Semantic Segmentation
지금까지 이미지 내 object들을 검출하고 위치를 찾아내는 object detection를 다루었다. 이러한 object 단위의 localization 문제 외에도 다양한 종류의 localization 문제가 있는데, 그 중 하나는 모든 픽셀 하나하나를 classify하는 semantic segmentation이 있다.

Semantic Segmentation의 특징은 객체 각각을 구분하지 않는다는 것이다. 위의 오른쪽 사진을 보면 소 두 마리가 구분되지 않고 하나의 같은 label을 가지는 것을 볼 수 있다.
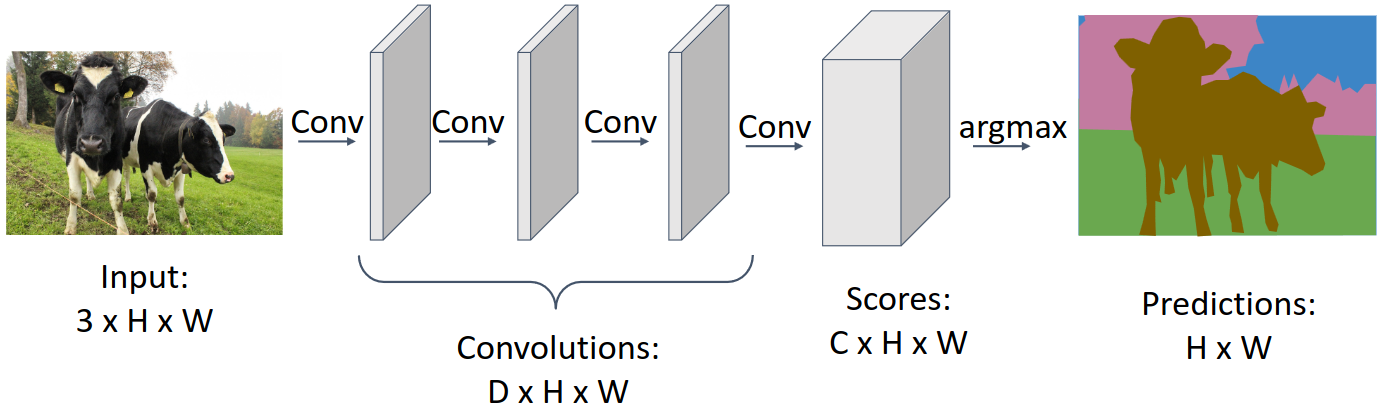
Semantic segmentation을 위해서는 모델의 출력이 입력 이미지와 같은 크기를 가지고, 각 픽셀에는 클래스 정보가 담겨 있어야 한다. 따라서 위와 같이 activation map의 크기를 변화시키지 않는 fully convolutional network를 생각할 수 있다. Conv layer를 통해 최종적으로 $C \times H \times W$의 activation map을 얻고, 여기에 argmax를 취해 클래스를 예측하는 것이다. 하지만 이러한 방식은 receptive field의 크기를 키우는 데 너무 많은 레이어가 필요하며, 원본 이미지의 resolution이 높을 경우 연산량이 매우 많이 발생한다는 문제가 있다.
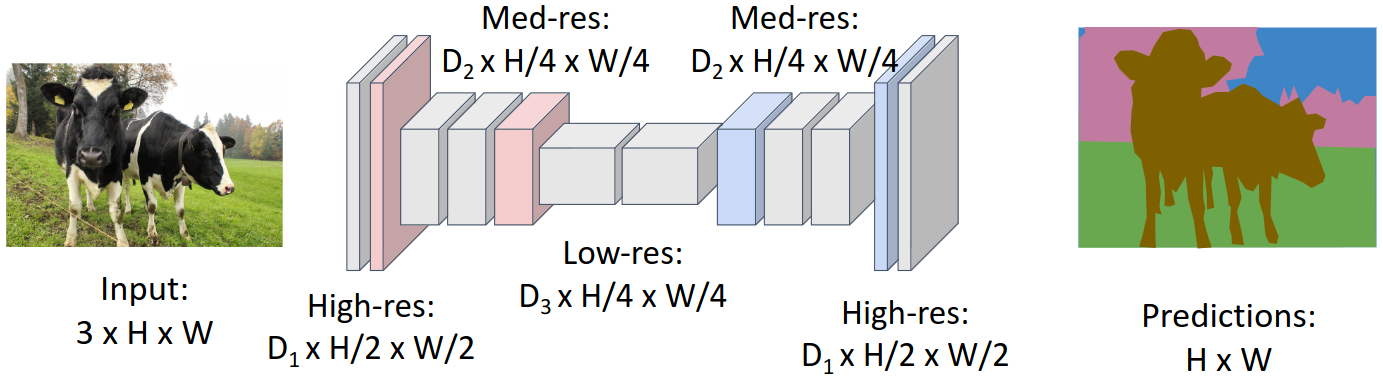
이러한 문제를 해결하기 위해, 위 그림과 같이 이미지를 downsampling했다가 다시 upsampling하는 방법을 사용한다. Downsampling을 위해서는 pooling이나 strided convolution을 사용한다. Upsampling을 위해서는 어떤 방법을 사용해야 할까?
Bed of Nails
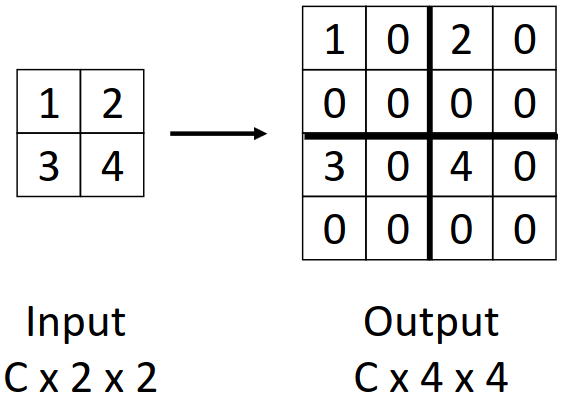
Bed of Nails는 위 그림과 같이 output cell의 좌상단에만 input cell 값을 넣고 나머지는 0으로 채우는 방식으로, 실제로 잘 사용되지는 않는다.
Nearest Neighbor
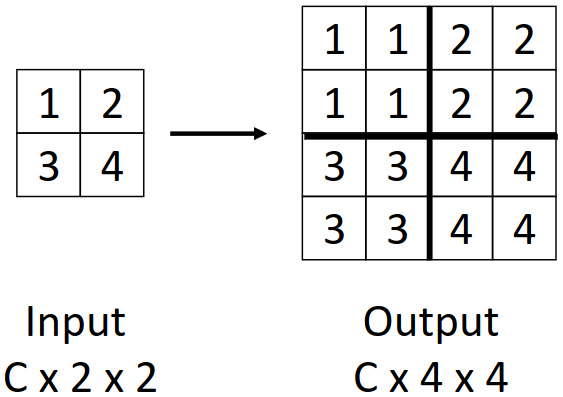
Nearest Neighbor는 각 output cell을 input cell 중 가장 가까운 값으로 채우는 방식이다.
Bilinear Interpolation
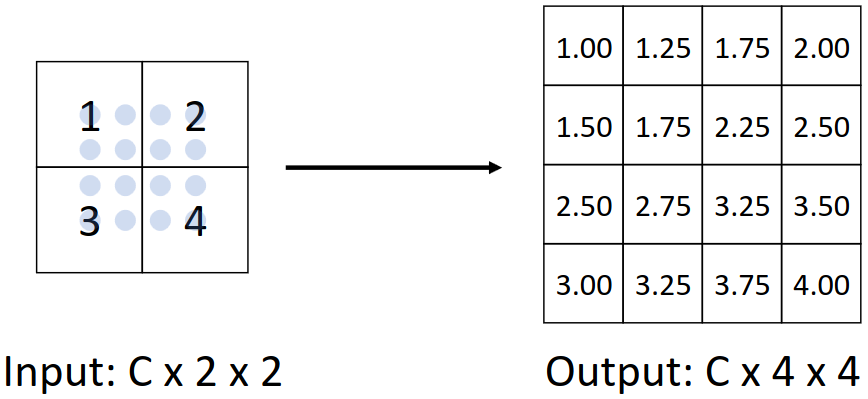
조금 더 복잡한 방식으로는 Bilinear Interpolation이 있다. 이는 RoI align에도 사용한 방식으로, output cell들을 resize해서 소숫점 좌표를 가진 grid로 만들고, interpolation을 이용하여 값을 구한다. 보통 꼭지점 4개의 값은 보존하고, 그 사이를 채우는 방식으로 작동한다. 구체적인 수식은 아래와 같다.
$f_{x,y} = \sum_{i, j} f_{i, j} \max(0, 1 - |x - i|) \max(0, 1 - |y - j|)$
$i, j$의 범위는 아래와 같다.
$i \in \{\lfloor x \rfloor - 1, \cdots, \lceil x \rceil + 1\}$
$j \in \{\lfloor y \rfloor - 1, \cdots, \lceil y \rceil + 1\}$
Biliear Interpolation은 잘 작동하고 컴퓨터 비전에서 많이 사용되는 방법이다.
Bicubic Interpolation
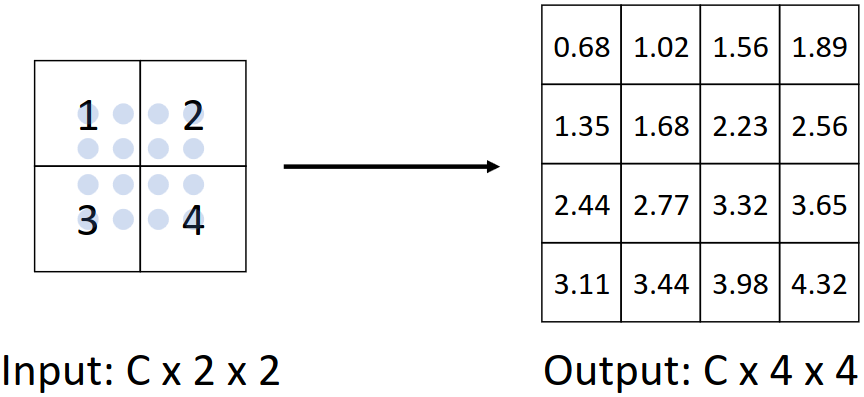
Bicubic Interpolation은 Bilinear Interpolation을 확장한 방식으로, 더 많은 값을 사용하여 interpolation을 수행한다. 일반적인 image resizing 알고리즘이지만 upsampling 시에는 잘 사용되지 않는다.
Max Unpooling
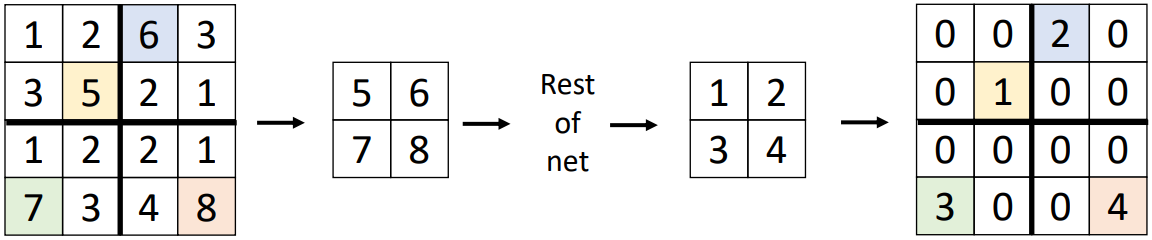
Max Unpooling은 downsampling 과정에서 어떤 위치의 픽셀에 가장 큰 값이 있었는지를 기억하고 있다가, 그 max pooling layer에 대응되는 max unpooling layer가 등장하면 해당되는 픽셀에 값을 넣어 주고 나머지는 0으로 채우는 방식이다. 이 방식을 통해 max pooling으로 인해 발생한 약간의 pixel shift를 복구할 수 있다. 하지만 실제로 그렇게 많이 사용되지는 않는다.
Transposed Convolution

고정된 함수가 아니라 CNN과 같은 구조를 이용해 upsampling을 하는 방법도 있는데, 이를 Transposed convolution이라 한다. Strided convolution 연산을 반대로 적용하는 방식으로 작동한다.
우선 일반 convolution 연산과 같이 특정 크기의 filter를 사용한다. 위 그림에서는 3x3 filter를 사용한다. 우선 위의 output image에서 빨간색 box로 표시된 3x3 filter를 output image의 첫 위치에 배치한다. 위 그림에서는 padding=1을 사용하여 (-1, -1)의 위치에 filter의 왼쪽 상단이 위치한다. 이후 input image의 좌상단에 해당하는 빨간색 픽셀값을 filter element-wise 곱하고, 이렇게 scaliing된 filter를 output image의 각 위치에 입력한다.
Stride를 2로 설정하였으므로, 그 다음 파란색에 해당하는 input image의 픽셀은 오른쪽으로 한 칸 이동했지만 output image의 box는 오른쪽으로 두 칸 이동한다. 이후 처음과 같은 방법으로 filter를 scaling하고 output image에 입력한다. 이때 겹치는 부분은 값을 더한다.
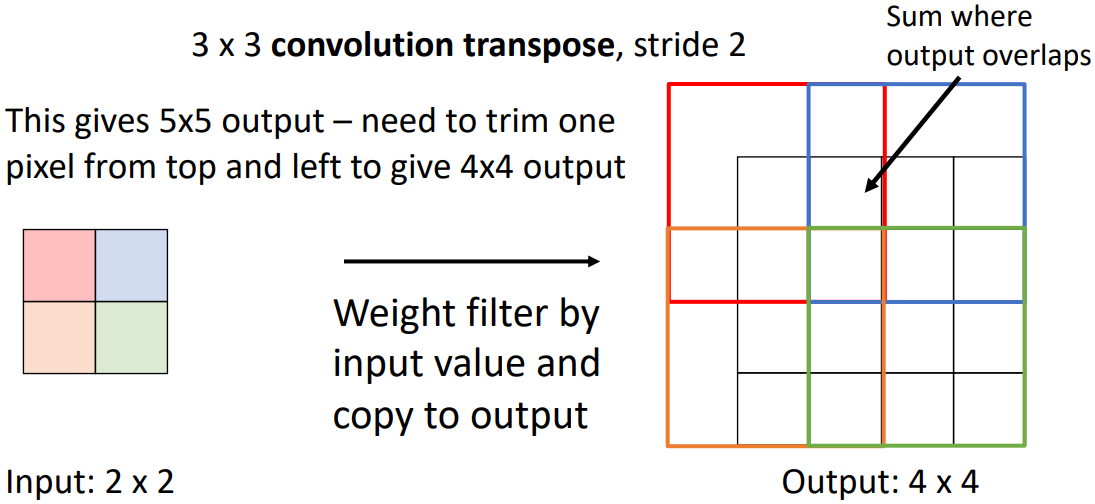
이 과정을 반복하면 위와 같은 결과를 얻을 수 있다. 마지막으로 padding에 해당하는 상단과 좌측의 픽셀 1칸씩을 제거하면 원하는 결과를 얻을 수 있다.
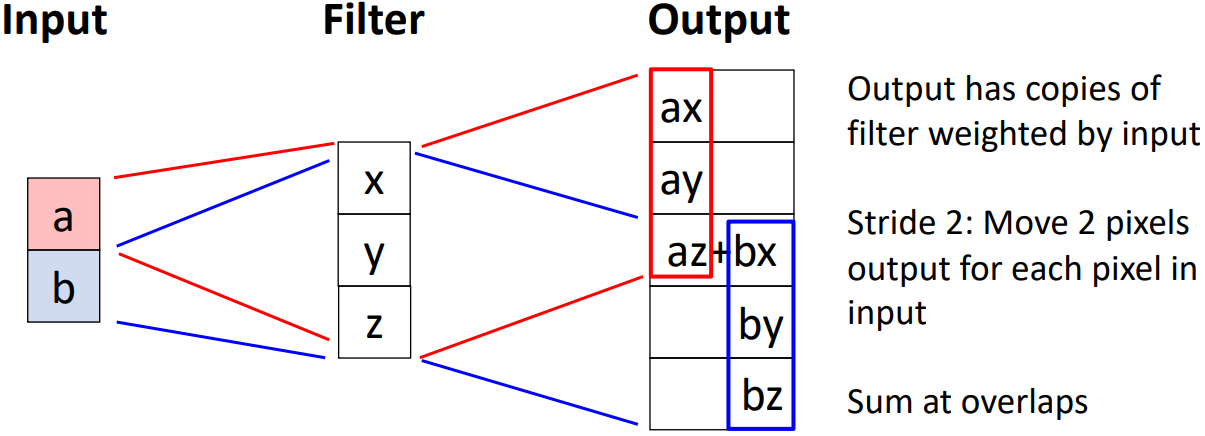
Transposed convolution을 좀더 쉽게 알아보기 위해 1차원으로 표현해 보면 위 그림과 같다. 필터에 각 input image 픽셀을 곱한 후 output image에 copy된다는 것을 알 수 있다.
Convolution as Matrix Multiplication
Transposed convolution를 알아보기 앞서, stride=2, padding=1인 일반 convolution을 matrix multiplication으로 표현해 보자.
$\begin{bmatrix} x & y & z & 0 & 0 & 0 \\ 0 & 0 & x & y & z & 0 \end{bmatrix} \times \begin{bmatrix} 0 \\ a \\ b \\ c \\ d \\ 0 \end{bmatrix} = \begin{bmatrix} ay + bz \\ bx + cy + dz \end{bmatrix}$
왼쪽 2x6 행렬이 필터에 해당하는 부분으로, matrix multiplication으로 convolution과 같은 효과를 내기 위해 형태를 변형한 것이다. stride가 2이기 때문에 첫 번째 열과 비교하여 두 번째 열이 오른쪽으로 2칸 이동하였다. 중간의 6x1 행렬이 input image에 해당하는 부분으로, padding이 1이기 때문에 위아래에 0이 추가되었다.
Transposed convolution을 matrix multiplication으로 표현하면 아래와 같다.
$\begin{bmatrix} x & 0 \\ y & 0 \\ z & x \\ 0 & y \\ 0 & z \\ 0 & 0 \end{bmatrix} \times \begin{bmatrix} a \\ b \end{bmatrix} = \begin{bmatrix} ax \\ ay \\ az + bx \\ by \\ bz \\ 0 \end{bmatrix}$
위의 1차원 transposed convolution 이미지와 같은 결과를 얻었다. 이때 output의 맨 위와 아래 element는 padding에 해당하는 부분으로, 이를 제거하면 크기가 4로 2배 upsampling된 결과를 얻을 수 있다.
이때 주목할 점은, 일반 convolution에 사용된 filter 행렬을 transpose한 것이 바로 transposed convolution에 사용된 filter 행렬이라는 것이다. Transposed convolution이라는 이름이 붙은 이유가 바로 이것 때문이다.
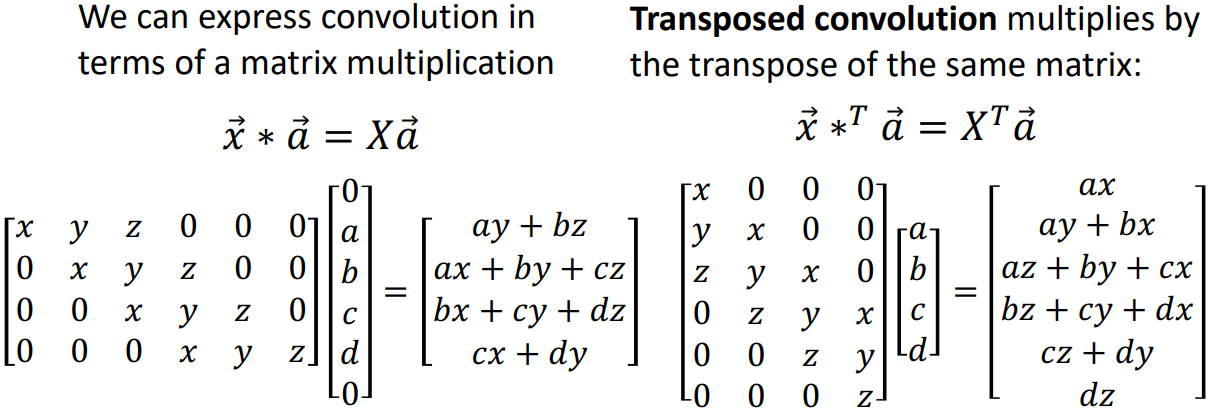
이해를 돕기 위해 stride=1인 convolution과 transposed convolution를 matrix multiplication으로 표현하면 위와 같다. Element들을 잘 살펴보면 위에 언급한 개념대로 동작하는 것을 알 수 있다.
위에 언급한 방식들 중 하나로 upsampling을 구현한 후, 모델을 학습시킬 때에는 Loss function으로 per-pixel cross entropy를 사용하면 된다.
Instance Segmentation
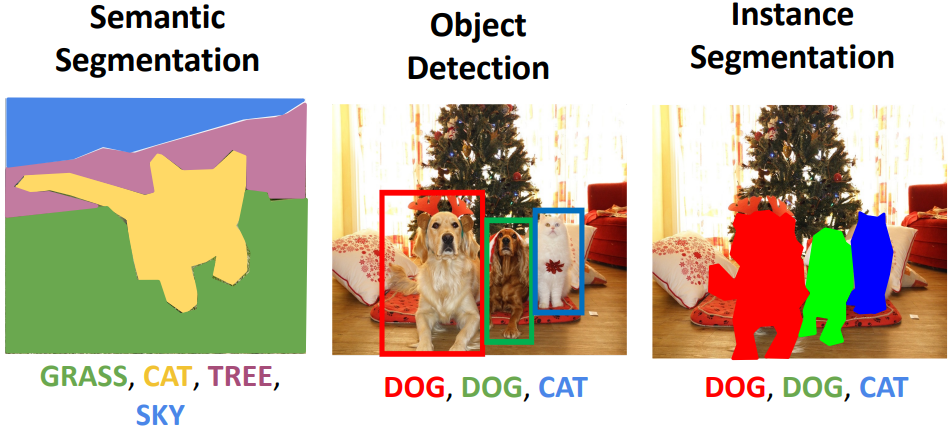
우선 컴퓨터 비전에서 물체를 분류하는 두 가지 카테고리인 'things'와 'stuff'에 대해 알아보자.
- Things: 셀 수 있는 물체로, 사람, 자동차, 책 등이 해당된다.
- Stuff: 셀 수 없는 물체로, 하늘, 물 등 뿐만 아니라 숲, 모래, 풀밭 등 구성요소 하나하나를 구분할 필요가 없는 것들도 포함된다.
Object detection은 'things'에 대해 localization을 하는 반면, semantic segmentation은 'things'까지도 각 물체로 취급하지 않고 하나의 'stuff'로 뭉뚱그려 처리한다. 이 둘을 융합한 개념인 Instance segmentation은 각 물체를 구분하고, 해당하는 물체에 대해서만 segmentation을 수행하는 것이다. 물체를 구분해야 하기 때문에 'things'에 해당하는 물체만을 segmentation할 수 있다.
Instance segmentation을 구현하는 방법은 꽤 직관적인데, 우선 object detection을 이용해 bounding box를 구한 후 각 box마다 semantic segmentation과 유사한 모델을 돌려 물체에 대한 mask를 얻는 것이다.
Mask R-CNN
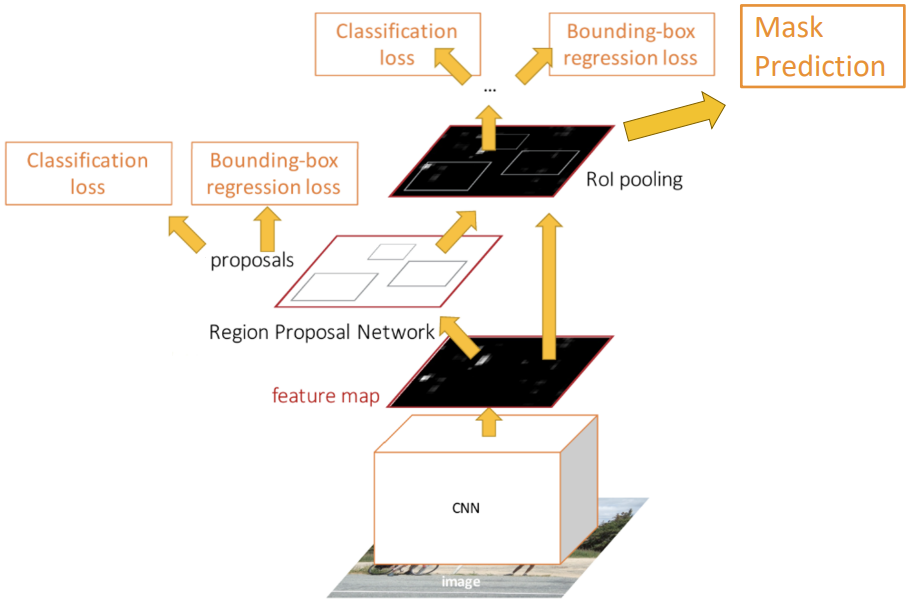
Instance segmentation 모델 중 하나로 Faster R-CNN을 기반으로 한 Mask R-CNN이 있다. Faster R-CNN의 per-region network에 mask를 생성하는 branch를 추가한 모델이다.
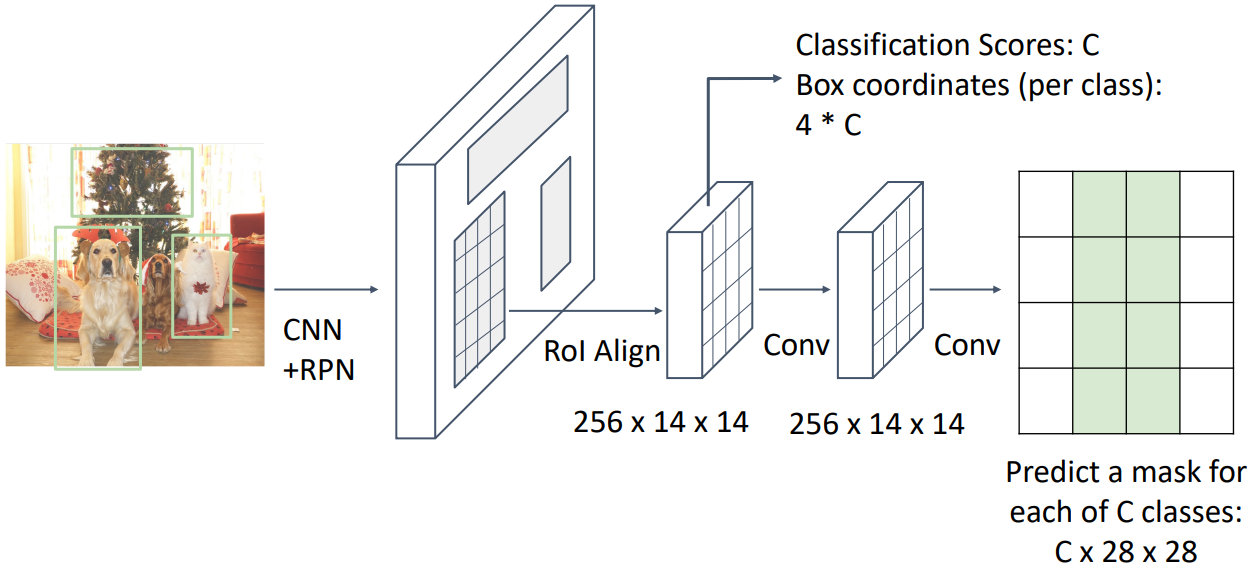
위 그림과 같이 RoI align을 통해 구한 각 영역에 대해 classification과 box regression을 수행함과 동시에 mask prediction까지 수행한다. 이때 모든 클래스에 대해 mask를 생성하고, classification으로 구한 클래스에 해당하는 mask만을 취한다. 학습할 때는 정답 클래스에 해당하는 mask만을 이용해 loss를 구한다.

Mask R-CNN을 이용해 얻은 결과는 위 그림과 같다. 매우 정확한 결과를 얻을 수 있기 때문에 현재까지도 많이 사용되는 모델이다.
Beyond Instance Segmentation
Mask R-CNN 모델과 같이 기존의 Faster R-CNN 모델에 새로운 branch를 추가하는 것만으로 완전히 새로운 문제를 해결할 수 있다. Instance segmentation 외에도 localization를 기반으로 한 다양한 문제가 존재한다. 이들에 대해 간단히 알아보자.
Panoptic Segmentation
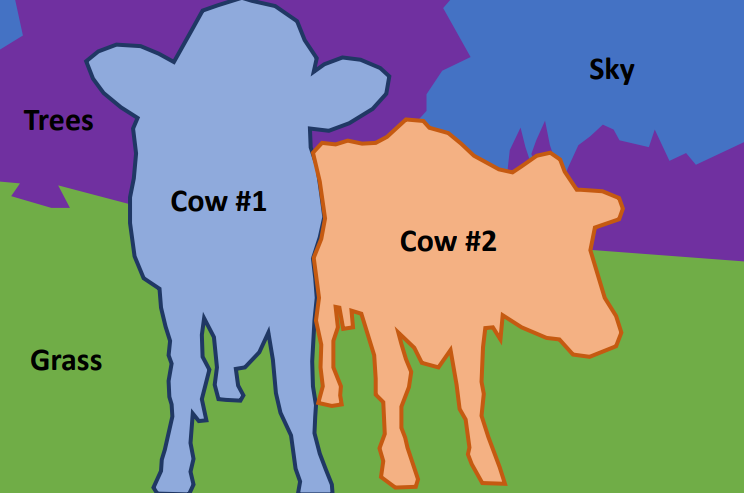
Panoptic segmentation은 instance segmentation에 'stuff'에 대한 구분까지 포함한 개념이다.
Human Keypoints

Human keypoints는 사람의 특정 부위에 대해 localization하는 문제이다. 사람의 얼굴, 손, 발 등이 어떤 픽셀에 위치하는지를 찾아낼 수 있다.
Dense Captioning
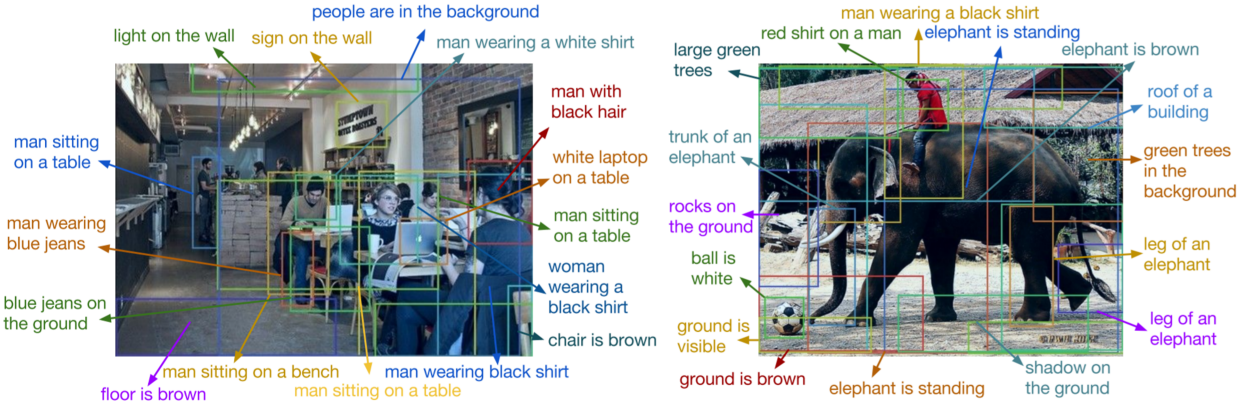
Dense captioning은 이미지 내의 모든 물체에 대해 caption을 생성하는 문제이다. Faster R-CNN 모델에 LSTM branch를 추가하는 방식으로 구현하였다.
3D Shape Prediction
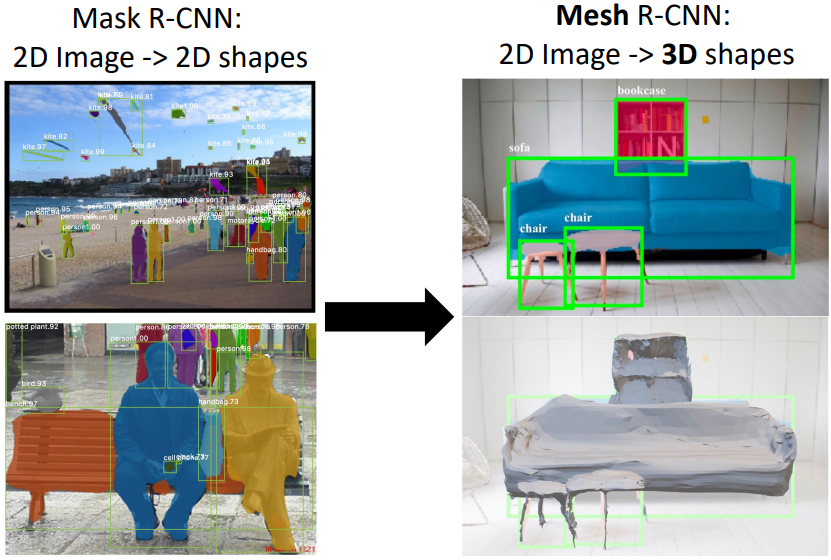
3D shape prediction은 2D 이미지를 보고 3D object의 형태를 예측하는 문제이다. 마찬가지로 mesh를 출력하는 branch를 추가해 구현하였다.
Summary
지금까지 object detection과 semantic segmentation에 대해 알아보았다. 이 둘은 컴퓨터 비전에서 가장 핵심적인 task로, 이 둘을 조합하여 다양한 새로운 문제들을 해결할 수 있다. 기존의 Faster R-CNN과 같은 two-stage detector에 새로운 branch를 추가하는 방식으로 새로운 문제에 맞는 모델을 구현할 수 있다. Single-stage detector는 object detection 외의 더 복잡한 문제에는 잘 사용되지 않는다.