiplication을 한 후 모두 더하게 되는데, 이는 앞 파트에서 설명한 copy 연산과 관련이 있다. $\mathbf{x}_{1,1}$이 $\mathbf{y}$의 첫 번째 row에는 전부 영향을 주기 때문에 모두 더하는 것이다.
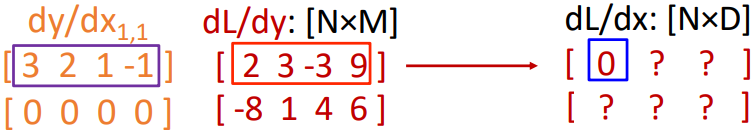
$3 \times 2 + 2 \times 3 + 1 \times (-3) + (-1) \times 9 = 0$
위와 같이 계산하여 $\frac{\partial L}{\partial \mathbf{x}_{1,1}}$을 구할 수 있다.
이 과정만 보면 Jacobian matrix를 구하는 것과 다른 것이 없어 보이지만, 위 과정의 결과를 보면 $\mathbf{w}$의 첫 번째 row와 $\frac{\partial L}{\partial \mathbf{y}}$의 첫 번째 row를 내적한 것이 된다. 이를 반복하여 $\frac{\partial L}{\partial \mathbf{x}}$를 채워 보면 아래와 같은 연산이 된다.
$\cfrac{\partial L}{\partial \mathbf{x}} = \cfrac{\partial L}{\partial \mathbf{y}} \cdot \mathbf{w}^T$
마찬가지로 $\frac{\partial L}{\partial \mathbf{w}}$는 아래와 같다.
$\cfrac{\partial L}{\partial \mathbf{w}} = \mathbf{x}^T \cdot \cfrac{\partial L}{\partial \mathbf{y}}$
즉, upstream gradient와 input variable의 곱으로 downstream gradient를 표현할 수 있는 것이다! 그리고 이 또한 위의 Patterns in Gradient Flow 파트에서 설명한 곱셈 node의 규칙을 따르는 것이다.
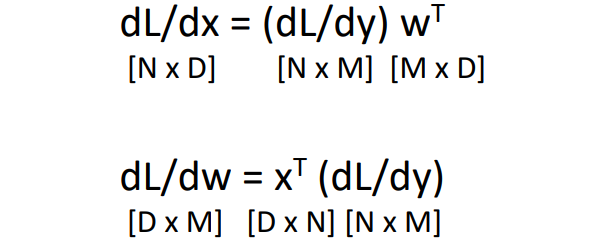
위 그림처럼 행렬 연산이 되도록 하기 위해 transpose를 취하고 곱셈 순서도 설정하였다.
이처럼 matrix 연산에서도 Jacobian matrix를 구하지 않고 local gradient를 계산하여 효율적으로 gradient를 계산할 수 있다.
Backprop Implementation
Neural Network의 노드를 class로 모듈화하여 backpropagation을 쉽게 구현할 수 있다.
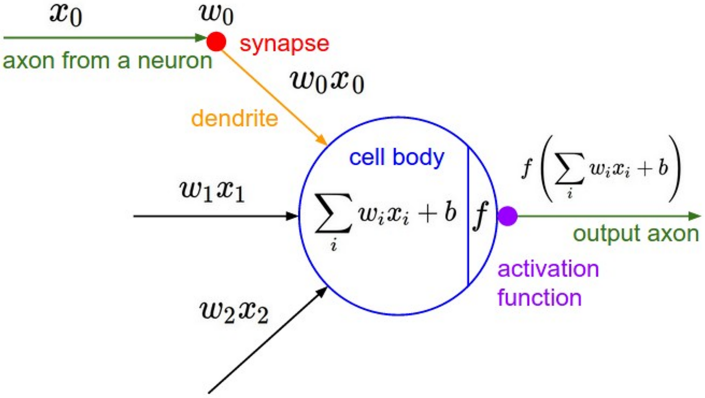
Neural Network의 노드를 시각화하면 위와 같이 입력을 받아 가중치 $\mathbf{W}$와 곱하고, activation function을 거쳐 출력값을 내보내는 구조이다. 이때 각 node 클래스 안에 forward와 backward 함수를 구현하여 입력값을 받아 출력값을 계산하거나 upstream gradient를 받아 downstream gradient를 계산할 수 있다. 이를 pseudo code로 나타내면 아래와 같다.
class ComputationalGraph(object):
def forward(inputs):
# 1. [pass inputs to input gates...]
# 2. forward the computational graph:
for gate in self.graph.nodes_topologically_sorted():
gate.forward()
return loss # the final gate in the graph outputs the loss
def backward():
for gate in reversed(self.graph.nodes_topologically_sorted()):
gate.backward() # little piece of backprop (chain rule applied)
return input_gradientsPyTorch 등 딥러닝 프레임워크에서도 마찬가지로 이러한 modular API 형식을 취하고 있다.
Summary
아무리 복잡한 Neural Network라도 Loss function을 각 파라미터로 편미분한 편도함수를 유도하는 것이 아닌, backpropagation을 통해 각 노드의 local gradient를 계산하여 효율적으로 gradient를 구할 수 있다. Scalar뿐만 아니라 vector, matrix에 대해서도 동일한 방식을 적용할 수 있다.
이제 임의의 node 개수와 layer 수를 가진 Neural Network를 구성하고, Activation function, Loss function, Regularization, Optimization을 이용해 네트워크를 훈련시킬 수 있다. 다음 강의에서는 이미지 처리에 핵심적인 Convolutional Neural Network와 Convolutional Layer에 대해 다룰 것이다.