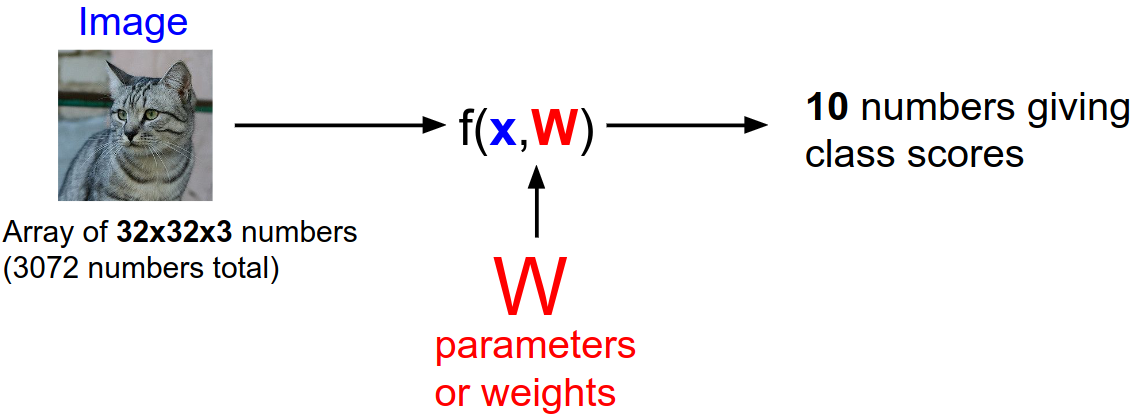
Linear Classifier
kNN에서는 단순히 이미지 자체를 비교해서 분류를 수행하였다. 즉, 데이터셋 자체가 분류 모델이었다. 하지만 앞으로 살펴볼 'parametric model'에서는 데이터셋에 대한 정보를 함축하여, 데이터셋 전체를 기억하지 않고도 분류를 더욱 효율적으로 수행할 수 있다.
$\mathbf{y} = f(\mathbf{x}, \mathbf{W})$
위 수식에서 $\mathbf{x}$는 입력된 픽셀값, $\mathbf{W}$는 데이터셋에 대한 정보가 함축된 'weight' 행렬, $f$는 $\mathbf{x}$와 $\mathbf{W}$를 이용하여 입력 이미지가 각 클래스에 속할 가능성을 클래스별 점수로 출력하는 함수이다. 이 점수를 통해 가장 높은 점수를 가진 클래스를 선택할 수 있고, 우리는 데이터셋 전체를 기억할 필요 없이 올바른 $\mathbf{W}$만을 갖고 있으면 쉽고 빠르게 분류를 수행할 수 있다.
올바른 $\mathbf{W}$를 찾는 법은 아래쪽에서 살펴보기로 하고, 우선 $\mathbf{W}$가 있을 때 $\mathbf{x}$와 $\mathbf{W}$를 어떻게 연산해야 할지 살펴보자. 가장 간단한 방법은 아래와 같이 단순히 픽셀값과 그에 해당하는 가중치를 곱한 후 모두 더하는 것이다. 사칙연산만으로 이루어져 있기 때문에 linear classifier라는 명칭이 붙었다. 이처럼 단순한 linear classifier는 대부분의 딥러닝 모델의 가장 기본적인 building block이 된다.
$f(\mathbf{x}, \mathbf{W}) = \mathbf{W} \cdot \mathbf{x} + \mathbf{b}$
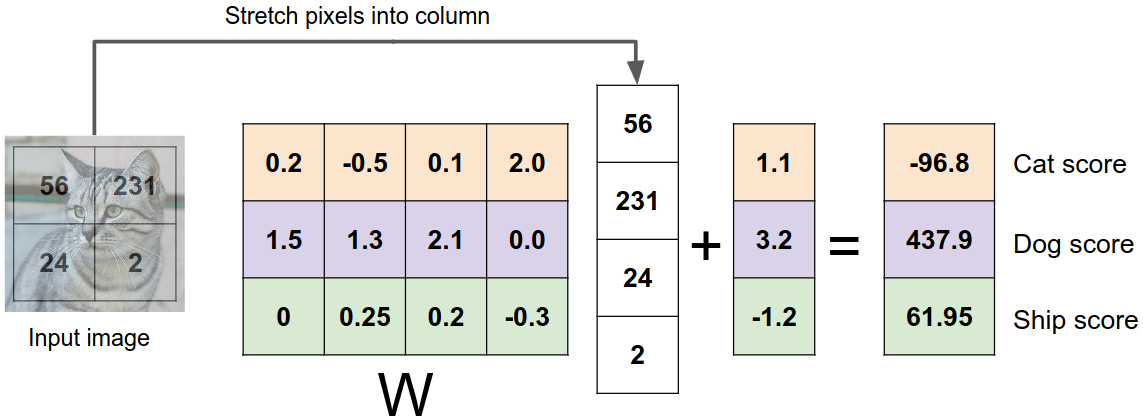
위 그림은 2x2 크기의 이미지를 3개의 클래스 중 하나로 분류하는 과정을 나타낸 것이다. 먼저 2x2 픽셀인 이미지를 4x1의 1차원 벡터 $\mathbf{x}$로 펼친다. 이후 3x4의 weight matrix $\mathbf{W}$와 입력 벡터 $\mathbf{x}$를 곱한 후 3x1의 bias 벡터 $\mathbf{b}$를 더하여 3x1의 점수 벡터를 만든다. 이 점수 벡터의 각 원소는 입력 이미지가 해당 클래스에 속할 가능성을 나타낸다.
이때, linear classification을 template matching으로 이해할 수 있다!
무슨 말인가 하면, $\mathbf{W}$의 각 row는 입력 이미지와 곱해져 하나의 클래스에 대한 점수를 만들어낸다. 첫 번째 row는 cat, 두 번째 row는 dog, 세 번째 row는 ship에 대한 점수를 만들어내는 식이다. 그렇다면 각 row가 어떨 때 점수가 가장 높을까?
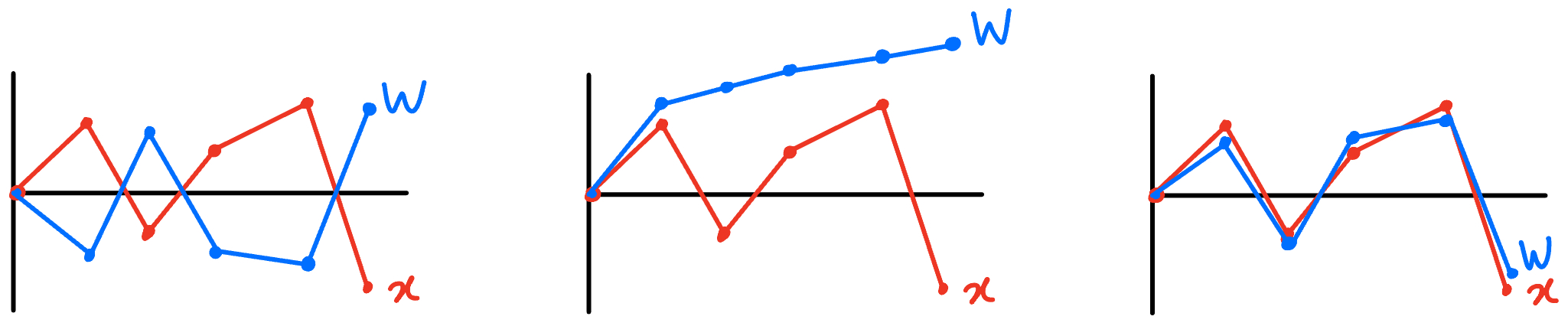
우선 첫 번째 경우를 보면, $\mathbf{W}$의 한 row와 $\mathbf{x}$의 부호가 항상 반대이기 때문에 곱은 항상 음수가 나온다. 따라서 쌍을 이루는 원소들의 부호가 같아야 점수가 높아짐을 알 수 있다. 두 번째 경우를 보면, $\mathbf{W}$와 $\mathbf{x}$의 그래프 형태가 유사하지 않다. 이 경우에는 예를 들어 $\mathbf{x}$의 마지막 원소가 양수가 된다면 점수가 더 높아질 수 있다. 즉, 고양이에 해당하는 row는 고양이 사진이 들어왔을 때만 높은 점수를 출력하고 다른 사진이 들어오면 낮은 점수를 출력해야 하는데 다른 클래스에 더 높은 점수를 줄 수도 있는 것이다. 세 번째 경우를 보면, $\mathbf{W}$와 $\mathbf{x}$의 형태가 거의 일치한다. 이 경우 고양이 사진에만 높은 점수를 출력하는 이상적인 $\mathbf{W}$가 된다.
우리는 수많은 training 데이터셋으로 학습하므로, 결과적으로 $\mathbf{W}$의 각 row는 각 클래스에 해당하는 이미지들을 한데 모아놓은 것 같은 형태가 된다. 실제로 CIFAR-10 데이터셋으로 학습시킨 $\mathbf{W}$의 각 row를 이미지로 변환해보면 아래 그림과 같다.

car 클래스의 경우 자동차의 정면 형상이 보이며 deer 클래스의 경우 연두색 배경에 갈색 물체가 있는 등 각 클래스에 해당하는 물체를 뭉뚱그려 놓은 듯한 형체가 보인다. 이때 중요한 것은 horse 클래스의 경우 말의 머리가 양쪽에 달려 있는 것처럼 보이는데, 실제로 말의 머리가 양쪽에 달려 있는 이미지는 없다. 즉, linear classifier의 경우 한 클래스당 하나의 템플릿밖에 가지지 못하기 때문에 그 물체가 보여질 수 있는 모든 경우를 뭉뚱그려 놓은 형태의 템플릿이 된다.
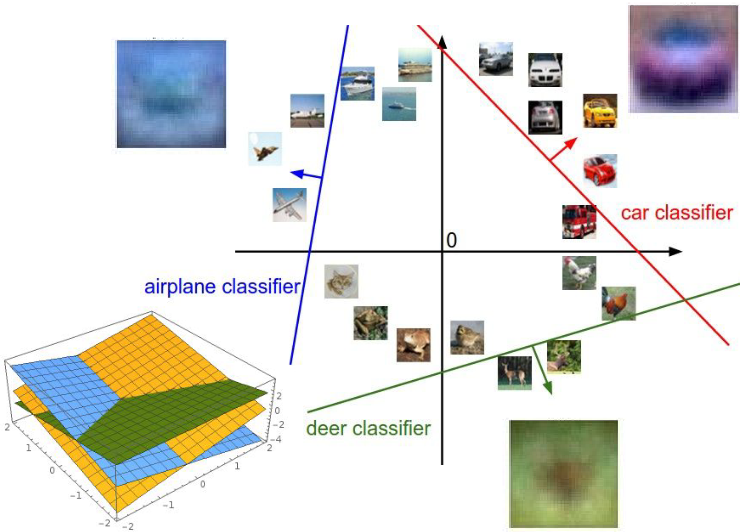
Linear classifier에 대한 또 다른 해석으로는 decision boundary가 있다. 대부분의 인공지능 교재에 많이 보이는 그림인데, 이미지들을 고차원 평면상에 놓고 그 사이에 구분선을 그어 한 클래스와 다른 클래스들을 구분하는 것이다. 즉, $f(\mathbf{x}, \mathbf{W})$의 결과가 특정 값보다 크면 그 클래스에 포함, 아니면 포함하지 않는 것으로 보는 것이다. 이러한 해석을 통해 linear classification의 한계점을 파악할 수 있다.
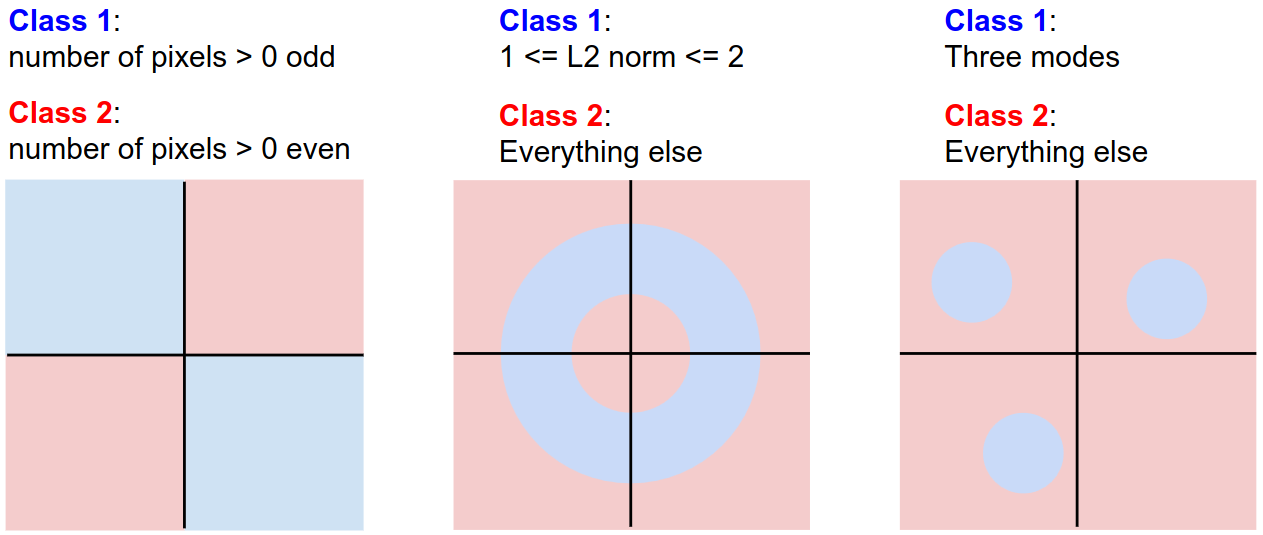
위 그림을 보면, 두 클래스의 하나의 직선으로 완전히 구분하는 것이 불가능하다. 왼쪽 경우처럼 픽셀의 수뿐만 아니라 이미지 내 사람의 수를 홀수와 짝수로 분류하는 문제 등은 linear classifier로 해결하기 어렵다. 오른쪽 경우처럼 한 클래스가 여러 곳에 퍼져 있는 경우도 있을 수 있는데, 위 horse 클래스에서 말이 왼쪽 또는 오른쪽 둘 중 하나만 보고 있는 경우가 이에 해당된다. 이 또한 두 경우를 한꺼번에 다른 클래스와 구분짓는 것은 어렵다. 결국 이 문제는 linear classifier를 다층으로 쌓아서 해결할 수 있는데, 이는 추후 강의에서 살펴볼 예정이다.
Loss Function - Multiclass SVM Loss

지금까지 linear classifier가 어떻게 작동하는지, $\mathbf{W}$는 어떤 의미를 가지고 있는지 살펴보았다. 그렇다면 최적의 $\mathbf{W}$를 어떻게 찾을 수 있을까? 이를 위해서는 먼저 $\mathbf{W}$가 얼마나 좋고 나쁜지를 수치화해야 한다. 이를 loss function이라고 한다. 이미지 한 개에 대한 loss function은 아래와 같이 정의할 수 있다.
$L_i(f(\mathbf{x}_i, \mathbf{W}), y_i)$
즉, 특정 입력값에 대한 예측값과 정답을 비교하여 얼마나 잘못 예측했는지를 수치화한 것이다. 이를 모든 데이터셋에 대해 적용한 전체 loss function은 아래와 같이 정의할 수 있다.
$L(\mathbf{W}) = \frac{1}{N} \sum_{i=1}^{N} L_i(f(\mathbf{x}_i, \mathbf{W}), y_i)$
Multiclass SVM Loss의 개념은, 단순하게 정답인 클래스의 점수가 다른 모든 클래스의 점수보다도 어느 정도 높아야 한다는 것이다. 이를 수식으로 나타내면 아래와 같다.
$L_i = \sum_{j \neq y_i} \max(0, s_j - s_{y_i} + 1)$
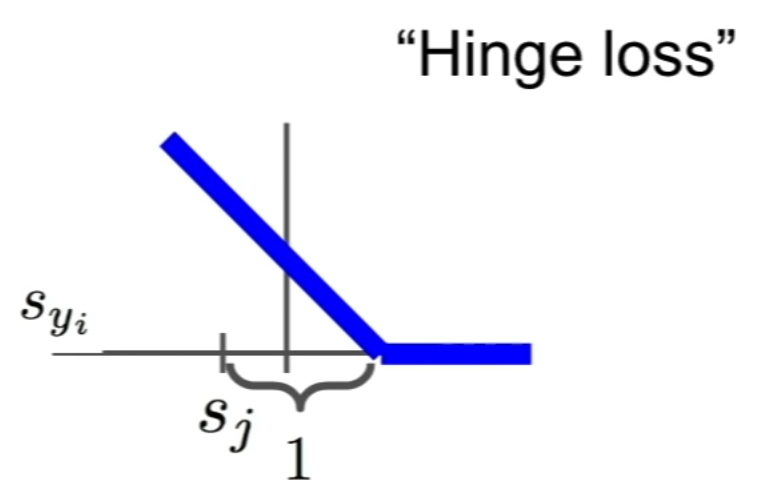
정답 클래스의 점수가 다른 한 클래스의 점수보다 1 이상 높다면 loss는 0이 된다. 반면 정답 클래스의 점수가 다른 클래스의 점수 + 1보다 낮다면, 그 둘의 차이가 그 클래스에 대한 loss 성분이 된다. 이를 정답 클래스를 제외한 모든 클래스에 대해 수행하고 모두 더하면 해당 이미지에 대한 loss가 된다.

예를 들어, 위 그림과 같이 3개의 인풋 이미지와 3개의 클래스가 있을 때 고양이 이미지에 대한 SVM loss를 계산해 보자.
$L_i = \sum_{j \neq y_i} \max(0, s_j - s_{y_i} + 1) = \max(0, 5.1 - 3.2 + 1) + \max(0, -1.7 - 3.2 + 1) = 2.9$
Q1: 자동차 이미지에 대한 점수들을 아주 약간씩 조절하면 loss에는 어떤 변화가 생길까?
A1: 정답 클래스의 점수가 다른 클래스의 점수보다 1 이상 높기 때문에 loss에는 변화가 없다. 이는 SVM loss의 경우 정답 클래스를 맞추기만 하면 점수 자체에는 큰 의미가 없다는 것을 뜻한다.
Q2: 가능한 loss의 최댓값과 최솟값은?
A2: 최댓값은 무한대이고, 최솟값은 정답 클래스의 점수가 다른 클래스의 점수보다 1 이상 높을 때 0이다.
Q3: Training 초기, 모든 점수가 작은 random 값으로 initialization되었을 때 loss는?
A3: 모든 클래스의 점수 차가 0에 가까울 것이기 때문에 모든 loss 성분이 1이 된다. 따라서 총 loss는 C - 1이다.
Q4: 정답 클래스까지 포함하여 합하면 어떻게 될까?
A4: 정답 클래스의 loss 성분은 항상 1이므로, 총 loss는 1만큼 커진다. 모든 인풋 이미지에 대해 이 현상이 발생하므로 classifier의 동작에는 변화가 없다.
Q5: loss 성분을 단순히 모두 합하는 것이 아닌 평균을 취하면 어떻게 될까?
A5: loss 성분을 모두 합하면 데이터셋의 크기에 따라 loss가 커지거나 작아질 수 있지만, 평균을 취하면 데이터셋 분모가 항상 C - 1이므로 모든 인풋 이미지에 대해 동일한 계산이 적용되고, loss의 상대적 비율은 동일하다.
Q6: 기존의 식 대신 아래의 식을 이용한다면 어떻게 될까?
$L_i = \sum_{j \neq y_i} \max(0, s_j - s_{y_i} + 1)^2$
A6: Loss 함수의 동작이 달라진다. Loss가 클 때를 더 크게 penalize하게 되어, loss가 상대적으로 큰 경우에 더 큰 gradient를 주게 된다.
Regularization
위의 Multiclass SVM Loss에서, loss=0으로 만드는 $\mathbf{W}$를 찾았다고 가정해 보자. 이 $\mathbf{W}$는 유일할까?
아니다. $\mathbf{W}$의 상수배에 해당하는 모든 행렬은 동일하게 loss를 0으로 만들 것이다. 그렇다면 수많은 상수배들 중에서 어떤 것을 선택해야 할까?
이러한 문제를 해결하기 위해 regularization을 사용한다. Regularization은 loss function에 모델의 복잡도에 대한 term을 추가하여 비슷한 성능의 모델 중 '간단한' 모델을 선택할 수 있도록 한다. 이를 통해 모델의 overfitting을 방지할 수 있으며, gradient를 변화시킴으로써 optimization 성능을 향상시킬 수도 있다.
$L(\mathbf{W}) = \frac{1}{N} \sum_{i=1}^{N} L_i(f(\mathbf{x}_i, \mathbf{W}), y_i) + \lambda R(\mathbf{W})$
여기서 $R(\mathbf{W})$가 regularization을 수행한다. Regularization strength를 나타내는 $\lambda$는 hyperparameter이다. 주로 사용되는 방식은 L1 regularization과 L2 regularization 등이 있고, Neural network에서는 Dropout, Batch normalization 등 더 복잡한 방식도 사용된다. 어떤 regularization 방식을 사용할지는 우리가 원하는 '간단함'의 정의에 따라 달라진다.
예시를 통해 regularization의 효과를 살펴보자.
$x = \begin{bmatrix} 1 & 1 & 1 & 1 \end{bmatrix}$
$w_1 = \begin{bmatrix} 1 & 0 & 0 & 0 \end{bmatrix} \quad w_2 = \begin{bmatrix} 0.25 & 0.25 & 0.25 & 0.25
\end{bmatrix}$
위 상황에서, $w_1^Tx$와 $w_2^Tx$는 똑같이 1이기 때문에 두 모델 중 하나를 선택할 수 없다. 이때 Regularization을 적용하면 이 문제를 해결할 수 있다. L1과 L2 Regularization 식은 아래와 같다.
$L1: R(\mathbf{W}) = \sum_{i} \sum_{j} |W_{ij}|$
$L2: R(\mathbf{W}) = \sum_{i} \sum_{j} W_{ij}^2$
L1 Regularization은 가능한 한 적은 수의 원소에 가중치를 집중된 weight를 선호하는 특성이 있다. 즉, weight matrix의 sparsity를 증가시키는 효과가 있어, 불필요한 feature를 제거하는 데 도움을 준다. 위 예시에서 L1 Regularization은 $w_1$을 더 선호한다. 반면 L2 Regularization은 모든 원소에 가중치가 고르게 분포된 weight를 선호한다. 즉, matrix의 모든 원소를 고르게 감소시키는 효과가 있어, 모든 feature를 고르게 사용하도록 하는 데 도움을 준다. 위 예시에서 L2 Regularization은 $w_2$를 더 선호한다.
따라서 regularization 방식은 인풋 데이터의 특성을 보고 직접 선택해야 한다. 인풋 데이터 중 outlier가 많은 경우 L1 Regularization을 사용하면 outlier에 덜 민감한 모델을 얻을 수 있고, 픽셀 하나하나에 noise가 많아 데이터 전체의 흐름을 파악해야 하는 경우 L2 Regularization을 사용하면 더 좋은 성능을 얻을 수 있다. Regularization은 머신러닝 모델을 구축하는 데 매우 중요하고 필수적으로 고려해야 하는 요소이다.
Softmax Classifier and Cross-Entropy Loss
Softmax Classifier
지금까지 Linear classifier와 이에 해당하는 loss function인 Multiclass SVM Loss에 대해 살펴보았다. 그러나 Multiclass SVM Loss는 정답 클래스의 점수가 다른 클래스의 점수보다 높기만 하면 점수 자체에는 큰 의미가 없다는 단점이 있다. Softmax Classifier는 점수를 확률 형태로 변환하여 이러한 단점을 보완한다. 아래는 변환 과정을 나타낸 그림이다.
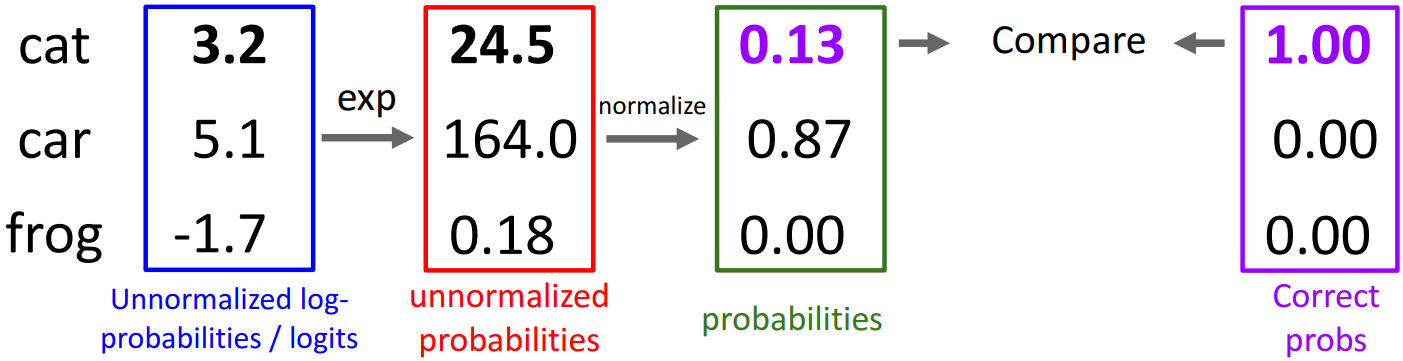
우선 각 클래스별 점수에 softmax 함수를 취한다. softmax 함수는 Softmax 함수는 max 함수의 미분가능한 approximation이라고 볼 수 있다. max 함수가 가장 큰 값을 1로 만들고 나머지는 0으로 만든다면, softmax 함수는 이를 연속적인 확률 분포로 나타내는 것이다. $f(\mathbf{x}_i, \mathbf{W})$의 결과로 나온 점수값(파란색 박스)에 exponential을 취하여 unnormalized probabilities(빨간색 박스)를 구한 뒤, 이를 모두 더한 값으로 나누어 normalized probabilities(초록색 박스)를 구한다. softmax 함수를 수식으로 나타내면 아래와 같다.
$P(j = \text{cat} | \mathbf{x}_i, \mathbf{W}) = e^{s_j} / \sum_{k \in \{\text{cat, car, frog}\}} e^{s_k}$
즉, cat 클래스를 예로 들면 $e^{3.2} = 24.5$가 되고, $\frac {24.5}{24.5 + 164.0 + 0.18} = 0.13$이 된다.
Cross-Entropy Loss
이후 우리가 원하는 이상적인 확률 분포와 비교하는데, 이 확률 분포는 위에서 언급한 max 함수 또는 one-hot encoding 형태와 동일하게 정답 클래스의 확률은 1, 나머지는 0인 분포이다. 두 확률 분포의 차이가 클수록 loss가 커지도록 loss function을 정의한다.
이때 두 확률 분포를 비교하는 방법은 Kullback-Leibler divergence(KL divergence)인데, 이는 머신러닝에서 매우 흔하게 사용되는 loss function인 Cross-Entropy Loss의 기본이 된다. KL divergence의 수식은 아래와 같다.
$D_{KL}(P||Q) = \sum_y P(y) \log \frac{P(y)}{Q(y)}, \quad y \in \{\text{cat, car, frog}\}$
$D_{KL}(P||Q)$ 값이 작을수록 두 확률 분포가 비슷하다는 것을 의미한다. 이때 $Q(y)$는 모델이 예측한 확률 분포(그림에서 초록색 박스), $P(y)$는 비교 대상이 되는 정답 확률 분포(그림에서 보라색 박스)이다.
이때 오답 클래스에 대해서는 $P(y)$가 어차피 0이기 때문에 더하는 것이 의미가 없다. 따라서 정답 클래스에 대해서만 비교를 진행한다. 위 수식에서 $P(y) = 1$, $Q(y) = 0.13$이 되어 KL divergence 값은
$D_{KL}(P||Q) = 1 \times \log \frac{1}{0.13} = 2.04$
이 된다.
여기서 $P(y) = 1$이라는 것이 KL divergence와 Cross-Entropy Loss의 연결고리가 된다.
Cross-Entropy의 수식은 아래와 같다.
$H(P, Q) = -\sum_y P(y) \log Q(y)$
즉, $P(y) = 1$이기 때문에 KL divergence와 Cross-Entropy는 결국 같은 식이 된다.
(사실 KL divergence에서 $P(y) = 1$이 아니라 어떤 상수여도 된다. 결국 우리의 관심은 $Q(y)$를 최대한 1에 가깝게 만드는 것이기 때문에 변수가 없는 $P(y)$는 무시할 수 있다.)
최종적인 Cross-Entropy Loss는 아래와 같다.
$L_i = -\log Q(y) = -\log (softmax(s)) = -\log (softmax(f(\mathbf{x}_i, \mathbf{W})))$
이때 확률밀도함수에 $-\log$를 취하면 negative log likelihood가 되기 때문에 이를 최소화하는 것은 Maximum Likelihood Estimation(MLE)과 같으며, 이 또한 결국 우리가 원하는 확률 분포와 최대한 같아지도록 하는 것이다.
Cross-Entropy Loss를 그래프로 나타내면 아래와 같다.
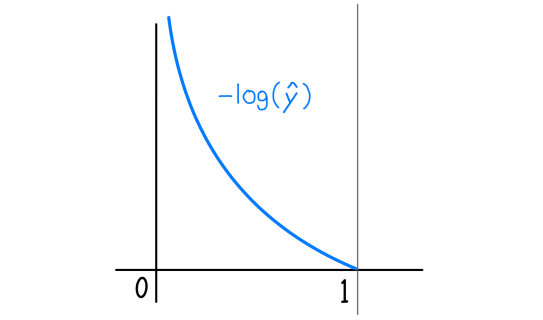
정답 클래스의 확률이 0에 가까울수록 loss는 무한대로 커지고, 1에 가까울수록 loss는 0에 가까워지는 것을 볼 수 있다. 이때 Cross-Entropy Loss의 경우 loss=0에 절대 도달할 수 없다는 특징이 있다.
Q: Training 초기, 모든 점수가 작은 random 값으로 initialization되었을 때 loss는?
A: 모든 클래스의 점수가 유사하므로 uniform distribution의 형태가 되어 softmax 함수의 결과는 1/C가 된다. 따라서 loss는 log(C)가 된다.