Following the Slope
지난 강의에서는 Loss 함수를 통해 모델의 가중치 $\mathbf{W}$가 얼마나 좋고 나쁜지를 수치화하는 방법을 배웠다. 이번 강의에서는 $\mathbf{W}$를 어떻게 업데이트해야 Loss가 최소가 되는 $\mathbf{W}$를 찾을 수 있을지 알아본다.
Loss 함수는 입력이 $\mathbf{W}$의 원소 개수만큼 있다. 따라서 일반적인 다항함수처럼 미분하여 최소값을 찾는 것은 불가능하다. 따라서 대수적으로 Loss의 최소값을 구하는 것이 아니라 iterative하게 $\mathbf{W}$를 업데이트하면서 Loss를 줄여나가는 방법을 사용한다. 이러한 방법을 Gradient Descent라고 한다.
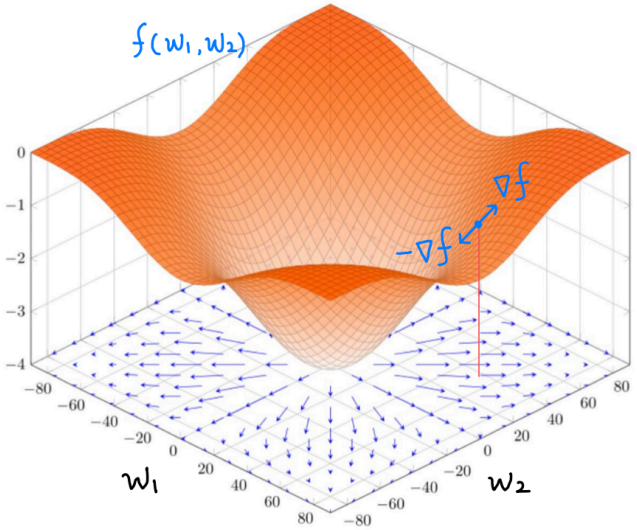
우선 위 그림과 같이 z축이 Loss, x축과 y축이 $\mathbf{W}$의 두 원소라고 하자. 이때 Loss가 최소가 되는 점을 찾으려면, 우선 임의의 점에서 시작한 뒤 Loss가 가장 급격히 감소하는 방향으로 조금씩 이동하면 된다. 눈을 감고 산을 내려가는 것과 비슷하다. 이때 Loss가 가장 급격히 감소하는 방향은 Loss 함수의 기울기에 음수를 취하면 된다.
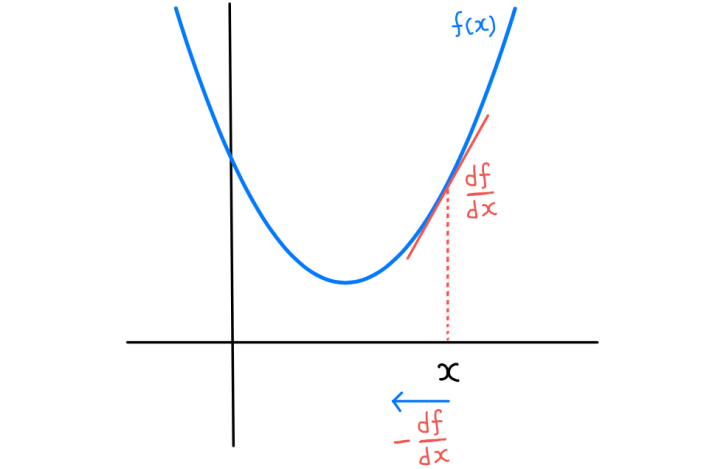
2차원에서 생각하면 편한데, 위 그림처럼 특정 점에서 함수의 기울기가 양수라면 점을 $-x$ 방향으로 움직여야 함수값이 감소한다. 즉, 기울기 값에 부호를 바꾸어 현재 점의 좌표에 더하면 이는 함수값이 감소하는 방향이 된다. 또한 기울기가 완만해질수록 움직이는 거리도 자연스럽게 줄어든다.
$\mathbf{W}$가 특정 값을 가질 때의 Gradient를 구하는 방법을 Backpropagation이라고 한다. 이에 대한 구체적인 방법은 Lecture 6에서 살펴보고, 지금은 특정 $\mathbf{W}$에 대한 Gradient를 이미 구했을 때 어떻게 $\mathbf{W}$를 업데이트할지 먼저 살펴보자.
Gradient Descent
Gradient Descent라는 말은 Loss function의 gradient에 기반하여 $\mathbf{W}$를 업데이트하는 방법을 의미한다. 가장 기본적인 방법은 Gradient 값 그대로 더하는 것이다. 이때 너무 급격하거나 느린 업데이트를 방지하기 위해 Gradient에 단순히 상수배만을 취하게 된다.
$\mathbf{W}^{(t+1)} = \mathbf{W^{(t)}} - \eta \frac{\partial L^{(t)}}{\partial \mathbf{W}^{(t)}}$
이를 코드로 구현하면 아래와 같다.
# Vanilla Gradient Descent
w = initialize_weights()
for t in range(num_steps):
dw = compute_gradient(loss_fn, data, w)
w = w - learning_rate * dw이때 개발자가 정해 주어야 하는 부분은 다음의 3가지이다.
- initialize_weights(): $\mathbf{W}$를 초기화하는 함수
- num_steps: $\mathbf{W}$ 업데이트 횟수
- learning_rate: Gradient에 곱해지는 상수
각각에 대해 간단히 언급하면, 우선 $\mathbf{W}$를 어떻게 초기화하느냐에 따라 최종 결과가 달라질 수 있다. 특히 각 레이어의 뉴런 수가 많을수록 초기화가 중요하다. 만약 $\mathbf{W}$를 모두 0으로 초기화하면 Gradient Descent가 제대로 작동하지 않을 수 있다. 또한 $\mathbf{W}$를 전부 같은 분포의 랜덤 값으로 초기화하는 방법에도 문제가 있다. 한 레이어가 다른 레이어보다 많은 수의 뉴런을 갖고 있을 경우, 단순히 원소의 개수가 많기 때문에 출력 $\mathbf{W} \mathbf{x}$ 의 값이 다른 레이어보다 커질 수 있다. 이를 해결하기 위해 Xavier Initialization이나 He Initialization과 같은 방법을 사용하는데, Xavier Initialization은 sigmoid나 tanh와 같은 activation function을 사용할 때, He Initialization은 ReLU와 같은 activation function을 사용할 때 좋은 결과를 보인다.
num_steps는 $\mathbf{W}$를 업데이트하는 횟수로, 보통 개발자가 숫자로 정해 주게 된다.
learning_rate $\eta$는 Gradient에 곱해지는 상수이다. 이 값이 너무 크면 Loss가 발산하고, 너무 작으면 Loss가 수렴하는데 너무 오래 걸릴 수 있다. 따라서 적절한 learning rate를 테스트를 통해 찾아야 한다.
Gradient Descent를 시각화하면 다음과 같다.
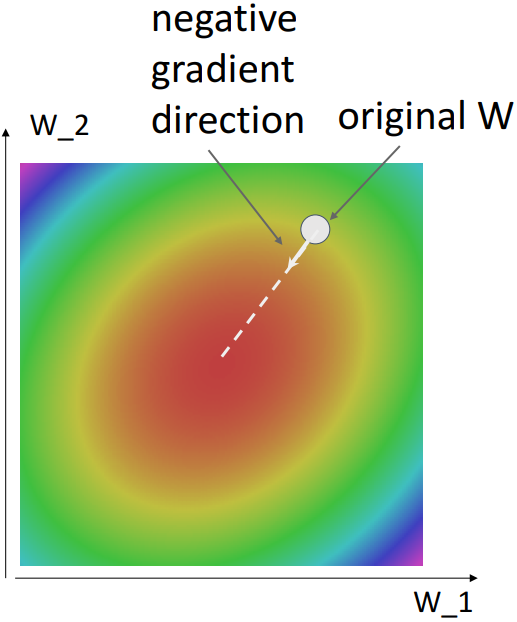
Stochastic Gradient Descent (SGD)
아래의 Loss 함수의 식을 보면, 모든 training 데이터셋에 대해 각 Loss 성분을 계산하고 모두 더하는 과정이 있다.
$L(\mathbf{W}) = \frac{1}{N} \sum_{i=1}^{N} L_i(f(\mathbf{x}_i, \mathbf{W}), y_i) + \lambda R(\mathbf{W})$
하지만 수백만 개의 데이터셋 전체에 대해 Loss를 계산하고 $\mathbf{W}$를 단 한 번 업데이트하는 것은 매우 비효율적이다. 따라서 데이터셋을 subsampling하여 여러 개의 mini-batch로 나누어 각 mini-batch에 대해 Loss를 계산하고 $\mathbf{W}$를 업데이트하는 방법을 사용한다. 이를 Stochastic Gradient Descent(SGD) 또는 Mini-batch Gradient Descent라고 한다. 이를 통해 계산량을 줄이고, 더 빠르게 수렴할 수 있다.
이를 코드로 구현하면 아래와 같다.
# Stochastic Gradient Descent
w = initialize_weights()
for t in range(num_steps):
minibatch = sample_data(data, batch_size)
dw = compute_gradient(loss_fn, minibatch, w)
w = w - learning_rate * dw이때 hyperparameter로 batch_size와 sampling 방식이 있다.
먼저 보편적인 mini-batch의 크기는 32, 64, 128 등으로, 효율적인 메모리 사용을 위해 2의 배수로 설정한다. 이때 mini-batch의 크기가 클수록 업데이트가 안정적이지만 계산량이 많아진다. Batch size는 모델의 성능에 그렇게까지 큰 영향을 미치지 않기 때문에, 컴퓨팅 파워가 받쳐 주는 한에서 가장 크게 하면 된다.
Sampling 방식의 경우, classification 문제에서는 랜덤하게 섞기만 하면 큰 문제가 없다고 한다. 중복이나 누락을 막기 위해 처음에 무작위로 섞은 뒤 batch들을 미리 만들어 놓고, 이를 순차적으로 사용한다.
여기에 Stochastic이라는 이름이 붙은 이유는, Loss 함수를 보면 최종 Loss는 이미지 각각에 대한 Loss의 평균이다. Mini-batch Gradient Descent의 경우 전체 이미지에서 랜덤하게 표본을 추출하여 표본평균을 구하고 이를 통해 모평균을 추정하는 과정이라고 볼 수 있기 때문에 확률적이라는 뜻의 Stochastic이라는 이름이 붙었다.
아래 링크를 통해 Linear classifier에서 input과 weight, hyperparameter를 바꾸어 가며 Gradient Descent가 어떻게 작동하는지 확인할 수 있다.
http://vision.stanford.edu/teaching/cs231n-demos/linear-classify/
Problems with SGD
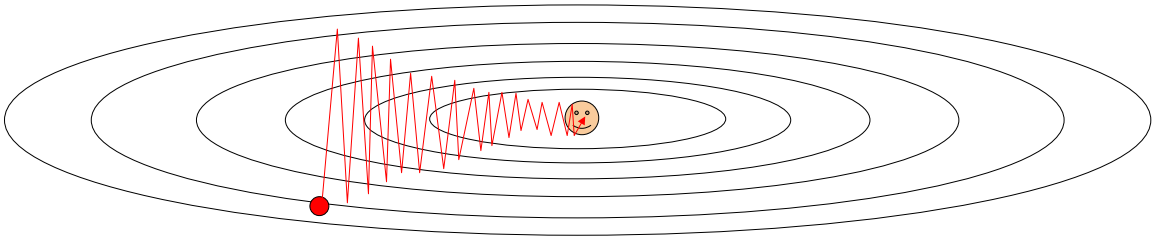
하지만 SGD에도 단점이 존재한다. 위 그림처럼 Loss 함수가 한 축으로는 빠르게 변화하고 한 축으로는 천천히 변화할 때, 단순 SGD를 사용한다면 지그재그 모양으로 움직이게 되어 수렴하는데 훨씬 많은 반복이 필요할 수도 있다.
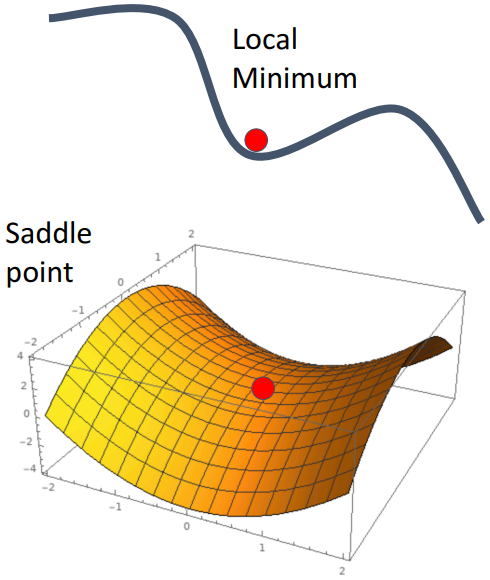
또한, gradient가 0인 지점만을 향해 가기 때문에 위 그림처럼 local minima 또는 saddle point에 빠지기 쉽다.

마지막으로, SGD는 모든 데이터셋에 대해 Loss를 계산하고 업데이트하는 것이 아니기 때문에 위 그림처럼 수렴 과정에서 noise가 많이 발생할 수 있고, 이로 인해 수렴이 느려질 수 있다.
Advanced Optimization Methods
Momentum
위와 같은 문제점을 해결하기 위해 SGD에 Momentum이라는 방법을 추가할 수 있다. Momentum은 공이 곡면을 따라 굴러 내려가는 것에서 intuition을 얻은 방식으로, 현재 Gradient 값에 이전 Gradient 값을 더하여 무작위성을 줄이고 일관성 있게 업데이트를 진행할 수 있다. 이는 공이 속도를 가지고 이동하는 중에 곡면으로 인해 방향이 부드럽게 변하는 것과 비슷하다.
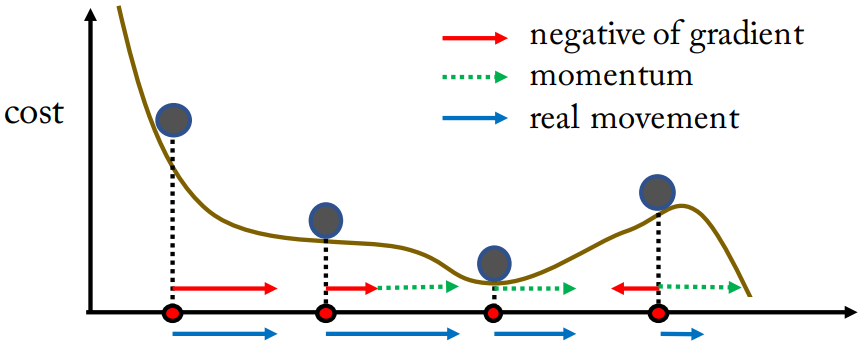
이를 통해 위 사진과 같이 local minima가 있더라도 빠져나올 수 있다.
이를 수식으로 나타내면 아래와 같다. $\rho$는 momentum의 강도를 나타내는 hyperparameter로 지난 momentum을 얼마나 잊을 것인지 결정한다. 보통 0.9 정도로 설정한다.
$\mathbf{v}^{(t+1)} = \rho \mathbf{v}^{(t)} - \eta \frac{\partial L^{(t)}}{\partial \mathbf{W}^{(t)}}$
$\mathbf{W}^{(t+1)} = \mathbf{W}^{(t)} + \mathbf{v}^{(t+1)}$
이를 코드로 구현하면 아래와 같다.
# Momentum
v = 0
for t in range(num_steps):
dw = compute_gradient(w)
v = rho * v - learning_rate * dw
w += v
위 그림을 통해 Momentum을 사용한 경우 SGD보다 더 빠르게 수렴하는 것을 확인할 수 있다.
Nesterov Momentum
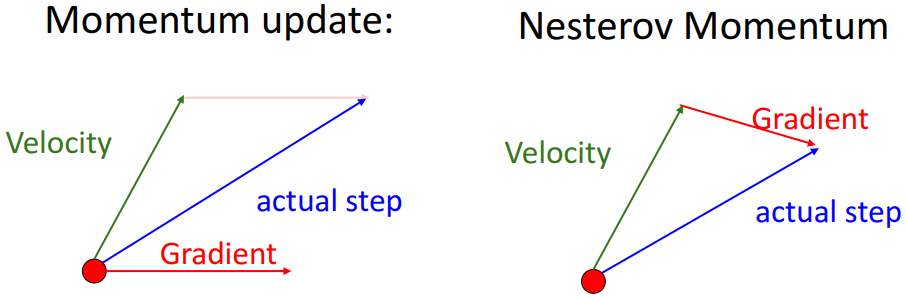
또한, Nesterov Momentum이라는 방법을 사용하면 Momentum을 더 개선할 수 있다. 기존 Momentum은 현재 위치에서의 gradient와 momentum 벡터를 더했다면, Nesterov Momentum은 Momentum 벡터대로만 갔을 때의 도착 지점을 가정해서 거기서의 gradient를 더한다.
이를 수식으로 나타내면 아래와 같다.
$\mathbf{v}^{(t+1)} = \rho \mathbf{v}^{(t)} - \eta \nabla L(\mathbf{W}^{(t)} + \rho \mathbf{v}^{(t)})$
$\mathbf{W}^{(t+1)} = \mathbf{W}^{(t)} + \mathbf{v}^{(t+1)}$
이를 코드로 구현하면 아래와 같다. 이때 아래 코드는 수식을 약간 변형한 버전으로, 변환 과정은 강의안에서 확인할 수 있다.
# Nesterov Momentum
v = 0
for t in range(num_steps):
dw = compute_gradient(w)
old_v = v
v = rho * v - learning_rate * dw
w -= rho * old_v - (1 + rho) * v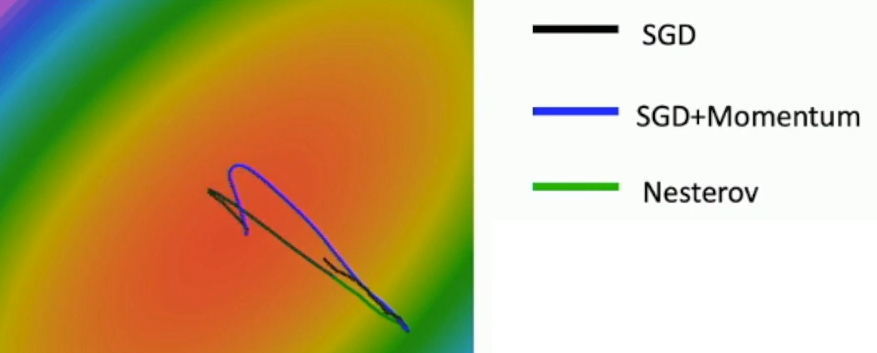
그 결과, 위 그림처럼 Nesterov Momentum을 사용한 경우 Momentum보다 더 빠르게 중심을 향해 수렴하는 것을 확인할 수 있다. 이때 둘 모두 최소값 근처에서 momentum 벡터로 인해 overshoot이 발생한다.
Adagrad
또 다른 카테고리의 optimization method로는 adaptive learning rate를 사용하는 방법이 있다. 이는 각각의 parameter 원소들에 대해 learning rate를 다르게 적용하는 방법이다.
이를 수식으로 나타내면 아래와 같다. $\odot$는 element-wise 곱셈을 의미하고, $\epsilon$은 0으로 나누는 것을 방지하기 위한 10e-8 정도의 작은 상수이다.
$\mathbf{G}^{(t)} = \mathbf{G}^{(t-1)} + \nabla L^{(t)} \odot \nabla L^{(t)}$
$\mathbf{W}^{(t+1)} = \mathbf{W}^{(t)} - \frac{\eta}{\sqrt{\mathbf{G}^{(t)} + \epsilon}} \odot \nabla
L^{(t)}$
즉, 먼저 각 원소에 대해 gradient의 제곱을 누적하여 $\mathbf{G}$를 구하게 된다. 이는 각 원소가 지금까지 증가든 감소든 얼마나 많이 update되었는지를 나타내는 벡터가 된다. 이후 각 원소에 대해 learning rate를 $\mathbf{G}$에 루트를 씌운 값으로 나눈다. 결과적으로 지금까지 많이 update된 원소는 learning rate가 작아지게 되고, 적게 update된 원소는 learning rate가 커지게 된다. 이를 통해 특정 feature가 드물게 나타날 때 또는 gradient가 작은 weight 원소에 대해서도 학습을 용이하게 할 수 있다.
이를 코드로 구현하면 아래와 같다.
# Adagrad
G = 0
for t in range(num_steps):
dw = compute_gradient(w)
G += dw * dw
w -= learning_rate * dw / (G.sqrt() + epsilon)RMSProp
그러나, Adagrad는 $\mathbf{G}$를 누적하기만 하기 때문에 학습이 진행될수록 learning rate가 너무 작아져서 학습이 느려지는 문제가 있다. 이를 해결하기 위해, RMSProp에서는 $\mathbf{G}$를 누적하는 대신 현재의 gradient 제곱과 가중평균을 취한다. 이를 통해 $\mathbf{G}$가 무한히 커지지 않게 된다.
$\mathbf{G}$를 계산하는 수식에만 변화가 있다. $\gamma$는 decay rate로, 보통 0.9 정도로 설정한다. 이는 $\mathbf{G}$가 얼마나 빨리 decay할지를 결정한다.
$\mathbf{G}^{(t)} = \gamma \mathbf{G}^{(t-1)} + (1 - \gamma) \nabla L^{(t)} \odot \nabla L^{(t)}$
$\mathbf{W}^{(t+1)} = \mathbf{W}^{(t)} - \frac{\eta}{\sqrt{\mathbf{G}^{(t)} + \epsilon}} \odot \nabla
L^{(t)}$
이를 코드로 구현하면 아래와 같다.
# RMSProp
G = 0
for t in range(num_steps):
dw = compute_gradient(w)
G = gamma * G + (1 - gamma) * dw * dw
w -= learning_rate * dw / (G.sqrt() + epsilon)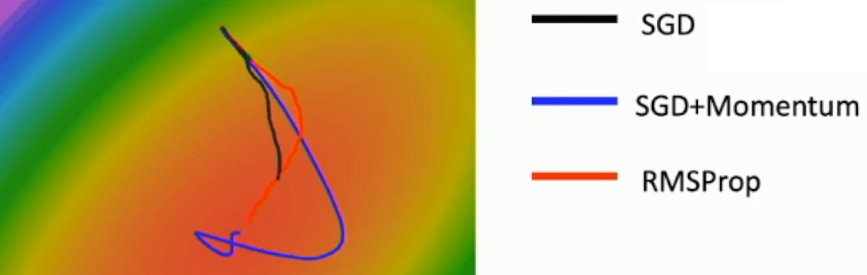
위 그림을 통해 SGD, SGD+Momentum, RMSProp을 비교하였다. Momentum을 적용한 버전은 이전과 유사하게 overshooting이 발생한 뒤 수렴하는 모습을 보인다. RMSProp은 빠르게 변화하는 방향으로의 업데이트를 억제하고 느리게 변화하는 방향으로의 업데이트를 촉진하여 어느 순간 중심을 향해 꺾은 후 빠르게 수렴하는 것을 확인할 수 있다.
Adam
이제 우리는 Momentum을 적용하여 부드러운 곡선으로 빠르게 수렴하는 방법과, Adaptive learning rate를 적용하여 각 원소에 대해 다른 learning rate를 적용하는 방법을 배웠다. 이 둘을 합친 것이 Adam이다.
이를 수식으로 나타내면 아래와 같다. $\beta_1$과 $\beta_2$는 각각 Momentum과 RMSProp의 decay rate로, 보통 0.9와 0.999로 설정한다. $\epsilon$은 0으로 나누는 것을 방지하기 위한 작은 상수이다.
$\hat{\mathbf{m}}^{(t+1)} = \frac{\mathbf{m}^{(t+1)}}{1 - \beta_1^{t+1}} \quad \text{where} \quad
\mathbf{m}^{(t+1)} = \beta_1 \mathbf{m}^{(t)} + (1 - \beta_1) \nabla L^{(t)}$
$\hat{\mathbf{G}}^{(t+1)} = \frac{\mathbf{G}^{(t+1)}}{1 - \beta_2^{t+1}} \quad \text{where} \quad
\mathbf{G}^{(t+1)} = \beta_2 \mathbf{G}^{(t)} + (1 - \beta_2) \nabla L^{(t)} \odot \nabla L^{(t)}$
$\mathbf{W}^{(t+1)} = \mathbf{W}^{(t)} - \frac{\eta}{\sqrt{\hat{\mathbf{G}}^{(t)} + \epsilon}} \odot
\hat{\mathbf{m}}^{(t)}$
이를 코드로 구현하면 아래와 같다.
# Adam
m = 0
G = 0
for t in range(num_steps):
dw = compute_gradient(w)
m = beta1 * m + (1 - beta1) * dw
G = beta2 * G + (1 - beta2) * dw * dw
m_hat = m / (1 - beta1 ** (t + 1))
G_hat = G / (1 - beta2 ** (t + 1))
w -= learning_rate * m_hat / (G_hat.sqrt() + epsilon)결국 momentum과 adaptive learning rate가 대칭적인 형태를 띠고 있음을 알 수 있다. 또한 $\mathbf{m}$과 $\mathbf{G}$ 대신 $\hat{\mathbf{m}}$과 $\hat{\mathbf{G}}$를 사용하는데, 이는 초기 학습 단계에서 $\mathbf{m}$과 $\mathbf{G}$가 0에 가까운 값으로 초기화되어 있을 때 이를 보정하기 위함이다.
Adam optimizer는 실제로 가장 잘 작동하고 현재 가장 많이 사용되는 optimizer 중 하나이다. 튜닝해야 하는 hyperparameter의 개수도 적다. 특히, $\beta_1 = 0.9$, $\beta_2 = 0.999$, $\epsilon = 10^{-8}$, learning rate는 0.001, 0.0005, 0.0001 셋 중 하나로 설정하면 대부분의 경우 잘 작동한다. 새로운 딥러닝 모델을 구축한다면 이 값들로부터 시작하는 것이 좋다.
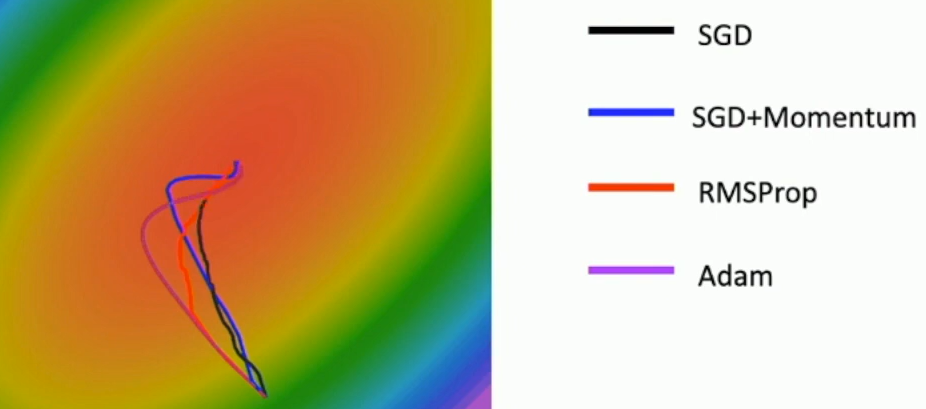
Adam이 overshooting은 momentum보다 적으며 RMSProp과 마찬가지로 중심 방향으로 꺾어 수렴하는 것을 확인할 수 있다.
Second Order Optimization Methods
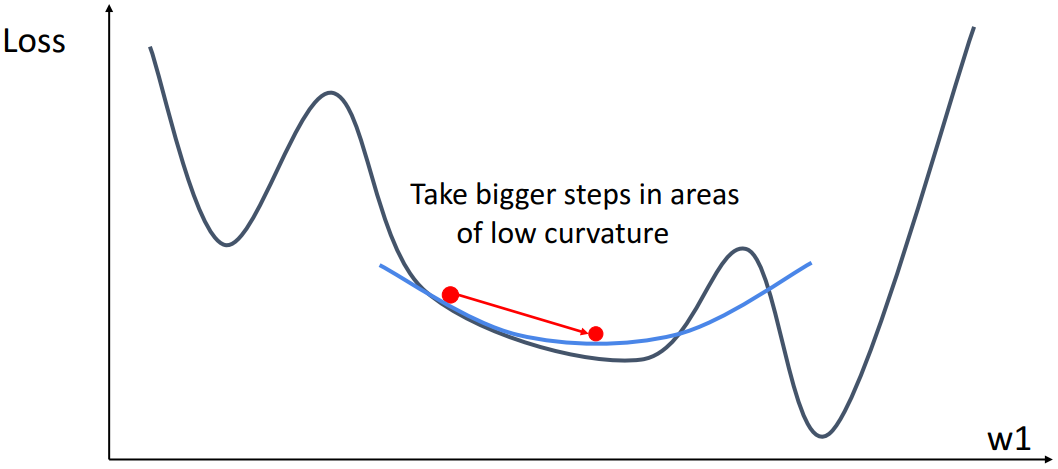
위에서 살펴본 모든 optimization method는 first order optimization method로, gradient만을 이용하여 최적화를 수행한다. 하지만, second order optimization method는 Hessian matrix를 이용하여 더욱 구체적인 최적화를 수행할 수 있다. 하지만 Hessian matrix를 계산하는 것은 $O(N^2)$, 계산 과정에서 Hessian matrix의 역행렬을 구하는 것은 $O(N^3)$이기 때문에 수백만 개의 input dimension을 가지는 딥러닝에서는 실제로 잘 사용되지 않는다. 데이터셋의 크기가 작고 full batch gradient descent를 사용할 수 있을 때에만 선택지로 고려하는 것이 좋다.
Summary
Lecture 4에서는 optimization method에 대해 배웠다. Adam은 가장 많이 사용되는 optimizer 중 하나이며, hyperparameter 튜닝도 많이 필요하지 않으므로 새로운 딥러닝 모델을 구축할 때에는 Adam을 사용하자.
지금까지의 흐름은 다음과 같다.
- Linear classifier를 이용해 분류를 수행한다.
- Loss function을 이용하여 주어진 weight가 얼마나 좋고 나쁜지 수치화한다.
- Optimizer를 이용하여 Loss를 최소화하는 weight를 찾는다.
다음 강의에서는 Linear Classifier를 대체할 Neural Network에 대해 배울 것이다.