Fast R-CNN
지난 강의에서는 R-CNN에 대해 알아보았다. 하지만 R-CNN 모델은 한 이미지당 2000개의 영역에 대해 각각 CNN을 실행해야 하므로 training과 test 모두에서 매우 느리다는 단점이 있다. 이때 CNN에서 가장 연산량이 많은 부분이 초반 몇 stage이므로, 이 점을 개선해 속도를 높인 Fast R-CNN이 등장하게 된다.
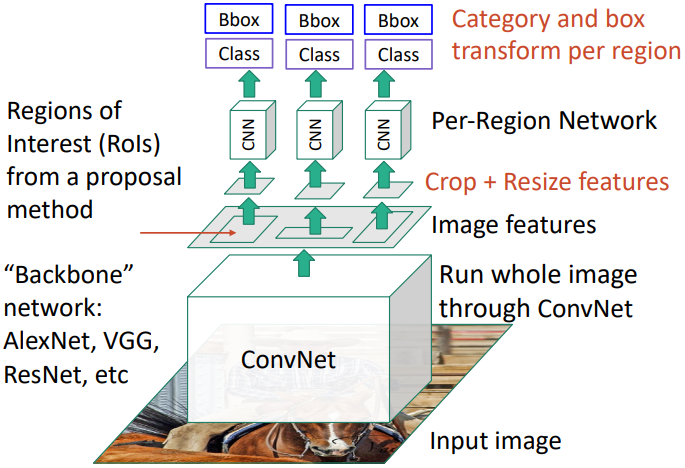
Fast R-CNN은 이미지 전체에 대해 CNN을 한 번만 실행하고, 추출된 feature map 상에서 RoI(Regions of Interest)를 구하는 방식을 사용한다. 연산량이 많은 초반 conv layer 단계들은 첫 단계에 포함하고, 이후 각 영역에 대해 fully connected layer만을 사용하거나 마지막 stage만을 사용하여 각 영역에 대한 class score와 bounding box를 예측한다. 이 FC layer는 R-CNN에서 이미지 영역 자체를 입력받는 모델에 비해 훨씬 가볍고 빠르게 동작한다.
이때, region proposal은 여전히 RGB 이미지를 이용하는 고전적인 방식을 사용한다. Fast R-CNN은 feature map 상에서 영역을 crop해야 하는데, region proposal을 feature map에 어떻게 대응시킬 수 있을까?
Projecting Bounding Boxes
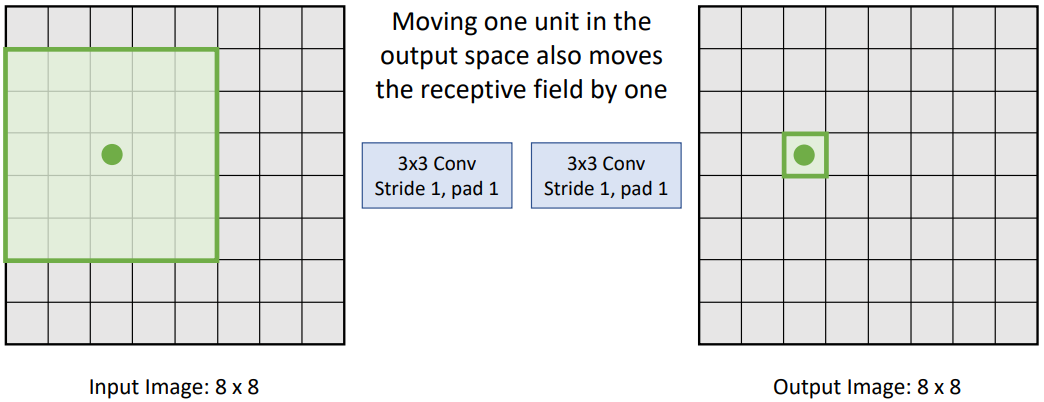
위 사진과 같이 output image의 특정 점에 대해 input image에서의 receptive field를 얻을 수 있다. input과 output 사이에 어떤 layer가 있든, 이미지의 크기가 유지된다면 receptive field의 중심은 항상 output image의 점과 같은 위치에 있다.
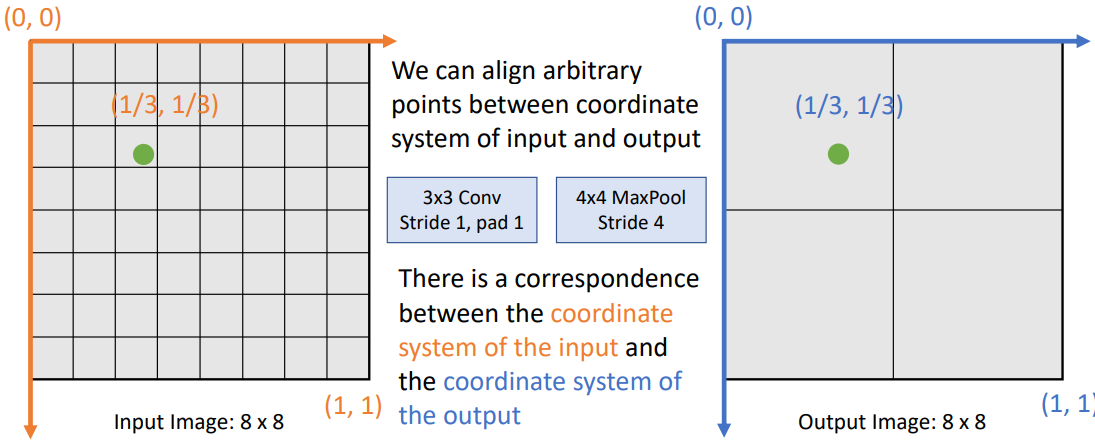
이미지의 크기가 달라진다면, 좌표의 절대적인 값은 달라지겠지만 output image의 특정 점에 대해 input image상에 대응되는 한 점은 항상 특정할 수 있을 것이다.
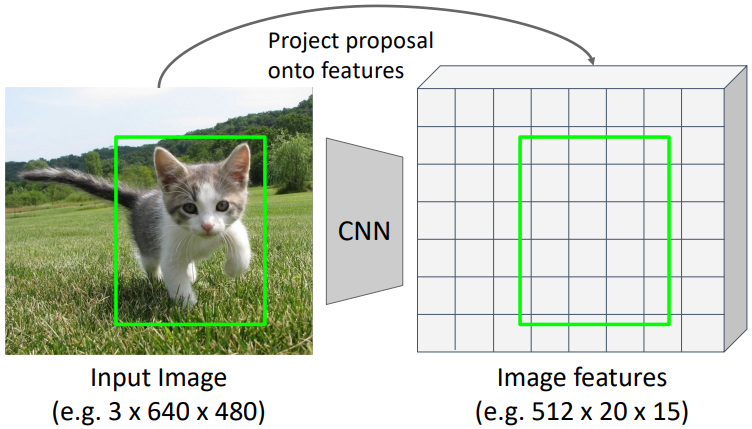
이를 직사각형의 모든 꼭짓점에 대해 적용하면 RGB 이미지 위의 region proposal을 feature map 상으로 그대로 옮길 수 있다. RoI pooling이 된다. 이때, Region proposal을 통해 얻은 영역은 그 크기가 제각각일 것이다. CNN은 정해진 크기의 이미지만을 입력으로 받을 수 있으므로 R-CNN에서는 모든 영역을 224x224로 resize하였다. 이와 유사하게 Fast R-CNN에서도 crop된 feature map을 고정된 크기로 resize하여 사용한다. 보통 7x7이나 14x14로 resize한다. 이때 사용되는 방법이 RoI pooling과 RoI aligning이다.
RoI Pooling
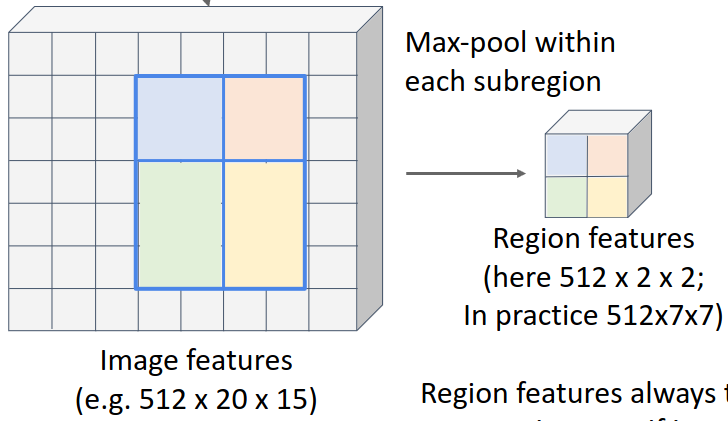
RoI pooling은 가장 먼저 RoI의 꼭짓점 좌표를 정수로 반올림하여 격자에 딱 맞게 한다. 이미지의 resolution이 달라질 경우 bounding box를 feature map을 옮겼을 때 좌표값이 소수점이 될 수 있기 때문이다. 이후 단순히 직사각형을 최대한 균일하게 7x7 또는 14x14의 영역으로 분할하고, 각 영역의 최댓값을 구하는 max pooling을 적용한다. 이 방법을 통해 어떤 크기나 비율을 가진 직사각형이라도 일정한 크기로 resize할 수 있다.
하지만 RoI pooling에는 두 가지의 문제점이 있다.
- 꼭짓점의 좌표를 반올림하여 강제로 격자에 맞추기 때문에, 이 과정 자체가 오차를 발생시키게 된다.
- 7x7이나 14x14개의 영역으로 분할하는 과정에서 각 변의 픽셀 수가 정확히 나누어떨어지지 않으면 위 예시와 같이 균일하지 않게 분할된다.
RoI Aligning
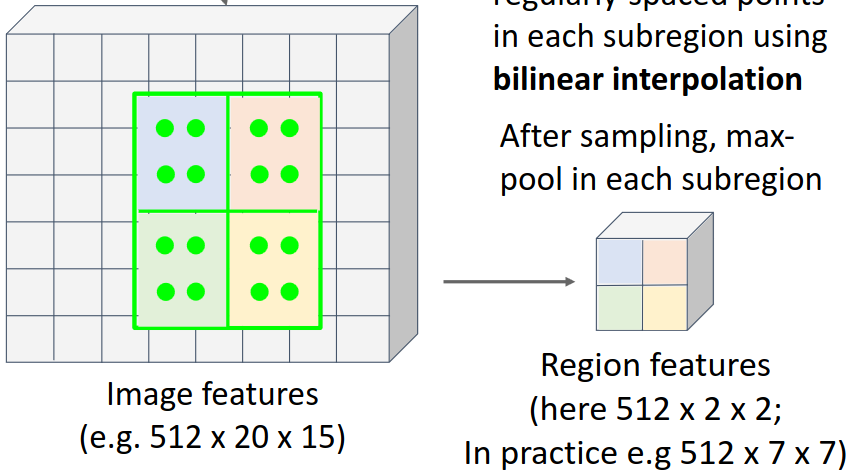
RoI aligning은 RoI pooling의 문제점을 해결하기 위해 등장한 방법이다. RoI aligning은 소수점 좌표를 반올림하는 대신 bilinear interpolation을 이용하여 위 두 문제를 동시에 해결하였다.
먼저 직사각형을 위와 동일하게 7x7 또는 14x14로 분할한다. 좌표값이 정수가 되지 않아도 되기 때문에 완벽하게 동일한 크기로 분할할 수 있다. 이후 각 영역의 대표값을 구해야 하는데, 픽셀값 자체를 이용하는 max pooling이 아니라 먼저 각 영역에 대해 고르게 샘플 점들을 분포시킨다. 위 그림은 RoI를 균일하게 4개의 영역을 나누고 각 영역에 대해 4개의 샘플 점을 배치한 것이다.
이때 이 샘플 점들 또한 정수 좌표값을 갖지 않을 수 있다. 따라서 각 샘플 점에 대해 bilinear interpolation을 이용하여 각 점에 대한 값을 구하고, 이 샘플 점들에 대해 max pooling을 적용하여 최종적으로 각 영역의 대표값을 구한다. Bilinear interpolation의 구체적인 과정은 아래와 같다.
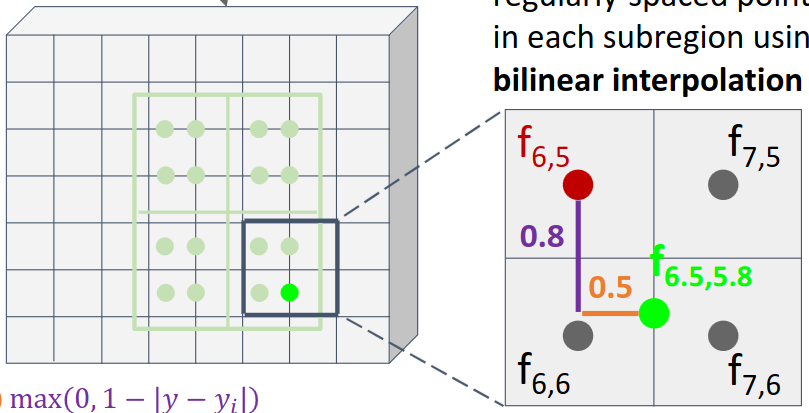
위와 같이 점 $(6.5, 5.8)$에서의 값을 구하고자 할 때, 먼저 가장 가까운 네 점 $(6, 5), (6, 6), (7, 5), (7, 6)$의 값을 구한다. 이후 각 점에 대해 거리에 반비례하는 가중치를 부여하여 값을 계산한다.
$f_{6.5, 5.8} = (f_{6, 5} \cdot 0.5 * 0.2) + (f_{7, 5} \cdot 0.5 * 0.2) + (f_{6, 6} \cdot 0.5 * 0.8) + (f_{7, 6} \cdot 0.5 * 0.8)$
이를 일반적인 수식으로 나타내면 아래와 같다.
$f_{x, y} = \sum_{i, j=1}^{2} f_{x_i, y_j} \cdot \max(0, 1 - |x - x_i|) \cdot \max(0, 1 - |y - y_j|)$
이러한 RoI aligning 방식은 RoI pooling보다 훨씬 더 흔하게 사용된다.
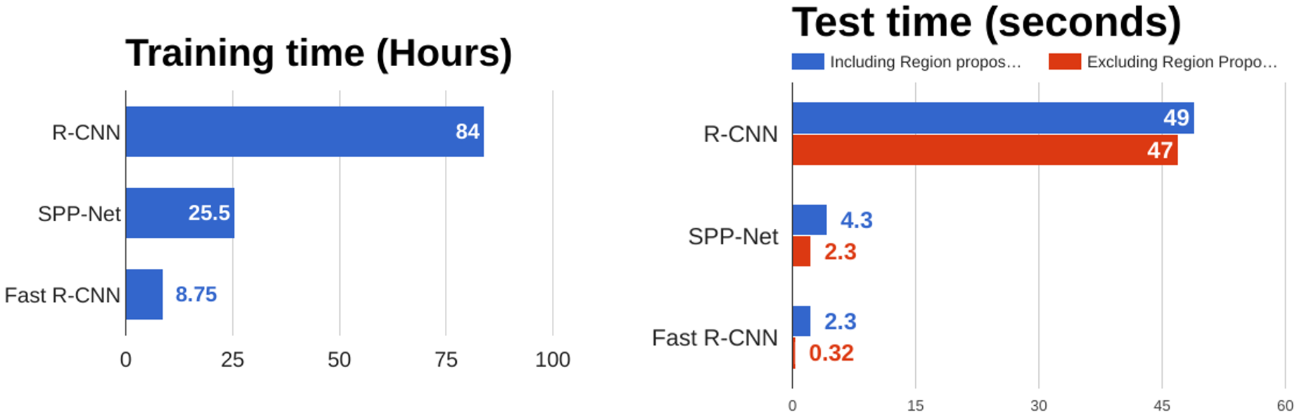
Fast R-CNN과 기존 R-CNN의 training/test time을 비교하면 위와 같다. Fast R-CNN은 R-CNN에 비해 학습 시에는 약 10배, test 시에는 약 20배 빠른 것을 알 수 있다. 또 하나의 주목할 점으로는, Fast R-CNN에서는 bottleneck이 더 이상 conv layer가 아니라 전통적인 방식의 region proposal이 되었다는 점이다.
Faster R-CNN
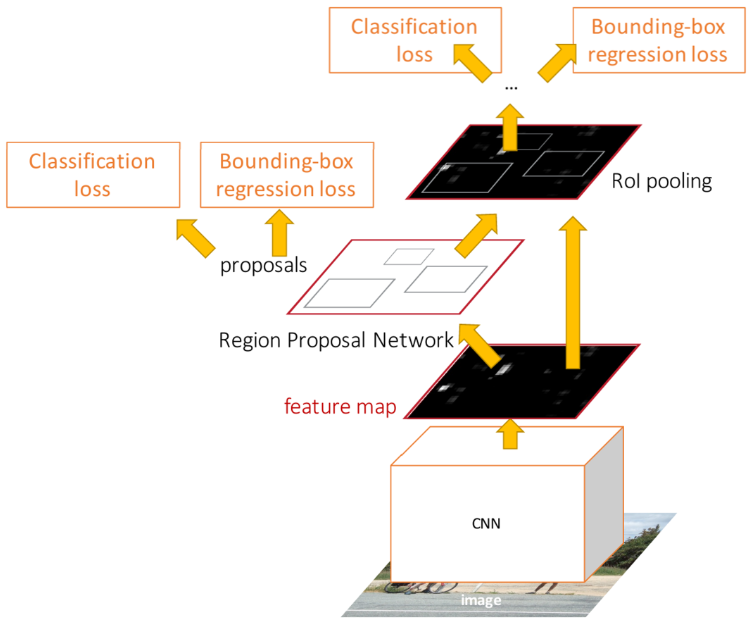
앞서 언급한 Fast R-CNN의 문제점을 해결하기 위해 region proposal을 기존의 알고리즘 대신 CNN 모델로 대체하여 그 속도를 다시 한 번 높인 것이 Faster R-CNN이다. 이를 Region Proposal Network(RPN)이 담당한다. 기존 Fast R-CNN에서도 사용되었던 backbone network에서 image feature map가 나오면, 이를 RPN에 입력으로 넣어 region proposal을 얻는다. 이미 사용되고 있는 모델의 출력을 이용하기 때문에 추가적인 연산량이 거의 발생하지 않는다. 최종적으로 RPN의 출력으로 나온 RoI에 대해 Fast R-CNN과 동일한 방식으로 classification과 bounding box regression을 수행한다.
Region Proposal Network (RPN)

RPN은 위의 오른쪽 이미지에 해당하는 feature map을 입력으로 받는다. 이 Feature map의 각 픽셀에 대해 원본 이미지에 대응되는 점을 구하고, 이 점을 중심으로 특정 크기의 bounding box를 그린다. 이를 anchor box라고 한다. RPN은 각 anchor box가 물체를 잘 포함하는지 아닌지에 따라 대응되는 feature map 상 픽셀을 positive와 negative로 binary classification한다. GT box는 RGB 이미지를 기준으로 제공되기 때문에 이러한 우회적인 방법을 사용하는 것이다. 이때 anchor box의 크기는 hyperparameter이다.
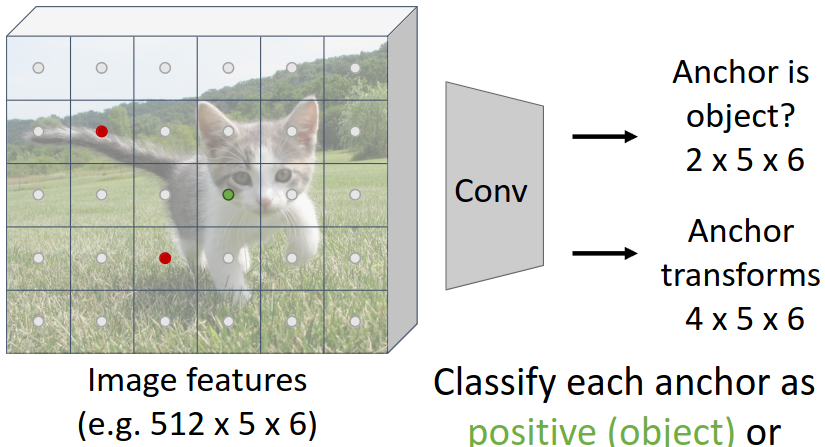
이를 위해 RPN은 conv layer로 구성되며 위 그림에서 입력이 512x5x6이라면 출력은 2x5x6이 된다. 각 픽셀이 positive일지 negative일지를 binary classification하였기 때문에 이러한 shape가 된다. 한 Anchor box와 어떤 GT box 사이의 IoU가 0.7보다 크면 그 anchor box는 positive로 분류되고, 모든 GT box와 가장 IoU가 높은 anchor box 또한 positive로 분류된다. IoU가 0.3보다 작은 anchor box는 negative로 분류된다. 이때 각 anchor box가 어떤 카테고리의 GT box와 매칭되는지는 고려하지 않는다.
Classification뿐만 아니라, RPN 네트워크를 이용해 bounding box regression까지 수행한다. 각 anchor box에 대해 GT box와의 차이를 regression하여 bounding box를 조정하는 것이다. 이때, anchor box와 GT box의 transform에 해당하는 $t_x, t_y, t_w, t_h$를 구하는 것이 목표이다. 따라서 classification과 별개의 branch를 구성하여 transform을 구한다. 따라서 output shape는 4x5x6이 된다.

또한, 실제로는 각 점당 크기와 비율이 다른 k개의 anchor box를 동시에 사용한다. 이에 따라 classification output은 2kx5x6, transform output은 4kx5x6이 된다. 이때, k는 hyperparameter이다.
Test 시에는, 각 anchor box에 대해 classification score와 transform을 구하고 transform를 이용해 bounding box regression을 수행한다. 이후 NMS를 적용하여 중복을 제거하고, 남은 bounding box에 대해 positive일 확률이 높은 상위 300개를 선택하여 최종적인 region proposal을 얻는다.
정리하면, Faster R-CNN은 총 4개의 Loss를 사용한다. 먼저 RPN의 classification loss와 transform loss, 그리고 per-region network의 classification loss와 transform loss이다. 이를 jointly training하여 최종적으로 Faster R-CNN을 학습시킨다.
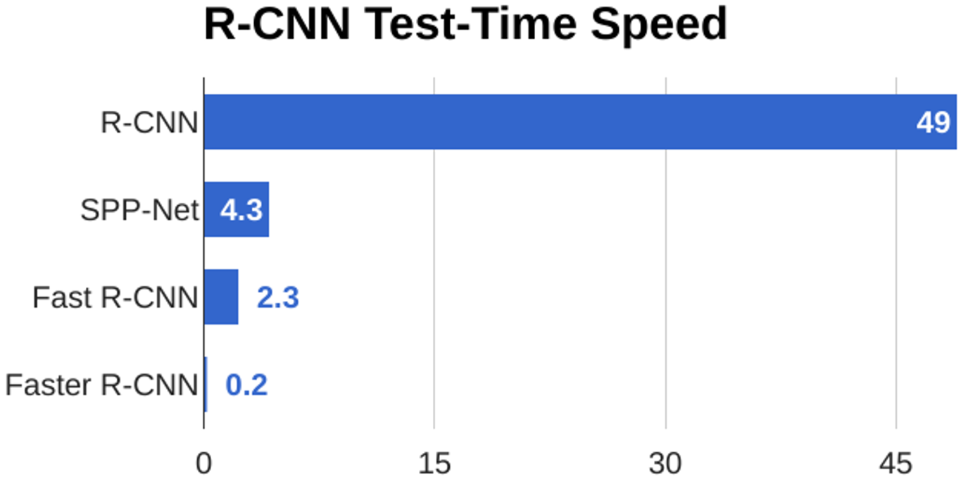
Faster R-CNN은 Fast R-CNN에 비해 test 시 약 10배 빠른 것을 알 수 있다. 그 이유는 RPN이 이미 계산된 feature map을 입력으로 받는 2개 정도의 작은 conv layer이기 때문이다. 따라서 원본 이미지 전체를 다루는 selective search 등의 방법보다 훨씬 효율적이다.
Dealing with Scale: Feature Pyramid Network
한 이미지에는 같은 물체더라도 위치에 따라 크게 보일 수도, 작게 보일 수도 있다. 이러한 scale에 대한 invariance를 얻기 위해, 다양한 크기의 물체를 학습시키기 위한 방법이 등장했다.
우선 이미지 자체를 다양한 scale로 resize한 다음 각각의 resolution에 맞춰진 CNN을 학습시키는 방법이 있지만 이는 매우 비효율적이다.
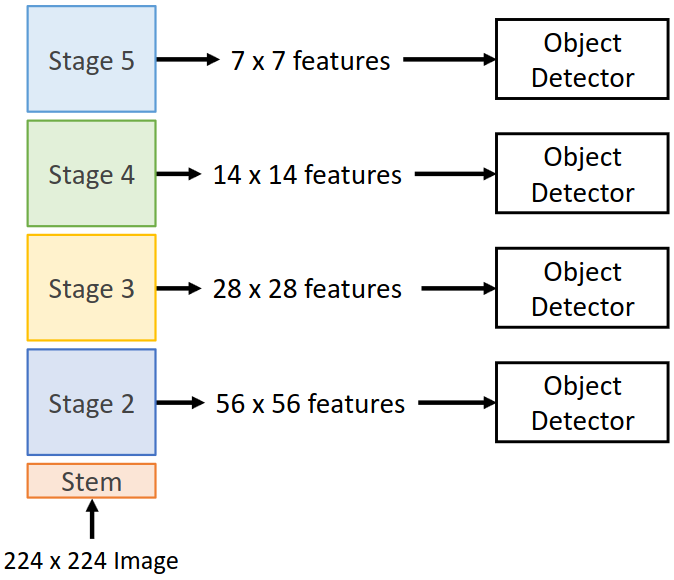
이보다 나은 방법으로 Multiscale features를 이용하는 방법이 있다. 이는 CNN의 각 stage에서의 중간 output을 이용하는 방법으로, 각 stage를 거칠 때마다 이미지의 resolution이 절반씩 줄어드는 설정을 이용하였다. 이러한 output들을 크기별 RPN에 입력한 후 출력되는 RoI들을 한데 모아 per-region network에 입력시킨다. 그러나, 초기 layer에서 나온 output은 high-level feature를 포함하지 않는다는 문제가 있다.
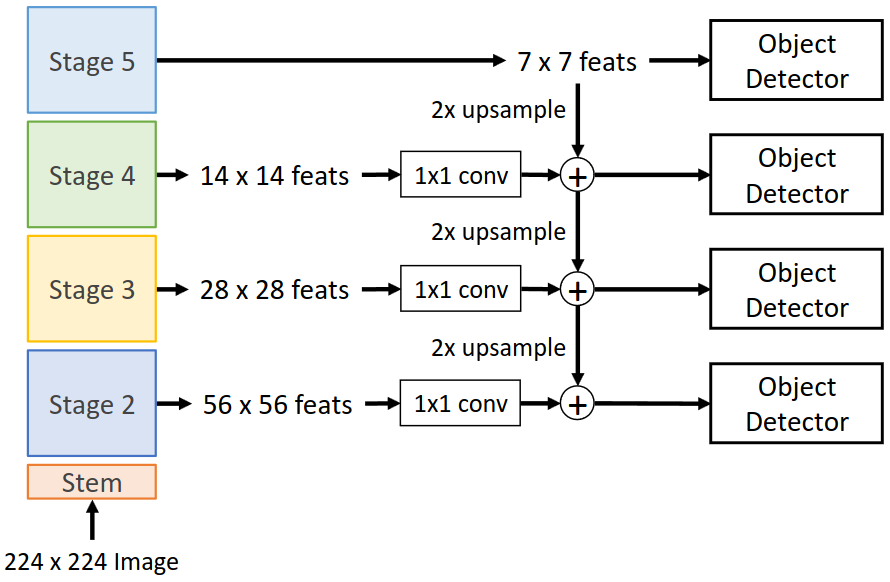
이 문제를 해결하기 위한 방법으로 Feature Pyramid Network(FPN)이 제안되었다. 원본 이미지를 네트워크에 통과시키며 중간 stage의 output을 저장해 두고, 마지막 stage의 output까지 얻는다. 위 그림에서 7x7 크기인 최종 output은 바로 RPN과 같은 object detector에 입력한다. 중간 stage output의 경우 상위 stage output과 순차적으로 더해지며 high-level feature를 포함하게 된다. 이때 upsampling이나 1x1 conv 등 shape의 조절을 거친다. 이후 각 feature map의 크기에 맞는 별개의 RPN에 입력한다. 이 과정을 통해 모든 크기의 feature map을 전체 네트워크를 이용해 연산한 것과 같은 효과를 얻을 수 있다. FPN은 추가적으로 소요되는 연산이 매우 적기 때문에 scaling 문제를 해결하기 위해 거의 대부분의 모델에 사용되는 방법이다.
RetinaNet
Two-Stage Detector vs. Single-Stage Detector
지금까지 알아본 Fast R-CNN과 Faster R-CNN은 모두 이미지 전체에 대해 연산을 수행하는 backbone network와, 각 RoI에 대해 연산을 수행하는 per-region network로 구성되어 있다. 이처럼 두 단계의 별개의 네트워크로 구성되어 있기 때문에 이들은 two-stage detector라고 불린다. 반대로 per-region network 없이 이미지 전체에 대한 하나의 네트워크만 이용하여 detection을 수행하는 방법도 있는데, 이들을 single-stage detector라고 한다.
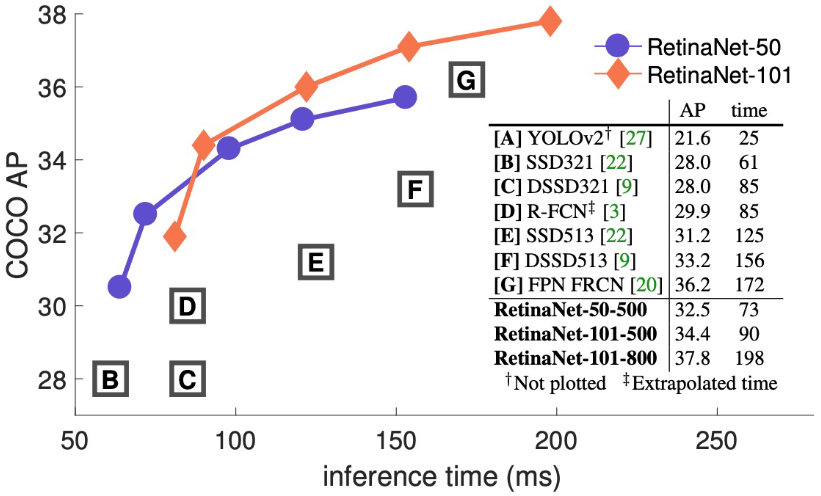
위 그래프에서 single-stage detector는 two-stage detector에 비해 빠르면서 정확도도 높은 것을 알 수 있다.
RetinaNet

RetinaNet은 single-stage detector의 일종이다. RPN과 유사하게 anchor를 이용하는데, 우선 위의 왼쪽 그림과 같이 각 anchor point에 대해 anchor box를 설정한다. 이후 각 box에 대해 classification과 bounding box regression을 수행한다.
이때 RPN에서는 각 anchor box가 물체를 포함하는지 아닌지를 binary classification했다면, RetinaNet은 각 anchor box에 대해 카테고리별로 score를 구한다. 이에 따라 classification output은 $K \cdot (C +1) \times 5 \times 6$이 된다. Background까지 class에 포함하기 때문에 $C + 1$을 곱한다. Bounding box regression은 RPN과 동일하게 수행한다. 이를 통해 하나의 stage만으로 detection을 수행할 수 있다.
이때, 대부분의 anchor box는 물체를 포함하지 않기 때문에 background에 해당하는 box들이 매우 많아질 수 있다. 이와 같은 training sample의 불균형은 학습을 방해할 수 있다. 이를 해결하기 위해 cross-entropy 대신 Focal Loss라는 새로운 loss function을 사용한다. 두 loss function의 수식은 아래와 같다.
$\begin{align*} CE(p) & = -\log(p) \\ FL(p) & = -(1 - p)^\gamma \cdot \log(p) \end{align*}$
마지막으로 FPN까지 사용하여 여러 크기의 물체를 detect하게 된다.
FCOS
Anchor box는 성능은 좋지만 실제 코드로 구현하기 불편하며 anchor box의 크기나 비율을 어떻게 설정할지에 대한 추가적인 hyperparameter가 필요하다. 이를 해결하기 위해 anchor box를 사용하지 않는 FCOS가 등장하였다.

FCOS는 anchor box 대신 anchor point 자체를 사용한다. 위의 왼쪽 이미지와 같이 cat 카테고리의 GT box가 있을 때, 그 box 내부에 anchor point가 속하면 그 점은 positive, 외부에 속하면 negative로 labeling한다. 한 anchor point가 여러 box에 속할 경우, 그중 가장 작은 box에 매칭시킨다.
카테고리를 구분하여 모든 point를 labeling하면, $C \times 5 \times 6$의 결과를 얻을 수 있다. 이때 C개의 독립된 binary classification problem으로 생각한다. Training은 per-category logistic regression을 사용하여 진행한다.
Bounding box regression 단계에서는 box의 경계선이 해당 점으로부터 상하좌우로 얼마나 떨어져 있는지를 예측한다. 위 왼쪽 그림에서 T, B, S, R 4개의 값을 예측한다. 이때 카테고리와 관계없이 그 점이 속한 가장 작은 box에 regression한다. L2 loss를 이용해 학습시키게 된다.
이때, GT box의 중심에 있는 anchor point는 실제로 물체 안에 속할 확률이 높지만 GT box의 경계에 위치한 point들은 물체의 외부에 있어 regression의 결과가 좋지 않을 수 있다. 따라서 물체가 GT box의 중심에 있는 정도인 centerness를 도입하여 regression의 결과를 얼마나 신뢰할지 결정한다. Centerness는 0부터 1 사이의 값으로, 1에 가까울수록 bounding box의 중심에 물체가 위치할 가능성이 높다. 아래의 수식을 통해 GT centerness를 구할 수 있다. Centerness의 학습은 logistic regression loss를 사용한다.
$centerness = \sqrt{\cfrac{\min(L, R)}{\max(L, R)} \cdot \cfrac{\min(T, B)}{\max(T, B)}}$
Test 시에는 각 anchor point에 대해 class score, bounding box edges, centerness를 각각 예측한다. 이후 class score와 centerness를 곱하여 confidence 값을 구한다. 이후 confidence에 threshold를 적용하는 등 가능성이 높은 box만을 선택한다.
FCOS 또한 FPN을 사용한다. 질문: But 구현은 어떻게 되는지?
Mean Average Precision (mAP)
Mean Average Precision(mAP)은 object detection 모델의 성능을 측정하는 지표 중 하나이다. mAP는 아래의 세 단계로 구성된다.
- 모든 test set에 대해 detection을 수행한다. 이때 NMS를 적용하여 중복된 bounding box를 제거한다.
- 각 카테고리에 대해 Average Precision(AP)을 구한다. AP는 Precision-Recall curve의 아래 면적을 의미한다.
- 모든 카테고리에 대해 AP의 평균을 구한다.
위의 2번 단계에서, Precision-Recall curve를 그리는 과정을 예시를 통해 알아보자. 우선 Precision과 Recall의 정의는 다음과 같다.
$Precision = \cfrac{\text{# of matched predicted boxes}}{\text{# of predicted boxes we considered}}$
$Recall = \cfrac{\text{# of matched GT boxes}}{\text{Total # of GT boxes}}$

먼저 위 그림과 같이 모든 test set에 대해 모델이 예측한 box와 GT box를 모으고, 모델이 예측한 box는 모델이 별도로 예측한 score 값을 이용해 정렬한다.
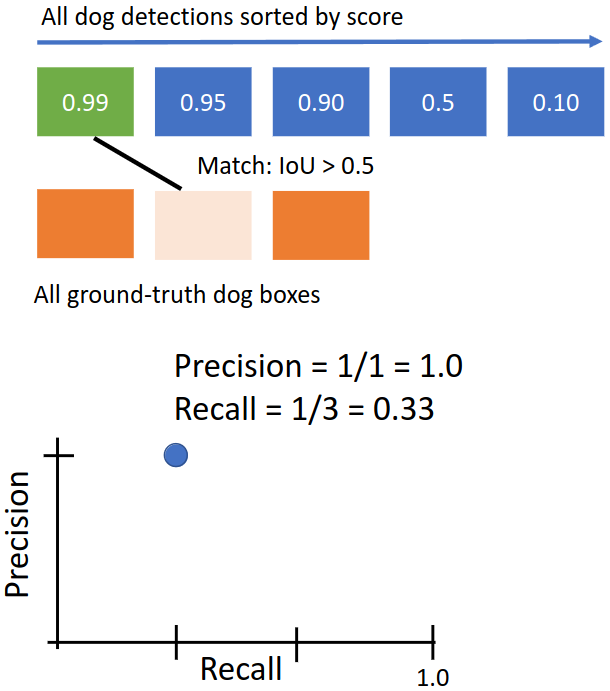
이후 score가 가장 높은 box부터, 그 box와 같은 이미지에 있으면서 IoU가 가장 큰 GT box를 찾는다. 이때 IoU가 0.5보다 큰 GT box가 없을 경우 negative로 처리한다. 위 경우 첫 번째 예측된 box와 두 번째 GT box가 매칭되었다. 매 매칭마다 Precision과 Recall을 계산한다.
현재까지 다룬 predicted box는 1개이고 그중 1개가 매칭되었으므로 precision은 1이다. 또한 총 3개의 GT box 중 1개가 매칭되었으므로 recall은 1/3이다. 따라서 (1, 1/3) 지점에 점을 찍을 수 있다.
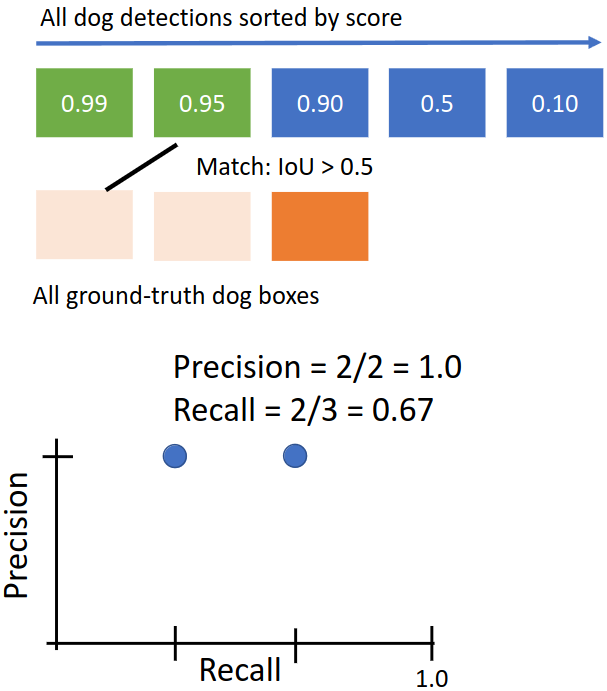
매칭된 GT box는 제외하고 두 번째 predicted box로 넘어간다. 이 경우도 매칭이 되었다. Precision은 2/2 = 1, recall은 2/3이 된다.
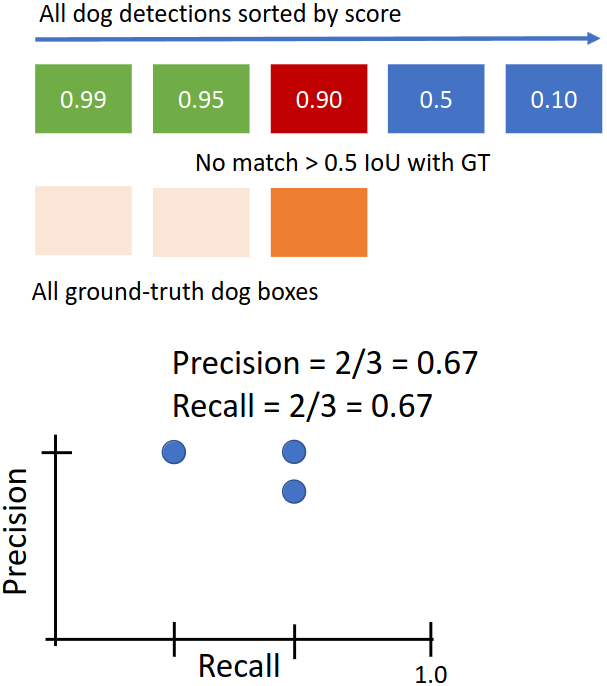
세 번째 predicted box의 경우 모든 GT box와의 IoU가 0.5보다 작아 매칭되지 않았다. 따라서 precision은 2/3, recall은 2/3이 된다.
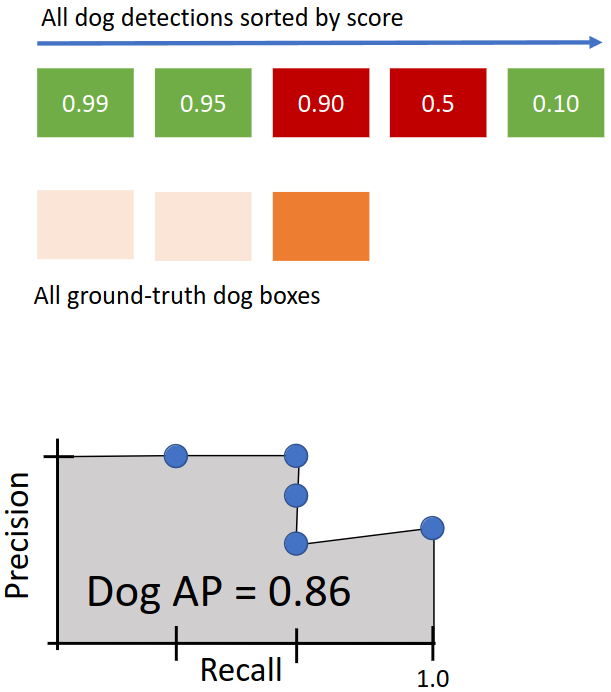
같은 과정을 반복하면 위의 그림과 같이 Precision-Recall curve를 얻을 수 있다. 이때 AP는 Precision-Recall curve의 아래 면적을 의미한다. 따라서 AP = 1이 되기 위해서는 모든 GT box가 매칭되어야 하고, 마지막 매칭이 이루어지기까지 negative가 단 하나라도 있어서는 안 된다.
위 예시에서는 IoU의 threshold를 0.5로 설정하였다. 따라서 이를 mAP@0.50이라고 부른다. mAP에서 더 나아간 COCO mAP의 경우 여러 threshold 값에 대해 mAP를 구하고 다시 이에 대한 평균을 구한다. mAP@0.50, mAP@0.55, mAP@0.60, ..., mAP@0.95를 구한 후 이들의 평균을 구한다.