Vision Transformer (ViT)
RNN을 완전히 대체한 Attention과 Transformer를, 컴퓨터 비전에는 어떻게 적용할 수 있을까? 이러한 질문에서 Vision Transformer가 등장하게 되었다.
Vision Transformer의 내부 아키텍쳐는 지난 강의에서 살펴본 transformer와 동일하다. 다만 입력 시퀀스를 이미지로부터 어떻게 생성하는지가 중요하다.
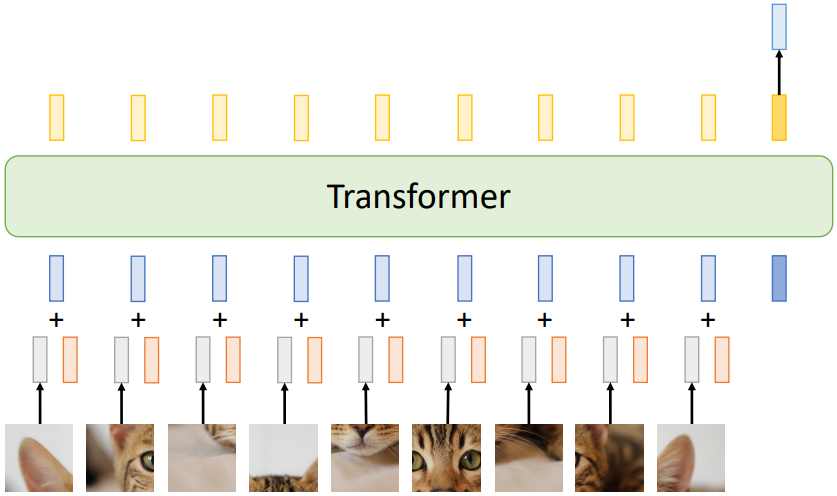
Vision Transformer에서는 위와 같이 이미지를 patch로 나누어 각 patch를 하나의 input vector로 입력한다. 보통 16x16 픽셀 크기의 patch를 사용한다. 이러한 방식의 경우, 이미지 픽셀 각각을 하나의 vector로 사용하는 것에 비해 메모리 사용량을 획기적으로 줄일 수 있다. 그 이유는, Self-Attention의 경우 입력된 sequence 길이의 제곱에 해당하는 크기의 행렬을 만들어야 하는데, 이미지의 경우 그 길이가 $(H \times W)^2$로 매우 크기 때문이다.
입력된 이미지 patch들은 각각 linear projection(=matrix와의 곱셈)을 통해 D의 크기를 가진 벡터로 변환된다. 여기에 각 patch의 이미지상 위치에 대한 정보를 담고 있는 positional embedding 벡터를 더해 준다. Positional embedding 벡터는 위치별로 서로 다른 learnable D-dimensional vector이다. 이것이 Vision Transformer의 입력이 된다.
이때, 우리는 classification과 같은 특정 task를 수행하기를 원한다. 따라서, Vision Transformer의 입력으로 추가적인 classification token을 넣어 준다. 위 그림에서 맨 오른쪽에 해당한다. 이 token 또한 D-dimension이며, learnable parameter이다. 이 token에 해당하는 출력을 얻고, 이를 classification score로 변환하여 최종 결과를 얻는다. 이것이 바로 Vision Transformer의 구조이다.
각 patch에 대한 output을 모아 그것으로부터 classification score를 얻는 것보다, 위에 설명한 classification token 방식이 훨씬 좋은 성능을 내었다고 한다.
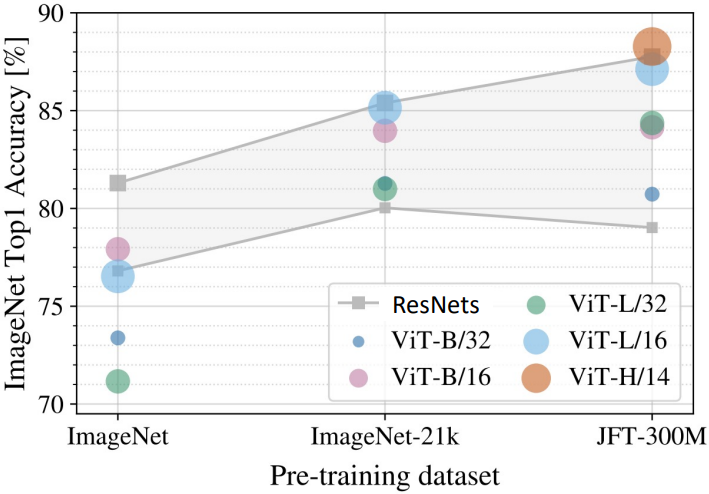
Vision Transformer의 성능을 ResNet과 비교하면 위의 그림과 같다. 위 비교는 먼저 x축에 해당하는 데이터셋으로 pre-training시킨 후 ImageNet으로 fine-tune 후 성능을 측정한 것이다. 데이터셋의 크기가 작을 때는 ResNet이 더 좋은 성능을 보이지만, 데이터셋의 크기가 커질수록 Vision Transformer가 더 우수한 성능을 보이는 것을 확인할 수 있다. 그뿐만 아니라, ViT는 ResNet보다 훨씬 빠른 training 속도를 보이는데, 이는 transformer에서 주로 쓰이는 matrix multiplication이 convolution보다 병렬화하기 쉽기 때문이다.
작은 데이터셋에서도 ResNet보다 우수한 성능을 내기 위해, Vision Transformer는 다양한 regularization과 data augmentation 기법을 사용한다. 이러한 기법들은 다음과 같다.
Regularization:
- Weight Decay
- Stochastic Depth
- Dropout
Data Augmentation:
- MixUp
- RandAugment
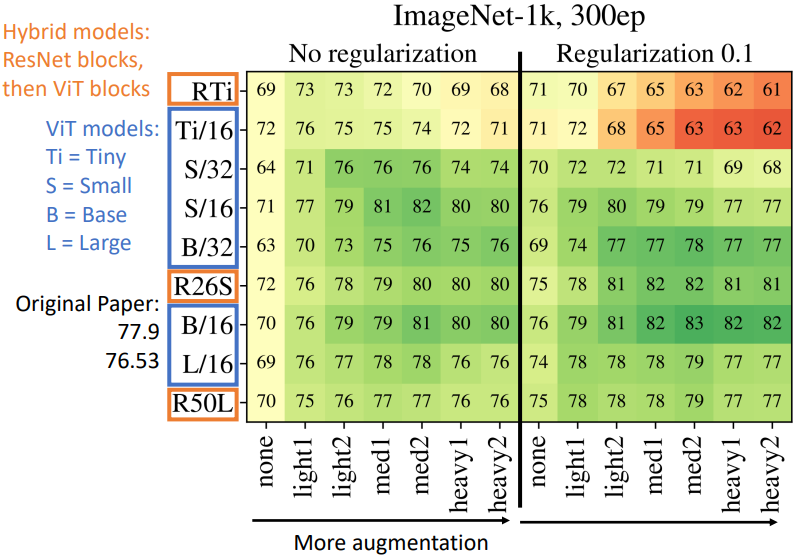
위와 같은 기법들을 사용하면 성능을 꽤 향상시킬 수 있는 것으로 밝혀졌다. 위의 그림은 이러한 기법들의 사용 유무에 따른 성능을 비교한 것이다. 모델에 따라 Regularization과 Data Augmentation을 모두 적용했을 때 최대 13%까지 성능 향상을 보이기도 한다.
Distillation
Distillation은 Regularization, Data Augmentation과 함께 모델의 성능을 향상시키는 또 다른 방법이다. 이는 일반적인 딥러닝 모델에 두루 쓰이는 기법으로, ViT에도 적용될 수 있다.
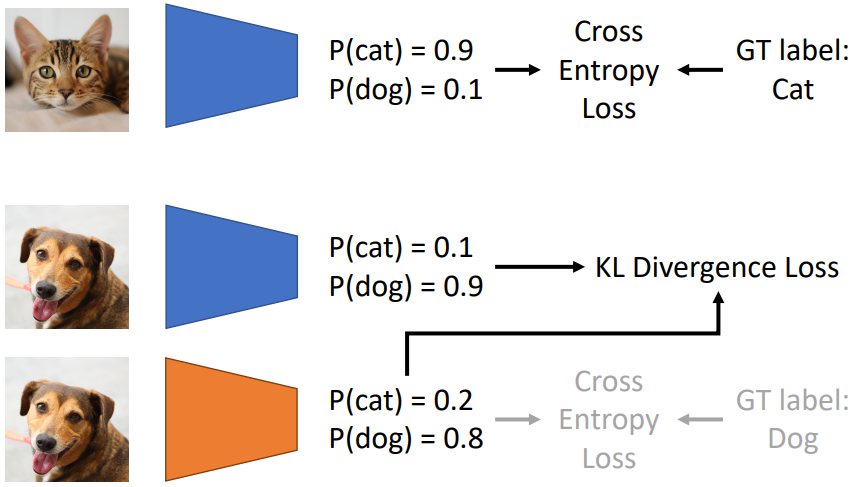
Distillation을 위해서는 두 개의 모델이 필요한데, 각각 teacher model과 student model이다. Teacher model은 꽤 큰 모델로, GT data를 이용해 학습된다. Student model은 MobileNet, ShuffleNet과 같이 상당히 작은 모델로, GT data를 이용해 학습하는 것이 아니라 teacher model의 output과 같은 output을 내도록 학습된다. 위 그림에서는 파란색 사다리꼴이 teacher model, 노란색 사다리꼴이 student model을 나타낸다.
Student model을 학습할 경우 teacher model output과의 KL divergence만을 고려하는 방법과, GT data와의 KL divergence까지 고려하는 두 가지 경우가 있다.
흥미로운 점은, student model을 직접 GT data만을 이용해 학습할 경우보다 teacher model로부터 학습할 경우 더 좋은 성능을 보인다는 것이다. 심지어는 teacher model보다도 더 좋은 성능을 보이기도 한다. 이에 대해 이론적으로 증명할 수는 없지만, GT data를 이용해 학습할 경우 단순히 정답인 GT data를 맞추기만 하면 되지만, Distillation을 이용할 경우 student model은 teacher model로부터 오답인 카테고리의 score까지 학습하기 때문인 것으로 추측된다.
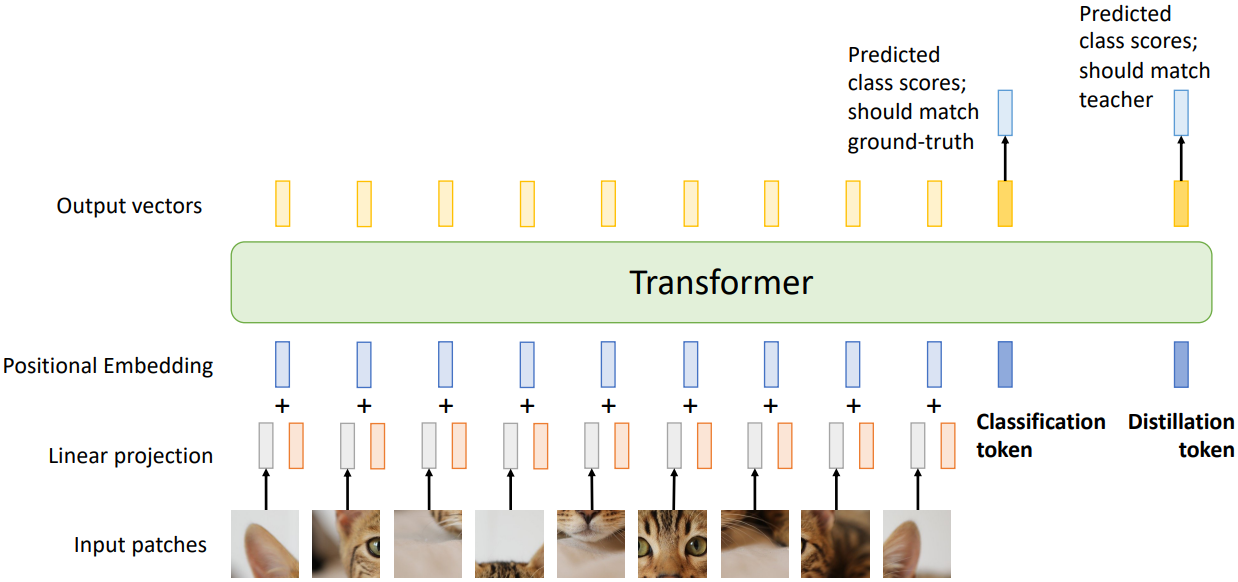
Distillation을 ViT에 적용하는 경우, 위의 그림과 같이 student ViT에 하나의 Distillation Token을 추가하면 된다. 이는 Classification Token과 독립적으로 score를 계산한다. Distillation Token 또한 learnable parameter이다.
Swin Transformer
CNN과 ViT의 가장 큰 차이점은, CNN은 레이어를 거칠수록 이미지의 크기는 줄고 채널 수는 늘어나는 hierarchical architecture를 가진다면, ViT는 레이어를 거쳐도 이미지의 크기와 채널 수가 변하지 않는 isotropic architecture를 가진다는 것이다. Hierarchical architecture의 경우 다양한 크기의 object들을 잘 인식할 수 있다는 장점이 있다. 그리하여 ViT이면서도 Hierarchical architecture를 가지는 새로운 모델을 개발했는데 이것이 바로 Swin Transformer이다.
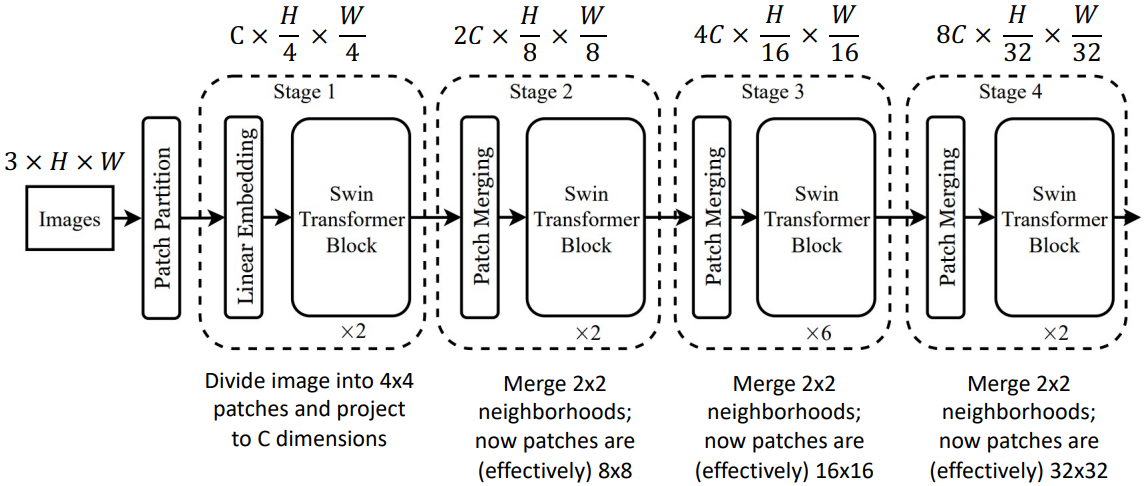
우선 Stage 1을 보면, 입력 이미지를 받아 4x4 픽셀 크기의 patch로 나눈다. 이 patch들로 transformer를 수행하게 된다. Patch의 크기가 4x4이므로 output 이미지의 크기는 1/4로 줄어든다.
Stage 2를 보면, Patch Merging이라는 블럭이 있다. 이 블럭에서는 2x2=4개의 patch를 하나로 합치고, 동시에 채널 수를 2배로 늘린다. 구체적인 방법으로는, 먼저 해당되는 4개의 patch에 대한 vector를 concatenate한다. 이렇게 하면 vector의 크기가 4배가 되는데, 여기에 linear projection(=1x1 conv)을 통해 채널 수를 반으로 줄여서 총 2배가 늘어나도록 한다. 그 이후의 Stage들은 Stage 2와 동일하다.
이때, Stage 1의 4x4 픽셀의 patch는 기존의 ViT에서 쓰이는 16x16 픽셀의 patch보다 훨씬 작다. 따라서 더 많은 patch가 생성되고, 결과적으로 기존 ViT보다 훨씬 많은 메모리를 소모하게 된다.
이를 해결하기 위해, Swin Transformer는 Window Attention이라는 새로운 매커니즘을 사용한다. Window Attention의 기본적인 개념은, 이미지를 window로 나눈 후, 각 window 내부의 patch들끼리만 attention을 수행하는 것이다.
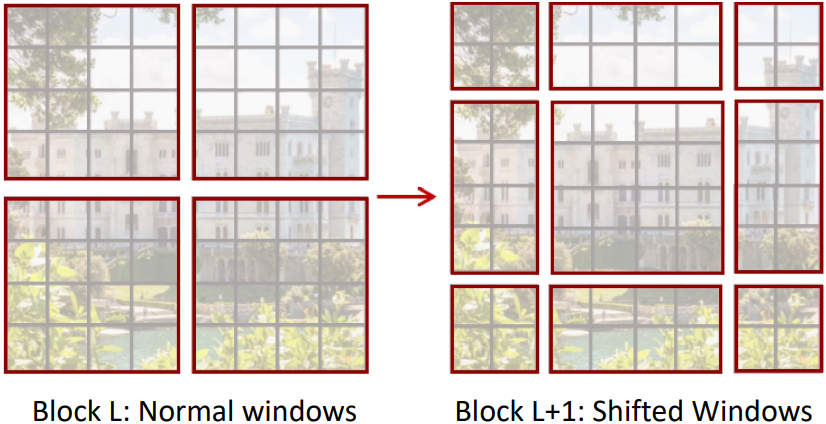
위 왼쪽 그림을 보면, 전체 이미지를 2x2의 window로 나누었고, 각 window에는 4x4=16개의 patch들이 속해 있다. 이때의 attention matrix의 크기를 계산해 보면 $M^4(H/M)(W/M)=M^2HW$가 된다. $M$이 고정되어 있다면 메모리 사용량은 이미지의 크기에 linear하게 된다. 이는 기존 ViT의 메모리 사용량인 $(H \times W)^2$보다 훨씬 작은 크기이다.
이때, 위 왼쪽 그림의 window만을 사용한다면 서로 다른 window 사이의 정보를 공유할 수 없다. 이 문제를 해결하기 위해 Stage마다 위 왼쪽 그림과 위 오른쪽 그림과 같은 두 가지 방법을 번갈아가며 사용한다. 오른쪽 그림의 경우 왼쪽 그림에서 window를 shift시켰기 때문에 Shifted Window라고 부른다.
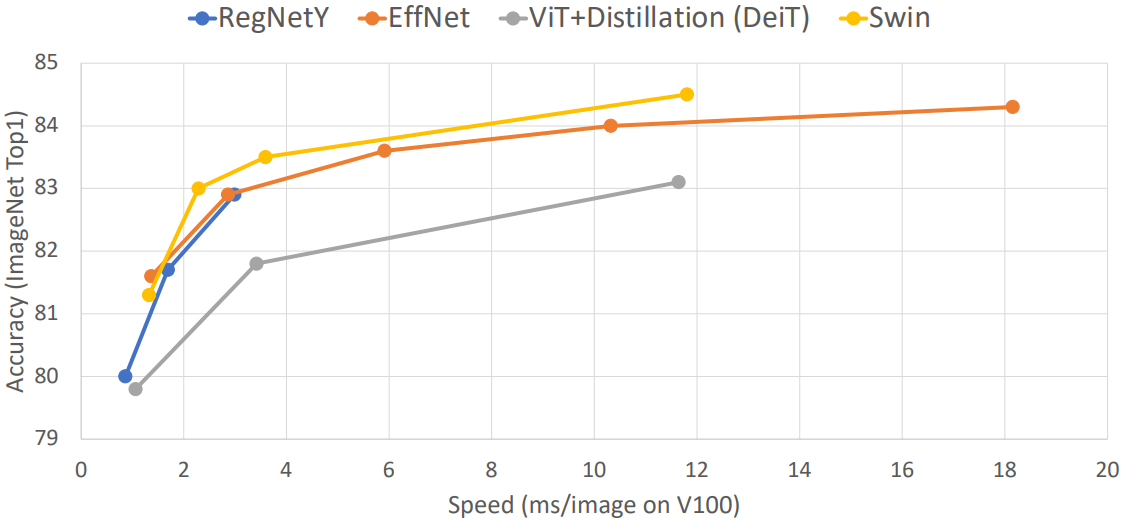
Swin Transformer의 성능은 위 그림과 같다. ViT뿐만 아니라 CNN 기반의 EfficientNet보다도 더 좋은 성능을 보이는 것을 확인할 수 있다. 또한, Swin Transformer는 Hierarchical Architecture를 가지고 있기 때문에 object detection, instance segmentation 등 다른 task에도 적용될 수 있다.
MLP-Mixer
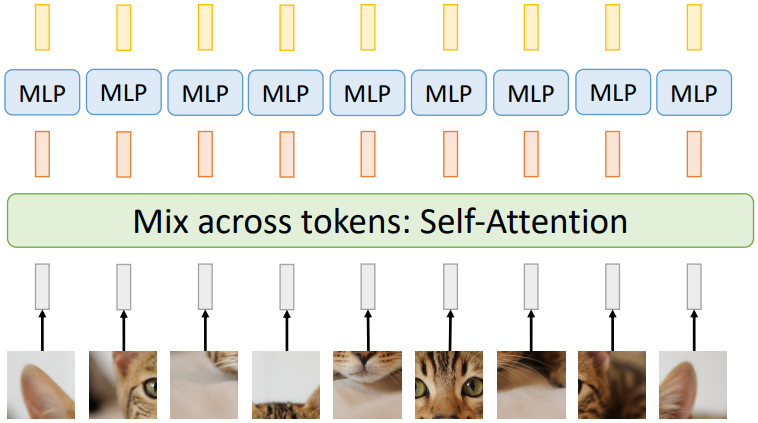
Transformer Block의 구조는 위와 같은데, input vector 사이에 정보 교환이 일어나는 부분은 self-attention 밖에 없고, MLP에서는 input vector 각각에 대해서만 연산이 이루어진다. 따라서, self-attention이 하는 정보 교환의 역할마저도 단순히 MLP로 대체할 수는 없을까? 라는 질문에서 MLP-Mixer가 등장하였다.
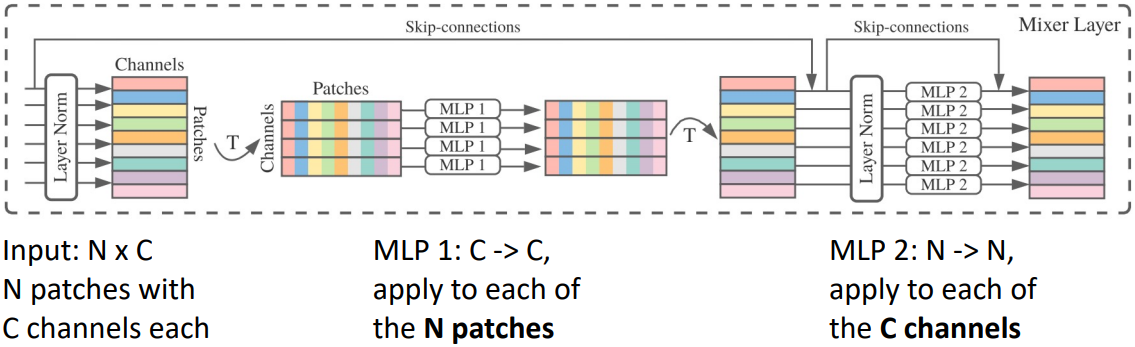
위 그림에서 볼 수 있듯, MLP-Mixer는 self-attention의 역할을 matrix transpose와 MLP로 대체하였다. C의 크기를 가지는 N개의 벡터가 있다면, 이를 $N \times C$ shape를 가지는 matrix 형태로 만든 후 transpose를 취하여 $C \times N$ shape로 만든다. 이후 이 matrix를 N의 크기를 가지는 C개의 벡터로 분리하고, 각각 MLP를 적용한다. 이 과정을 통해 각 벡터 간 정보를 교환한다. 이후 다시 transpose를 취하여 원래 shape로 복원하고, 두 번째 MLP layer를 적용한다.
MLP-Mixer의 성능은 ViT와 비교하여 그렇게 큰 우위를 보이지는 않는 것으로 나타났다.
Object Detection with Transformers: DETR
Transformer를 이용하여 Object Detection을 수행할 수 있는 모델도 등장하였다. DETR 모델은 기존 CNN 기반의 모델에서 많이 사용되었던 anchor나 bounding box regression 없이 바로 object detection을 수행할 수 있는 모델이다.
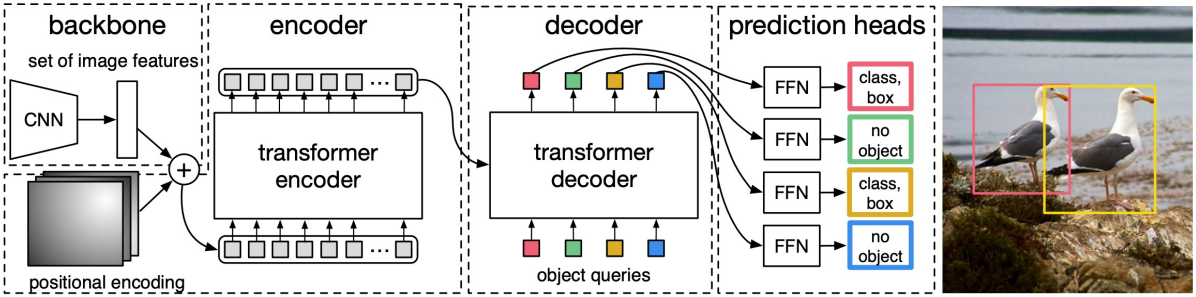
우선 이미지를 CNN에 통과시켜 feature를 얻고, 여기에 positional embedding을 추가한다. 이를 transformer encoder 모듈에 입력시키는데, 이는 기존에 보았던 ViT와 동일하게 self-attention을 이용하여 output vector를 만들어 낸다.
transformer decoder는 self-attention이 아닌 일반 attention을 수행하는 블럭이다. 즉, input vector와 query vector가 별개로 입력된다. Input vector로는 encoder 모듈의 output vector가 입력되고, query vector는 learnable parameter이다. 이 query vector의 element들은 각각 하나의 object를 담당하는데, 각 element들이 input vector 전체를 보고 detection을 수행하게 된다. Query vector의 크기는 충분한 크기로 사전에 정해져 있다.
마지막으로 decoder의 output에 fast-forward network를 적용하여 classification score와 bounding box를 한번에 얻게 된다.
이 구조는 bipartite matching loss를 이용하는데, 이는 non-max suppression이나 복잡한 heuristics 없이도 box matching을 효율적으로 수행할 수 있게 해 준다.