Sequence-to-Sequence with RNNs and Attention
Attention이 등장하게 된 배경인 Sequence-to-Sequence 문제에 대해 자세히 살펴보자. Sequence-to-Sequence 문제에서는 입력 시퀀스와 출력 시퀀스의 길이가 다를 수 있기 때문에 아래 그림과 같이 encoder-decoder 구조로 네트워크를 구성한다. Encoder는 입력 시퀀스를 받아서 하나의 hidden vector로 압축하고, Decoder는 이 hidden vector를 이용해 출력 시퀀스를 생성한다.
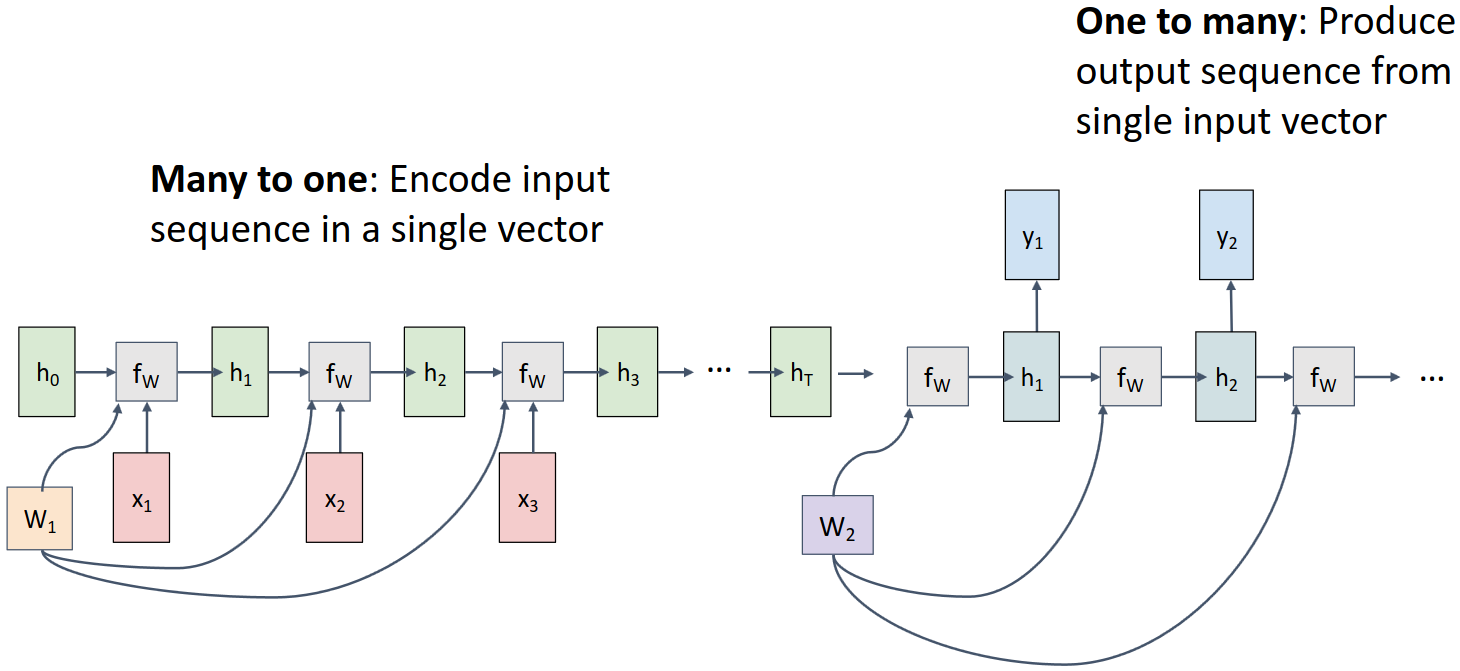
이 구조의 문제점으로는, 입력 시퀀스의 정보가 decoder의 시작 부분에만 전달되기 때문에 decoder가 출력 시퀀스를 생성하는 동안 입력 시퀀스의 정보를 잃어버릴 수 있다는 점이다.
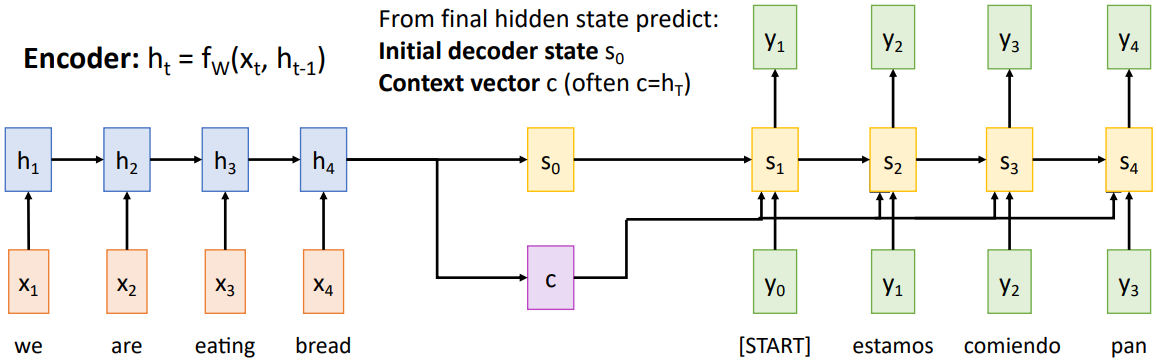
이 문제를 해결하기 위해 context vector를 도입할 수 있다. 이는 hidden state와는 별개로 입력 시퀀스의 정보를 담고 있는 vector이다. Hidden state만을 이용해 decoder의 시작 부분에만 입력 시퀀스를 전달하는 대신, context vector를 decoder의 매 time step마다 전달하여 입력 시퀀스의 정보를 유지할 수 있다.
그러나 이 방식 또한 문제점을 가지고 있는데, context vector의 길이가 정해져 있기 때문에 입력 시퀀스의 길이가 무한정 길어질 경우 context vector에 모든 정보를 담을 수 없다는 점이다.
이에 대한 해결책으로, 같은 context vector를 계속 사용하는 대신, 매 출력 시퀀스마다 필요한 정보만을 가지고 context vector를 매번 업데이트하여 사용할 수 있다. 이것이 바로 초창기 Attention이 등장한 배경이다.
Attention as an add-on to Sequence-to-Sequence
앞서 설명했듯, 초창기 Attention은 Sequence-to-Sequence의 문제를 해결하기 위해 RNN에 추가적으로 도입된 네트워크이다. 이때의 attention은 매 decoder의 hidden state를 이용하여 그 다음 time step에 사용할 context vector를 예측하는 방식으로 동작한다. 이 과정의 의의는 "현재의 hidden state를 이용해 다음 time step에서 더 집중해서 볼 입력 시퀀스의 subset을 추출해 context vector에 저장하는 것"이다. 매 time step마다 이전 step의 output과 context vector를 이용해 hidden state를 계산하고, 이 hidden state를 이용해 output과 다음 context vector를 계산하는 과정이 반복된다.
그렇다면 decoder hidden state를 이용해 다음 time step에 사용할 context vector를 계산하는 과정을 좀 더 자세히 살펴보자. 아래 그림은 t = 1일 때 context vector $c_1$를 계산하는 과정이다.
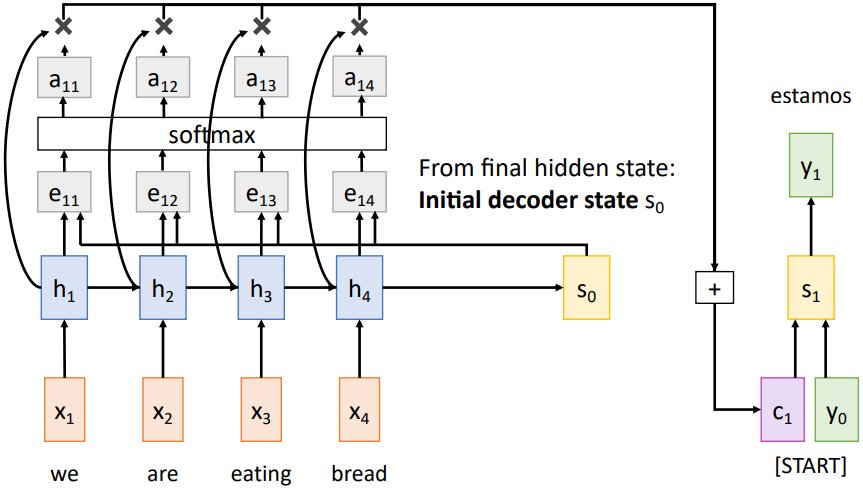
먼저, 이전 time step의 decoder hidden state $s_0$를 가져와 각각의 encoder hidden state와 함께 MLP에 입력한다. 이 MLP를 $f_{att}$라 하면 아래와 같이 각 쌍에 해당하는 alignment score $e_{t,i}$를 구할 수 있다.
$e_{t,i} = f_{att}(s_{t-1}, h_i)$
이 alignment score는 "현재의 hidden state를 보았을 때, 다음 time step에서는 어떤 입력 성분에 더 집중해야 하는지"를 나타낸다.
위 그림에서 $e_{11}$, $e_{12}$, $e_{13}$, $e_{14}$의 값이 클수록 다음 hidden state를 계산할 때 그 입력 성분을 더 많이 참조하게 되는 것이다. 이때 이 값들을 유효하게 사용하기 위해 softmax를 취하여 0과 1 사이의 값인 $a_{t,i}$로 변환하게 된다. 이를 attention weight라고 한다. 이후 $a_{t,i}$를 각각의 encoder hidden state에 곱하여 중요도에 따라 각 입력 성분을 취한 후 이를 모두 더해 context vector를 생성한다.
$c_{t} = \sum_i a_{t,i}h_i$
즉, context vector $c_t$는 $s_t$를 계산할 때 집중해서 봐야 할 인풋 시퀀스의 부분집합이라고 할 수 있다. 이렇게 계산된 context vector $c_t$는 아래와 같이 다음 hidden state $s_t$를 계산하는데 사용된다. 이때 $G$는 decoder RNN, $U$는 decoder에 사용되는 weight matrix를 나타낸다.
$s_t = G_U(y_{t-1}, s_{t-1}, c_t)$
위 예시에서는 "we are eating bread"라는 문장을 스페인어로 번역하는데, t = 1일 때 "we are"에 해당하는 "estamos"를 출력하기 위해서는 $h_1$과 $h_2$에 더 집중해야 한다. 따라서 $c_1$은 아마도 $a_{11} = a_{12} = 0.45$, $a_{13} = a_{14} = 0.05$ 정도로 계산되어 "we"와 "are"에 더 많은 가중치가 부여되었을 것이다.
같은 방식으로 다음 time step t = 2에서는 "eating"에 해당하는 정보가 많이 포함된 context vector $c_2$를 생성한다. 이 과정을 반복하여 [STOP] 시그널이 출력될 때까지 문장을 이어나가게 된다.
이러한 Attention 구조 덕분에 입력 시퀀스의 길이가 아무리 늘어나더라도 유한한 크기의 context vector에 효과적으로 필요한 정보만을 담아 전달할 수 있다.
참고로, alignment score를 계산하는 MLP는 ground truth 없이 단순 backpropagation으로 학습한다.

위 그림은 Attention을 이용하여 영어를 프랑스어로 변역할 때 사용된 attention weight를 시각화한 것이다. 각 문장은 아래와 같다.
- Input: "The aggrement on the European Economic Area was signed in August 1992."
- Ground truth: "L'accord sur la zone économique européenne a été signé en août 1992."
위 그림을 보면 첫 4개 단어와 마지막 6개 단어는 순서대로 같은 의미를 가지고, 5번째~7번째 단어는 역순으로 같은 의미를 가지는 것을 알 수 있다. 또한 'was signed'의 경우 'a été signé'로 번역되는데, 단어의 수가 다르기 때문에 정확히 일대일 매칭이 되지 않고 가중치가 분산된 것을 확인할 수 있다. 이러한 attention weight을 통해 모델이 어떤 입력 성분을 근거로 출력을 생성하는지를 볼 수 있고, 이를 통해 모델의 동작을 해석할 수 있다.
이처럼 Attention 메커니즘은 Sequence-to-sequence RNN에 더해져 그 성능을 크게 향상시킬 수 있는 방법이다.
Image Captioning with RNNs and Attention
위의 Attention 메커니즘을 자세히 살펴보면, Attention은 입력 데이터를 순차적으로 처리하는 것이 아니라 순서가 없는 '집합'으로 생각하고 병렬적으로 처리한다. 데이터의 종류도 문자나 단어에만 국한되지 않는다. 그렇기에 Attention을 RNN뿐만 아니라 image captioning 등 다양한 문제에 일반화시킬 수 있다.
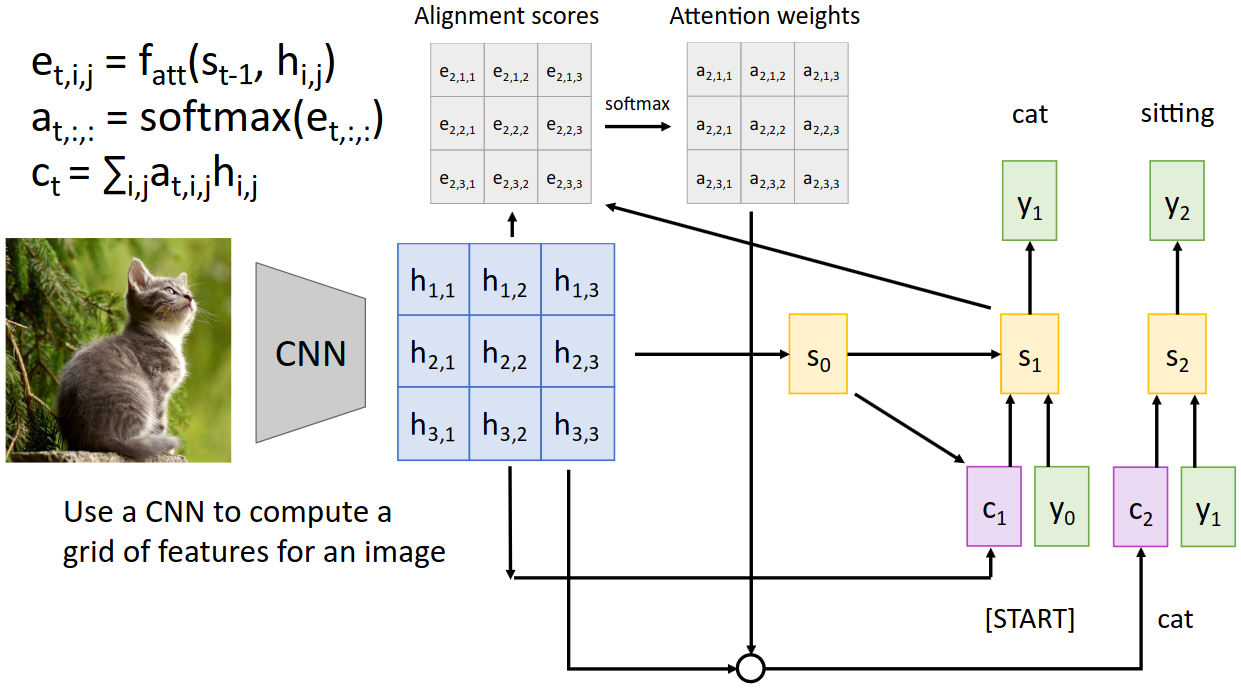
Image captioning에서는 input hidden state를 RNN에서 가져오는 것이 아닌 conv net의 activation map에서 가져온다. 먼저 Transfer learning을 통해 feature map을 얻는다. 이 feature map을 이용하여 decoder의 initial hidden state인 $s_0$을 얻는다. 이후 $s_0$와 각각의 feature map 요소들을 이용해 alignment score를 계산하고 전체에 softmax를 적용하여 attention weight를 구한다. 이를 기존의 feature map과 element-wise 곱한 후 더하여 context vector를 생성한다.
$e_{t,i,j} = f_{att}(s_{t-1}, h_{i,j})$
$a_{t,i,j} = softmax(e_{t,:,:})$
$c_t = \sum_{i,j} a_{t,i,j}h_{i,j}$
따라서 context vector $c_t$는 $s_t$를 계산할 때 집중해서 봐야 할 인풋 이미지의 부분집합이라고 할 수 있다.

위 그림은 Attention을 이용하여 이미지 캡션을 생성할 때 사용된 attention weight를 각 time step마다 시각화한 것이다. 'bird'라는 단어를 생성할 때는 새가 있는 부분의 attention weight가 높고, 'water'를 생성할 때는 새를 제외한 나머지 부분의 attention weight가 높은 것을 확인할 수 있다.
Attention Layer
Attention 메커니즘은 지금까지 살펴본 것과 같이 RNN과 함께 사용될 수도 있지만, 약간의 업그레이드를 거쳐 독립적으로 사용 가능한 레이어의 형태로 발전시킬 수 있다. 위에서 살펴본 image captioning 모델을 부분적으로 업그레이드하면서 Attention 레이어를 독립적으로 사용할 수 있는 형태로 만들어 보자.
우선 Attention Layer에서 사용할 변수를 정의하자.
- Query vector: $q$ (Shape: $D_Q$)
- Input vectors: $X$ (Shape: $N_X \times D_X$)
새롭게 등장한 Query vector $q$는 image captioning 모델에서의 decoder hidden state $s_t$에 해당한다. Input vectors $X$는 $D_X$의 크기를 가진 벡터가 $N_X$ 길이의 시퀀스만큼 입력된다는 것을 의미한다. 위 image captioning 모델에서의 $h_{i,j}$에 해당한다.
Upgrade 1: Replace the Similarity Function with Dot Product
첫 번째로는 similarity function을 단순히 dot product로 대체하는 것이다. 벡터와 벡터의 dot product는 두 벡터가 유사할수록 큰 값을 가진다. 따라서, alignment score를 '다음 time step에서 어느 element를 집중해서 봐야 할지'가 아닌 '각 time step의 input vector가 query vector와 얼마나 유사한지'로 계산한다.
$e_i = q \cdot X_i / \sqrt{D_Q}$
이때, $D_Q = D_X$로 설정하면 $e_i$의 shape는 $N_X$가 된다. 또한 dot product의 결과를 $\sqrt{D_Q}$로 나누어 주게 되는데, 이는 모델의 학습 시 saturation이나 vanishing gradient 문제를 방지하기 위한 trick이다.
Upgrade 2: Calculate Context Vectors for Every Decoder Time Step at Once
두 번째로는 모든 decoder time step에 대해 context vector를 한 번에 계산하는 것이다. 우선, 모든 decoder time step에 대해 decoder hidden state, 즉 query vector $q$를 사전에 알고 있다고 가정한다. 그렇다면 아래와 같이 query vector를 모아 행렬을 구성할 수 있다. 이때 $N_Q$는 decoder time step의 수를 의미한다.
- Query vectors: $Q$ (Shape: $N_Q \times D_Q$)
- Input vectors: $X$ (Shape: $N_X \times D_X$)
이제 각 query vector와 각 input vector 사이의 dot product를 행렬 곱셈으로 한 번에 표현할 수 있다.
$E = QX^T / \sqrt{D_Q}$
이후 이전과 동일하게 softmax를 이용해 attention weight를 구하는데, 이때 각 query vector에 대해 독립된 확률 분포를 구하기 위해 column-wise softmax를 취한다. Attention weight $A$의 shape는 $N_Q \times N_X$가 된다.
$A = softmax(E, \text{dim=1})$
이제 아래의 식을 이용해 각 query vector에 대한 context vectors $Y$를 계산할 수 있다. $Y$의 각 element $y_i$는 기존의 context vector와 마찬가지로 $D_X$의 column 크기를 가지고, 모든 query vector에 대한 context vector를 모았으므로 $Y$는 $N_Q$의 row 크기를 가진다. 즉, $Y$의 shape는 $N_Q \times D_X$가 된다.
$Y = AX$
그렇다면 사전에 모든 decoder time step에 대한 query vector를 어떻게 알 수 있을지 의문이 생기는데, query vector에서부터는 RNN의 개념으로부터 벗어나기 때문에 단순히 각 time step에서의 context vector를 얻기 위한 일종의 '질문'이라고 생각하면 된다. 이 query vector를 어떻게 구하는지에 대해서는 아래의 Self-Attention Layer에서 다룬다.
Upgrade 3: Extract Keys and Values from Input Vectors
위 수식들에서 input vectors $X$가 어떻게 사용되는지를 살펴보면, 먼저 query vectors $Q$와 곱해져 alignment score를 계산하는 데 사용되고, 이후 alignment score $A$와 곱해져 context vectors $Y$를 계산하는 데 사용된다. 이때 두 연산에 동일한 input vectors $X$를 사용하는 것이 아닌, 각 연산에 더욱 최적화된 아래의 두 행렬 $K$와 $V$를 추출할 수 있다.
- Key matrix: $W_K$ (Shape: $D_X \times D_Q$)
- Value matrix: $W_V$ (Shape: $D_X \times D_V$)
- Key vectors: $K = XW_K$ (Shape: $N_X \times D_Q$)
- Value vectors: $V = XW_V$ (Shape: $N_X \times D_V$)
- $E = QK^T / \sqrt{D_Q}$
- $Y = AV$
Key vectors $K$는 alignment score를 계산하는 데 사용되고, Value vectors $V$는 context vectors $Y$를 계산하는 데 사용된다. Key vectors $K$는 query vectors와 곱해져 각 time step에서 중요하게 볼 부분을 추출하는 데 사용된다. 또한 value vectors $V$는 실질적인 정보를 담고 있으며 $A$와 곱해져 필요한 정보만을 추출한 $Y$를 생성하게 된다.
이 단계에서부터는 앞에서 가정한 $D_Q = D_X$가 더 이상 적용되지 않는다. 대신 Key vectors의 column이 Query vector와 같은 $D_Q$의 크기를 가진다. 또한 Value vectors의 column이 $D_V$의 크기를 가지므로 $Y$의 column도 $D_V$의 크기를 가지게 되고, 인풋 시퀀스와 아웃풋 시퀀스가 다른 shape을 가질 수 있게 된다.
지금까지의 attention layer를 그림으로 나타내면 아래와 같다. $X$와 $Q$는 독립적으로 입력된다고 가정한다.
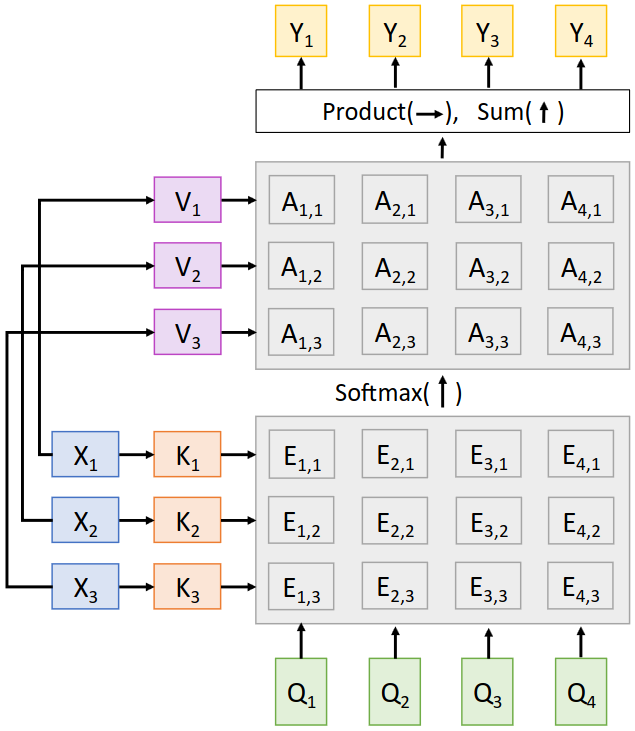
$X$로부터 $K$를 구한 뒤 $Q$와 곱하여 alignment score $E$를 구하고, 여기에 column-wise softmax를 취해 attention weight $A$를 구한다. 이후 $A$와 $V$를 곱하여 context vector $Y$를 구한다. 이 과정을 통해 각 time step에서 필요한 정보만을 효율적으로 추출할 수 있다. $Y$의 각 element $y_i$는 query vector element $q_i$와 전체 input vectors $X$의 정보를 반영한다.
Self-Attention Layer
지금까지 살펴본 Attention Layer는 query vector와 input vectors를 독립적으로 입력받아 context vector를 계산하는 아주 일반적인 형태이다. 여기서 드는 한 가지 의문은 query vector를 어떻게 구하는가이다. 앞서 살펴본 sequence-to-sequence RNN에서는 decoder input $y_i$가 들어올 때마다 hidden state $s_i$를 생성했다. 반면 Self-Attention Layer에서는 input data $x_i$를 이용해 query vector를 생성한다. 그렇기에 모든 input vector를 병렬적으로 계산해 query vector를 한꺼번에 생성할 수 있다.
즉, 여기서 추가되는 부분은 $X$에 query matrix $W_Q$를 곱해 query vectors $Q$를 생성하는 것밖에 없다. Input vectors $X$만 가지고 context vector를 만들어 내기 때문에 Self-Attention Layer라고 불리는 것이다.
- Query matrix: $W_Q$ (Shape: $D_X \times D_Q$)
- Query vectors: $Q = XW_Q$ (Shape: $N_X \times D_Q$)
$X$를 이용해 $Q$를 구하기 때문에 $N_X = N_Q$가 되어 두 행렬의 row의 크기는 동일하다. 이후는 앞서 살펴본 Attention Layer와 동일하게 진행된다.
Self-Attention Layer를 그림으로 나타내면 아래와 같다.
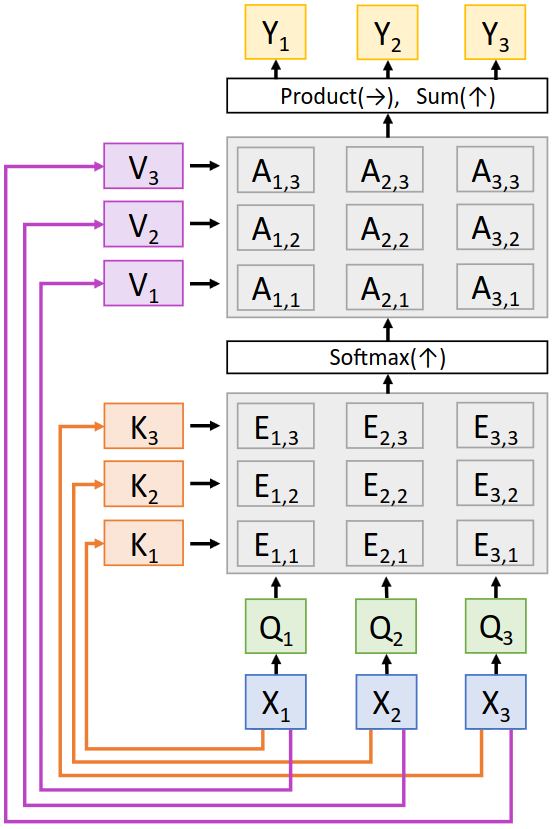
Self-Attention Layer로부터 계산된 context vector $Y$는 이 layer의 output이 되고, 이후의 layer들을 이용해 최종 output을 생성하게 된다. 결국 Self-Attention Layer는 input vectors $X$를 이용해 같은 크기의 output vectors $Y$를 계산하는데, $Y$의 각 element $y_i$는 모든 $X$의 element를 이용해 계산된다. 즉, input이나 output의 time step이나 순서의 의미가 없어지고 모든 element를 고려하여 output을 계산하는 것이다.
추가적으로, 위의 Upgrade 1에서 alignment score를 dot product로 계산하기 때문에 '각 time step의 input vector가 query vector와 얼마나 유사한지'의 의미로 해석할 수 있다고 설명했다. 이제는 '각 time step의 key vector가 query vector와 얼마나 유사한지'로 해석할 수 있는데, input vector 자체와 query vector의 유사도를 계산하는 것이 아니라 학습 파라미터인 $W_K$를 통해 key vector를 query vector와 유사하게 만들어주는 것이다. 또한 self-attention에서는 query vector 또한 input vector로부터 계산되기 때문에 이 두 벡터들이 유사해지도록 동시에 두 weight matrix $W_K$와 $W_Q$를 학습하게 된다.
Self-Attention Layer의 장점으로는 아래의 두 가지가 있다.
- Input vector가 아무리 길어도 Self-Attention Layer 하나만 거치면 output은 input vector 전체에 dependent하다.
- GPU에서 병렬 처리가 가능하다.
또한, 앞서 Image Captioning 부분에서 설명했듯 Self-Attention Layer는 입력 데이터의 순서에 상관이 없다는 점이 중요한 특징이다. 즉, 벡터들의 '집합'에 대해서 이 Self-Attention Layer를 적용할 수 있다. 다른 말로 하면, 이 Self-Attention Layer는 입력 데이터가 어떤 순서로 들어오는지 알지 못한다는 것이다. 언어 모델 등에서는 입력 데이터의 순서를 알고 있는 것이 도움이 되기 때문에 아래와 같은 트릭을 사용한다.
Positional Encoding
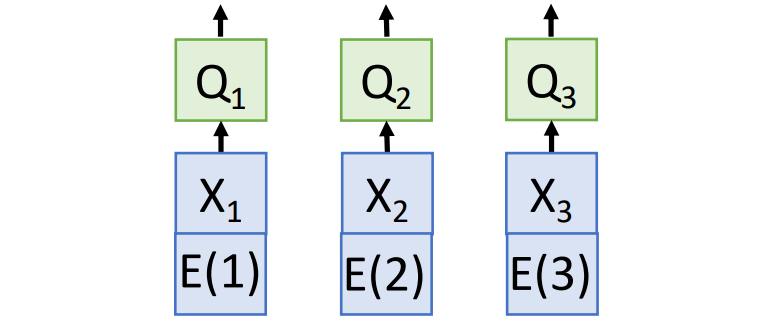
위와 같이 입력 데이터 $X$에 순서 정보를 담고 있는 positional encoding vector $E$를 concat하거나 add하는 방법이 있다.
Masked Self-Attention Layer
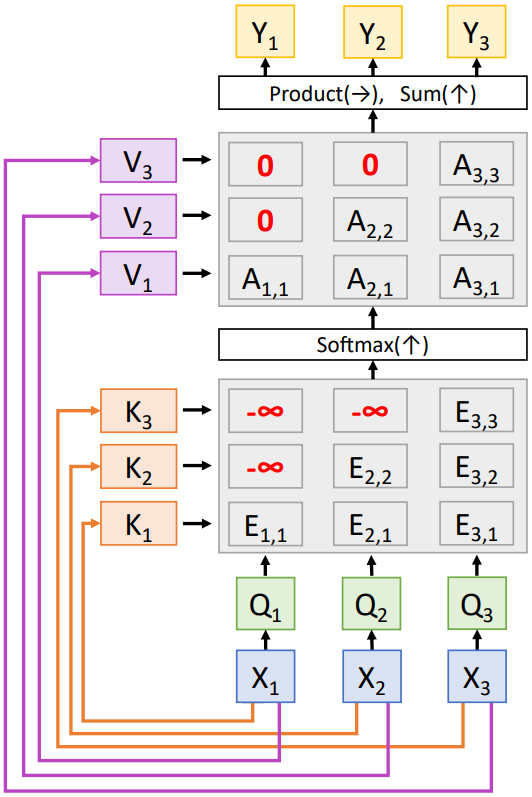
위와 같이 Alignment score $E$를 계산할 때, 현재 time step 이후의 time step에 대한 정보를 강제로 $-\infty$로 만들어 버리는 방법이 있다. 이렇게 하면 softmax를 취했을 때 해당하는 값이 0이 되어 이후의 time step에 대한 정보를 무시할 수 있다.
Multihead Self-Attention
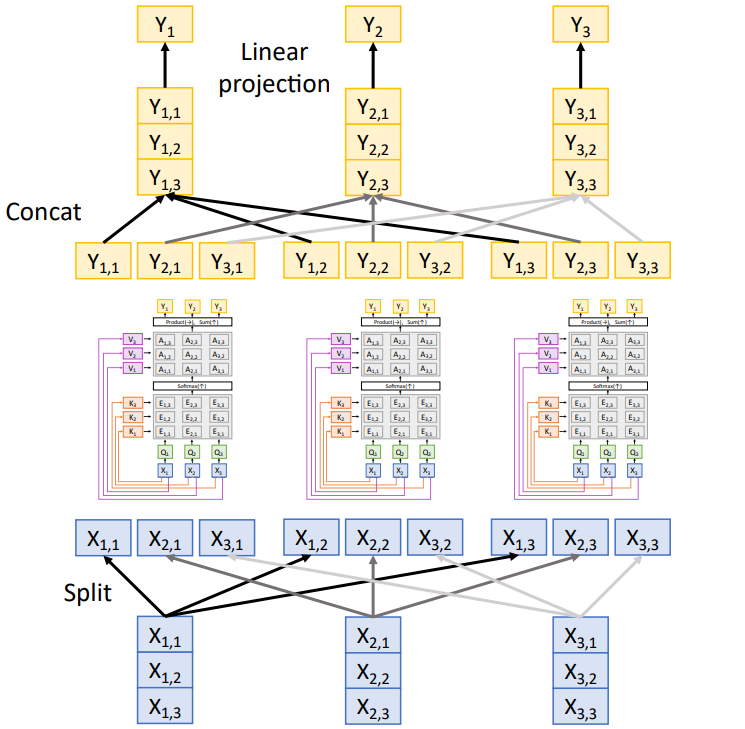
Multihead Self-Attention은 우선 입력되는 벡터들을 각각 h개의 chunk들로 나눈다. 위 그림에서는 3개의 chunk로 나누었다. 이후 chunk별로 입력 데이터를 분리하여 각각 self-attention을 수행한다. 이렇게 얻어진 chunk별 결과를 concat한다. 다만 이렇게 하면 하나의 input vector에서는 chunk간 상호작용이 없기 때문에, 마지막으로 FC layer를 이용하여 concat된 결과를 하나의 벡터로 만들어 준다.
CNN with Self-Attention
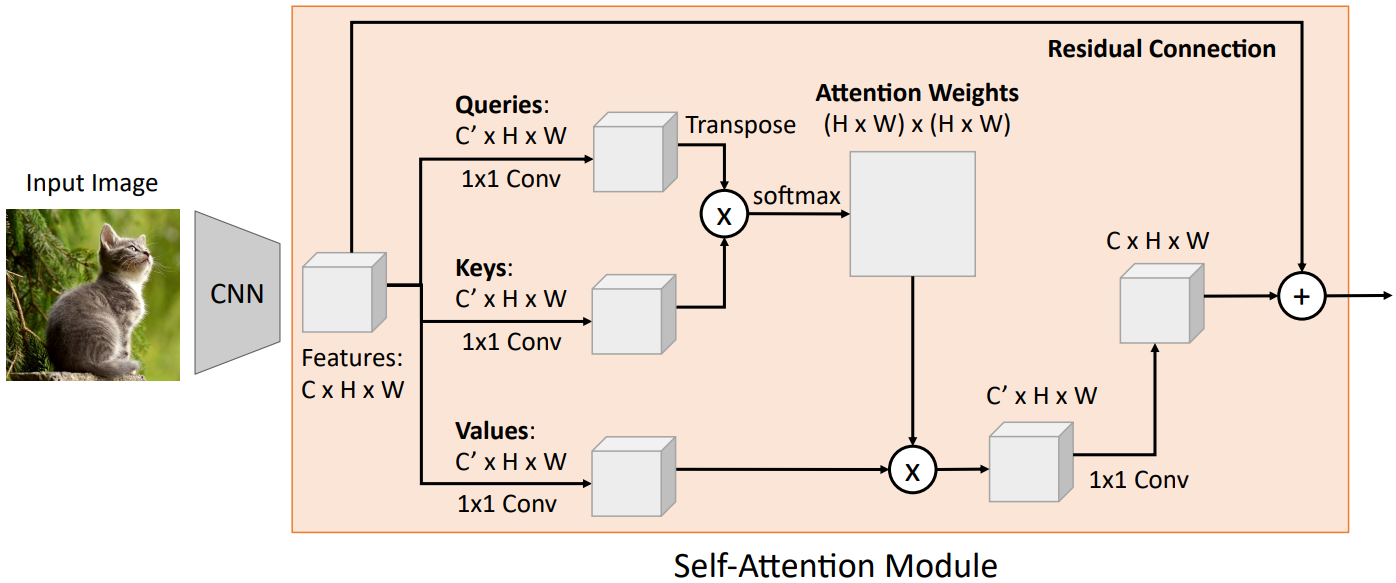
Self-Attention을 이미지에도 적용할 수 있다. 우선 CNN을 이용해 feature map을 얻은 뒤, 이를 1x1 conv를 이용하여 query, key, value로 나눈다. 이후 $E=QK^T$를 계산하고, 여기에 softmax를 취해 attention weight를 구한다. 이후 $Y=AV$를 계산하여 context vector를 얻는다. 마지막으로는 형태를 맞추기 위해 1x1 conv를 이용하여 채널 수를 기존과 동일하게 맞춰 주고, residual connection을 이용하여 원래의 feature map과 합쳐 준다.
Transformer
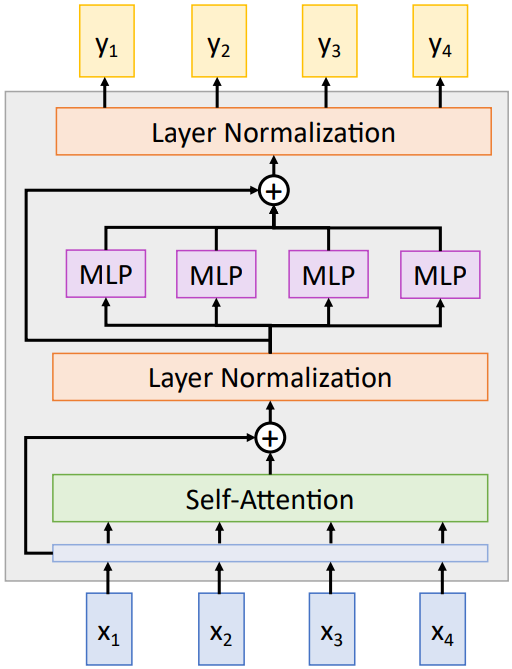
Transformer는 Self-Attention Layer를 이용한 아키텍쳐이다. 하나의 transformer block 내부를 살펴보면, 우선 input vector를 받아 Self-Attention Layer를 거치고, Residual Connection을 이용하여 gradient flow를 유지해 준다. 이후 Layer Normalization을 적용한다. Residual Connection과 Layer Normalization은 ResNet에서와 유사하게 모델이 빠르게 수렴하도록 하는 역할을 하는데, ResNet에서 Batch Normalization을 사용했던 것과 달리 Transformer에서는 Layer Normalization을 사용한다. Layer Normalization은 vector 사이의 상호작용이 없기 때문이다.
이후 각 vector에 대해 Feed Forward Network라고도 불리는 MLP를 적용하고, Residual Connection과 Layer Normalization을 한 번 더 적용한다. 이렇게 생성된 vector가 이 Transformer block의 output이 된다. Transformer block을 여러 번 쌓아서 Transformer 네트워크를 구성하게 된다.
이러한 Transformer 아키텍쳐에서는 hyperparameter로 block의 개수, query vector의 dimensions $D_Q$, Self-Attention Layer의 head 수의 3개밖에 없다.
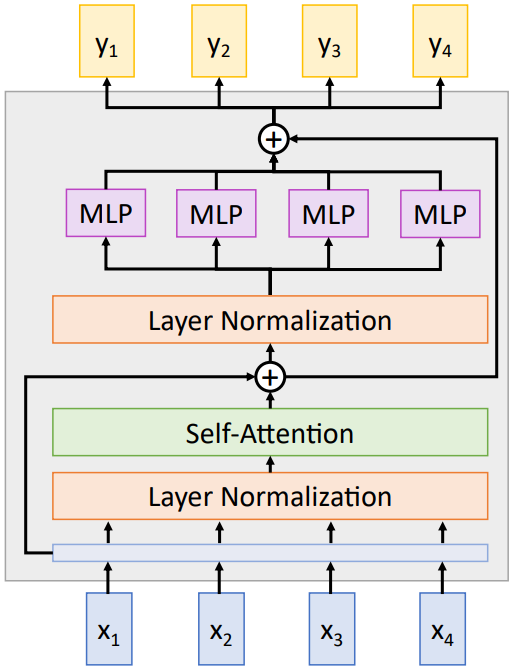
위 그림은 Layer Normalization을 Residual Connection 앞에 두는 Pre-Norm Transformer의 구조를 나타낸다. 이 구조가 실제로는 더 많이 사용된다.
질문: Self-Attention 이후에 MLP를 적용하는 것이 RNN에서 hidden state를 output으로 변환하기 위해 한 번 더 MLP를 적용하는 것과 같은 역할을 하는 것인가?