Supervised vs Unsupervised Learning
지금까지 우리는 Supervised Learning을 다루었다. Supervised Learning에서는 training dataset이 input과 output의 쌍 $(X, Y)$으로 주어진다. 따라서, 모델은 input $X$를 output $Y$로 매핑하는 함수를 학습하게 된다.
반면, Unsupervised Learning에서는 output이 주어지지 않는다. 대신 모델은 input 데이터에 내재된 패턴을 학습한다. Unsupervised Learning의 예시로는 clustering, dimensionality reduction, feature learning, density estimation 등이 있다.
Discriminative vs Generative Models
AI 모델을 구분할 수 있는 또 다른 기준으로는 Discriminative vs Generative가 있다. Discriminative Model은 $P(Y|X)$를 학습한다. 즉, input $X$가 주어졌을 때 output $Y$의 확률 분포를 학습하는 것이다. Classification을 예시로 들면, 이미지가 주어졌을 때 class를 예측하는 것이다. 이러한 형태의 모델에서는 Output $Y$의 확률 분포를 모두 합하면 1이 되어야 하기 때문에, 한 class에 대한 확률이 높아지면 다른 class에 대한 확률은 자연스럽게 낮아진다는 특징이 있다.
반면, Generative Model은 $P(X)$를 학습한다. 즉, clustering과 같이 학습 데이터 $X$를 보고 $X$의 확률 분포를 학습하는 것이다. 따라서 이 확률 분포를 이용하면 새로운 데이터를 생성할 수도 있고, 특정 input image가 outlier인지 여부도 판단할 수 있다. 또한 label 없이도 이미지의 특징을 학습하여 feature를 추출할 수도 있다.
Conditional Generative Model은 $P(X|Y)$를 학습한다. 즉, class $Y$가 주어졌을 때 image $X$의 확률 분포를 추정하는 것이다. 따라서 이 분포를 이용하면 주어진 class에 해당하는 이미지를 생성할 수 있다.
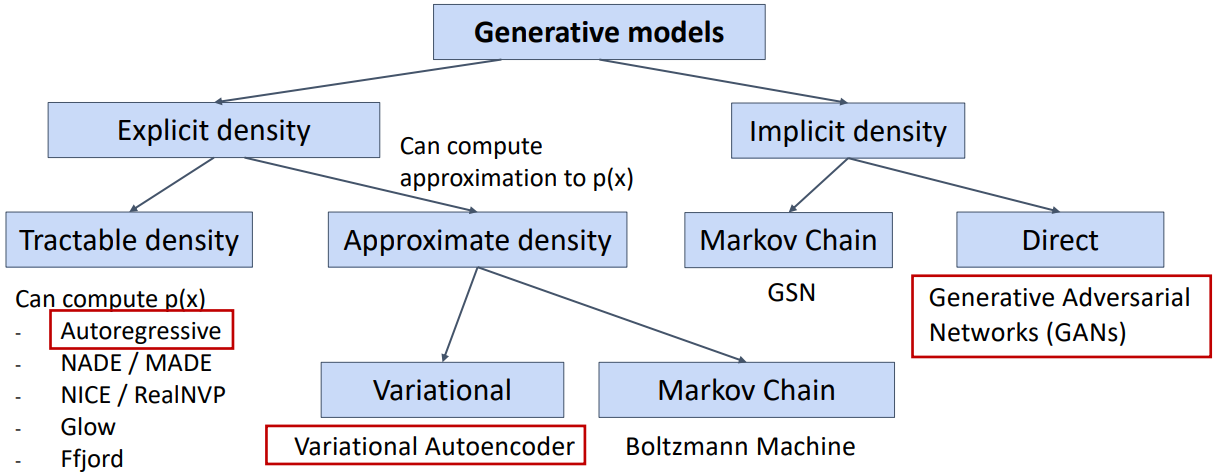
Generative Model은 위 그림과 같이 분류할 수 있다. 생성된 확률 분포를 직접 얻을 수 있는지 여부에 따라 explicit과 implicit density model로 나뉜다. Explicit은 또다시 정확한 확률 분포를 얻을 수 있는지, 추정치만 얻을 수 있는지에 따라 tractable과 approximate density model로 나뉜다. 이 강의에서는 Autoregressive Model, Variational Autoencoder, Generative Adversarial Network (GAN)에 대해 다룬다.
Autoregressive Models
Explicit density model의 목표는 $X$에 대한 확률 분포 $p(x) = f(x, W)$를 직접 얻는 것이다. 이러한 모델을 훈련시키기 위해 Maximum Likelihood Estimation (MLE)을 사용한다. 즉, 지금까지 입력된 training dataset에 대한 확률 분포를 최대화하는 $W$를 찾는 것이다. 주어진 dataset을 $x^{(1)}, x^{(2)}, \cdots, x^{(N)}$이라고 할 때, MLE는 다음과 같이 정의된다.
$W^* = \arg \max_W \prod_{i=1}^N p(x^{(i)})$
계산의 편의를 위해 log를 취하면 다음과 같이 정의된다. 이때 $\arg \max$의 결과는 바뀌지 않는다.
$W^* = \arg \max_W \sum_{i=1}^N \log p(x^{(i)})$
이때 $p(x^{(i)})$를 $f(x^{(i)}, W)$로 근사하면 다음과 같다.
$W^* = \arg \max_W \sum_{i=1}^N \log f(x^{(i)}, W)$
위의 수식을 loss function으로 사용해서 모델을 학습시키면, 모델은 training dataset에 대한 확률 분포를 근사하게 된다. 이러한 셋업은 Explicit density model들의 공통된 특징이다.
그렇다면 Autoregressive Model에서 함수 $f$를 정의하는 방법을 알아보자. 우선 입력 $x$가 $x = (x_1, x_2, \cdots, x_T)$ 등 $T$개의 부분으로 나뉘어져 있다고 가정한다. 이미지에서는 pixel에 해당한다. 그러면 확률분포를 아래와 같이 나타낼 수 있다.
$\begin{align*} p(x) & = p(x1, x2, \cdots, x_T) \\ & = p(x_1) p(x_2|x_1) p(x_3|x_1, x_2) \cdots \\ & = \prod_{t=1}^T p(x_t|x_1, x_2, \cdots, x_{t-1}) \end{align*}$
위의 수식을 잘 살펴보면 RNN과 형태가 유사함을 알 수 있다. 즉, 지금까지 생성된 부분 전체를 이용하여 다음 부분에 해당하는 확률 분포를 계산하는 것이다. 이러한 방식을 통해 모든 부분에 해당하는 확률 분포를 차례차례 구할 수 있다.
이러한 Autoregressive Model의 장점으로는 단순한 구조와 loss function을 가지기 때문에 evaluation하기 쉽다는 것이 있다. 단순히 test set image들이 예측된 확률분포에 잘 들어맞는지를 비교하면 된다. 하지만 generation이 느리다는 단점이 있다.
PixelRNN
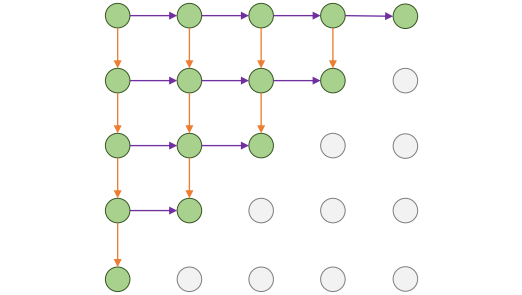
Autoregressive Model의 한 예시로 PixelRNN이 있다. 이는 위의 Autoregressive Model를 이미지 픽셀에 적용하는데, 1차원이 아닌 2차원 RNN의 형태이다. 즉, 한 픽셀의 hidden state는 위쪽 픽셀과 왼쪽 픽셀 모두에 dependent하다.
$h_{x,y} = f(h_{x-1,y}, h_{x,y-1}, W)$
최종적으로 각 픽셀별 hidden state를 이용하여 그 픽셀의 값이 0부터 255까지의 값이 될 확률을 계산하고, 가장 높은 확률을 가지는 값을 선택하여 이미지를 생성한다.
이러한 방식은 모든 픽셀을 순차적으로 처리해야 하기 때문에 training과 testing 모두에서 속도가 매우 느리다는 단점이 있다.
PixelCNN
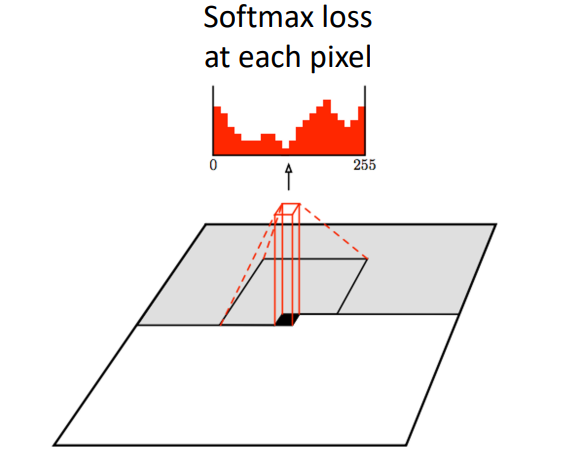
위의 PixelRNN의 단점을 해결하기 위한 모델이 PixelCNN이다. CNN 방식을 사용하기 때문에 병렬 처리가 가능하다. 따라서 training은 PixelRNN보다 빠르지만, 여전히 testing은 순차적으로 진행해야 하므로 느리다.
Variational Autoencoder (VAE)
Variational Autoencoder는 Approximate density model로, 확률 분포를 직접 얻을 수 없다. 대신, 여기서는 확률 분포의 최솟값을 최대화하는 방식으로 학습한다.
Autoencoder
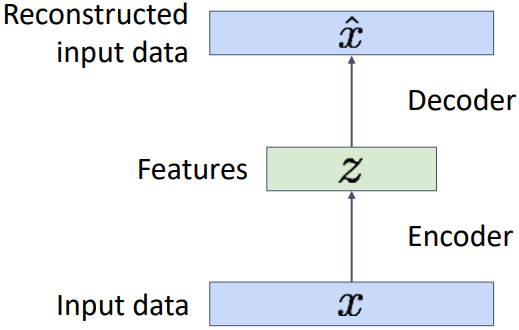
VAE에 대해 살펴보기 전에 일반적인 Autoencoder의 구조에 대해 먼저 살펴보자. Autoencoder는 raw data $x$로부터 feature vector $z$를 추출하는 unsupervised learning 방법이다. 즉 Ground Truth $z$가 존재하지 않는다. Feature vector $z$는 $x$를 더욱 간결하고 고차원적으로 표현하는 feature들을 가지고 있다. 이렇게 추출된 feature vector $z$는 transfer learning을 통해 다양한 task에 사용될 수 있다.
이렇게 입력 $x$를 feature vector $z$로 변환하는 네트워크를 encoder라고 한다. Encoder는 FC layer, CNN 등 다양한 형태로 구성할 수 있다. 이러한 $z$를 Latent Vector라고도 한다.
이러한 Encoder를 실제로 학습시키기 위해서는 Decoder가 필요하다. Decoder는 feature vector $z$를 입력받아 원래의 입력 $x$를 출력하도록 학습하는 모델이다. 이렇게 되면, 원래 입력 $x$와 decoder의 출력 $\hat{x}$ 사이의 L2 loss를 최소화하는 방향으로 encoder와 decoder를 모두 학습시킬 수 있다. 이러한 방식을 통해 GT data 없이도 $x$의 특징을 잘 담고 있는 feature vector $z$를 추출할 수 있다.
학습을 마친 후에는 encoder만을 사용하게 된다. Encoder로부터 추출된 feature vector $z$를 직접 다양한 task에 사용할 수 있다. 하지만 이러한 일반적인 Autoencoder는 probabilistic하지 않기 때문에 새로운 데이터를 sampling할 수는 없다는 문제가 있다.
Variational Autoencoder (VAE)
Variational Autoencoder에서는 사용자가 latent vector $z$에 직접 접근할 수 없다. 따라서 $z$로부터 $x$를 sampling하는 과정은 아래와 같이 이루어진다.
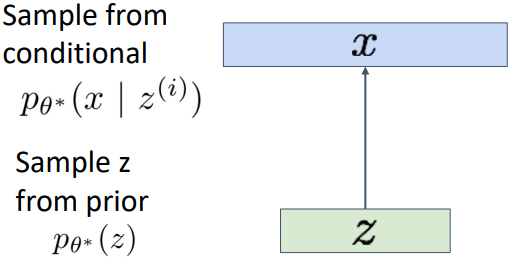
우선 $z$의 prior distribution $p_{\theta^*}(z)$으로부터 $z$를 sampling한다. 이때 prior distribution은 보통 Gaussian distribution으로 가정한다. 이 분포는 학습되는 것이 아닌 사전에 정해지는 것이다.
이후 $z$에 대한 conditional distribution $p_{\theta^*}(x|z^{(i)})$로부터 $x$를 sampling한다. 이때 $p_{\theta^*}(x|z^{(i)})$는 사전에 정해지는 것이 아니라 뉴럴 네트워크를 통해 학습된다. Autoencoder에서의 decoder 부분과 유사하다고 볼 수 있다.
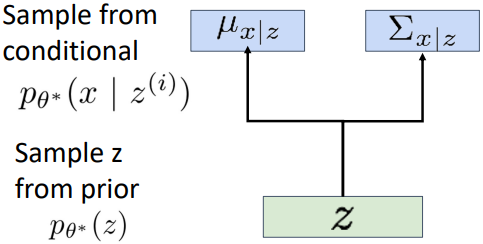
이때, $z$로부터 이미지의 픽셀값 $x$ 자체를 바로 생성하는 것이 아니라, 우선 픽셀별 평균 $\mu_{x|z}$와 covariance $\sum_{x|z}$를 출력한다. 이렇게 정의된 Gaussian distribution으로부터 각 픽셀값을 독립적으로 샘플링하게 된다. 이러한 과정을 통해 $x$를 생성할 수 있다.
Training VAEs
가장 큰 문제는, 이러한 모델을 어떻게 학습시킬 것인가이다. $z$는 우리가 접근할 수 없는 latent vector이므로 여기서는 Maximum Likelihood Estimation (MLE)을 사용한다.
$p_\theta(x) = \cfrac{p_\theta(x|z)p(z)}{p_\theta(z|x)}$
따라서 위 식에서 $p_\theta(x)$를 최대화하면 된다. 이때 $p_\theta(x|z)$는 decoder에 해당하는 부분을 통해 얻을 수 있고, $p(z)$는 prior distribution으로부터 얻을 수 있다. 하지만 $p_\theta(z|x)$는 계산하기 어렵다. 따라서 encoder와 유사한 네트워크를 추가하여 $q_\phi(z|x)$를 구하고, 이것이 $p_\theta(z|x)$와 최대한 비슷해지도록 encoder를 학습시킨다.
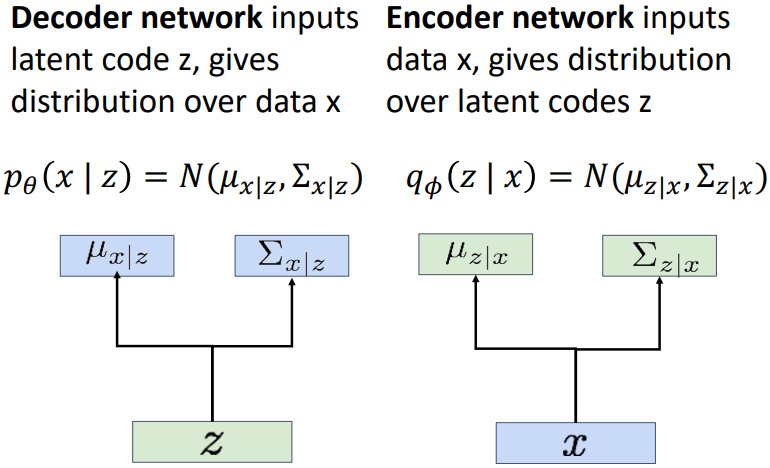
수학적으로 Loss function을 유도해 보자. 우선 위 식의 양변에 log를 취하면 다음과 같다.
$\log p_\theta(x) = \log \cfrac{p_\theta(x|z)p(z)}{p_\theta(z|x)}$
분모와 분자에 각각 $q_\phi(z|x)$를 곱한다.
$\log p_\theta(x) = \log \cfrac{p_\theta(x|z)p(z)}{p_\theta(z|x)} \cdot \cfrac{q_\phi(z|x)}{q_\phi(z|x)}$
이후 로그 규칙을 이용해 아래와 같이 정리한다.
$\log p_\theta(x) = \log p_\theta(x|z) - \log \cfrac{q_\phi(z|x)}{p(z)} + \log \cfrac{q_\phi(z|x)}{p_\theta(z|x)}$
여기서 한 가지 trick으로, $\log p_\theta(x)$는 $z$와 무관하므로 $z$에 대해 expectation을 취해도 값이 변하지 않는다. 즉,
$\log p_\theta(x) = \mathbb{E}_{z \sim q_\phi(z|x)} \left[ \log p_\theta(x) \right] = \mathbb{E}_{z \sim q_\phi(z|x)} \left[ \log p_\theta(x|z) - \log \cfrac{q_\phi(z|x)}{p(z)} + \log \cfrac{q_\phi(z|x)}{p_\theta(z|x)} \right]$
위 식은 아래와 같이 정리된다.
$\log p_\theta(x) = \mathbb{E}_{z \sim q_\phi(z|x)} \left[ \log p_\theta(x|z) \right] - \mathbb{E}_{z \sim q_\phi(z|x)} \left[ \log \cfrac{q_\phi(z|x)}{p(z)} \right] + \mathbb{E}_{z \sim q_\phi(z|x)} \left[ \log \cfrac{q_\phi(z|x)}{p_\theta(z|x)} \right]$
KL Divergence의 정의를 활용하면 아래와 같다.
$\log p_\theta(x) = \mathbb{E}_{z \sim q_\phi(z|x)} \left[ \log p_\theta(x|z) \right] - D_{KL} \left( q_\phi(z|x) || p(z) \right) + D_{KL} \left( q_\phi(z|x) || p_\theta(z|x) \right)$
각 항의 의미를 생각해 보면, 첫 번째 항 $\mathbb{E}_{z \sim q_\phi(z|x)} \left[ \log p_\theta(x|z) \right]$은 data reconstruction에 해당한다. Encoder의 확률분포 $q_\phi(z|x)$로부터 $z$를 sampling하고, 이 $z$를 활용해 decoder에서 확률분포 $p_\theta(x|z)$를 구해 $x$를 다시 sampling하기 때문이다.
두 번째 항은 KL Divergence로, $q_\phi(z|x)$와 $p(z)$ 사이의 차이를 의미한다. 앞에 $-$ 부호가 붙어 있으므로 maximum likelihood가 되려면 KL Divergence 값이 작아져야 한다. 즉, 이는 encoder로부터 나온 $z$의 분포 $q_\phi(z|x)$가 우리가 설정한 prior distribution $p(z)$와 유사해지도록 하는 역할을 한다.
마지막 항은 $q_\phi(z|x)$와 $p_\theta(z|x)$ 사이의 차이를 의미하는데, $p_\theta(z|x)$를 직접적으로 구하기 어렵다. 하지만 우리는 KL Divergence의 값이 항상 0 이상이라는 것을 알고 있으므로, 이 항을 제외하고 부등식을 세우면 아래와 같다.
$\log p_\theta(x) \geq \mathbb{E}_{z \sim q_\phi(z|x)} \left[ \log p_\theta(x|z) \right] - D_{KL} \left( q_\phi(z|x) || p(z) \right)$
따라서, 우리는 우리가 원하는 확률분포를 직접 얻을 수는 없지만 그 확률분포의 lower bound를 최대화하는 방향으로 학습을 진행하게 된다. 이때의 lower bound를 Evidence Lower Bound (ELBO)라고 한다.
이것이 바로 VAE가 Approximate density model로 분류된 이유이다.