Transfer Learning
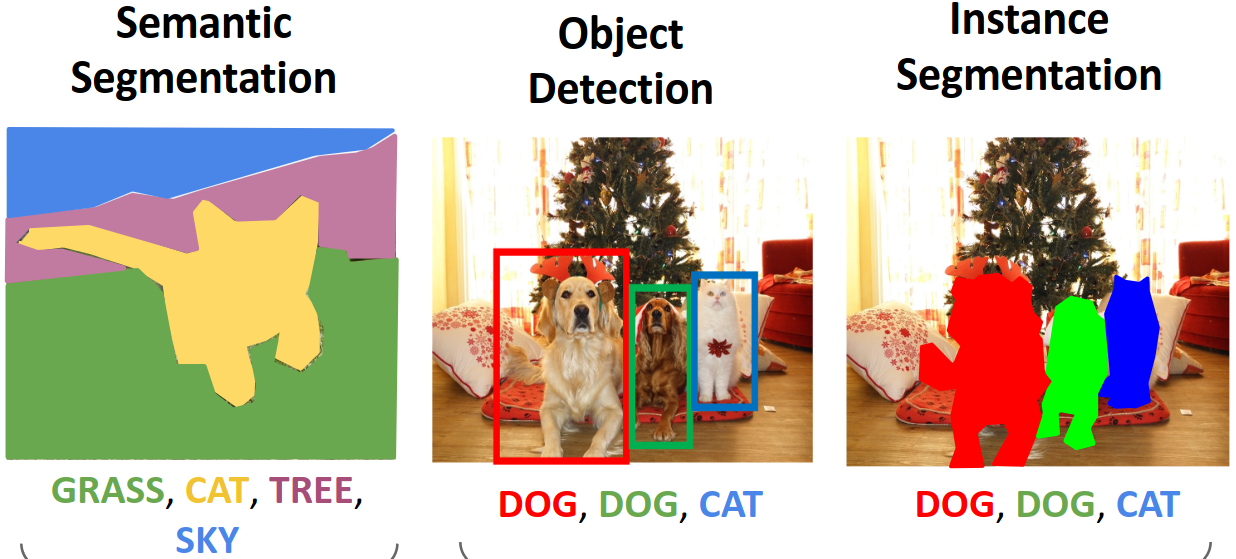
지금까지 우리는 CNN을 통해 image classification이라는 가장 기본적인 task를 해결하는 방법을 공부했다. 하지만 실제로는 object detection, semantic segmentation, instance segmentation 등 다양한 task가 존재한다. 이러한 다양한 task에 기존에 배운 architecture를 적용하여 보다 효율적으로 네트워크를 학습시키는 방법이 바로 transfer learning이다.
실제로 image classification을 위해 학습된 모델을 가져와서 특정 동물을 구분하는 task에 적용했을 때 기존에 사람이 직접 hand-tune한 모델보다 더 좋은 성능을 보이기도 했다. Transfer learning은 오늘날 computer vision으로 문제를 해결하는 모든 곳에 사용된다.
Transfer Learning은 기존에 어떤 task를 위해 학습된 모델을 가져와서 새로운 task에 적용하는 방법이다. Transfer Learning을 통해 다양한 종류의 task를 해결할 수 있고, 학습의 수렴 속도도 더 빨라진다. 구체적인 Transfer Learning의 방법으로는 Feature extraction과 Fine-tuning이 있다.
Feature Extraction

Feature extraction은 기존에 ImageNet 데이터셋 등으로 학습된 모델을 가져온 후, classification을 담당하는 마지막 layer만을 제거하고 새로운 task에 맞는 layer를 추가하는 방법이다. 위 그림은 VGG 모델에서 1000개의 class로 분류를 수행하는 마지막 linear layer만을 제거한 모습이다. 학습 시에는 backbone network의 weight를 고정시키고 추가한 layer만을 학습시킨다. 이를 통해 적은 데이터로도 훨씬 높은 성능을 얻을 수 있다.
또한 모델 맨 마지막에 linear model만 추가하기 때문에 이를 gradient descent가 아닌 convex optimization으로 풀 수 있다. 따라서 훨씬 효율적인 학습이 가능하다.
Fine-tuning
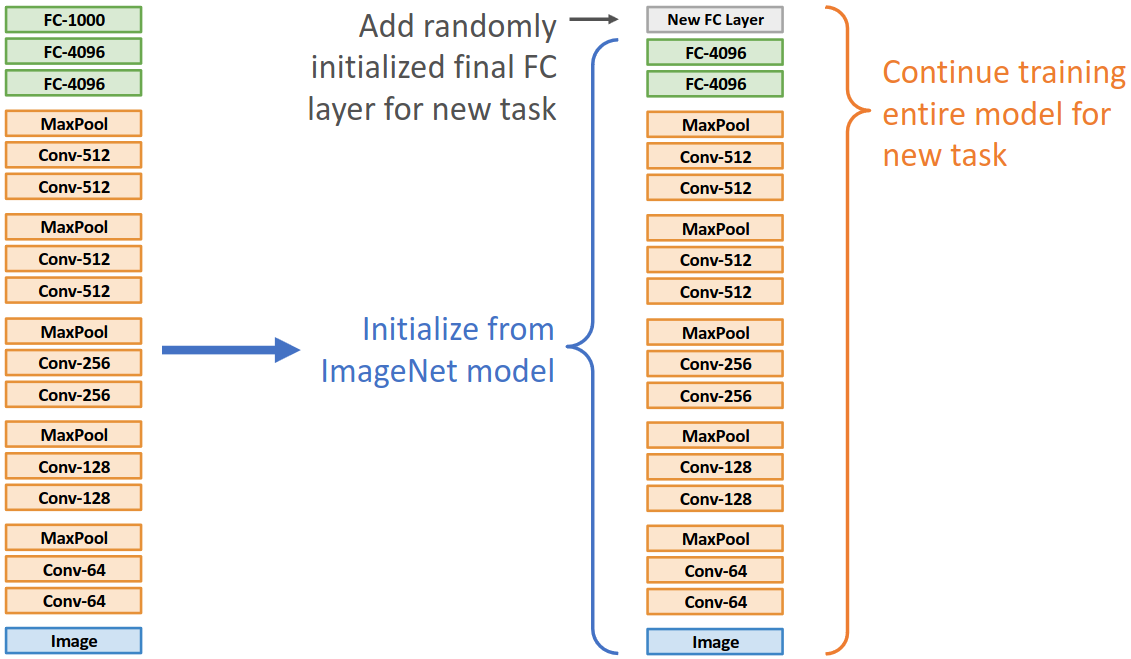
Fine-tuning은 기존에 학습된 모델을 가져온 후, 전체 layer를 주어진 task에 맞게 학습시키는 방법이다. 이때 backbone network는 기존에 가져왔던 weight 그대로 시작하고, 새로 추가한 layer만 random initialize한다. 학습 데이터가 많은 경우 Fine-tuning 방식을 사용하면 feature extraction 방식보다 더 좋은 성능을 얻을 수 있다.
Fine-tuning을 할 때는 아래의 몇 가지 trick이 있다.
- 처음에는 feature extraction 방식과 동일하게 backbone network는 freeze시키고 추가한 layer만 학습시킨다. 처음부터 전체 네트워크를 학습시키면 마지막 layer의 gradient가 너무 random하여 이전 layer들의 파라미터까지 크게 변화시킬 수 있기 때문이다.
- Learning rate를 backbone network에서 사용한 값의 1/10으로 설정한다. 이 또한 위와 같은 이유이다.
- 모델의 초반부는 freeze시킨 채로 나머지 layer들만 학습시키기도 한다. 이는 연산량과 메모리 사용을 줄이기 위해서이다. 가장 초반 layer들은 높은 해상도에서 feature를 추출하기 때문에 연산량과 메모리 사용이 많다.
- Batch normalization을 test mode로 하여 학습을 진행한다. 이 또한 연산량과 메모리 사용을 줄이기 위함이다.
Fine-tuning 방법은 feature extraction 방법에 비해 더 많은 데이터와 연산량을 필요로 하지만, 더 좋은 성능을 얻을 수 있다.
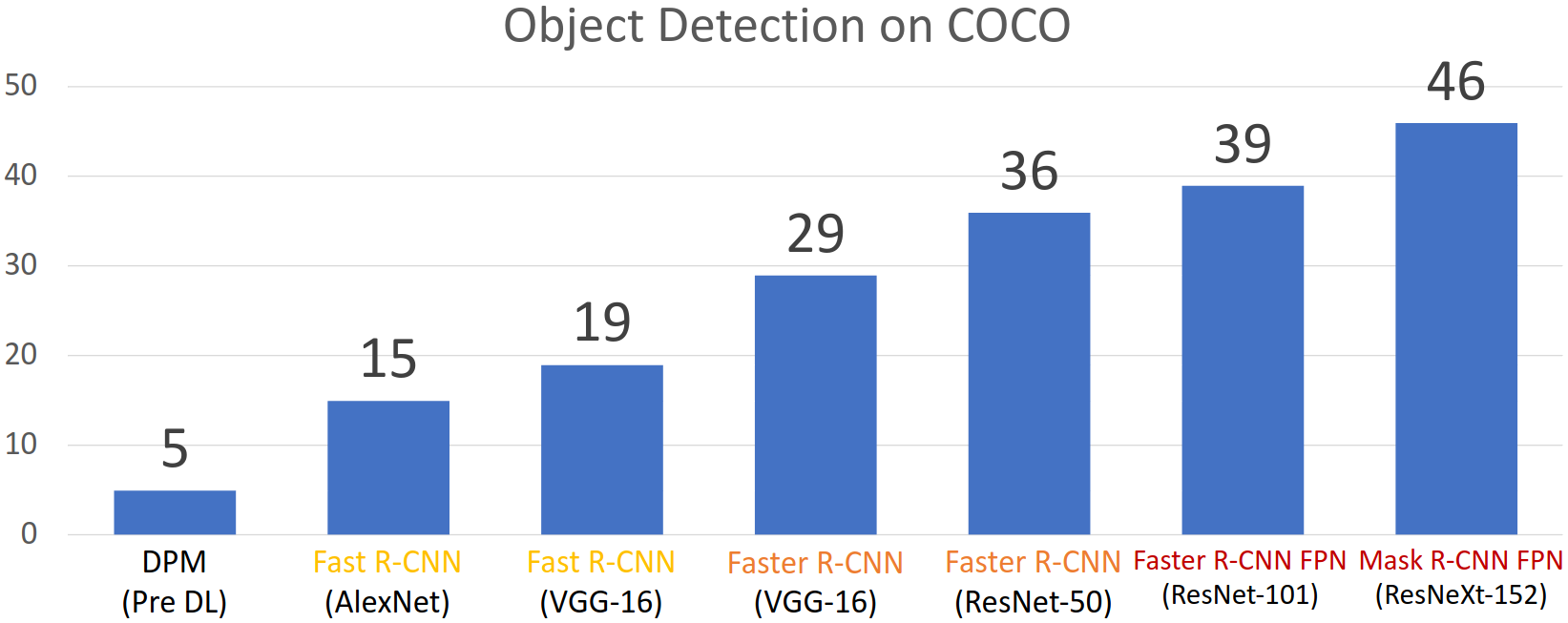
Transfer learning의 또 다른 특징으로는, image classification 시에 성능이 좋았던 모델을 backbone network 로 사용할수록 적용하려는 task에 대해서도 더 좋은 성능을 보인다는 것이다. 위 그림에서 추가된 layer의 종류가 같더라도 backbone network가 좋아질수록 성능이 향상되는 것을 확인할 수 있다.
Object Detection

Object detection은 이미지 내에서 object의 위치를 찾아내는 task이다. 이를 위해서는 classification과 localization이라는 두 가지 task를 동시에 수행해야 한다. 즉, 이미지 내에 어떤 object가 있는지 판별하고, 그 object가 어디에 있는지까지 찾아내야 한다. Object의 위치를 찾아내는 방법으로는 bounding box regression을 사용한다. 이때 bounding box는 box의 중심 좌표 (x, y), width, height의 네 개의 수로 표현된다.
Object detection은 이미지상에 여러 개의 object가 있을 수 있고, classification과 localization을 동시에 수행해야 하며 인풋 이미지의 크기도 커지기 때문에 classification에 비해 훨씬 어려운 task가 된다.
Object detection의 세부적인 사항은 아래와 같다.
- Bounding box는 물체가 회전되어 있더라도 이미지의 가로, 세로와 평행하게 그린다.
- 검출하고자 하는 물체의 일부분이 가려진 경우에는 보통 이미지에 보이는 부분만을 bounding box로 표시한다.
Intersection over Union (IoU)
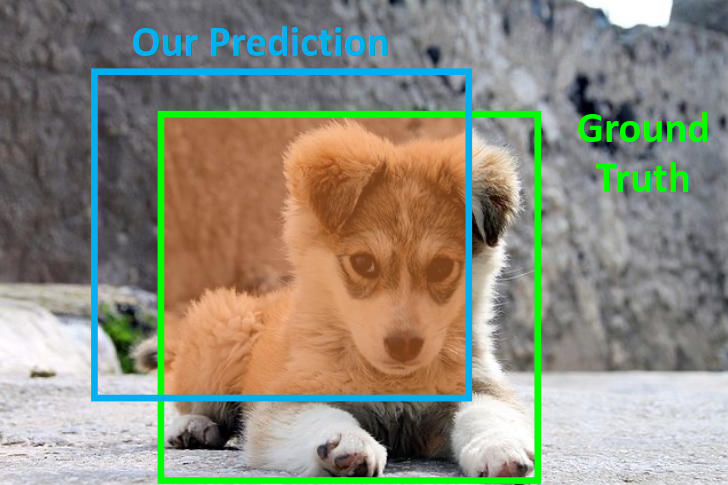
Intersection over Union(IoU)는 bounding box의 정확도를 측정하는 지표이다. IoU는 두 bounding box의 겹치는 영역의 비율을 나타내며, 아래와 같이 정의된다.
$IoU = \cfrac{\text{Area of Overlap}}{\text{Area of Union}}$
IoU > 0.5이면 두 bounding box가 괜찮은 정확도를 가진다고 판단한다. IoU > 0.7이면 꽤 높은 정확도를 가진다고 판단하고, IoU > 0.9이면 매우 높은 정확도를 가진다고 판단한다.
Detecting a Single Object
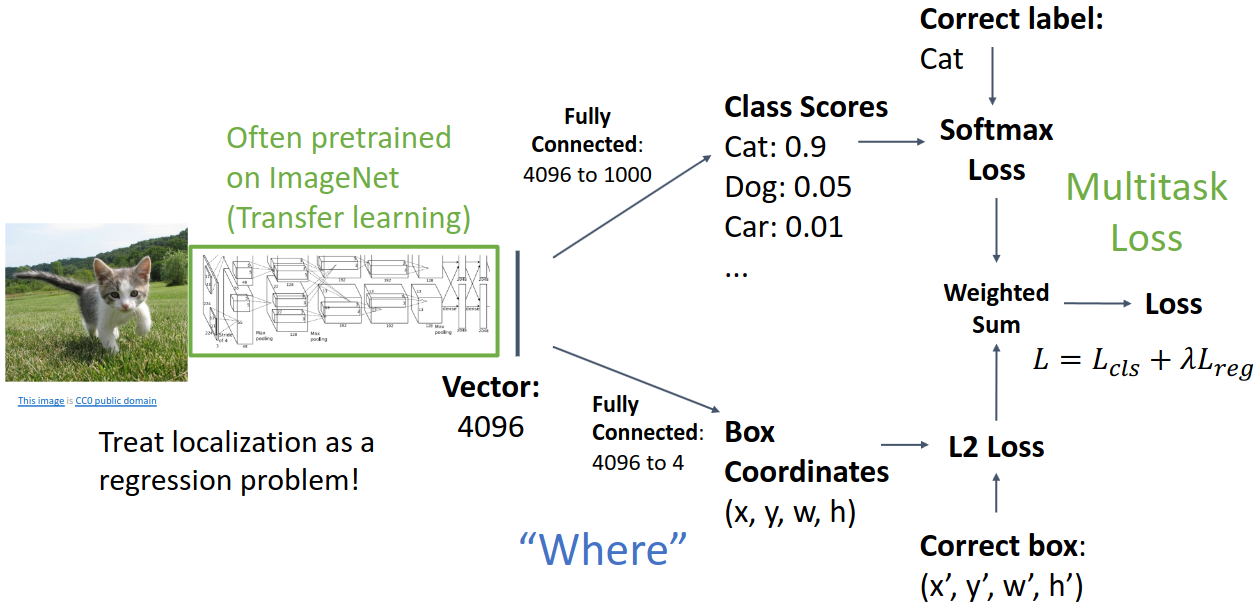
우선 하나의 이미지에 하나의 object만 있는 경우를 살펴보자. 먼저 transfer learning을 통해 가져온 모델을 이용하여 4096개의 feature를 추출한다. 이 feature vectore를 이용해 classification과 localization을 동시에 수행하게 된다.
먼저 classification을 살펴보면, 기존과 동일하게 fully connected layer를 통해 4096개의 feature를 1000개의 class로 분류한다. 이후 softmax를 통해 각 class에 대한 확률을 구하고, 가장 높은 확률을 가진 class를 선택한다.
Localization은 bounding box regression을 통해 수행한다. 이때 bounding box는 box의 중심 좌표 (x, y), width, height의 네 개의 수로 표현된다. 이를 위해 fully connected layer를 통해 4096개의 feature를 4개의 수로 변환한다. 이후 L2 loss을 통해 예측한 bounding box와 실제 bounding box의 차이를 계산한다.
이때 IoU는 loss로 사용하지 않는데, 두 box가 완전히 겹치지 않을 경우 IoU가 항상 0이 되어 gradient 또한 0이 되기 때문이다.
최종적인 loss는 classification loss와 localization loss의 가중치 합으로 정의된다. 이때 두 loss의 비율을 결정하는 $\lambda$는 hyperparameter가 된다.
Detecting Multiple Objects
여러 개의 object를 검출하는 경우에는 이미지 내에 몇 개의 object가 있는지 알 수 없기 때문에 훨신 어려운 문제가 된다.
Sliding Window

가장 단순한 방법으로, 이미지 위를 sliding하는 임의의 크기의 window를 만들어 각 window에 대해 detection을 진행하는 것이다. 이때 각 카테고리에 해당하는 물체가 존재하는지, 또는 아무 물체도 존재하지 않는지를 판별한다. 하지만 이 방법은 모든 크기의 window, 모든 위치에 대해 detection을 수행해야 하기 때문에 연산량이 매우 많다. 800x600 이미지의 경우 5800만 개의 window가 존재하게 된다.
Region Proposal
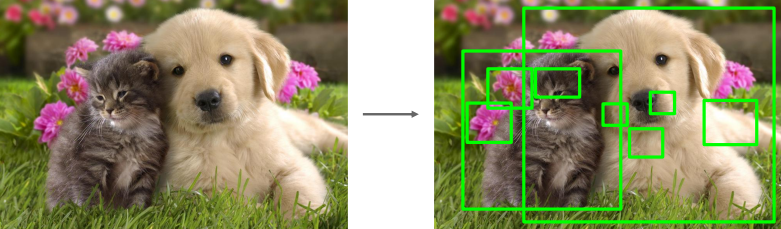
연산량을 줄이면서 효율적으로 물체를 탐색하기 위해, 먼저 물체가 있을 만한 영역을 찾아내고 그 영역에서만 detection을 수행하는 방법이 제안되었다. 물체가 있을 만한 직사각형 영역을 미리 찾아내는 것을 Region Proposal이라 한다.
Region Proposal에는 다양한 방법이 있다. 대표적인 방법인 Selective Search의 경우 2000개의 후보 영역을 찾아내는 데 CPU에서 몇 초밖에 소요되지 않기 때문에 매우 효율적이다. 하지만 이마저도 더 효율적인 neural network 모델로 대체되었다. 이에 대해서는 다음 강의에서 살펴보고, 우선은 원하는 개수만큼의 후보 영역을 얻어낼 수 있다고 가정하자.
Region Proposal을 이용해 multiple object detection을 수행하는 R-CNN에 대해 알아보자.
R-CNN: Region-based CNN
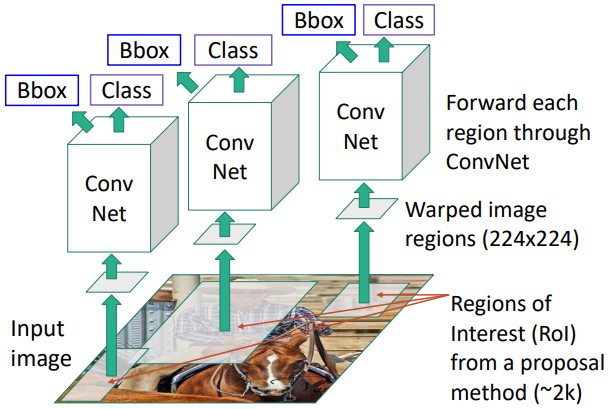
R-CNN은 Region Proposal을 통해 얻어낸 후보 영역(Regions of Interest, RoI)에 대해 각각 CNN을 적용하여 object detection을 수행하는 방법이다. 먼저 후보 영역을 224x224 크기로 resize한다. 이후 이 이미지들을 각각 CNN에 넣어 영역 안에 물체가 있는지 없는지를 판단하는 classification을 수행한다.
이와 동시에, 제안된 bounding box를 물체에 더욱 정확하게 맞추는 bounding box regression을 수행한다. 이를 위해 모델의 마지막에 classification과 별개의 FC branch를 추가하게 된다. 여기서는 기존의 bounding box를 얼마나 shift, scale할지를 결정하는 4개의 숫자 $(t_x, t_y, t_w, t_h)$를 예측한다.
Bounding Box Regression
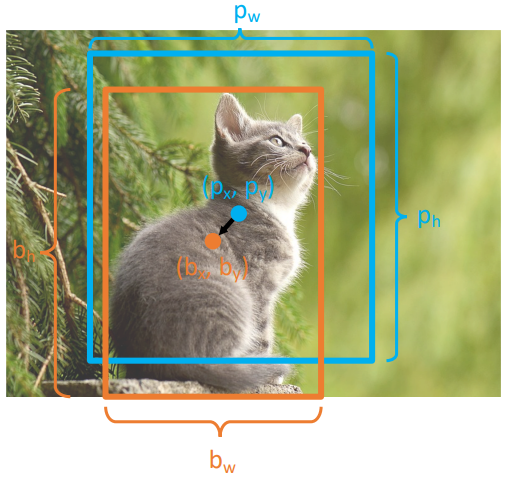
위 그림에서 파란색 박스를 region proposal을 통해 얻어낸 bounding box라고 하자. 이때 box의 중심을 $(p_x, p_y)$, width를 $p_w$, height를 $p_h$라고 하자. 이후 모델은 이 box를 어떻게 transform할지를 결정하는 $(t_x, t_y, t_w, t_h)$를 예측한다. 이때 예측된 bounding box는 아래와 같이 계산된다.
$\begin{align*} b_x &= p_x + t_x \cdot p_w \\ b_y &= p_y + t_y \cdot p_h \\ b_w &= p_w \cdot e^{t_w} \\ b_h &= p_h \cdot e^{t_h} \end{align*}$
중심 좌표인 $(p_x, p_y)$에 $t_x, t_y$를 단순히 더하는 것이 아니라 $p_w, p_h$를 곱한 후 더해줌으로써 직사각형 영역이 정사각형으로 압축된 후 CNN에 입력된 것을 보정해 준다. 또한 $t_w, t_h$에 exponential을 취해줌으로써 크기가 항상 양수가 되도록 한다. $t_x, t_y, t_w, t_h$가 모두 0일 때는 원래의 bounding box가 되기 때문에 L2 regularization과도 일맥상통한다.
또한 위의 공식을 이용해 ground truth bounding box와 region proposal bounding box 사이의 transform을 역산하면 R-CNN 모델이 학습할 데이터를 얻을 수 있다.
$\begin{align*} t_x &= \cfrac{b_x - p_x}{p_w} \\ t_y &= \cfrac{b_y - p_y}{p_h} \\ t_w &= \log \cfrac{b_w}{p_w} \\ t_h &= \log \cfrac{b_h}{p_h} \end{align*}$
R-CNN Training
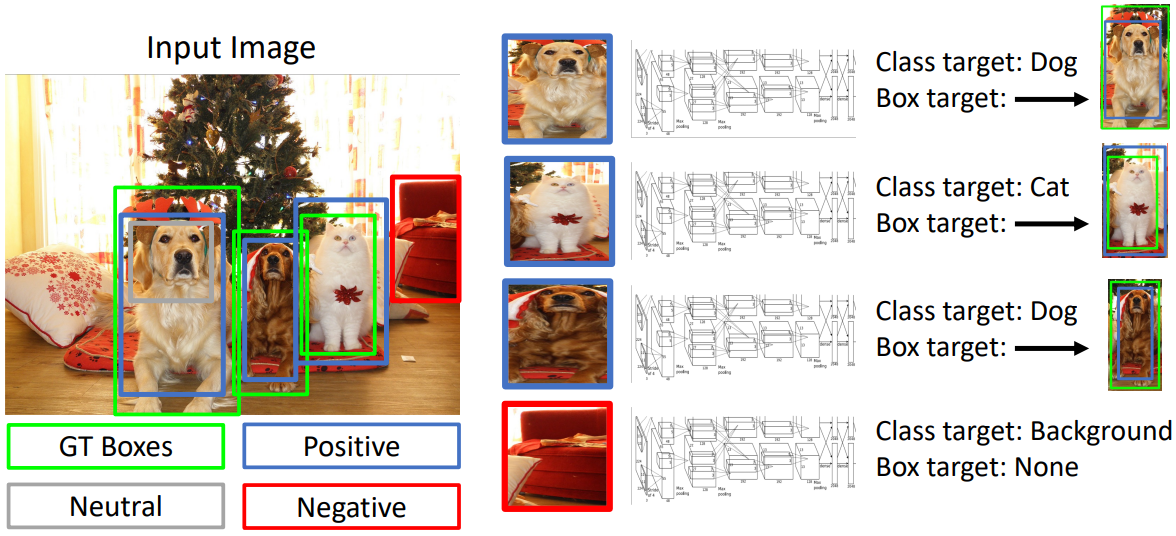
R-CNN의 학습은 다음과 같이 진행된다. 우선 이미지의 각 물체에 대한 ground truth box와 region proposal 결과는 왼쪽 그림과 같다. 이때 training 시에는 GT 정보를 알고 있기 때문에 각 region proposal 결과마다 IoU 값이 최대가 되게 하는 GT box를 찾을 수 있다. IoU의 최댓값이 0.5 이상은 positive, 0.3 이하는 negative, 그 사이는 neutral로 정한다. Positive region의 경우 IoU가 최대가 되게 하는 GT box와 매칭시킨다.
이후 positive나 negative로 분류된 region proposal만을 이용하여 학습을 진행한다. 우선 각 region 영역 내 이미지를 224x224로 resize한 후 각각의 모델에 input으로 넣는다. 이 모델은 출력으로 물체의 class와 bounding box의 transform을 예측할 것이다.
Positive region의 경우를 살펴보면, 각 region은 각각 IoU가 최대인 GT box와 매칭되어 있으므로 이 GT box의 class와 둘 사이의 transform을 예측하도록 학습할 수 있다. Transform의 경우 4개의 수를 단순 벡터로 생각하여 모델이 예측한 벡터와 실제 GT box로 transform이 이루어지게 하는 벡터 사이에 L2 loss를 적용한다.
Negative region의 경우는 물체가 없는 영역이므로 class를 background로 예측해야 한다. Transform 예측 결과는 무시한다.
R-CNN Test Time
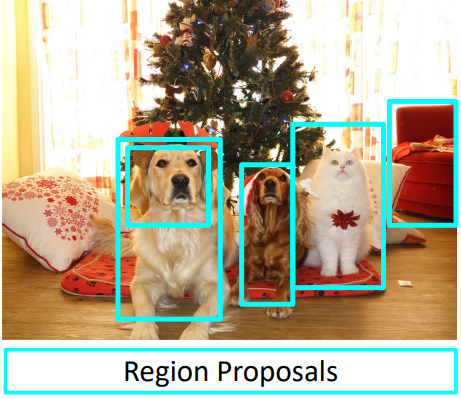
Test 시에는 우선 이미지에 대해 region proposal을 수행한 후, 각 영역을 224x224로 resize한다. 이후 각 이미지들을 CNN에 넣어 class와 bounding box transform을 예측한다. 이후 각 region에 대해 class가 background가 아니고, class score가 threshold 이상인 region만을 남긴다. 남은 region에 대해서는 모델로부터 얻은 transform을 이용하여 bounding box를 변형시킨다. 이 과정을 bounding box regression이라 하며, 이를 통해 최종 bounding box를 얻어낸다.
이때 class score의 threshold는 heuristic으로 정하게 되는데, 전체 클래스에 대해 threshold를 정하거나 각 클래스마다 threshold를 정하는 방법이 있다. 다만 이는 데이터의 종류에 따라, 원하는 목적에 따라 스스로 정해야 하는 hyperparameter이다.
Overlapping Boxes: Non-Max Suppression (NMS)
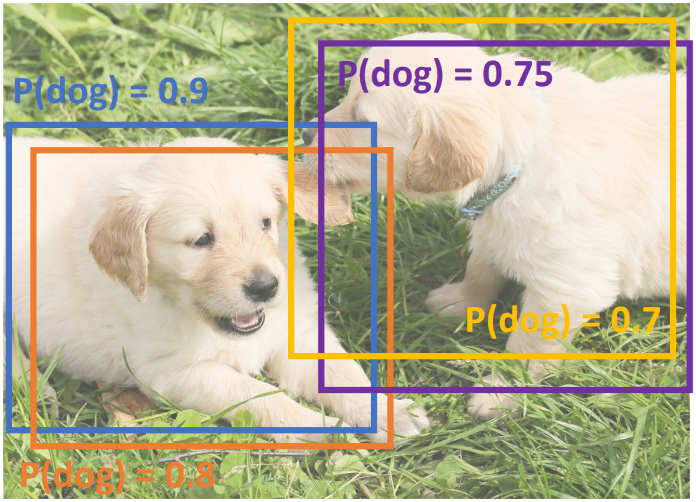
Regional proposal을 통해 얻어낸 bounding box들은 서로 겹치는 경우가 많다. 따라서 이러한 overlapping box를 제거하는 것이 효율적이다. 이를 위해 Non-Max Suppression(NMS)이라는 방법이 사용된다.
NMS는 먼저 class score가 높은 순서대로 bounding box를 정렬한다. 이후 가장 높은 class score를 가진 box를 선택하고 다른 모든 box들과의 IoU를 계산한다. 이때 IoU가 threshold 이상인 box들은 제거한다. 이 과정을 반복하여 최종적으로 겹치지 않는 bounding box들만을 남긴다.
다만 이 방법은 이미지 내 물체들 자체가 많이 겹쳐져 있는 경우에는 제대로 작동하지 않을 수 있다.