Image Classification
컴퓨터 비전의 가장 기초적인 문제로 이미지 분류가 있다. 이미지 분류는 이미지를 입력으로 받아 그 이미지가 개, 고양이, 자동차 등 어떤 클래스에 속하는지 분류하는 문제이다. 그렇다면 어떤 이미지가 특정 클래스에 속하는지 컴퓨터가 어떻게 판단할 수 있을까?
가장 직관적이고 단순한 방법은 단순히 픽셀 밝기 값들의 차이를 구해서 차이가 가장 작은 이미지의 클래스를 따라가는 것이다. 그림으로 표현하면 다음과 같다.
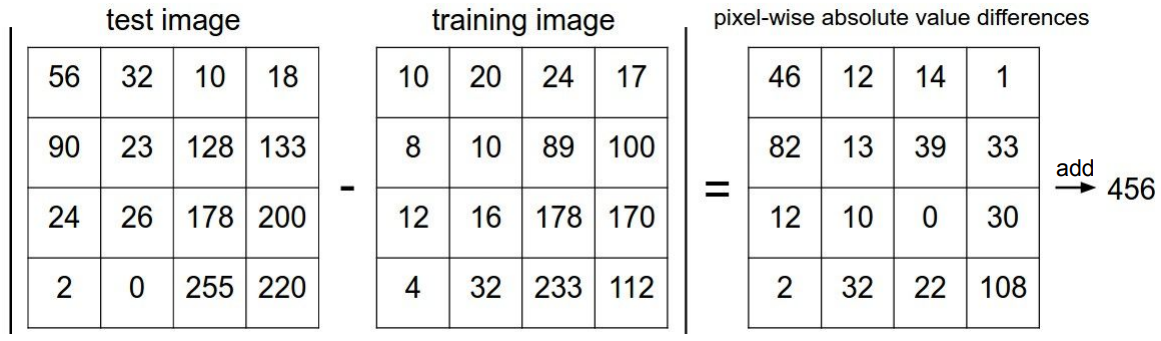
위 그림처럼 차의 절댓값을 모두 합한 것을 L1 distance라 한다. L1 norm과 같은 개념.
이와 유사하게 L2 distance는 차의 제곱을 모두 합한 뒤 제곱근을 씌운 것이다. L2 norm과 같은 개념.
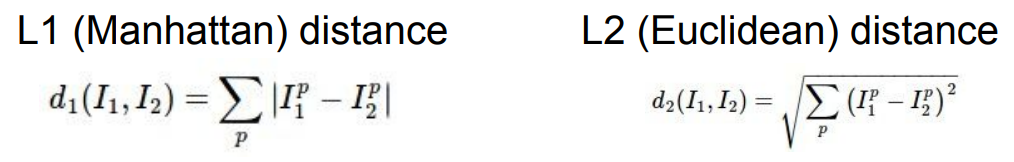
세상의 모든 이미지를 한 군데에 모아 놓고, 위 식을 이용해서 주어진 이미지와 픽셀값이 가장 유사한 이미지를 찾으면 그 두 이미지에는 같은 물체가 있지 않을까?
Nearest Neighbor
이 단순한 발상을 알고리즘으로 옮긴 것이 바로 Nearest Neighbor다. 여러 이미지들 중 주어진 이미지와 가장 유사한 이미지를 찾고, 그 이미지와 같은 클래스를 부여하는 것이다. 이 알고리즘을 시각화해 보면 다음과 같다.
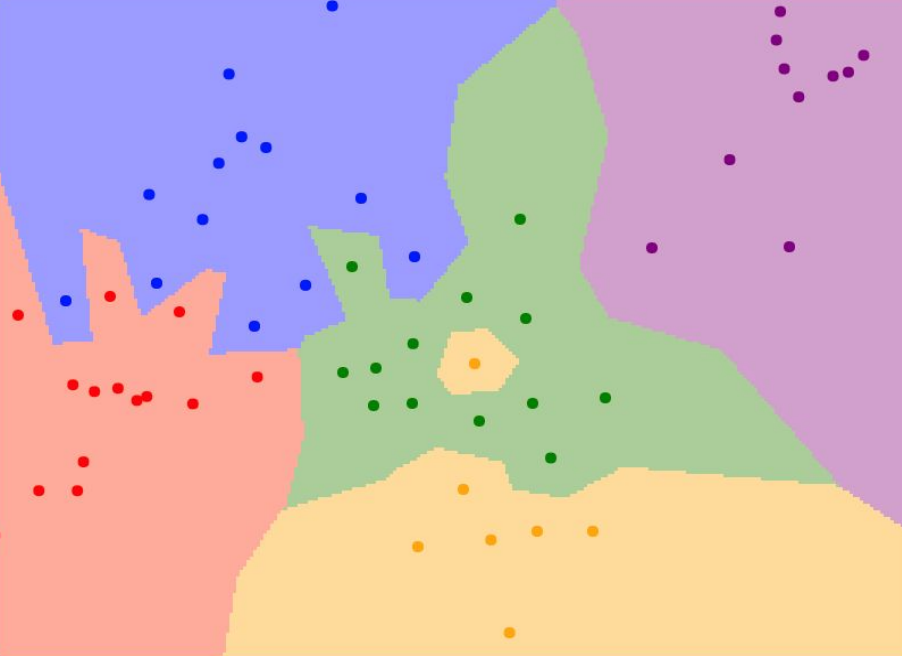
위 사진은 2차원 평면 상 점들을 이미지라고 가정하고 decision boundary를 그린 것이다. 각 색깔은 서로 다른 클래스를 나타낸다. 이 상태에서 새로운 점이 들어온다면, 그 점과 가장 거리가 가까운 점과 같은 색을 가질 것이다. 그렇기 때문에 사진 가운데에 outlier로 보이는 노란색 점이 초록색 점에 둘러싸여 있지만, 그 점 주변에서는 새로운 점이 노란색으로 분류될 것이다.
k-Nearest Neighbors (kNN)
이를 보완하기 위해 가장 가까운 점을 여러 개 선택하여 최다 득표를 받은 클래스를 선택할 수 있다. 여기서 k는 비교할 점(이미지)의 개수를 뜻하는데, k가 1이면 가장 유사한 이미지 하나의 클래스를 따라간다는 뜻이고, 3이면 가장 유사한 3개 이미지를 뽑아 셋 중 가장 많은 수가 나온 클래스를 따라가는 식이다. 아래 사진을 통해 k가 증가할수록 가운데 노란색 점과 같은 outlier에 강인해지는 모습을 확인할 수 있다.
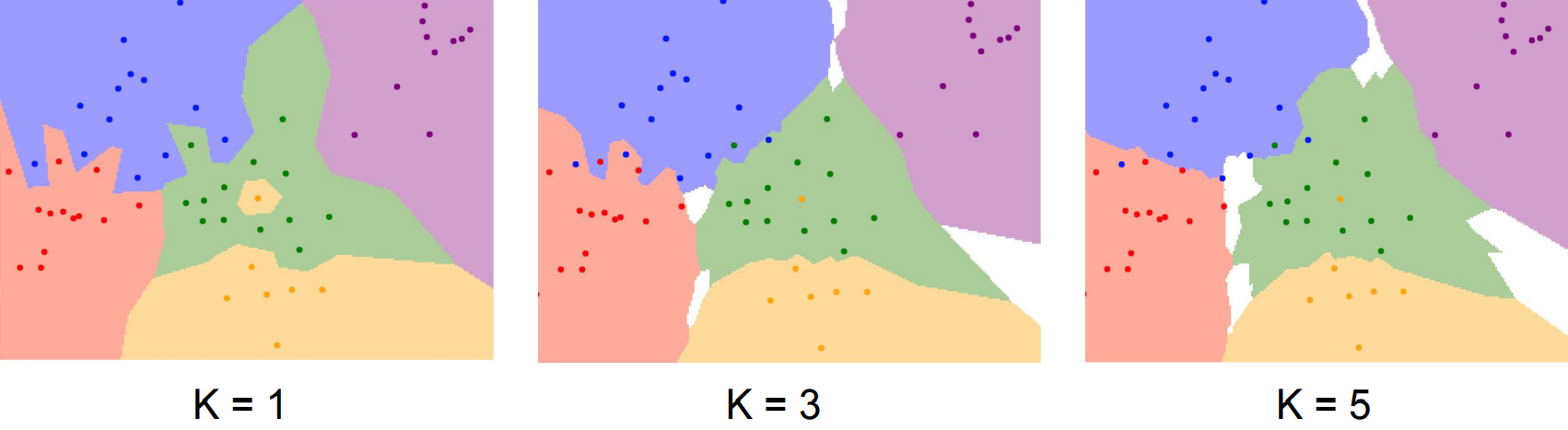
아래 웹사이트를 통해 여러 파라미터를 바꾸어 보며 kNN 알고리즘을 시각적으로 확인할 수 있다.
http://vision.stanford.edu/teaching/cs231n-demos/knn/
이 알고리즘은 단순한 만큼 치명적인 단점이 있다. Training에는 아무런 연산이 필요하지 않은 반면 prediction에 엄청난 연산이 소요된다는 점이다. Training은 사실상 아무런 연산 과정 없이 주어진 데이터를 그대로 저장하기만 하면 되므로 O(1)이다. 반면 prediction에서는 모든 training 데이터와의 distance를 계산해야 하기 때문에 데이터가 많아질수록 연산량이 O(N)으로 증가한다. 실제 사용 환경에서는 training이 오래 걸리더라도 prediction이 빨라야 하므로 이 알고리즘은 실용성이 낮다. 또한, 단순 픽셀값의 차이는 이미지 내 물체의 위치나 방향 등을 고려하지 않기 때문에 이미지에 대한 고차원적인 이해가 불가능하다.
Data Splitting
본격적으로 뉴럴 네트워크를 이용한 이미지 분류에 들어가기 앞서, 데이터셋을 어떻게 분류하고 모델을 훈련시킬 수 있을지 알아보자.
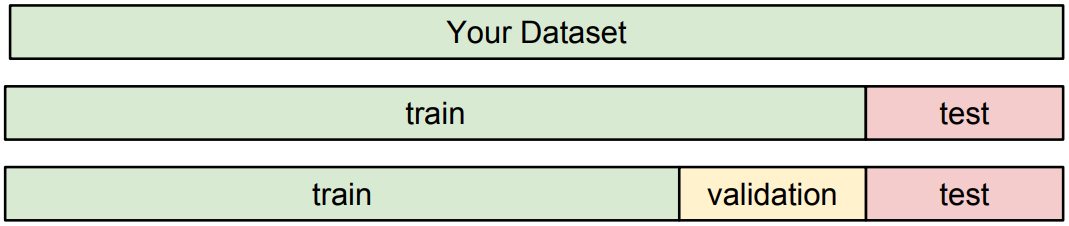
첫 번째 아이디어로, 우리가 가진 모든 데이터를 모델 훈련에 사용할 수 있다. 우리의 모델은 훈련된 이미지에는 이미 완벽히 동작할 것이다. 훈련 시에는 이미지와 정답(라벨)을 주고 훈련시키기 때문이다. 그렇기 때문에 여러 hyperparameter들을 조정해 가며 어떤 조합이 최적일지 찾는 것은 불가능하다.
두 번째 아이디어로, 데이터를 training set과 test set으로 나눌 수 있다. training set을 이용해 모델을 훈련시키고, test set 결과를 통해 가장 적합한 hyperparameter들을 구할 수 있다. 하지만 이 방법 또한 완벽하지는 않은데, test set에만 잘 작동하는 hyperparameter를 구하게 될 수도 있기 때문이다.
따라서, 데이터셋을 training set, validation set, test set의 세 가지로 분류하는 것이 좋다. Training set으로 모델을 훈련시키고, validation set을 이용하여 hyperparameter tuning을 한다. 그 이후에 test set을 이용하여 모델의 성능을 최종적으로 측정하는 것이다. 이 성능이 논문이나 보고서에 실리게 되는 숫자이다. 즉, 모델의 훈련뿐만 아니라 hyperparameter tuning에도 test set이 영향을 미치지 않도록 해야 한다.
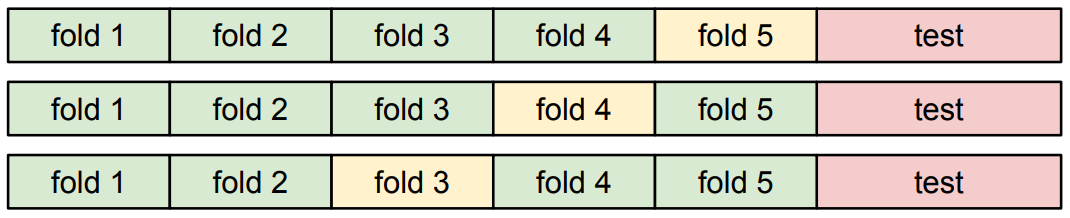
마지막으로, 데이터셋의 크기가 작을 때 주로 사용하는 Cross-Validation이라는 방법이 있다. 이 방법은 우선 training set을 fold라는 단위로 균등하게 나눈 후, 각 fold를 돌아가면서 한 번씩 validation set으로 사용하는 것이다. 이를 통해 더욱 정확한 validation 성능 측정이 가능하다. 하지만 fold의 수에 따라 연산량이 늘어나기 때문에 데이터량이 매우 많은 딥러닝의 경우 잘 사용하지 않는다.